Redis数据类型使用场景以及Redis高级用法
Redis基本数据类型使用场景
String 字符类型
-
set key value / get key
-
mset k1 v1 k2 v2 k3 v3 / mget k1 k2 k3 #同时设置多个kv / 同时获取多个key的值
-
getset k1 v2 #先取值再设置值
-
incr key num / incyby key num
缓存、共享Session、计数器
List列表类型
-
lpush key v1 v2 v3 / rpush key v1 v2 v3 #从列表左 / 右添加元素
-
lrange key start stop #查看列表某个区间的所有元素,索引从0开始
-
lpop key / rpop key #左 / 右 弹出一个元素(先移除再返回)
-
llen key :获取列表中元素的个数
好友列表、粉丝列表、评论列表、基于lrange的快速分页
Hash散列类型
-
hset key field value / hmset key field value field2 value2 #一次设置单个/多个值
-
hget key field / hmget key field1 field2... #一次获取单个/多个值
-
hgetall key #获取所有字段值
-
hsetnx key field value #当field不存在时,插入值,当其存在时,不做操作
-
hdel key field1 field2 #删除单个/多个字段
-
hincrby key field num #增加数字num 比如购物车中的购买数量
-
hkeys key / hvals key : 只获取字段名 / 字段值
-
hgetall key #获取所有字段
秒杀库存、爆款商品、购物车
Set集合类型
-
add key v1 v2 v3 #添加元素
-
srem key v1 v2 #删除指定元素
-
smembers key #获取集合中的所有的元素
-
sismember key v1 #判断元素是否在集合中
-
sdiff setA setB #求差集,属于setA 不属于setB的元素
-
sinter setA setB #求交集,属于setA 和setB的交集部分
-
sunion setA setB #求并集,setA 和 setB的并集
-
scard setA #获取集合中元素的个数
-
spop setA #因为储存是无序的,所以是随机弹出一个元素
统一去重、差集(你可能认识)、并集(共同好友)
Zset有序集合
-
zadd key 分数 元素 #比如:zadd stu 80 english :添加一个元素到有序集合,:英语元素 80分
-
zrange key start stop #按照元素分数从小到大,获得排名在某个范围的元素列表
-
zrevrange key start stop #按照元素分数从大到小,获得排名在某个范围的元素
-
withscores #跟在上面两种语法后,可以把元素的分数一并显示出来
-
zscore key 元素 #获取元素的分数
-
zrem key 元素 #删除元素
-
zincrby key num field #为field元素增加分数 num
-
zcard key #获得集合中元素的数量
-
zcount key min max #获取指定分数范围内的元素的个数
-
zremrangebyrank key start stop #按照排名范围删除元素
-
zremrangebyscoe key min max #按照分数范围删除元素
-
zrank / zrevrank key 元素 #从小->大 / 大->小获取元素的的排名
排行榜、热搜
Redis的特殊数据类型使用场景
BitMap
-
BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态,
-
其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现
-
setbit key offset value
-
offset 必须是数字,value 只能是 0 或者 1
-
该命令返回修改前的值,bit的默认值都是0
-
setbit test1 1 1
setbit test1 3 1
setbit test2 3 1
setbit test2 5 1
getbit test1 3
bitcount test2 # 统计test2里面有多少个状态为1,比传统数据库统计快很多

