JUC并发编程大礼包
JUC:就是 java.util .concurrent 工具包的简称,这是一个处理线程的工具包
线程的状态
可观察:Thread.State枚举类
-
NEW (新建)
-
RUNNABLE (准备就绪)
-
BLOCKED (阻塞)
-
WAITING (一直等待)
-
TIMED_WAITING (等待一定时间)
-
TERMINATED (终结)
wait和sleep的区别
-
sleep 是 Thread 的静态方法、wait 是 Object 的方法,任何对象实例都能调用
-
sleep 不会释放锁、wait 会释放锁,但调用它的前提是当前线程占有锁(即代码要在 synchronized 中)
-
它们都可以被 interrupted 方法中断
并发与并行
-
串行
-
表示所有任务都一一按先后顺序进行
-
准备调料 - 切菜 - 热油 - 下菜 - 调味 - 洗盘子 - 装盘
-
-
并行
-
并行的效率从代码层次上强依赖于多进程/多线程代码,从硬件角度上则依赖于多核 CPU
-
准备调料 - 切菜同时热油 - 下菜时可洗盘子 - 调味 - 装盘
-
-
并发
-
同一时刻多个线程在访问同一个资源,多个线程对一个点
-
管程(monitor)
管程(monitor)是保证了同一时刻只有一个进程在管程内活动,即管程内定义的操作在同一时刻只被一个进程调用(由编译器实现).但是这样并不能保证进程以设计的顺序执行
JVM 中同步(锁)是基于进入和退出管程(monitor)对象实现的,每个对象都会有一个管程(monitor)对象,管程(monitor)会随着 java 对象一同创建和销毁执行线程首先要持有管程对象,然后才能执行方法,当方法完成之后会释放管程,方法在执行时候会持有管程,其他线程无法再获取同一个管程
用户线程与守护线程
用户线程:平时用到的普通线程,自定义线程
守护线程:运行在后台,是一种特殊的线程,比如垃圾回收
-
当主线程结束后,用户线程还在运行,JVM 存活
-
如果没有用户线程,都是守护线程,JVM 结束
Lock接口
Synchronized
synchronized 是 Java 中的关键字,是一种同步锁。它修饰的对象有以下几种:
-
修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象
-
修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象
-
修饰一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象
-
修饰一个类,其作用的范围是 synchronized 后面括号括起来的部分,作用主的对象是这个类的所有对象
-