-
统计年活跃用户数量
将用户ID当作offset,如果一年内用户登录过网站,就将value的bit值设置为1
然后使用bitcount key,获取统计数据
-
更多用法各种统计
BITOP AND destkey key [key ...],对一个或多个key求逻辑并,并将结果保存到destkey。
用天数标识作为key,用户ID作为offset
你想连续几天就几天登陆的用户统计数据
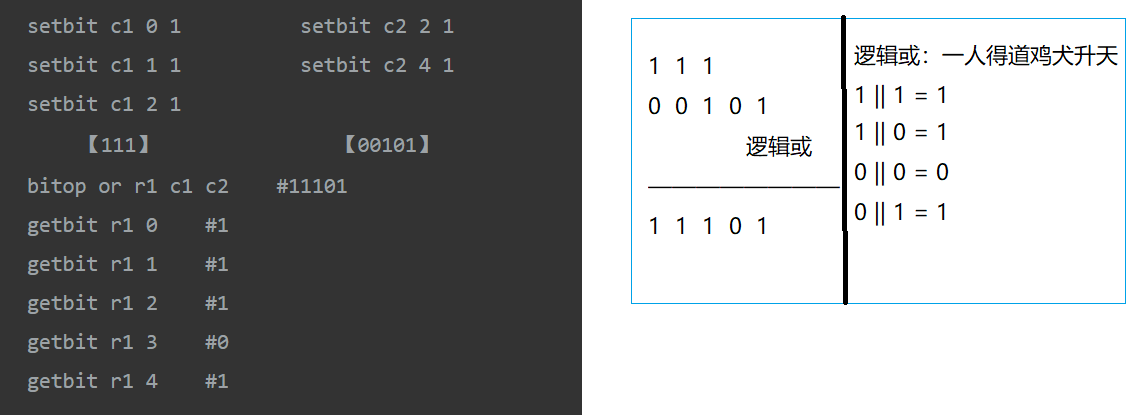
BITOP OR destkey key [key ...],对一个或多个key求逻辑或,并将结果保存到destkey。
以时间字符串作为key,比如 “200522:active“ ,用户的ID就可以作为offset
你想统计几天的数据你说了算,只需要将全部时间key做逻辑或操作
然后使用bitcount即可算出总人数
BITOP XOR destkey key [key ...],对一个或多个key求逻辑异或,并将结果保存到destkey。
两个不同就为真
BITOP NOT destkey key,对给定key求逻辑非,并将结果保存到destkey。
指本来值的反值
这个可以用来统计多久几天内没有访问的数量
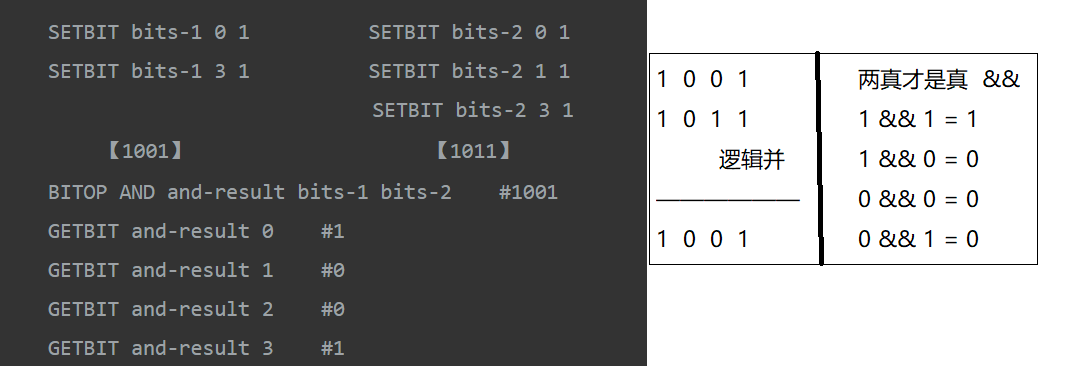
bitmap的优势,以统计活跃用户为例
-
每个用户id占用空间为1bit,消耗内存非常少,存储1亿用户量只需要12.5M
HyperLogLog
-
基于bitmap 计数
-
基于概率基数计数
这个数据结构的命令有三个:pfadd、pfcount、pfmerge
用途:记录网站IP注册数,每日访问的IP数,页面实时UV、在线用户人数
局限性:只能统计数量,没有办法看具体信息
-
pfadd h1 1
-
pfadd h1 2
-
pfadd h1 2
-
pfadd h1 3
-
pfadd h2 1
-
pfadd h2 4
-
pfcount h1 # 3 [1、2、3]
-
pfmerge h1 h2 # 去重后归纳到h1
-
pfcount h1 # 4 [1、2、3、4]
Geospatial (3.2)
-
可以用来保存地理位置,并作位置距离计算或者根据半径计算位置等
-
有没有想过用Redis来实现附近的人?或者计算最优地图路径
-
它本质上还是借助于Sorted Set(ZSET)
GEOADD key 经度 维度 名称
-
把某个具体的位置信息(经度,纬度,名称)添加到指定的key中,数据将会用一个sorted set存储
-
以便稍后能使用GEORADIUS和GEORADIUSBYMEMBER命令来根据半径来查询位置信息
-

Redis的消息模式
队列模式
-
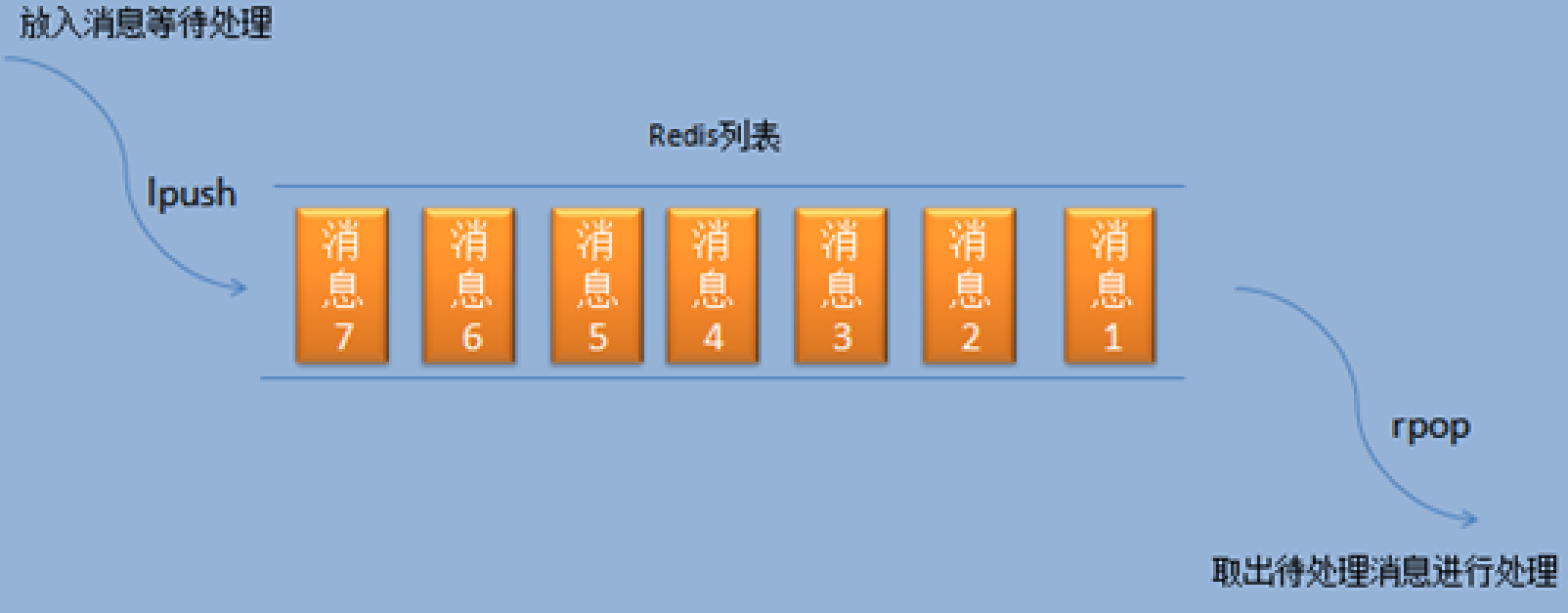
使用list类型的lpush和rpop实现消息队列
-
消息接收方如果不知道队列中是否有消息,会一直发送rpop命令,如果这样的话,会每一次都建立一次连接,这样显然不好
-
可以使用brpop命令,它如果从队列中取不出来数据,会一直阻塞,在一定范围内没有取出则返回null
发布订阅模式
-
对比RabitMQ或者RocketMQ再或者Kafka
-
生产者 - 中间件暂存 - 消费者
-
只要是通过Redis Stream实现,详见下面
Redis Stream(5.0)
-
Redis 5.0 全新的数据类型:streams
-
streams支持多个客户端(消费者)等待数据(Linux环境开多个窗口执行XREAD即可模拟),
-
并且每个客户端得到的是完全相同的数据。
-
这个功能有点类似于redis以前的Pub/Sub,但是也有基本的不同
-
Pub/Sub是发送忘记的方式,并且不存储任何数据
-
而streams模式下,所有消息被无限期追加在streams中,除非用于显示执行删除(XDEL)
-
-
streams的Consumer Groups也是Pub/Sub无法实现的控制方式
-
Stream由 :消息、生产者、消费者、消费组 组成
-
一系列的阻塞操作允许消费者等待生产者加入到streams的新数据
-
另外还有一个称为Consumer Groups的概念,允许一组客户端协调消费相同的信息流
-
-
发布消息
-
xadd mystream * message apple xadd mystream * message orange
-
-
读取消息
-
xrange mystream - +
-
-
阻塞读取:没有消息处于阻塞状态,知道拿到信息并消费结束阻塞状态