虽然可以使用 synchronized 来定义方法,但 synchronized 并不属于方法定义的一部分,因此,synchronized 关键字不能被继承。如果在父类中的某个方法使用了 synchronized 关键字,而在子类中覆盖了这个方法,在子类中的这个方法默认情况下并不是同步的,而必须显式地在子类的这个方法中加上synchronized 关键字才可以。当然,还可以在子类方法中调用父类中相应的方法,这样虽然子类中的方法不是同步的,但子类调用了父类的同步方法,因此,子类的方法也就相当于同步了
伪代码售票案列
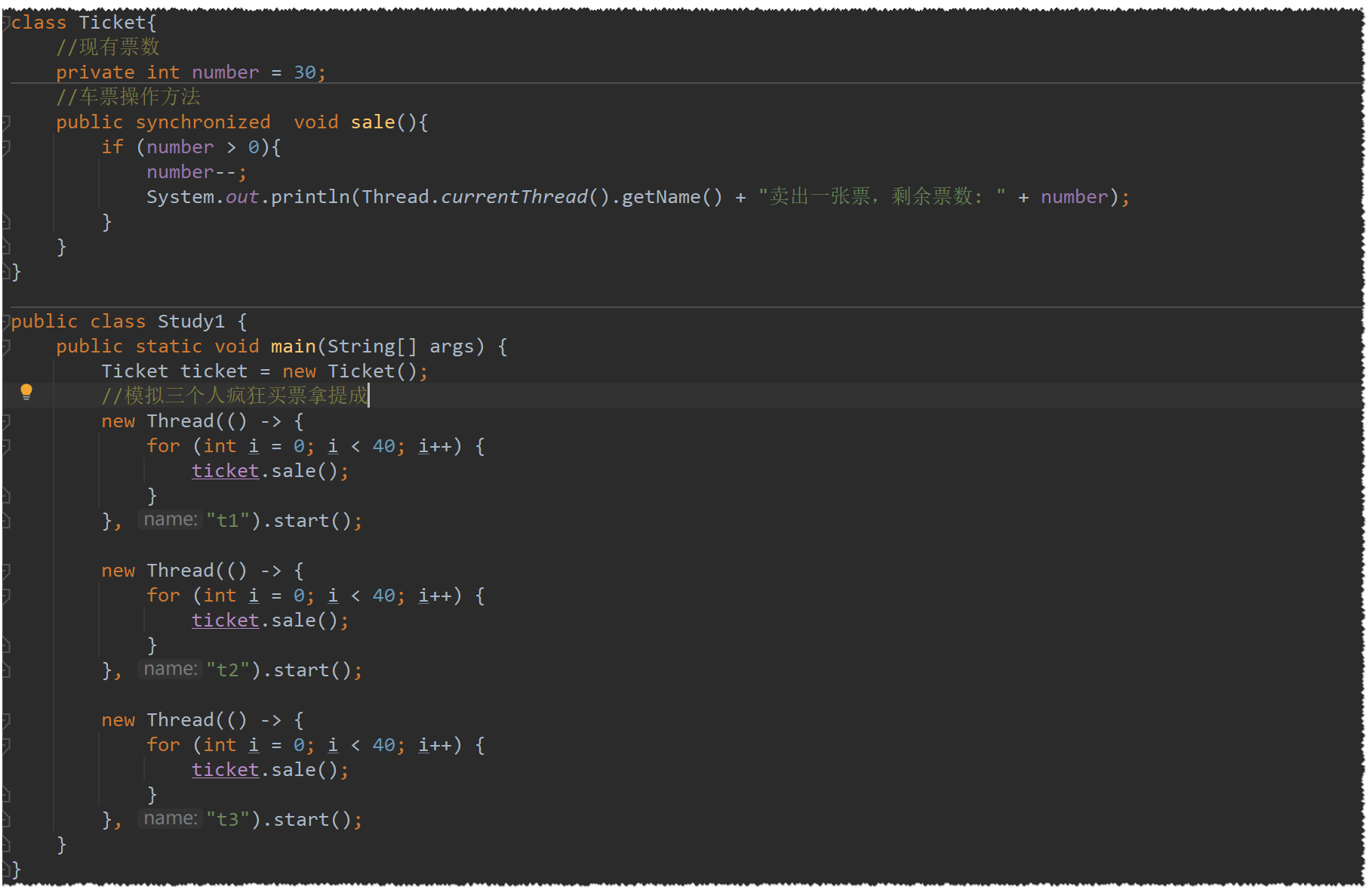
-
上面得Ticket类得sale方法是被synchronized修饰得一个方法,当一个线程获得锁在执行业务得时候,其他线程便只能一直等待,直到当前获得锁得线程释放锁,当前获得锁得线程会有两个情况都会释放锁
-
执行完了该代码块 , 放弃对锁得赞占有
-
线程执行过程中发生了异常,JVM会让线程释放锁
-
Lock接口说明
Lock 提供了比 synchronized 更多的功能,Lock是一个接口,主要的方法包含:
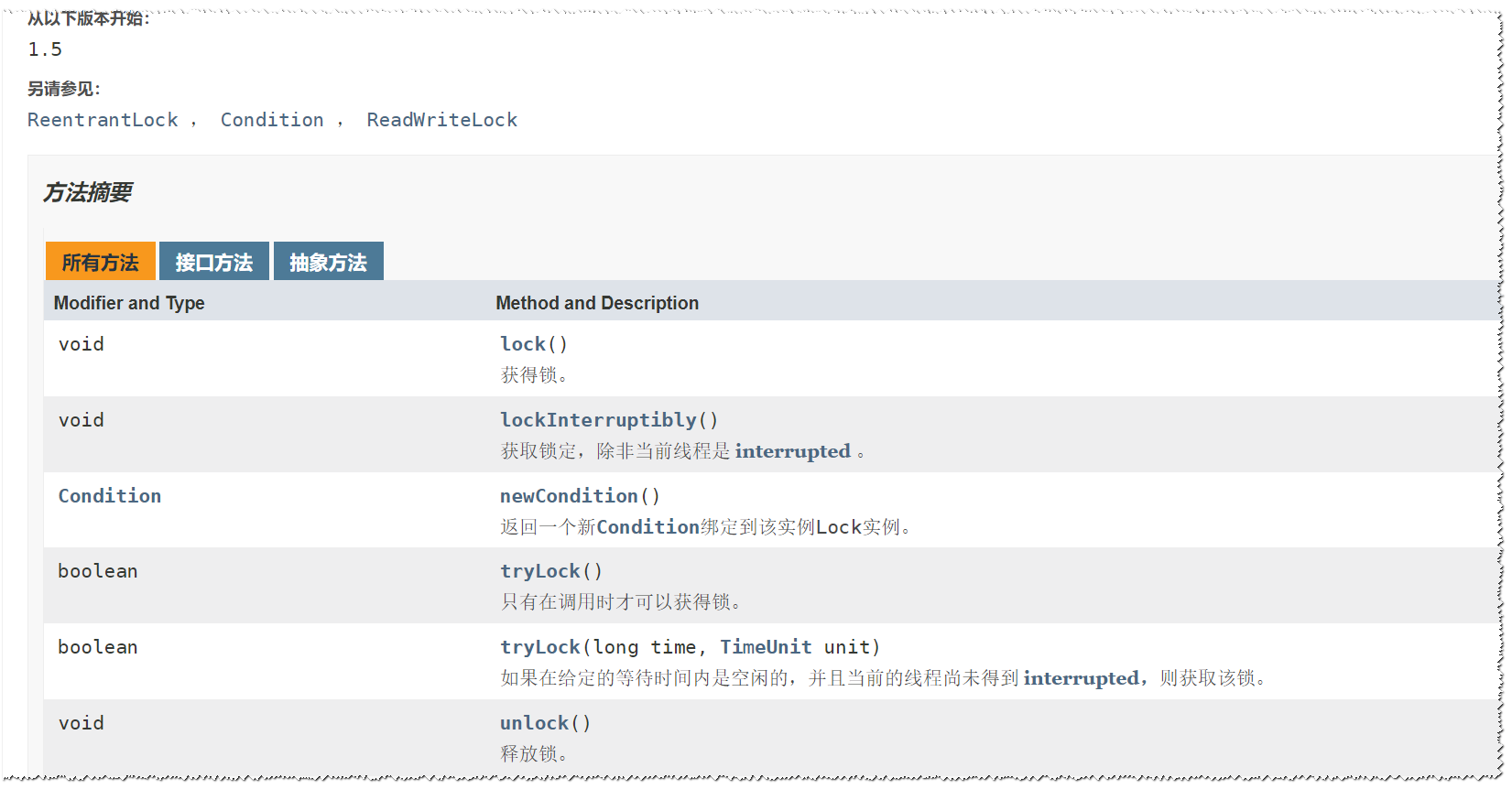
newCondition()方法简单说明
-
synchronized 使用 wait() / notify() 这两个方法一起使用可以实现等待/通知模式
-
Lock 锁的 newContition()方法返回 Condition 对象,Condition 类使用await() / signal() 可以实现等待/通知模式
-
await():会使当前线程等待,同时会释放锁,当其他线程调用 signal()时,线程会重新获得锁并继续执行
-
signal():用于唤醒一个等待的线程
-
-
注意:在调用 Condition 的 await()/signal()方法前,也需要线程持有相关的 Lock 锁,调用 await()后线程会释放这个锁,在 singal()调用后会从当前Condition 对象的等待队列中,唤醒 一个线程,唤醒的线程尝试获得锁, 一旦获得锁成功就继续执行
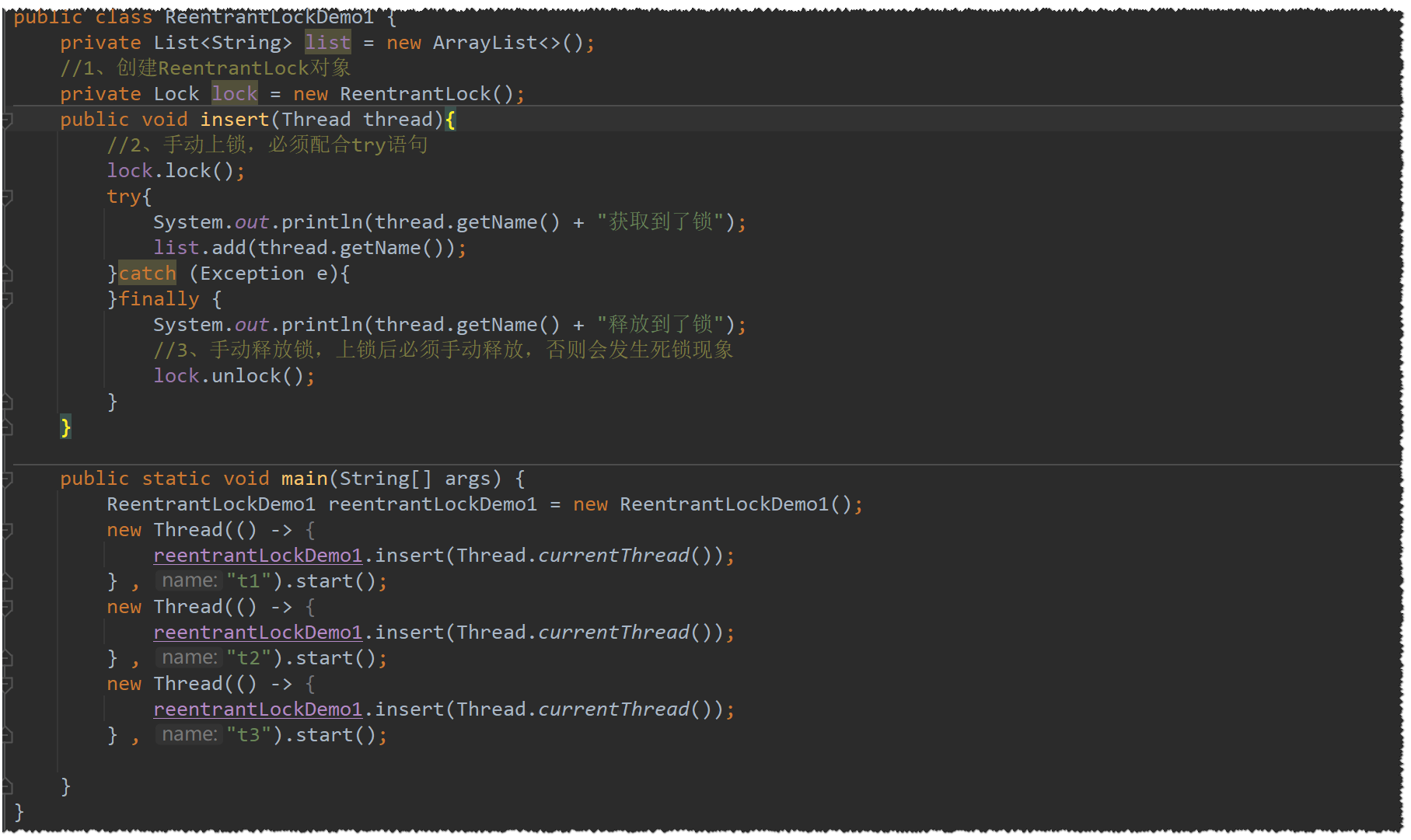
ReentrantLock
API手册中时这样描述这个类的:
-
一个可重入互斥
Lock具有与使用synchronized方法和语句访问的隐式监视锁相同的基本行为和语义,但具有扩展功能
下面我们来简单使用一下

ReentrantReadWriteLock
顾名思义:读写锁,该接口只有两个方法,readLock() 、 writeLock
-
熟悉MySQL的朋友都知道,InnoDB储存引擎下的锁就有这个概念【独占锁、共享锁】
-
在这里也是一样,读锁是一个共享锁 , 写锁是一个排他锁,下面我们用代码简单示范一下
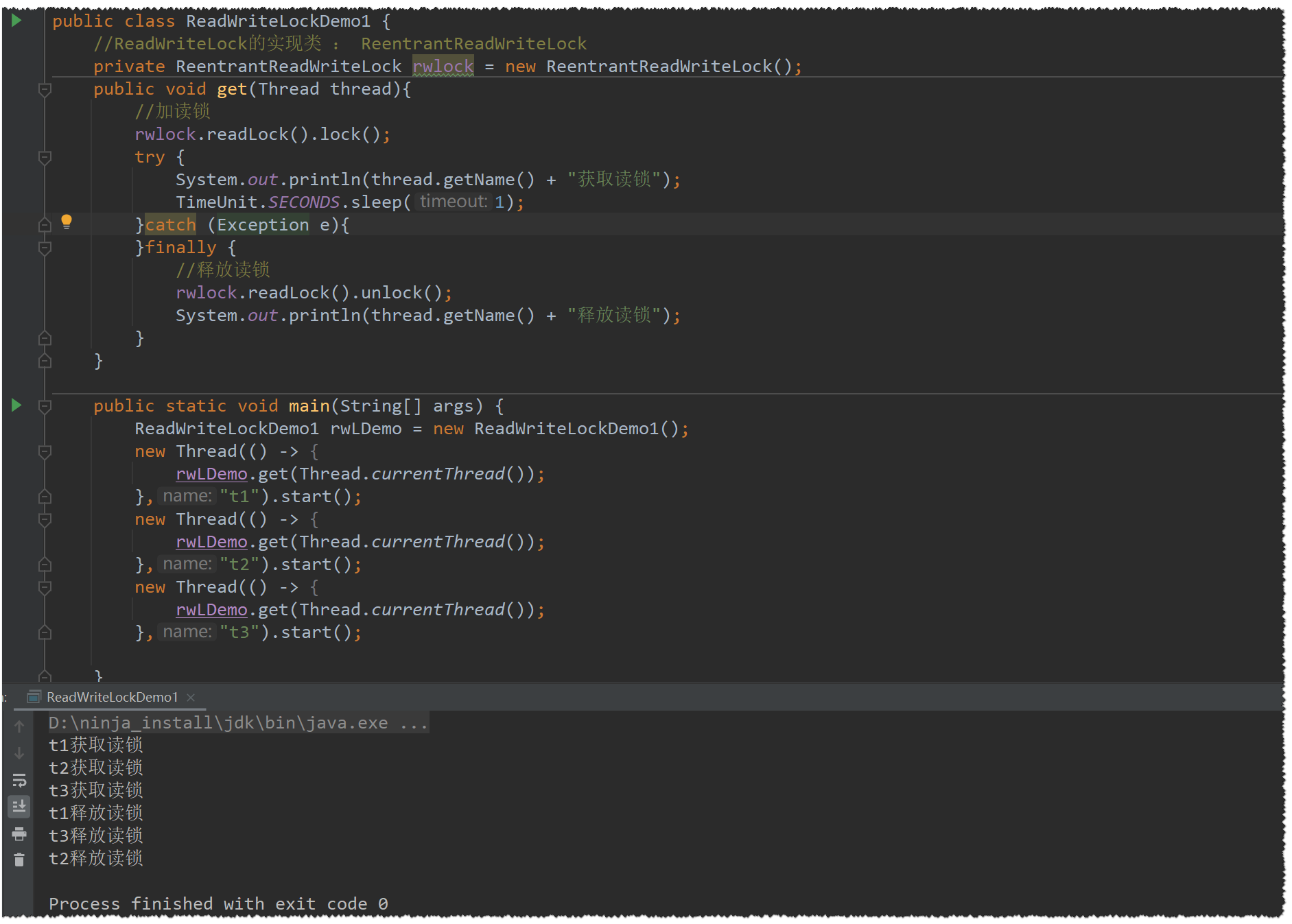
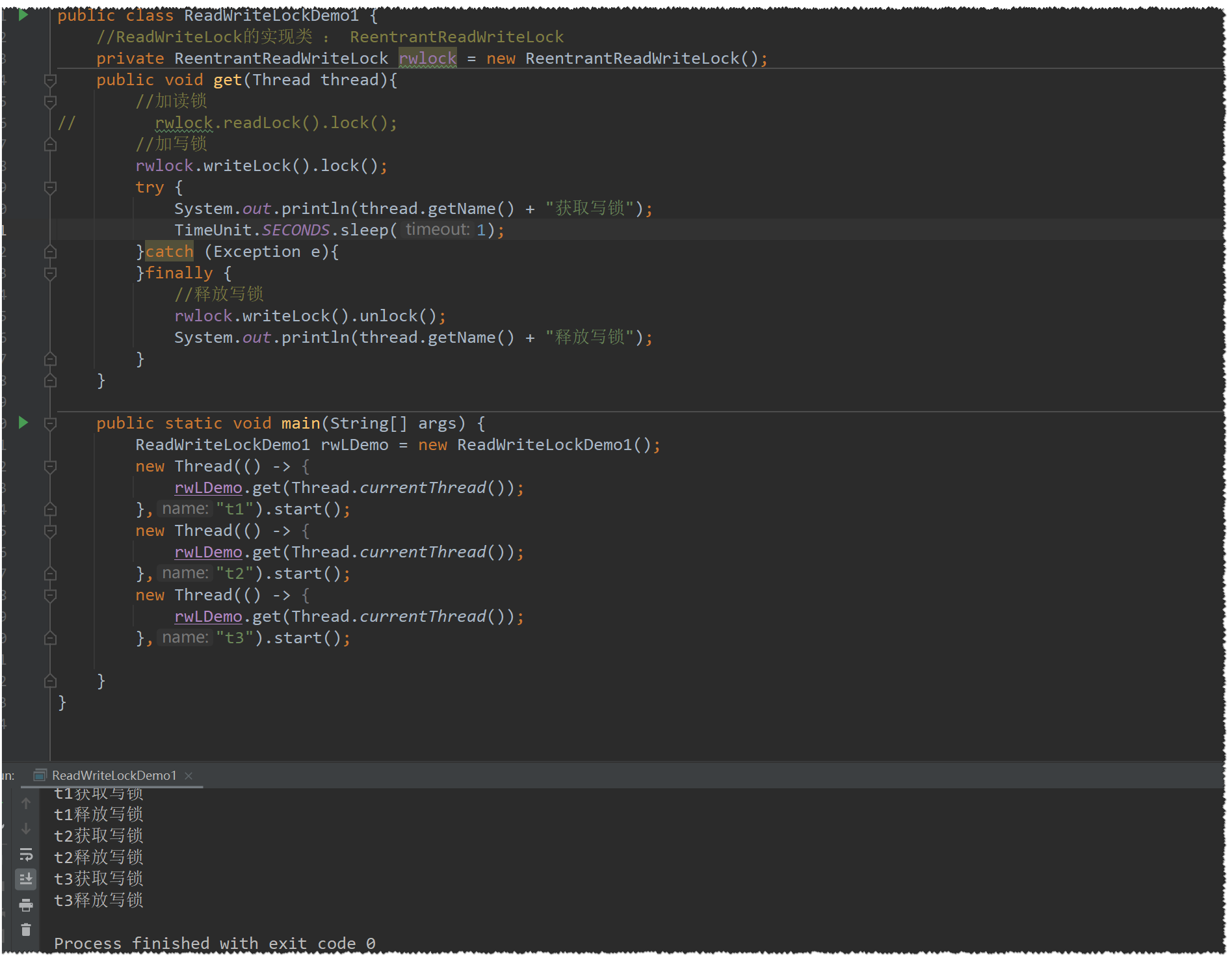
这里再提一下注释事项:
-
已有线程占有读锁,再来线程获取写锁得处于等待状态,等待读锁释放
-
在该线程持有读锁的情况下,该线程不能继续获取写锁
-
-