-
xread block 0 streams mystream $
-
-
再次发布消息,看阻塞读取的窗口
-
xadd mystream * message strawberry
-
-
消费组的创建(两个)
-
xgroup create mystream mygroup1 0 xgroup create mystream mygroup2 0
-
-
通过消费组读取消息
-
xreadgroup group mygroup1 zhangsan count 2 streams mystream > xreadgroup group mygroup1 lisi count 2 streams mystream > xreadgroup group mygroup2 wangwu count 1 streams mystream >
-
只是模拟一下用法,至于更详细的使用请见官方文档,一般发布订阅模式,我们都是使用MQ或者Kafka来实现
Redis事物
Redis事物说明
-
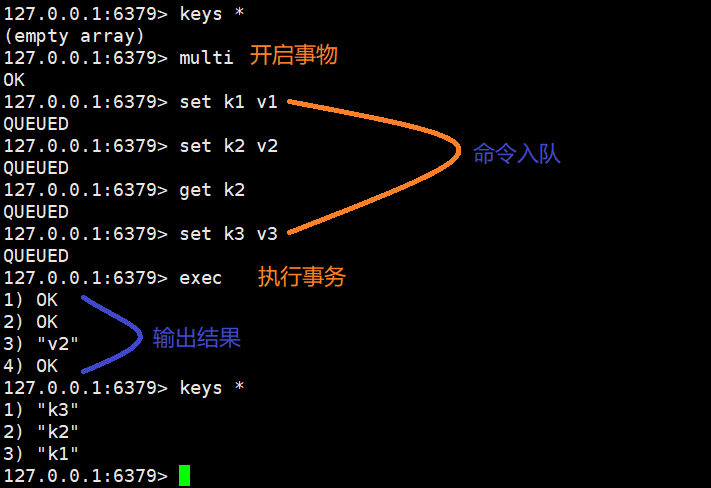
redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
-
但是批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,
-
也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到。
-
-
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚
-
事务中任意命令执行失败,其余的命令仍会被执行。
-
-
Redis事务的三个阶段:
-
开始事务
-
命令入队
-
执行事务
-
-
Redis失误相关的命令
-
multi :标记一个事物块的开始
-
exec :执行所有事务块的命令( 一旦执行exec后,之前加的监控锁都会被取消掉)
-
discard :取消事务,放弃事务块中的所有命令
-
watch key1 key2 ... :监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则事务被打断 ( 类似乐观锁 )
-
unwatch :取消watch对所有key的监控
-
正常流程
不正常演示
-
放弃事物:discard
-
开启事物 -- > 命令入队 --> 取消事物 【所有入队指令无效】
-
-
语法错误
-
开启事物 --> 命令入队 (命令错误) --> 执行事物 【所有入队指令无效】
-
-
运行错误
-
开启事物 --> 命令入队 (运行错误,incr k1 (k1的值是v1) ) --> 执行事物 【正确指令执行,错误指令将错误提示抛出】
-
-
监控
-
watch key --> 开启事物 --> 命令入队 --> 执行事物 [如果key在开启事物后,被其他客户端更改,则改事物块无效]
-
比如A线程监控了key,然后开启了事物,此时B线程对该key进行了操作指令,然后A线程的实物块无效
-
Redis乐观锁
-
乐观锁。具体思路如下:
-
利用redis的watch功能,监控这个redisKey的状态值
-
获取redisKey的值
-
创建redis事务
-
给这个key的值+1
-
然后去执行这个事务,如果key的值被修改过则回滚,key不加1
-
public void watch() { try { String watchKeys = "watchKeys"; jedis.set(watchKeys, 1);//初始值 value=1 jedis.watch(watchkeys);//监听key为watchKeys的值 Transaction tx = jedis.multi();//开启事务 tx.incr(watchKeys);//watchKeys自增加一 List<Object> exec = tx.exec();// 执行事务,如果其他线程对watchKeys中的value进行修改,则该事务将不会执行 if (exec == null) { System.out.println("事务未执行"); } else { System.out.println("事务成功执行,watchKeys的value成功修改"); } } catch (Exception e) { e.printStackTrace(); } finally { jedis.close(); } }
Redis乐观锁实现秒杀
public static void main(String[] arg) { String redisKey = "second"; ExecutorService executorService = Executors.newFixedThreadPool(20); try { Jedis jedis = new Jedis("127.0.0.1", 6378); jedis.set(redisKey, "0");// 初始值 jedis.close(); } catch (Exception e) { e.printStackTrace(); } for (int i = 0; i < 1000; i++) { executorService.execute(() -> { Jedis jedis1 = new Jedis("127.0.0.1", 6378); try { jedis1.watch(redisKey); String redisValue = jedis1.get(redisKey); int valInteger = Integer.valueOf(redisValue); String userInfo = UUID.randomUUID().toString(); if (valInteger < 20) { //只有20个秒杀名额 Transaction tx = jedis1.multi(); tx.incr(redisKey); List list = tx.exec(); // 秒杀成功 失败返回空list而不是空 if (list != null && list.size() > 0) { System.out.println("用户:" + userInfo + ",秒杀成功!当前成功人数:" + (valInteger + 1)); }else { // 版本变化,被别人抢了。 System.out.println("用户:" + userInfo + ",秒杀失败"); } }else { // 秒完了 System.out.println("已经有20人秒杀成功,秒杀结束"); } } catch (Exception e) { e.printStackTrace(); } finally { jedis1.close(); } }); } executorService.shutdown(); }
-
但是这种方式由于Redis的原子性不能得到保证,所以不是很完美
-
下面我们将整合Lua,使得程序更加完善
Redis和lua整合
Lua简单介绍
-
lua是一种轻量小巧的脚本语言,用标准C语言编写
-
其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能
-
Redis中使用Lua的好处
-
减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行
-
原子操作,redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。
-
换句话说,编写脚本的过程中无需担心会出现竞态条件
-
-
复用性,客户端发送的脚本会永远存储在redis中
-
这意味着其他客户端可以复用这一脚本来完成同样的逻辑
-
在redis客户端中,执行以下命令:
EVAL script numkeys key [key ...] arg [arg ...]
-
script:是一段Lua脚本程序,它会被运行在Redis服务器上下文中,这段脚本不必(也不应该)定义为一个Lua函数
-
numkeys:用于指定键名参数的个数。
-
key [key ...]:从EVAL的第三个参数开始算起,使用了numkeys个键(key),
-
表示在脚本中所用到的那些Redis键(key),
-
这些键名参数可以在Lua中通过全局变量KEYS数组,用1为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)
-
-
arg [arg ...]:可以在Lua中通过全局变量ARGV数组访问,访问的形式和KEYS变量类似(ARGV[1] 、 ARGV[2] ,诸如此类)。
-
比如
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second 1) "key1" 2) "key2" 3) "first" 4) "second"
Lua脚本调用Redis命令
-
redis.call(); 一般使用这个,保证原子性
-