已有线程占有写锁,再来线程获取读锁或者写锁都得处于等待状态,等待写锁释放
-
在该线程持有写锁的情况下,该线程可以继续获取读锁,只有写锁不是当前线程持有的情况下再次获取读锁才会失败
-
-
public ReentrantReadWriteLock(boolean fair) {}上面我们使用到了无参构造,他还有一个有参构造-
传入参数位布尔,代表是否获取公平锁,默认为false,我们可以看其无参构造中调用
this(false);得到验证 -
吞吐量优先的情况下,非公平锁的性能优于公平锁
-
Lock和synchronized 的区别
-
synchronized 是 Java 语言的关键字,Lock 是一个接口,不是 Java 语言内置的,属于API级别
-
synchronized 在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生,而 Lock 在发生异常时,如果没有主动通过 unLock()去释放锁,则很可能造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁
-
Lock 可以使用
tryLock(long timeout, TimeUnit unit)让等待锁的线程响应中断,而 synchronized 却不行,使用synchronized 时,等待的线程会一直等待下去,不能够响应中断 -
Lock 可以提高多个线程进行读操作的效率
线程间通信
线程间通信的模型有两种:共享内存和消息传递
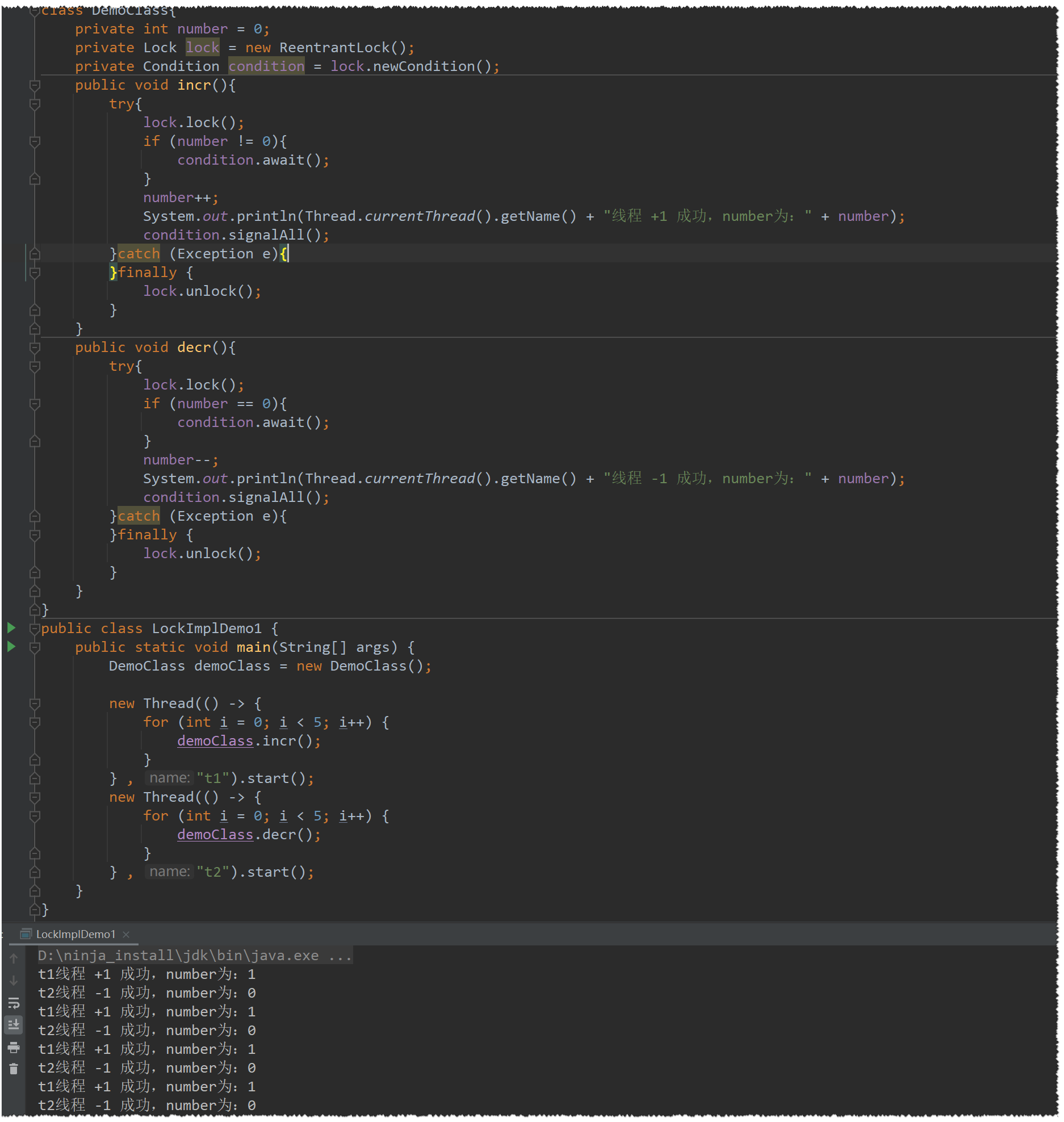
场景:两个线程,一个线程负责对某个数字 + 1, 另一个线程负责 - 1 , 两个线程交替执行
Lock实现方式
synchronized实现方式
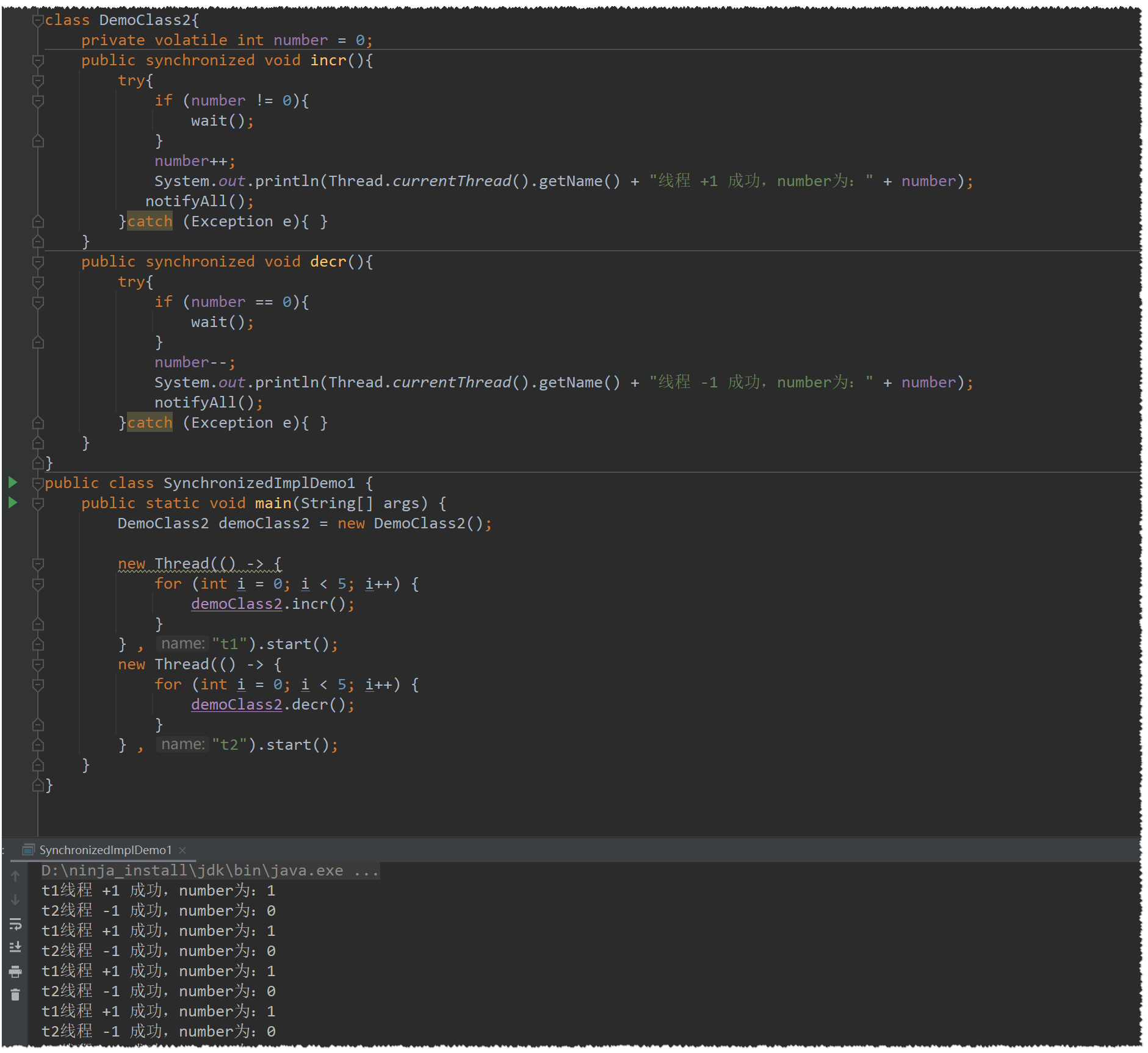
在上面的实现中,还有一个隐藏的问题存在就是:虚假唤醒
-
我们再加一下线程来看看,t1、t3负责加 , t2、t4负责减
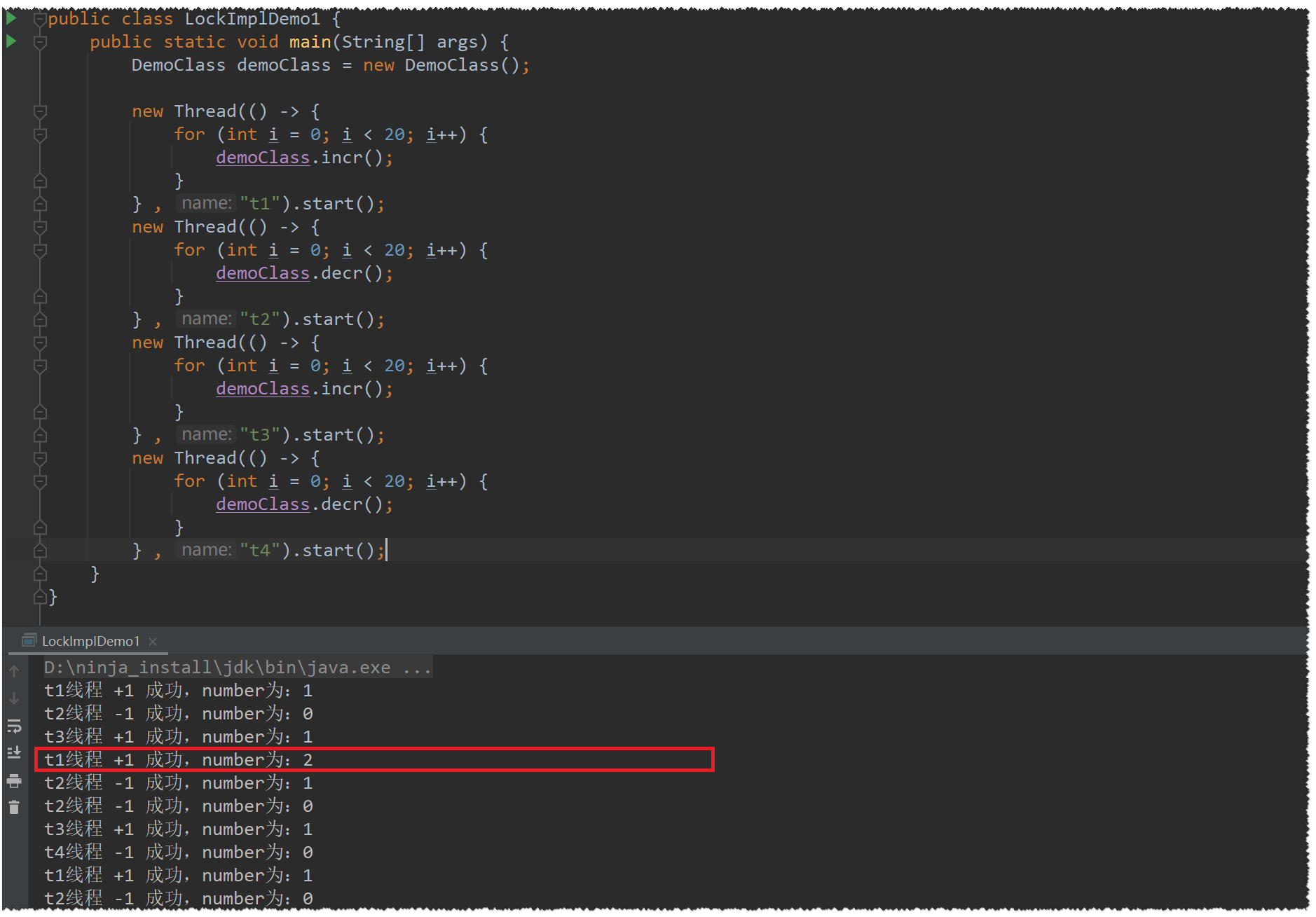
结果出现了一个2,是什么情况呢?
-
虚假唤醒造成的原因就是:线程在哪里睡下,就会在哪里醒来,醒来继续往下执行代码,逃过了if()的判断
-
因此不建议使用
if (number == 0)这种语句,而是应该使用while (number == 0)这种循环语句
集合的线程安全问题
ArrayList线程安全问题
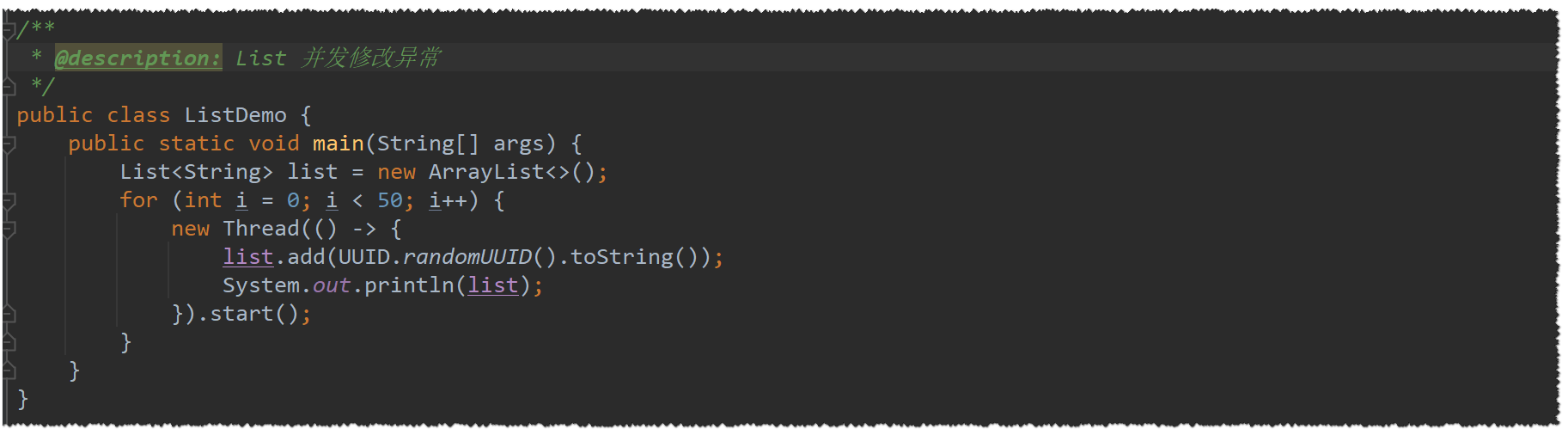
List的并发修改异常:java.util.ConcurrentModificationException
-
造成这个异常出现的原因就是当一个线程在修改这个集合的时候,另一个线程也在修改这个集合,并修改了该集合的容量大小,就会抛出这一异常

因为add()没有加任何的锁,导致容器大小在并发时被随意修改,导致异常抛出
第一种解决方式:
List<Object> list = Collections.synchronizedList(new ArrayList<>());(不推荐)

-
Vector的add()时加了synchronized同步锁的,不会出现并发修改问题
第二章解决方法:
List<Object> list = Collections.synchronizedList(new ArrayList<>());(不推荐)


可以发现也是加了同步锁的
第三种解决方法:
List list = new CopyOnWriteArrayList();(推荐)
-
CopyOnWriteArrayList 相当于线程安全的ArrayList,和 ArrayList 一样,它是个可变数组;
-
动态数组机制
-
它内部有个“volatile 数组”(array)来保持数据。在“添加/修改/删除”数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给“volatile 数组”, 这就是它叫做 CopyOnWriteArrayList 的原因
-
由于它在“添加/修改/删除”数据时,都会新建数组,所以涉及到修改数据的操作,CopyOnWriteArrayList 效率很低;但是单单只是进行遍历查找的话,效率比较高
-
-
线程安全机制
-
通过 volatile 和互斥锁来实现的。
-
通过“volatile 数组”来保存数据的。一个线程读取 volatile 数组时,总能看到其它线程对该 volatile 变量最后的写入;就这样,通过 volatile 提供了“读取到的数据总是最新的”这个机制的保证
-
通过互斥锁来保护数据。在“添加/修改/删除”数据时,会先“获取互斥锁”,再修改完毕之后,先将数据更新到“volatile 数组”中,然后再“释放互斥锁”,就达到了保护数据的目的
-
HashSet线程安全问题
和ArrayList一样,并发修改也会抛出异常,大家都知道HashSet的底层就是HashMap,使用HashMap的key进行储存数据,无需且不允许重复
解决方案:CopyOnWriteArraySet
HashMap的线程安全问题
解决方案:ConcurrentHashMap
多线程锁
synchronized 实现同步的基础:Java 中的每一个对象都可以作为锁。
-
对于普通同步方法,锁是当前实例对象。
-
所以同一个类中有多个同步方法,但实列对象只有一个,锁竞争,同一时刻,只能有一个线程执行同步方法
-
同步方法和非同步方法不互斥
-
-
对于静态同步方法,锁是当前类的 Class 对象
-
所以一个类的静态同步方法和非静态同步方法不互斥,锁对象不同
-
但是两个静态同步方法会发生互斥现象,锁相同造成锁竞争
-
-
对于同步方法块,锁是 Synchonized 括号里配置的对象
Callable & Future接口
创建线程的4种方式中,继承Thread 、实现Runnable接口均无法获取子进程的运算接口,且也无法控制服务器性能损耗,