返回值就是redis命令执行的返回值
-
如果出错,返回错误信息,不继续执行
-
-
redis.pcall();
-
返回值就是redis命令执行的返回值
-
如果出错了 记录错误信息,继续执行
-
注意:在脚本中,使用return语句将返回值返回给客户端,如果没有return,则返回nil
redis-cli --eval
-
可以使用redis-cli --eval命令指定一个lua脚本文件去执行
-
脚本文件(redis.lua),内容如下
local num = redis.call('GET', KEYS[1]); if not num then return 0; else local res = num * ARGV[1]; redis.call('SET',KEYS[1], res); return res; end
-
在redis客户机,执行脚本命令
[root@localhost bin]# ./redis-cli --eval redis.lua lua:incrbyml,8 // 0 * 8 (integer) 0 [root@localhost bin]# ./redis-cli incr lua:incrbyml //在这里将Redis的lua:incrbyml变成了1 (integer) 1 [root@localhost bin]# ./redis-cli --eval redis.lua lua:incrbyml,8 // 1 * 8 (integer) 8 [root@localhost bin]# ./redis-cli --eval redis.lua lua:incrbyml,8 // 8 * 8 (integer) 64 [root@localhost bin]# ./redis-cli --eval redis.lua lua:incrbyml,2 //64 * 2 (integer) 128 [root@localhost bin]# ./redis-cli
-
参数解读
-
--eval:告诉redis客户端去执行后面的lua脚本
-
redis.lua:具体的lua脚本文件名称
-
lua:incrbymul : lua脚本中需要的key
-
8:lua脚本中需要的value
-
-
注意:
-
命令中keys和values中间需要使用逗号隔开,并且逗号两边都要有空格
-
Redis + lua 秒杀
-
秒杀场景经常使用这个东西,主要利用他的原子性
-
首先定义Redis的数据结构,Hash,分别为总库存,以及以抢数量,抢购名额为:total - released
-
商品Id :{total:100,released:0}
-
编写Lua脚本
local n = tonumber(ARGV[1]) if not n or n == 0 then return 0 end local vals = redis.call("HMGET", KEYS[1], "total", "released"); local total = tonumber(vals[1]) local blocked = tonumber(vals[2]) if not total or not blocked then return 0 end if blocked + n <= total then redis.call("HINCRBY", KEYS[1], "released", n) return n; end return 0
-
将ARGV[1]转换为数字
-
如果不存在或者为0,则返回0,并退出程序
-
如果存在则开始执行命令:hmget key field1 field2
-
讲商品总量和已抢数量转化为数字
-
如果这两个数字不存在,则返回0,并结束程序
-
如果该两个数字存在,则判断已抢数量+ 当前抢购数量 < 商品总量
-
如果成立,则开始执行 hincrby key released n,为released增加n个已抢数量
-
并返回当前抢购的数量n,结束程序
执行脚本命令:ecal script_string 1 商品ID 抢购数量
ARGV[1] 就会得到抢购数量
KEYS[1]就会得到商品key
-
若库存足够则返回申请的数量,否则返回0,不返回可满足的剩余数
面临的问题
-
至于如何保证Redis和数据库数据一致性的问题
-
暂时考虑不全,以后补充
-
Redis分布式锁
面对的业务场景
-
库存超卖
-
用户重复下单
-
MQ消息去重
-
订单操作变更
问题分析
-
共享资源竞争 :用户id、订单id、商品id ......
-
解决方案 :共享资源互斥 、共享资源串行化
-
问题转化: 锁的问题
-
单进程多线程中使用锁
-
使用synchronize、ReentrantLock
-
-
多进程多线程(分布式应用)
-
分布式锁是控制分布式系统之间同步访问共享资源的一种方式
-
分布式锁特点
-
客户端通过竞争获取锁才能对共享资源进行操作(①获取锁);
-
当持有锁的客户端对共享资源进行操作时(②占有锁)
-
其他客户端都不可以对这个资源进行操作(③阻塞)
-
直到持有锁的客户端完成操作(④释放锁);
Redis分布式锁特性
-
互斥性
-
在任意时刻,只有一个客户端可以持有锁(排他性 )
-
-
高可用,具有容错性
-
只要锁服务集群中的大部分节点正常运行,客户端就可以进行加锁解锁操作
-
-
避免死锁
-
具备锁失效机制,锁在一段时间之后一定会释放。(正常释放或超时释放)
-
-
加锁和解锁为同一个客户端
-
一个客户端不能释放其他客户端加的锁了
-
拓展:实现分布式锁的方式
-
基于数据库实现分布式锁(悲观锁、乐观锁)
-
数据量小的情况下适用
-
-
基于ZK时节点的分布式锁
-
基于Redis的分布式锁
-
给予Etcd的分布式锁
获取/释放锁的版本迭代
Redis获取锁V1版本

-
setnx key value
-
设置key的值为value,key不存在则设置成功返回1,key若存在则设置失败返回0
-
在设置了锁了为锁设置了有效时间,过期自动释放
-
问题所在
-
如果程序在获取锁成功之后,没进入到设置过期时间哪里就崩掉了
-
这个锁的释放改由谁来完成,故该版本有缺陷
-
改进方向:上锁和设置过期时间应该是原子操作才对
Redis获取锁V2版本

-
使用lua脚本保证V1版本之后的原子性问题
-
可用版本之一,但是不完善,上锁时间固定,不可能每个锁的业务时间都设置一样长吧
Redis获取锁V3版本

-
set key value nx px expireTime
-
set key value nx px 10000
-
设置key的值为valuem并设置10S的有效期,key不存在设置成功返回1,否则失败
-
-
可用版本之一,但是不完善,上锁时间固定,不可能每个锁的业务时间都设置一样长吧
Redis释放锁V1版本
-
思考一下,单单使用del key 可以按成锁的释放吗?