现在我们开始讲解第三种创建线程的方式,该方式可以获取子线程的运算结果和捕获期间发生的异常
-
查看构造方法,得到入参为
Callable

-
发现是一个函数式接口

-
直接开始上活
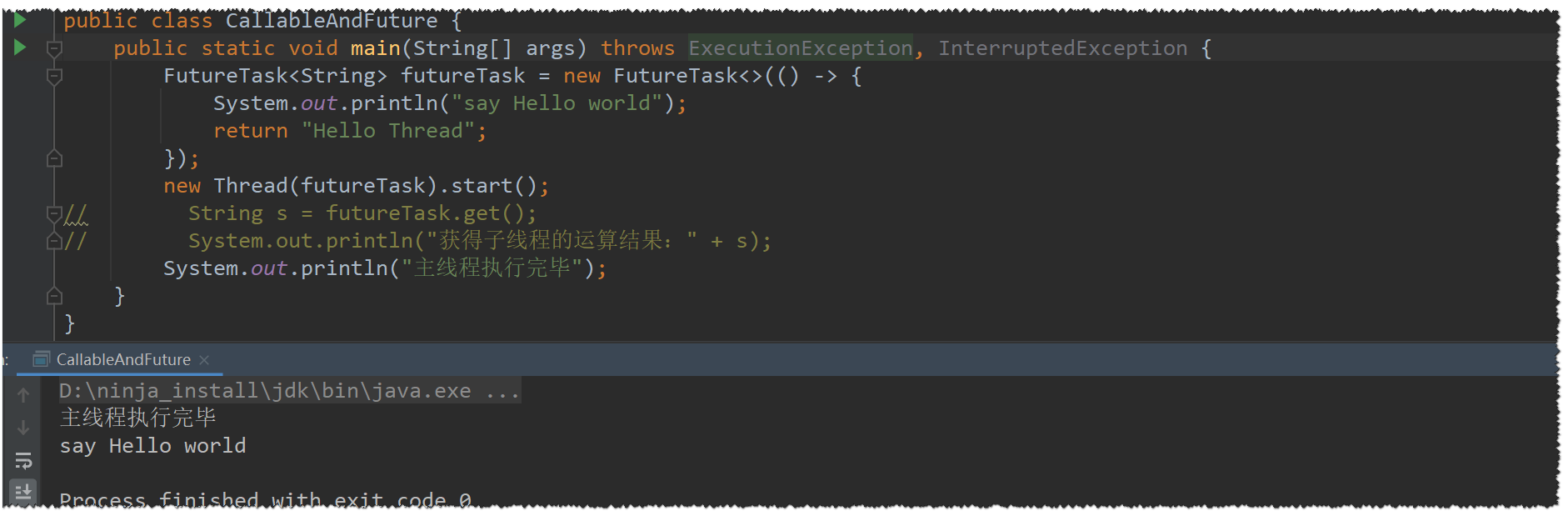
FutureTask方法一览
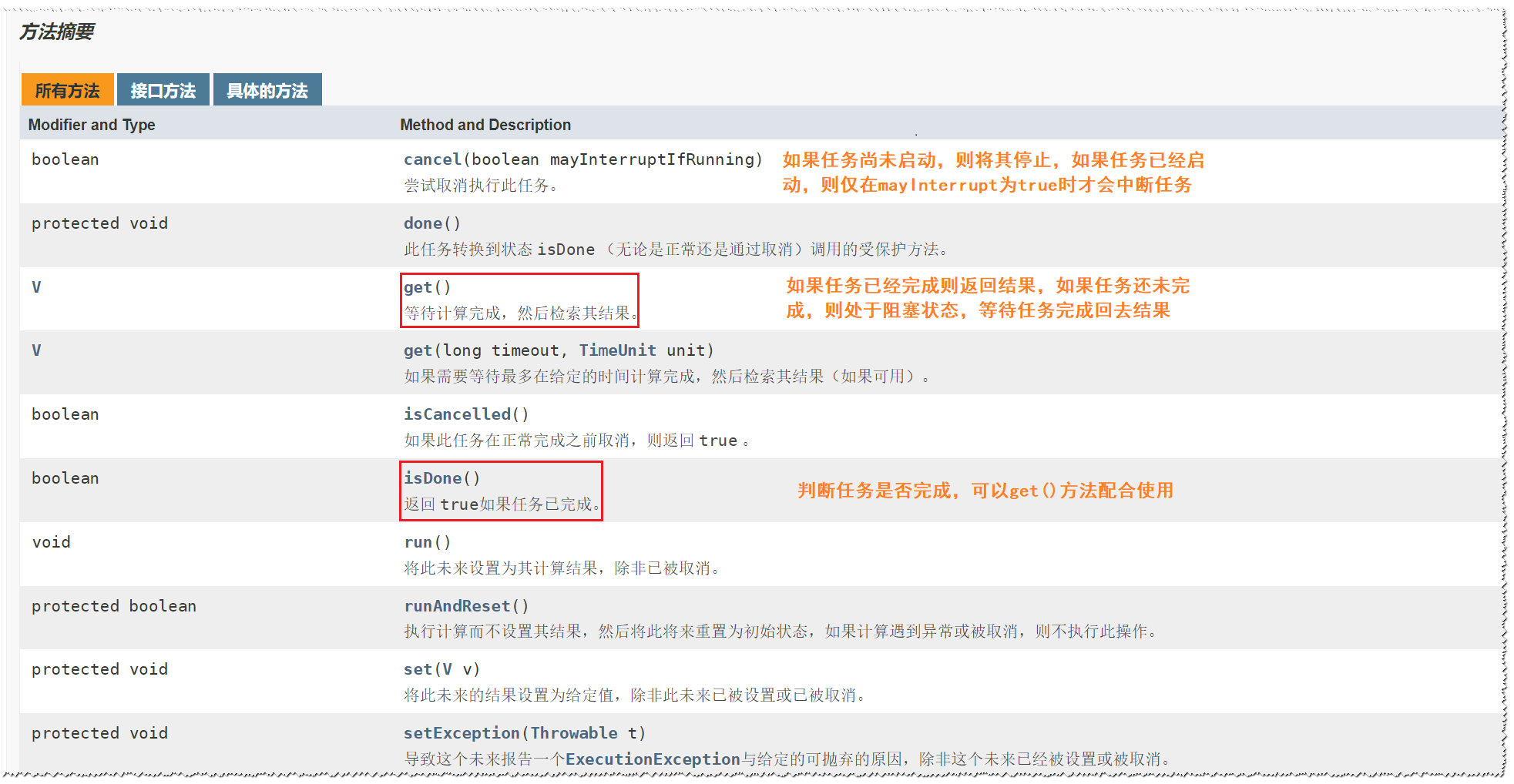
一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后再去获取结果
JUC三大辅助类
JUC 中提供了三种常用的辅助类,通过这些辅助类可以很好的解决线程数量过多时 Lock 锁的频繁操作。这三种辅助类为:
CountDownLatch: 减少计数
-
类似于Redis的闭锁:
-
-
CountDownLatch实现
-
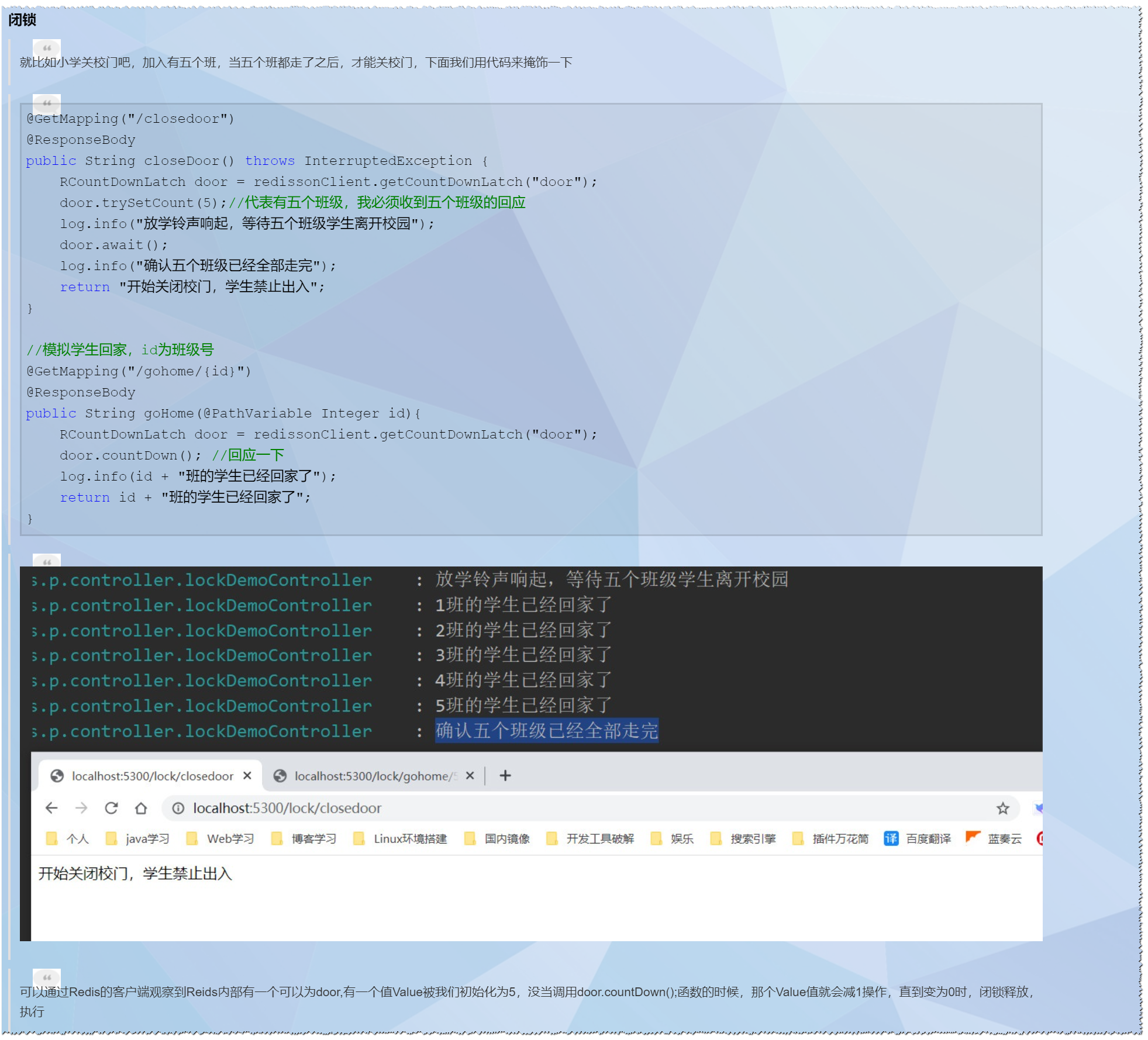
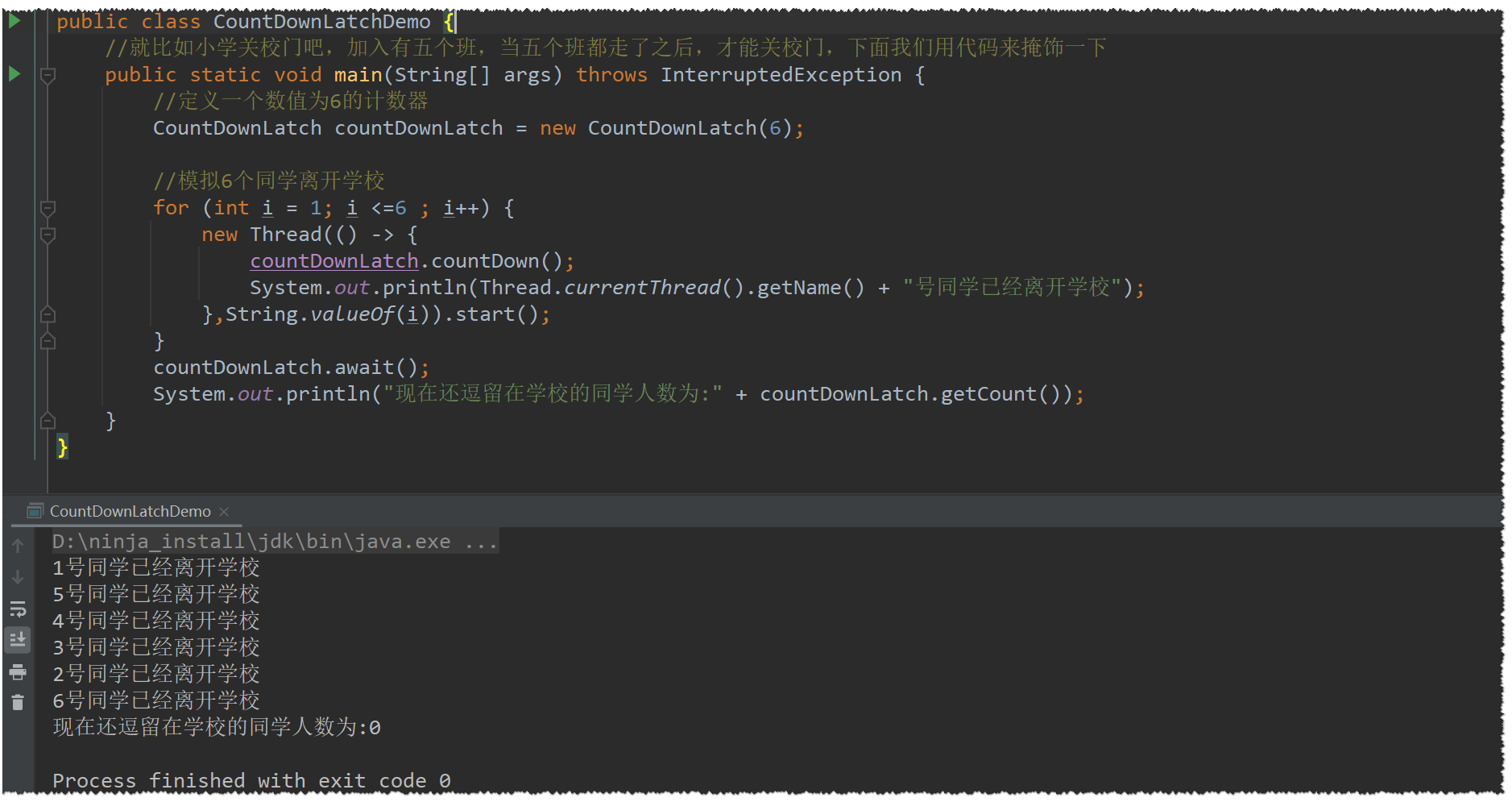
CyclicBarrier: 循环栅栏
这个还没想到有什么应用场景,那我们还是以上面6个学生离开学才能关门来掩饰一下他的功能
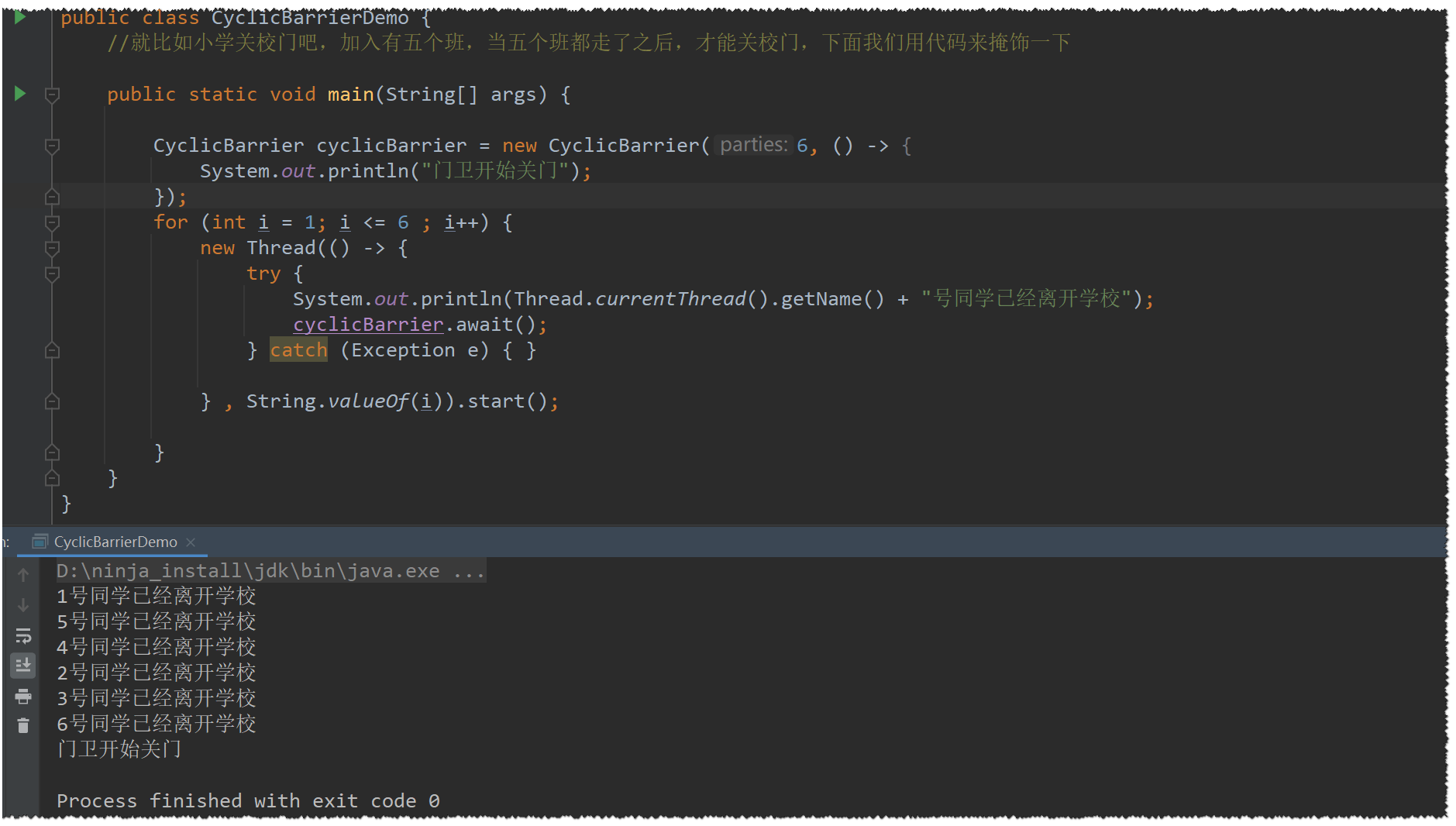
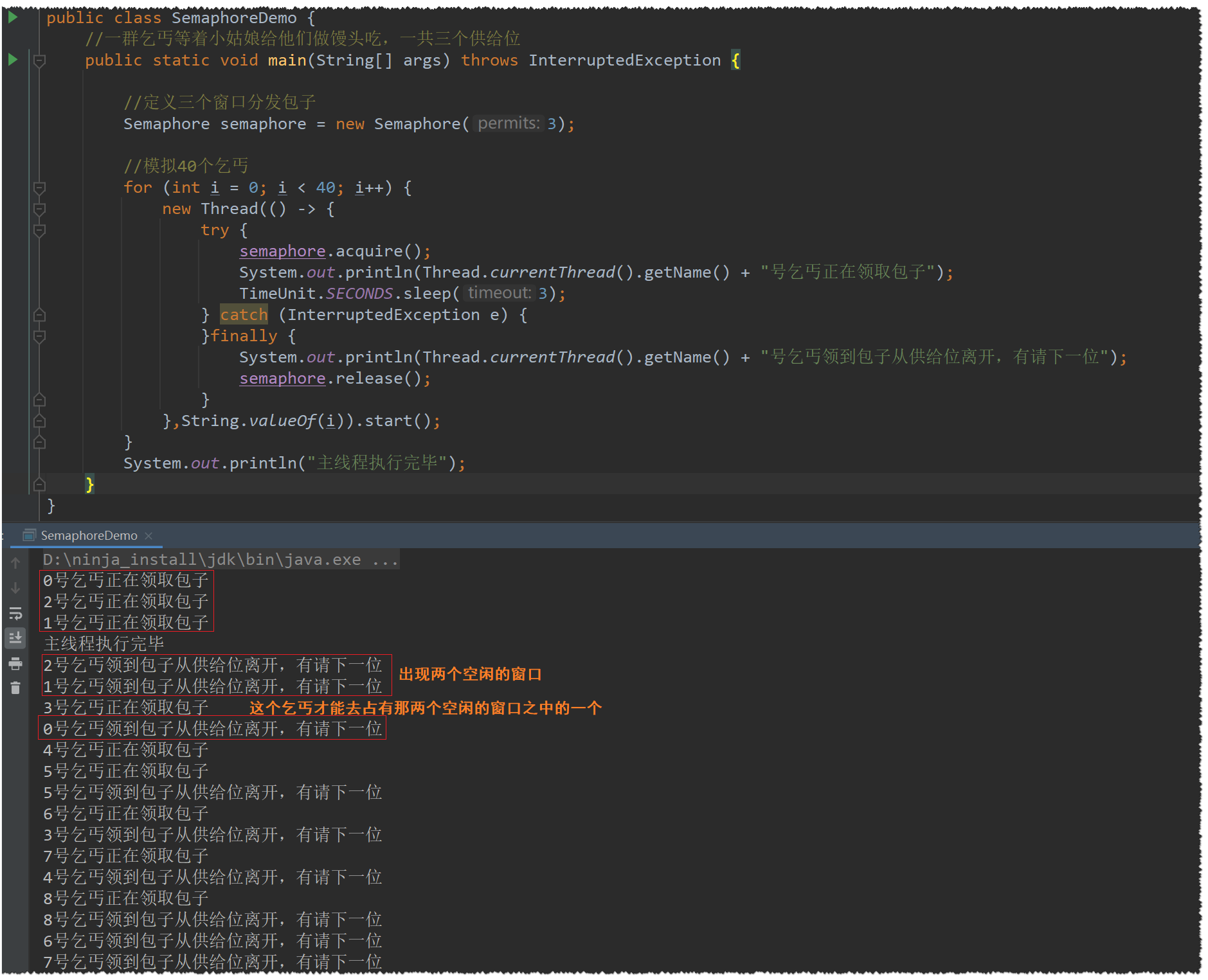
Semaphore: 信号灯
-
和Redis的信号量一致
-
-
Semaphore代码实现
-

总结一下
-
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才继续往下执行,会阻塞A线程
-
CyclicBarrier一般用于在执行一组线程互相等待至某个状态,然后类似于回调一个方法 , 不会阻塞主线程
-
Semaphore其实和锁有点类似,它一般用于控制对某组资源的访问权限
阻塞队列BlockingQueue
常见核心方法
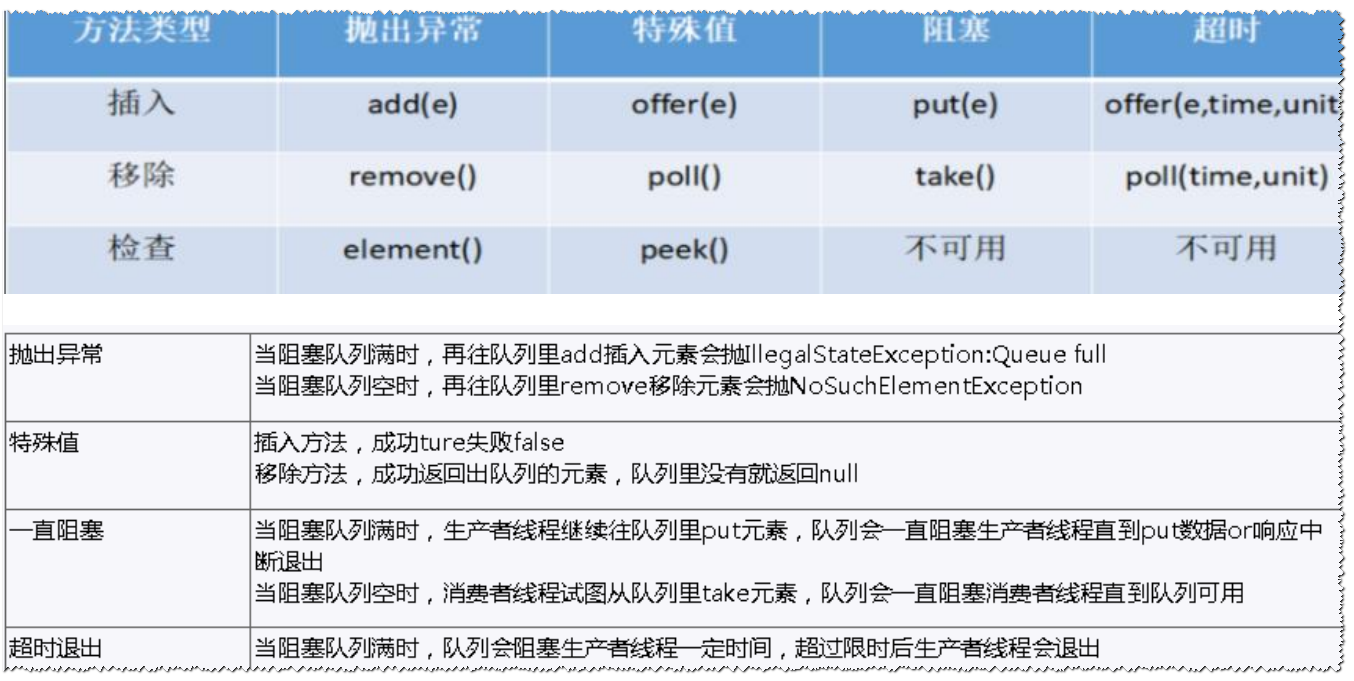
其他就不做介绍了,因为现在流行的消息中间件真的太多了
ThreadPool
线程池的种类
1:newCachedThreadPool
作用:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
特点:
-
线程池中数量没有固定,可达到最大值(Interger. MAX_VALUE)
-
线程池中的线程可进行缓存重复利用和回收(回收默认时间为 1 分钟)
-
当线程池中,没有可用线程,会重新创建一个线程
创建方式:ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
适用场景: 适用于创建一个可无限扩大的线程池,服务器负载压力较轻,执行时间较短,任务多的场景
2:newFixedThreadPool
作用:创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程