-
加入A线称得到了锁,设置了30秒的有效期
-
A的业务有点复杂,30秒过去了,锁自动释放了,A线程还在业务流转
-
锁释放后线程B拿到了锁,也设置了30秒的有效期
-
A线程业务流转完毕,执行释放锁操作del,把B线程上的锁给释放了
-
多线程情况下,分布式锁直接失效
-
Redis释放锁V2版本
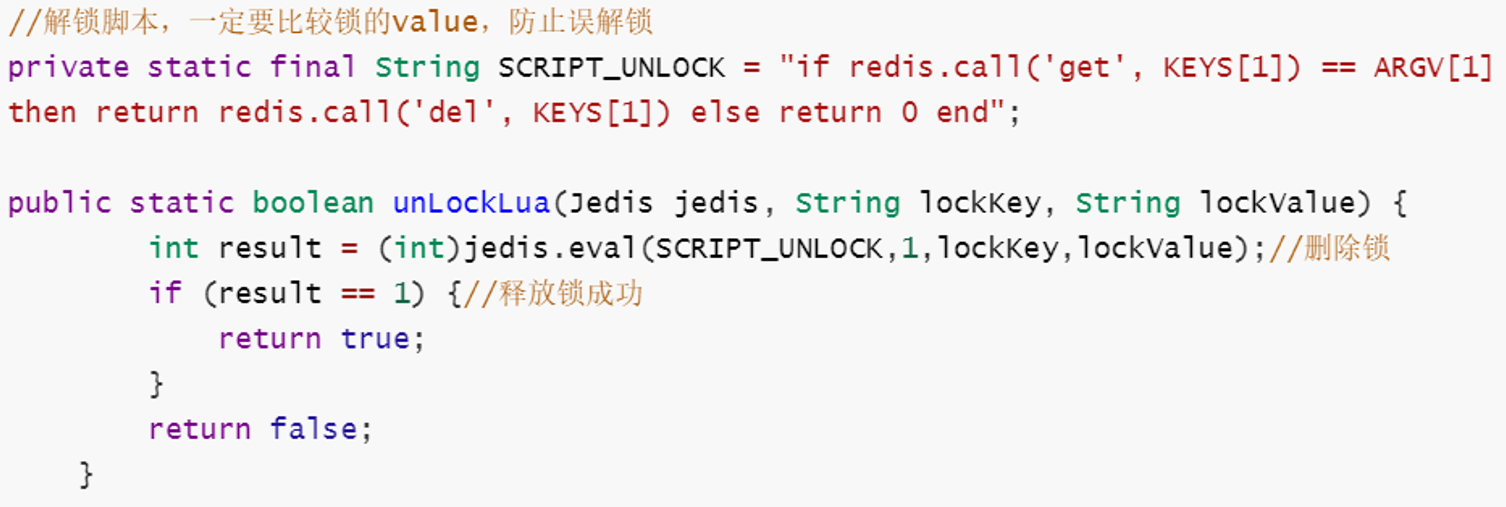
-
使用lua脚本保证了Value的唯一性
-
这样就不会释放别人上的锁,因为在释放锁时会判断是否是自己上的锁
-
value可以考虑使用线程id或者时间戳都行,保证唯一性即可
-
一直存在的问题
-
锁的有效时间问题
-
我们设置锁的有效时间是为了防止死锁的问题发生
-
如果这个时间设置的很长,万一我持有锁的线程挂了,那得等多久才等他自动释放啊,造成其余大量线程阻塞
-
如果这个时间设置的很短,万一我持有锁的线程的业务还没有流转完,锁就自动释放了,这个锁也太不靠谱了
-
解决手段V1版本
-
根据业务场景和经验来判断这个锁的超时释放时间,必须保证有富余时间
-
如果保证不了,那也不靠谱
解决手段V2版本
-
获取锁的线程开启一个守护线程,给快要过期的锁续航
-
比如你设置的锁的有效时长为20秒,过去了19秒,主线程还没释放锁
-
守护线程操作Redis,使用expire,为该锁续命20秒
-
每20S守护线程都去续命key
-
直到主线程释放锁,销毁守护线程结束
-
Redisson实现分布式锁
-
目前落地生产环境用分布式锁,一般采用开源框架,比如Redisson

-
如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。
-
发送lua脚本到redis服务器上,脚本如下: (自动的,无需手动操作)
-
保证这段复杂业务逻辑执行的原子性。
-
KEYS[1]) : 加锁的key
-
ARGV[1] : key的生存时间,默认为30秒
-
ARGV[2] : value (UUID.randomUUID()) + “:” + threadId)
-
"if (redis.call('exists',KEYS[1])==0) then "+ "redis.call('hset',KEYS[1],ARGV[2],1) ; "+ "redis.call('pexpire',KEYS[1],ARGV[1]) ; "+ "return nil; end ;" + "if (redis.call('hexists',KEYS[1],ARGV[2]) ==1 ) then "+ "redis.call('hincrby',KEYS[1],ARGV[2],1) ; "+ "redis.call('pexpire',KEYS[1],ARGV[1]) ; "+ "return nil; end ;" + "return redis.call('pttl',KEYS[1]) ;"
加锁机制
-
第一个判断是否key存在,不存在才加锁
-
使用hash的数据格式加锁 key:{field:1}
-
设置有效时长为30秒
-
锁互斥机制
-
第二个判断用于其他线程想获取锁的场景
-
当前锁已经被占用的情况下,剩下的代码就不会执行了
-
此时其他的线程来了,第一个if可能是false,不会执行
-
则走到第二个if判断,判断其他线程带来的key:{field:1},是否和现在锁的信息一致
-
肯定是不一样的,此时就走: return redis.call('pttl',KEYS[1])
-
返回生效锁的有效时长
-
-
然后其余线程进入无限循环的过程,一直获取锁,直到获取成功
-
自动延时机制
-
只要一个客户端一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一 下,如果该客户端还持有锁key,那么就会不断的延长锁key的生存时间
可重入锁机制
-
当获得锁的线程再次向获取锁的时候
-
第一个if判断不成立
-
第二个判断成立
-
然后对value进行 + 1操作,数据结构会变成:key:{field:2}
释放锁机制
#如果key已经不存在,说明已经被解锁,直接发布(publish)redis消息 "if (redis.call('exists', KEYS[1]) == 0) then " + "redis.call('publish', KEYS[2], ARGV[1]); " + "return 1; " + "end;" + # key和field不匹配,说明当前客户端线程没有持有锁,不能主动解锁。 "if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " + "return nil;" + "end; " + # 将value减1 "local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " + # 如果counter>0说明锁在重入,不能删除key "if (counter > 0) then " + "redis.call('pexpire', KEYS[1], ARGV[2]); " + "return 0; " + # 删除key并且publish 解锁消息 "else " + "redis.call('del', KEYS[1]); " + "redis.call('publish', KEYS[2], ARGV[1]); " + "return 1; "+ "end; " + "return nil;"
-
KEYS[1] :需要加锁的key,这里需要是字符串类型
-
KEYS[2] :redis消息的ChannelName,一个分布式锁对应唯一的一个channelName:“redisson_lockchannel{” + getName() + “}”
-
ARGV[1] :reids消息体,这里只需要一个字节的标记就可以,主要标记redis的key已经解锁,再结合redis的Subscribe,能唤醒其他订阅解锁消息的客户端线程申请锁。
-
ARGV[2] :锁的超时时间,防止死锁
-
ARGV[3] :锁的唯一标识,也就是刚才介绍的 id(UUID.randomUUID()) + “:” + threadId
-
-
其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
-
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用: del myLock ,从redis里删除这个key
-
然后呢,另外的客户端2就可以尝试完成加锁了
-
下面就是代码层面了,原理已经很明了了,我们来点实际的东西
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> </dependency>
//redisson配置类 public class RedissonManager { private static Config config = new Config(); //声明redisso对象 private static Redisson redisson = null; //实例化redisson static{ config.useClusterServers() // 集群状态扫描间隔时间,单位是毫秒 .setScanInterval(2000) //cluster方式至少6个节点(3主3从,3主做sharding,3从用来保证主宕机后可以高可用) .addNodeAddress("redis://192.168.217.120:6379" ) .addNodeAddress("redis://192.168.217.130:6379") .addNodeAddress("redis://192.168.217.140:6379") .addNodeAddress("redis://192.168.217.150:6379") .addNodeAddress("redis://192.168.217.160:6379") .addNodeAddress("redis://192.168.217.170:6379"); //得到redisson对象 redisson = (Redisson) Redisson.create(config); } //获取redisson对象的方法 public static Redisson getRedisson(){ return redisson; } }
//加锁解锁工具类 public class DistributedRedisLock { //从配置类中获取redisson对象 private static Redisson redisson = RedissonManager.getRedisson(); private static final String LOCK_TITLE = "redisLock_"; //加锁 public static boolean acquire(String lockName){ String key = LOCK_TITLE + lockName;//声明key对象 RLock mylock = redisson.getLock(key);//获取锁对象 //加锁,并且设置锁过期时间3秒,防止死锁的产生 uuid+threadId mylock.lock(3, TimeUtil.SECOND); return true;//加锁成功 } //锁的释放 public static void release(String lockName){ String key = LOCK_TITLE + lockName;//必须是和加锁时的同一个key RLock mylock = redisson.getLock(key); //获取锁对象 mylock.unlock(); //释放锁(解锁) } }
//业务开发中使用分布式锁 public String testLock() throws IOException { String key = "test123"; //加锁 DistributedRedisLock.acquire(key); //执行具体业务逻辑 doSomething...... //释放锁 DistributedRedisLock.release(key); //返回结果 return soming; }
.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号