特点:
-
线程池中的线程处于一定的量,可以很好的控制线程的并发量
-
线程可以重复被使用,在显示关闭之前,都将一直存在
-
超出一定量的线程被提交时候需在队列中等待
创建方式:ExecutorService executorService = Executors.newFixedThreadPool(n);
适用场景: 适用于可以预测线程数量的业务中,或者服务器负载较重,对线程数有严格限制的场景
3: newSingleThreadExecutor
作用: 线程池中最多执行 1 个线程,以无界队列方式来运行该线程
创建方式:ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor()
适用场景: 适用于需要保证顺序执行各个任务,并且在任意时间点,不会同时有多个线程的场景
4:newScheduleThreadPool (了解即可)
作用:线程池支持定时以及周期性执行任务,创建一个 corePoolSize 为传入参数,最大线程数为整形的最大数的线程池
特点:
-
线程池中具有指定数量的线程,即便是空线程也将保留
-
可定时或者延迟执行线程活动
创建方式:ExecutorService cachedThreadPool = Executors.newScheduledThreadPool(n);
适用场景: 适用于需要多个后台线程执行周期任务的场景
5:newWorkStealingPool(jdk1.8引入)
作用:创建一个拥有多个任务队列的线程池,可以减少连接数,创建当前可用 cpu 核数的线程来并行执行任务
创建方式:ExecutorService cachedThreadPool = Executors.newWorkStealingPool();
适用场景: 适用于大耗时,可并行执行的场景
6:自定义线程池
创建方式:

特点:降低资源的消耗、提高响应速度、提高线程的可管理性
线程池底层工作原理
-
线程池创建,准备好core数量的核心线程,准备接受任务
-
core满了,就将再进来的任务放入阻塞队列中。空闲的core就会自己去阻塞队列获取任务
-
阻塞队列满了,就直接开新线程执行,最大只能开到max指定的数量
-
max满了就用 RejectedExecutionHandler handler 拒绝任务
-
max都执行完成,有很多空闲,在指定的时间 keepAliveTime 以后,释放 max - core 这些线程
-
new LinkedBlockingDeque<>():默认是 Integer 的最大值。会导致内存占满,需要根据自己的业务定
注意事项
上面我们说到了好几个创建线程池的方式方法,但是我们工作一般都是使用自定义的方式创建线程池
-
线程池使用的队列为Inteer.max_value,会导致OOM
-
阿里巴巴Java开发手册有相关规定,不允许使用Executors区创建线程池
CompletableFuture异步编排
可以使得我们的任务单独运行在与主线程分离的其他线程中,并且通过回调可以在主线程中得到异步任务的执行状态,是否完成,和是否异常等信息
Future和CompletionStage
CompletableFuture实现了两个接口:CompletableFuture<T> implements Future<T>, CompletionStage<T>
Future
-
先说Future,前面我们爷简单的了解过,下面我们再来串一下
-
继承Thread或者实现Runnable接口,根本不值得信任,在这里不在赘述
-
Future + Callable,能获取返回值,但获取异步响应会阻塞主线程
CompletionStage
-
代表异步计算过程中的某一个阶段,一个阶段完成以后可能会触发另外一个阶段
-
一个阶段的执行可能是被单个阶段的完成触发,也可能是由多个阶段一起触发
-
CompletionStage的接口方法的返回值一般都是新的CompletionStage , 以便于链式调用
CompletableFuture
-
实现了上面两个接口,通过整合扩展,提供的功能就是异步编排大杀器
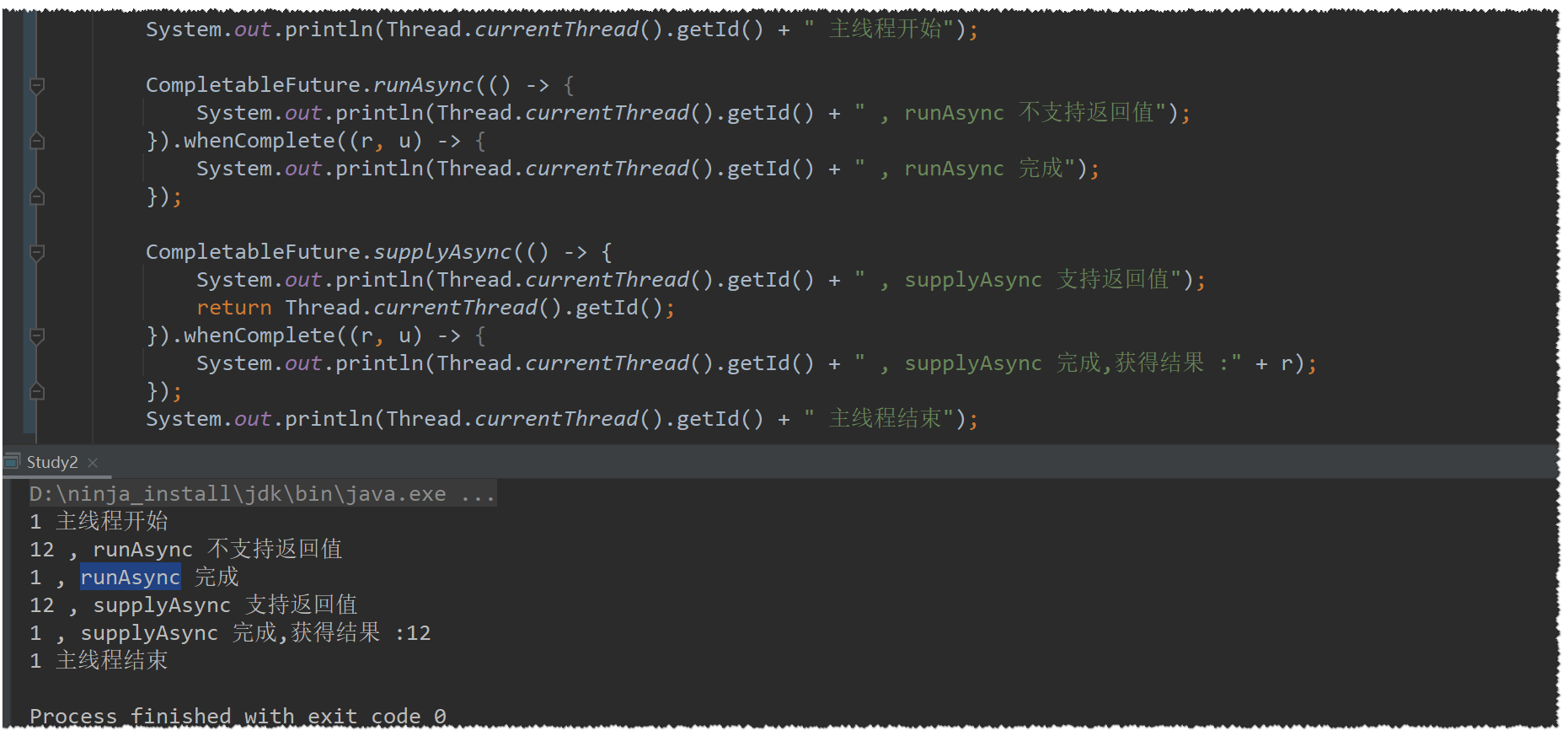
提交任务:runAsync / supplyAsync

有无返回值的异步任务
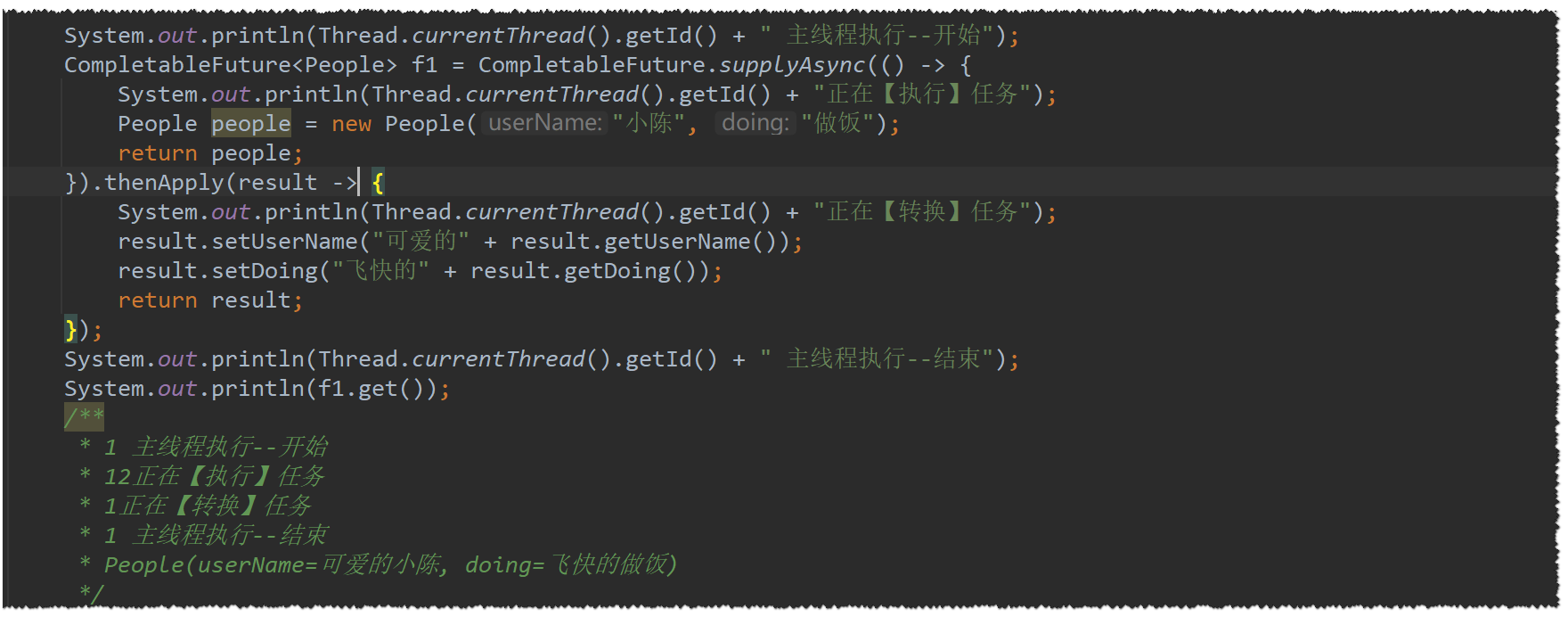
转换结果:thenApply
顾名思义:然后应用
什么意思呢?就是把上一个线程的结果应用于下一个线程的计算,并产生新的
CompletableFuture

-
首先我们来看看
thenApply ()-
初始化People的任务是由12 号线程完成的
-
转换People的任务是由主线程完成的
-
主线程是在转换任务结束后才结束的
-
所以,这个同步thenApply()方法,是与主线程保持串行同步执行
-
-
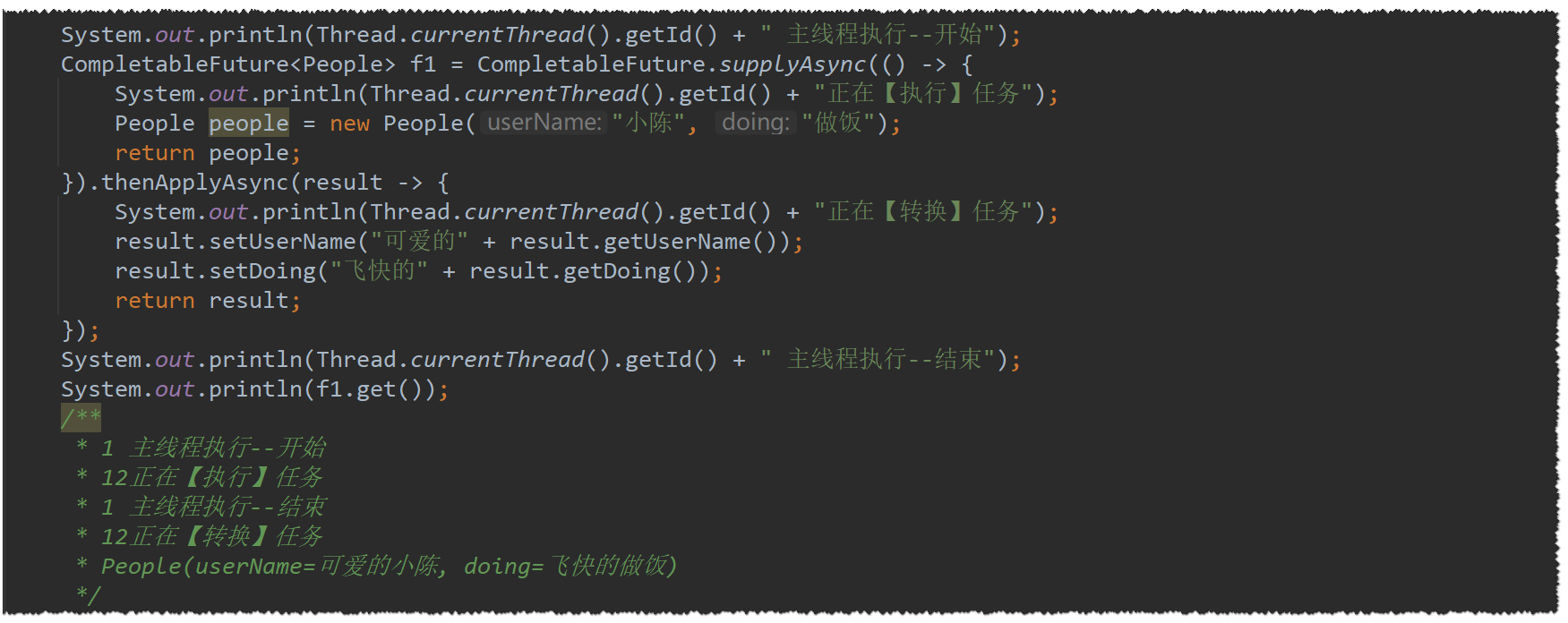
然后再来看看
thenApplyAsync(result)-
初始化People的任务是由12 号线程完成的
-
转换People的任务也是由12号线程完成的,12号线程来源于自带的
ForkJoinPool.commonPool -
主线程无阻塞直接结束
-
所以,这个同步thenApplyAsync( r )方法,是与主线程异步执行
-
-
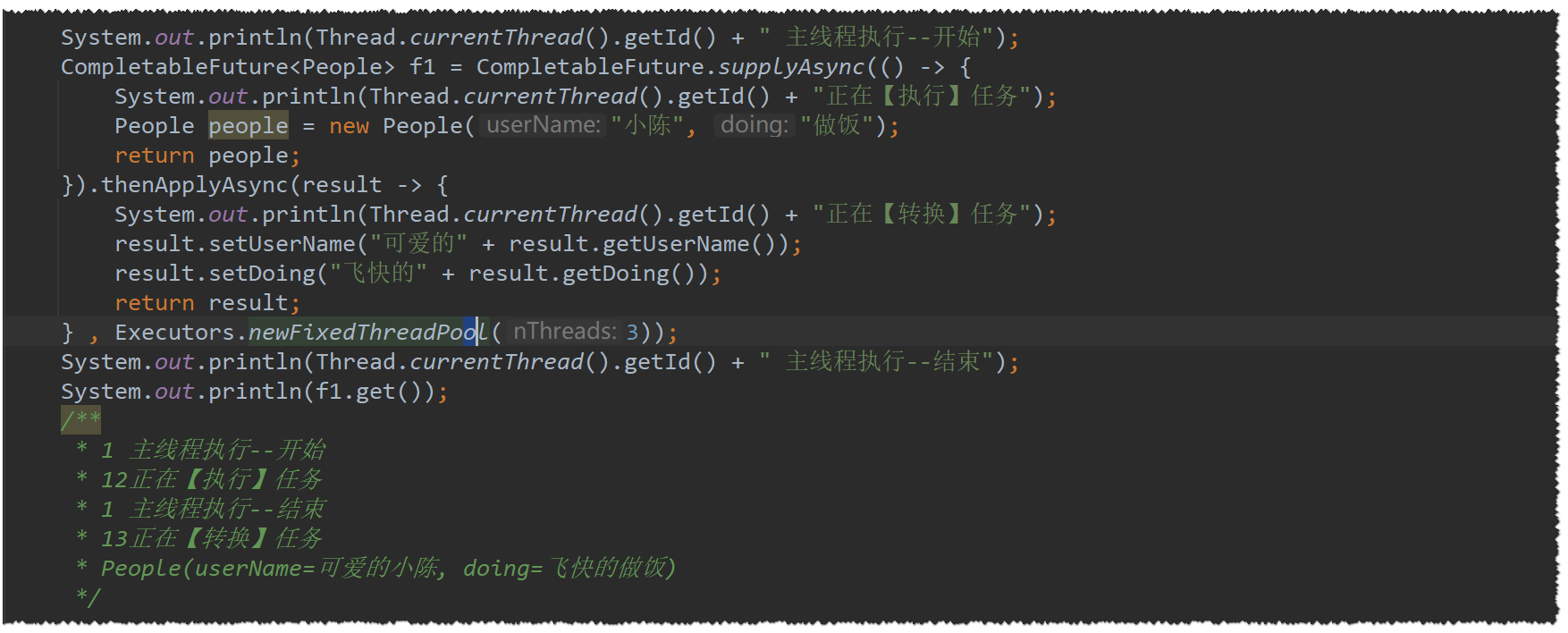
最后再来看看
thenApplyAsync(result , pool)-
初始化People的任务是由12 号线程完成的
-
转换People的任务也是由13 号线程完成的,13号线程来源于我们自定义的 new FixedThreadPool(3)线程池
-
主线程无阻塞直接结束
-
所以,这个同步thenApplyAsync( r ,pool)方法,是与主线程异步执行
-
消费结果:thenAccept
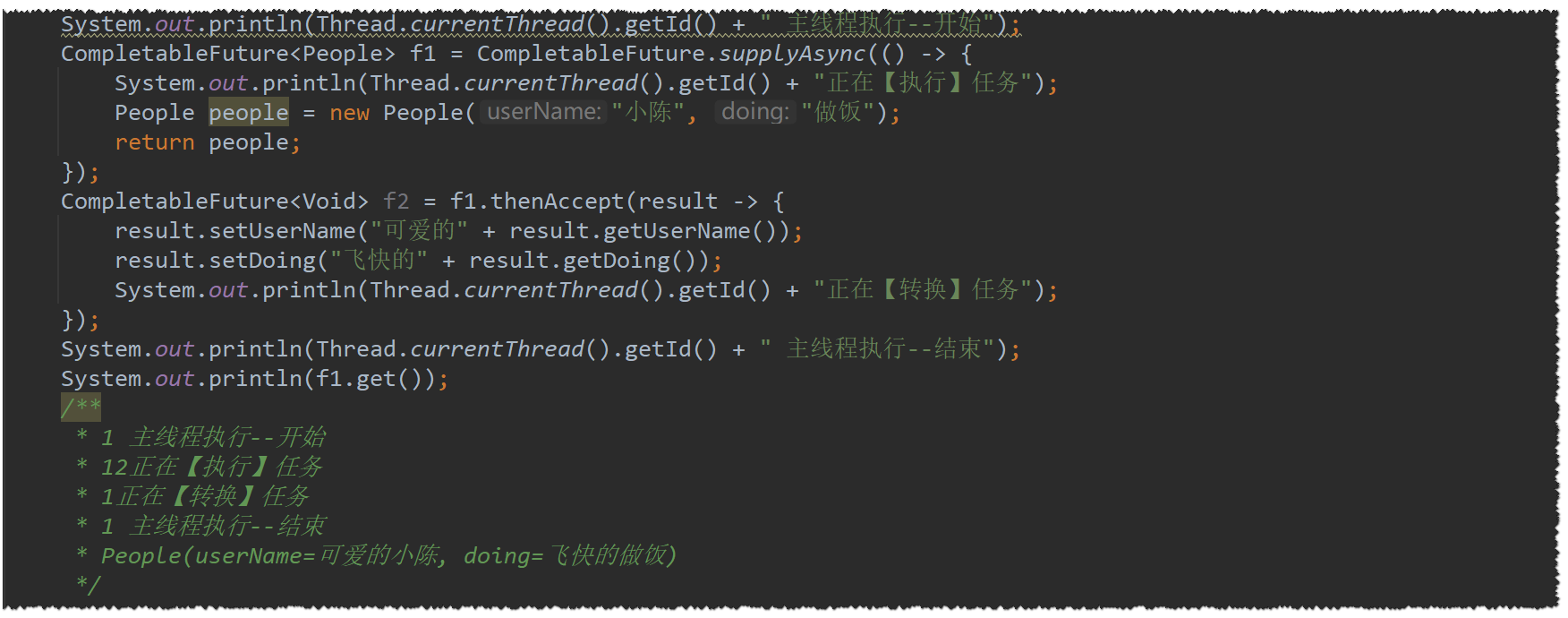
-
同步异步大致上和thenApply()的使用都是一样的,其他的区别主要在于
-
回调函数没有返回值
-
任务完成后触发的回调:thenRun
-
同步异步大致上和thenApply()的使用都是一样的,其他的区别主要在于
-
没有入参,也没有返回值
-
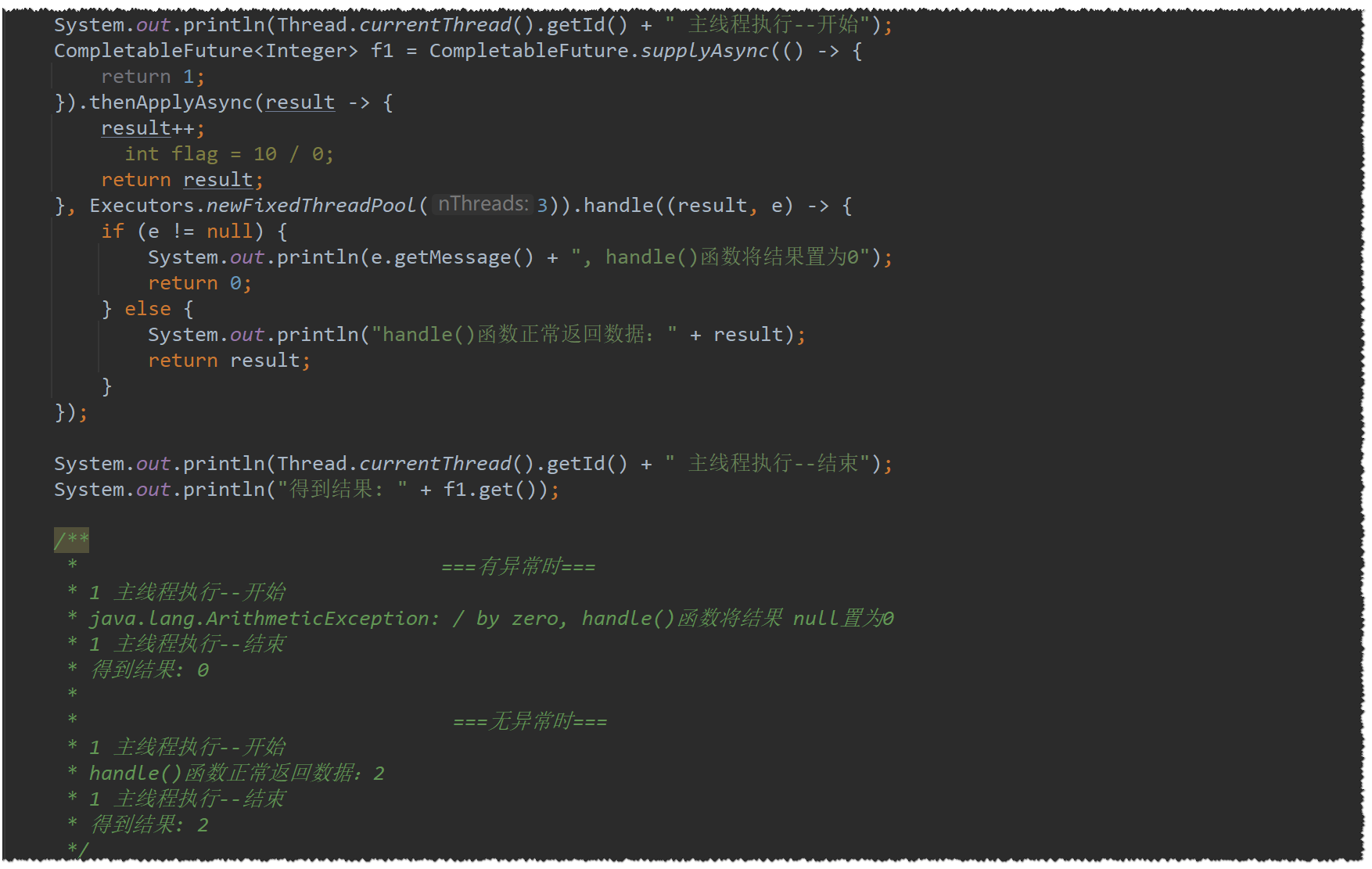
异常监控:handle / exceptionally / whenComplete
handle(result , e):不会外抛异常,可返回结果,无论如何都会执行
-
当然也支持同步/异步、默认/指定线程池执行哦
-
和thenApply的区别在于:是否监管异常,thenApply遇到异常会抛出,他会将异常吃掉
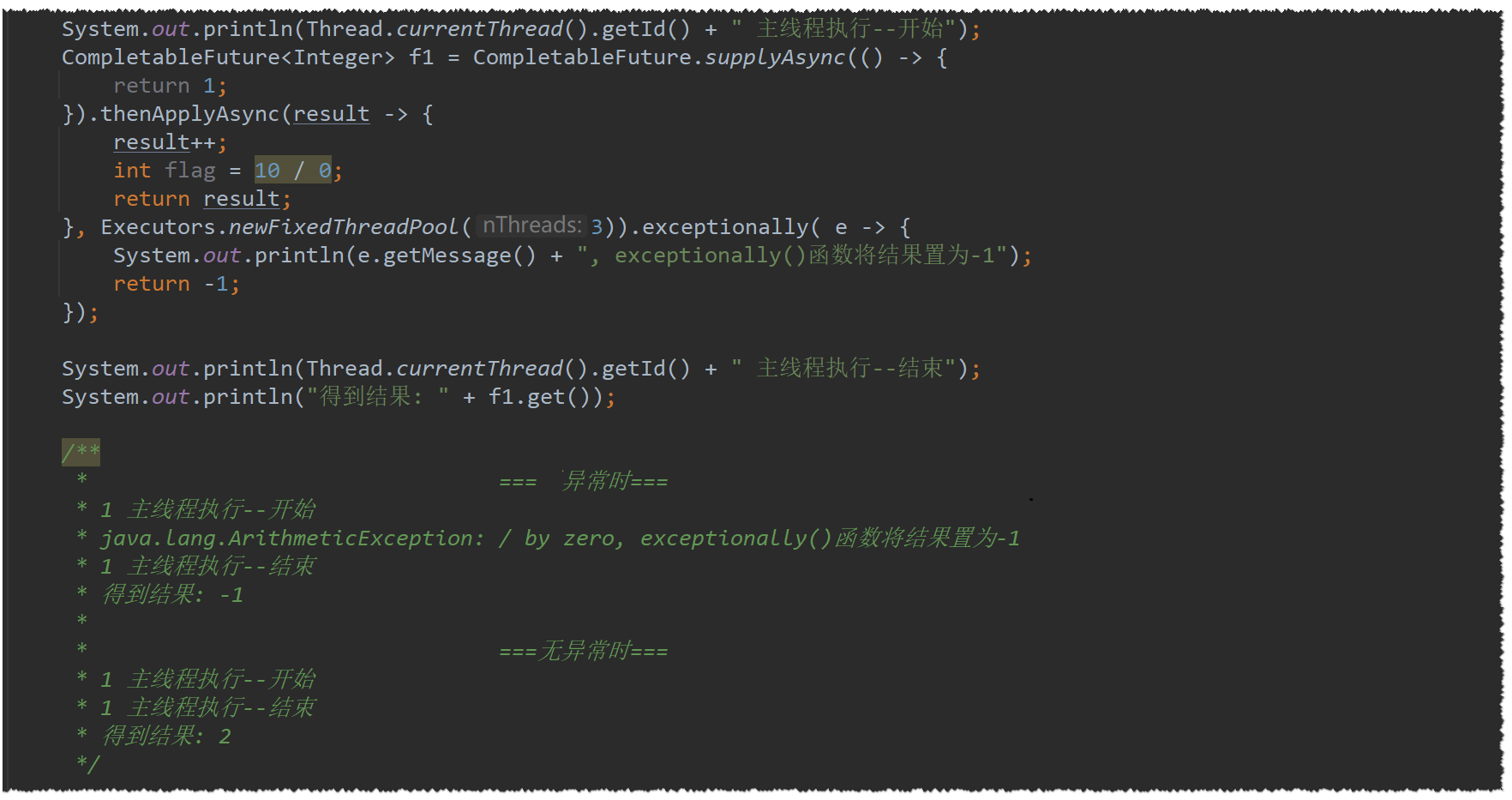
exceptionally(e) :不会外抛异常,可返回结果,只有发生异常时才会执行
-
只能主线程执行,无异步版本(12版本好像有了,之前的无)
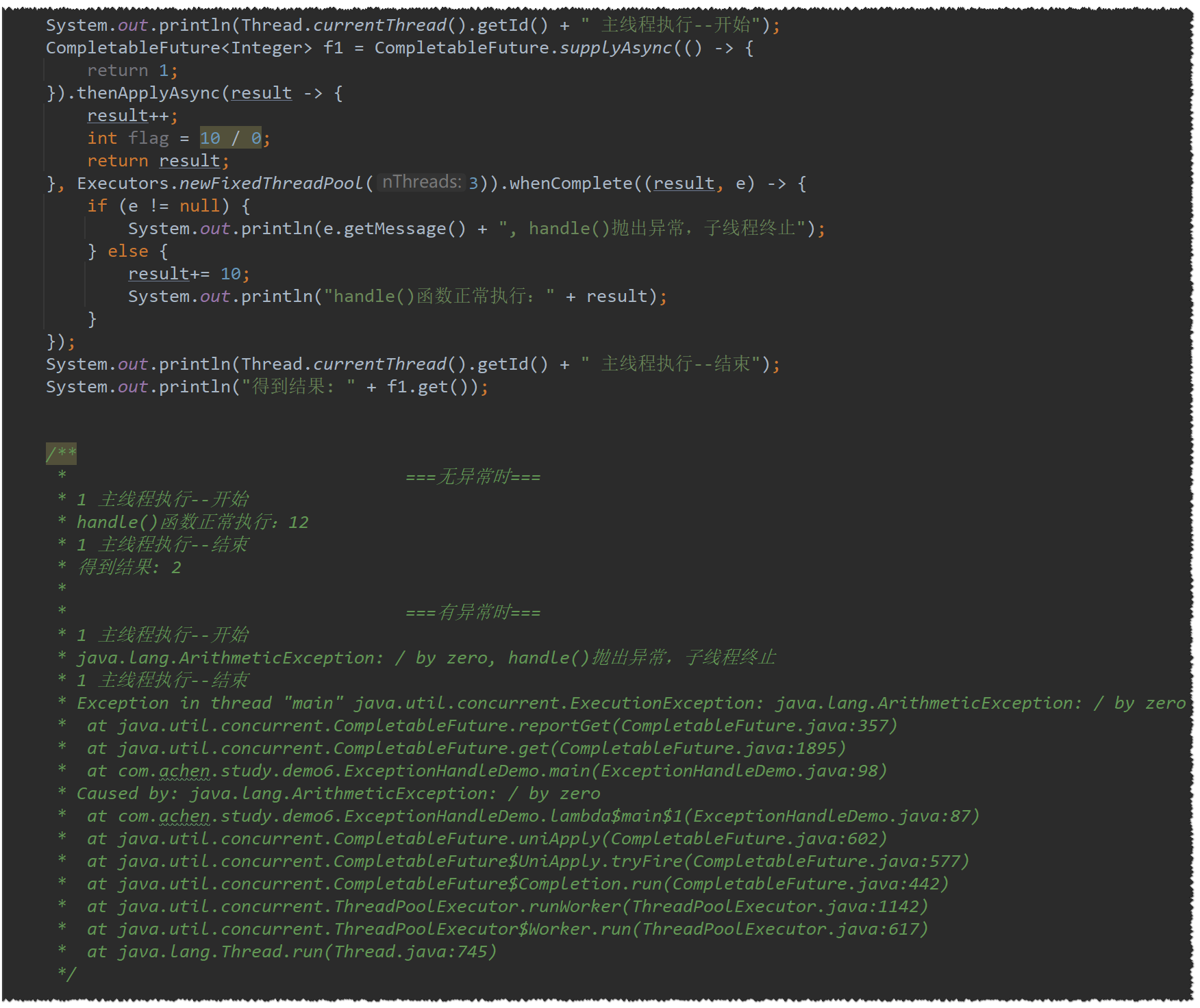
whenComplete(result , e):会外抛异常,没有返回值,无论如何都会执行
-
支持同步/异步、默认/指定线程池执行
and关系:thenCombine / thenAcceptBoth / runAfterBoth
-
将两个CompletableFuture组合起来,只有这两个都正常执行完了才会执行某个任务
thenCombine
-
thenCombine会将两个任务的执行结果作为方法入参传递到指定方法中,且该方法有返回值

thenAcceptBoth
-
thenAcceptBoth同样将两个任务的执行结果作为方法入参,但是无返回值
runAfterBoth
-
runAfterBoth没有入参,也没有返回值
or关系:applyToEither / acceptEither / runAfterEither
-
将两个CompletableFuture组合起来,只要有一个正常执行完了才会执行某个任务
applyToEither
-
applyToEither会将已经执行完成的任务的执行结果作为方法入参,并有返回值
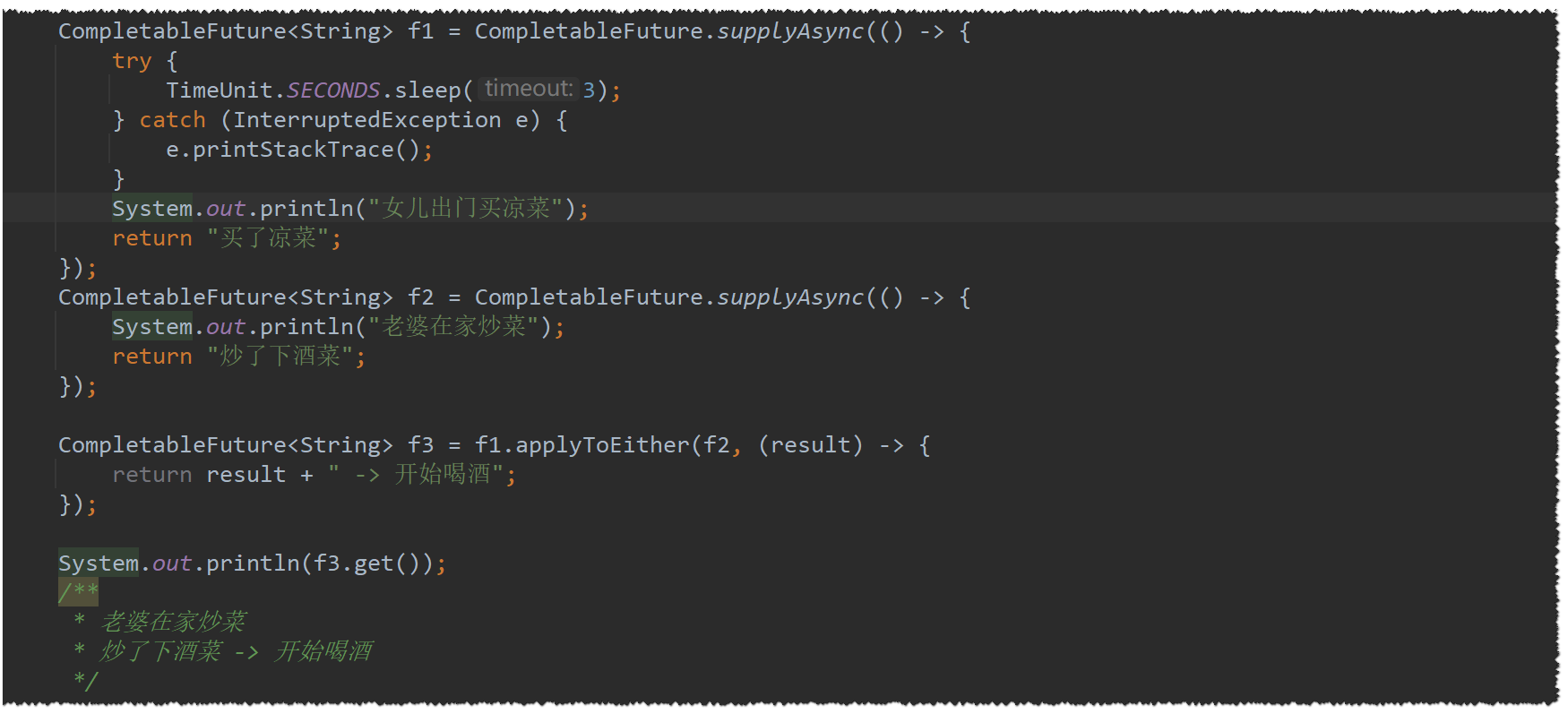
acceptEither
-
acceptEither同样将已经执行完成的任务的执行结果作为方法入参,但是没有返回值
runAfterEither
-
runAfterEither没有方法入参,也没有返回值
allOf / anyOf
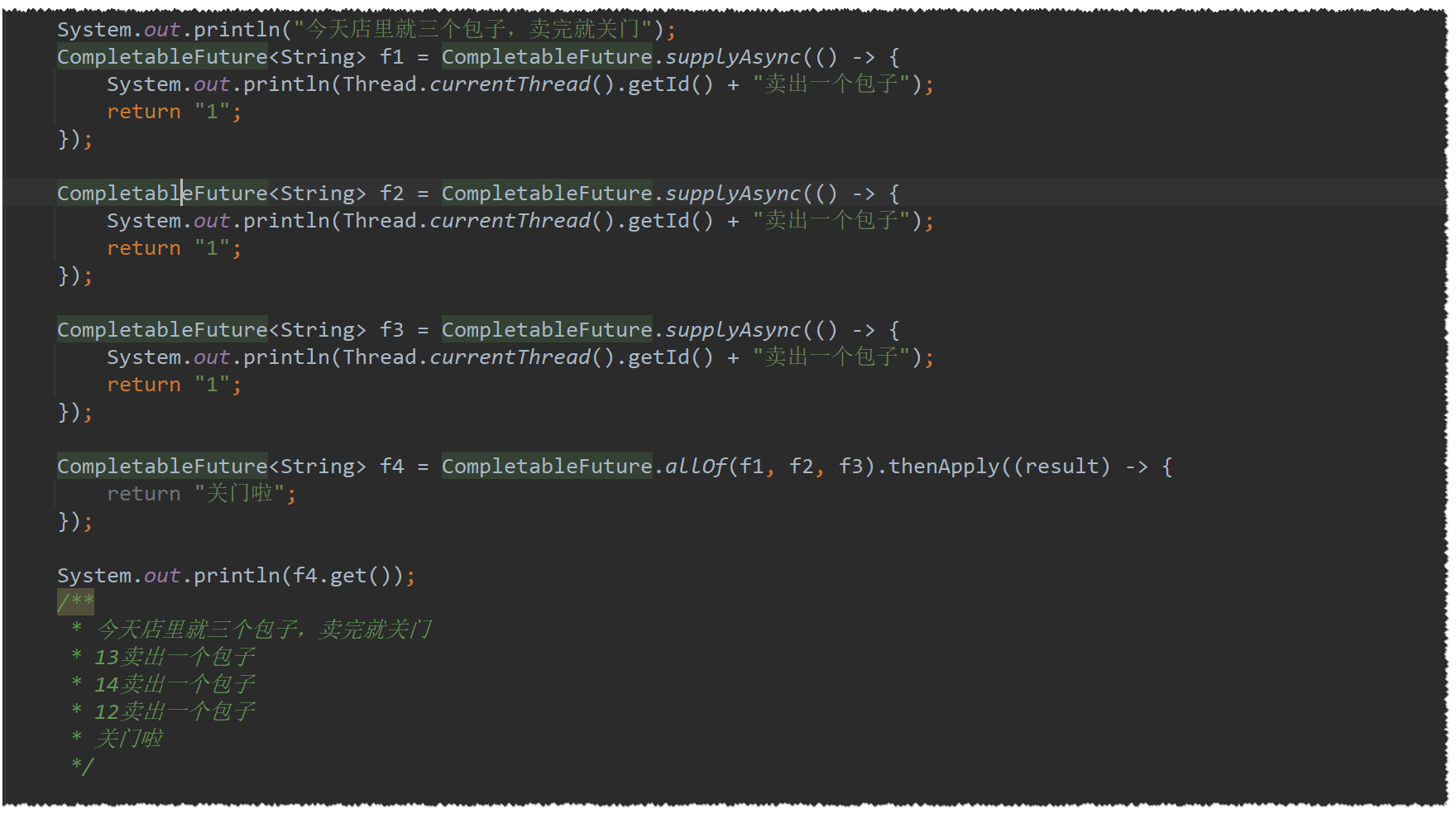
allOf
-
所有任务执行完才执行
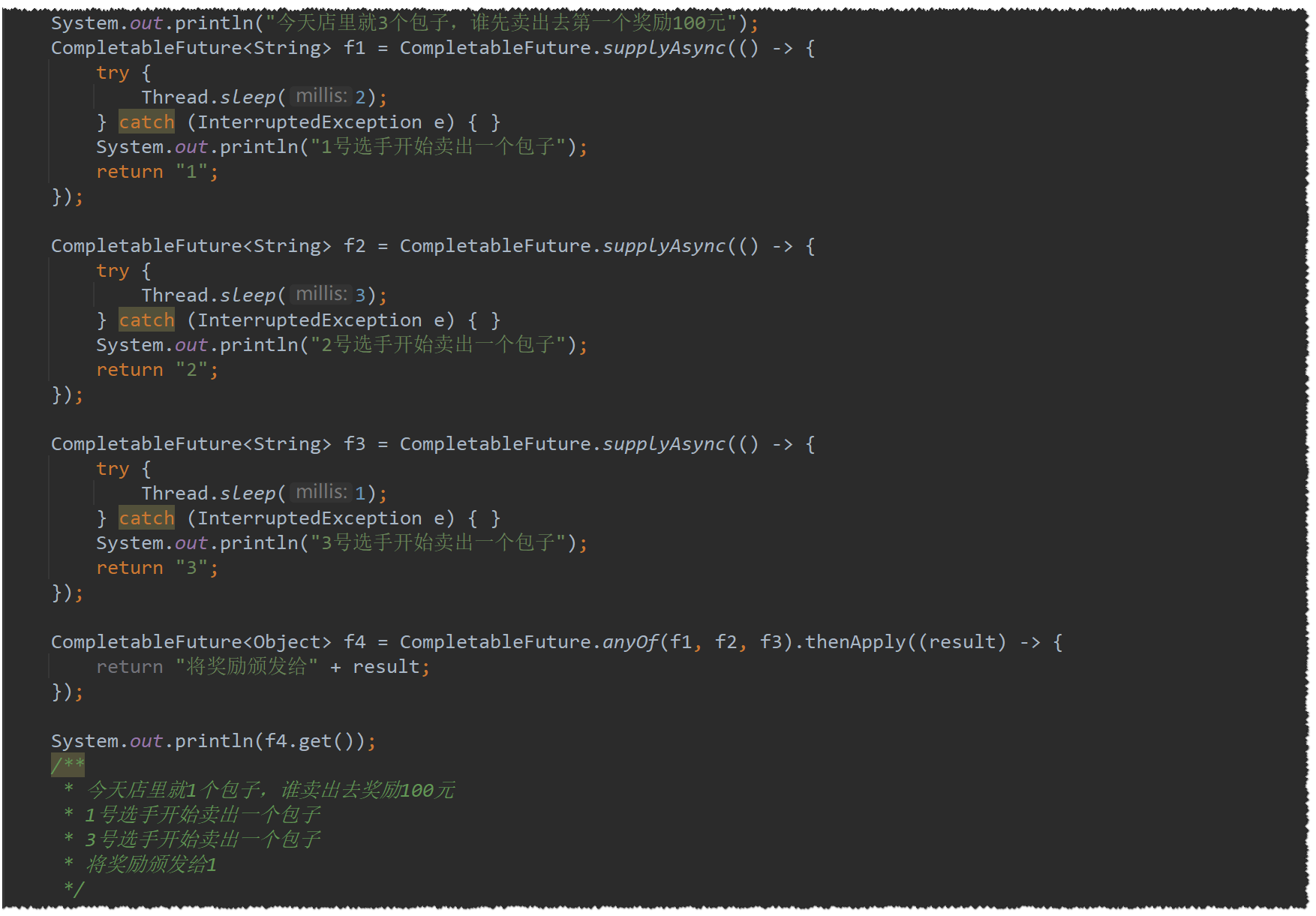
anyOf
-
任一任务执行完就执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号