Redis架构原理与集群演变
Redis持久化机制
-
Redis是一个KV的 内存数据库,为了保证数据的持久性,它提供了三种持久化方案
-
RDB方式(默认)
-
AOF
-
混合持久化模式(4.0增加,5.0默认开启)
-
Redis的持久化方案
RDB方案
-
RDB是Redis默认采用的持久化方式
-
RDB方式是通过快照的方式完成数据的备份
-
当符合一条件时,Redis会自动将内存的数据快照并持久化到硬盘中
触发RDB快照的时机
-
符合配置文件配置的快照规则
-
执行save或者bgsave命令时
-
执行flushall
-
执行主从复制的操作时
RDB设置快照规则
-
在Redis的安装目录中有redis.conf的配置文件

-
save "" :表示不适用RDB储存
-
save 900 1 :表示15分钟内如果有1个键被更改则进行快照
-
save 30010 :表示5分钟内如果有10个键被更改则进行快照
-
save 60 10000 :表示1分钟内如果有10000个键被更改则进行快照
RDB快照实现原理

-
:当快照被触发时
-
:Redis主进程调用系统的fork函数复制一个当前进程的副本(子进程)
-
:Redis主进程继续响应请求,保持服务的可用
-
:被复制出来的子进程开始将内存中的数据写入到一个rdb的临时文件中
-
:当子进程写入完所有数据后,会用该临时文件覆盖替换旧的rdb文件,该子进程结束,一次快照完成
注意事项
-
Redis在快照期间不会修改原有RDB文件,而是新建一个RDB文件,将数据写入其中,当数据写完后,进行文件覆盖式替换
-
如果生成快照失败,就不会进行替换。保证了RDB文件随时都是完整可读的
-
RDB的优缺点
-
RDB方式持久化,因为子进程刷盘到覆盖原有文件是需要时间的,这段时间变更的数据无法持久化到当前持久化文件中
-
如果这个时候Redis异常退出,那么这次快照会失败且快照时变更的数据也会丢失
-
单单只是RDB,是无法保证数据的完成的,如果数据非常重要,就应该混合使用下面我们说到的AOF方式
-
-
RDB方式可以最大化Redis的性能,父进程什么也不需要做,只需要fork分叉出一个子进程来处理
-
如果次数数据集比较大,fork可能比较耗时,造成服务器在一段时间内停止处理客户端的请求
-
AOF方案

-
默认情况下,AOF是需要手动开启的
-
开启AOF持久化后,没执行一条变更数据的命令,Redis就会将该命令写入到磁盘中的AOF文件中去
-
因为涉及IO操作,会牺牲一点点Redis的性能,但是我们可以使用比较快的硬盘,降低这种损耗
AOF同步磁盘数据
-
Redis每次更改数据时候,aof机制都会将其命令记录在aof文件中
-
但是实际上,并没有保证实时性,由于操作系统的缓存机制,数据进入到硬盘的缓冲中,在通过硬盘缓存机制刷新到aof文件

-
always
-
每次执行写入都会进行同步, 这个是最安全但是是效率比较低的方式
-
-
everysec (默认)
-
每一秒执行(默认)
-
-
no
-
不主动进行同步操作,由操作系统去执行,这个是最快但是最不安全的方式
-
AOF重写原理
-
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写。重写后的新AOF文件包含了恢复当前数据集所需的最小命令集合
-
比如
-
set k1 v1
-
set k1 v2
-
set k1 v3
-
重写优化后只有:set k1 v3
-
-
AOF文件有序的保存了对Redis执行的操作命令,这么数据,都是以Redis协议(REST)格式保存
-
因此AOF文件的内容容易理解,对文件进行解析也很轻松
-
RDB和AOF的选择(混合持久化方式)
Redis 4.0之前面临的抉择
-
Redis只是作为内存数据库:RDB + AOF 数据不会丢
-
Redis只是作为缓存服务器:RDB
-
不建议单单只使用AOF,文件过大,Redis重启非常慢
-
恢复时,Redis会限度去AOF文件,再读取RDB文件
Redis 4.0后无需考虑,默认:混合持久化方式
-
Redis 4.0 之后新增的方式,混合持久化是结合了 RDB 和 AOF 的优点
-
在写入的时候,先把当前的数据以 RDB 的形式写入文件的开头
-
再将后续的操作命令以 AOF 的格式存入文件
-
这样既能保证 Redis 重启时的速度,又能减低数据丢失的风险
混合持久化方式
-
RDB 可能会导致一定时间内的数据丢失
-
AOF 由于文件较大则会影响 Redis 的启动速度
-
为了能同时拥有 RDB 和 AOF 的优点,Redis 4.0 之后新增了混合持久化的方式
-
该方式在Redis 4.0 引入,默认关闭,在5.0默认开启
-
可通过该命令查看状态:config get aof-use-rdb-preamble
-

-
如果是在4.0到5.0之间的版本,有以下两种方式开启
-
通过命令开启,重启失效 : config set aof-use-rdb-preamble yes
-
通过配置文件开启,永久有效:aof-use-rdb-preamble yes
-
修改文件后,重启机器
-
-
多插一句:如果你的业务是有必须持久化的的需求,才开启持久化
如果持久化不是那么重要或者根本不需要,可以关闭持久化,将Redis的性能再度提升
Redis的的主从同步机制
-
持久化的方式保证Redis服务重启也不会丢失数据
-
将硬盘中的持久化文件读取到内存中
-
-
如果此时服务器硬盘坏了,持久化文件也没有了,如何保证数据不丢失呢?
-
主从复制
-
主从同步实现原理
-
Redis的主从同步,分为全量同步和增量同步
-
只有从机第一次链接主机的时候是全量同步
-
断线重连可能会触发全量同步,也有可能是增量同步(master判断runid是否一致)
全量同步三阶段
-
第一阶段:同步快照
-
Master创建快照,并发送给从机slave,slave载入快照并解析快照将数据载入内存
-
这一阶段可以是磁盘快照文件,(IO操作)
-
也可以开启无磁盘数据同步,直接网络完成同步:repl-diskless-sync yes
-
-
Master 同时将此阶段所产生的新的操作命令存储到缓冲区
-
-
第二阶段:同步写缓冲
-
Master 向 Slave 同步存储在缓冲区的写操作命令,Slave载入缓冲区操作命令
-
-
第三阶段:同步增量
-
Master 向 Slave 同步写操作命令
-
增量同步
-
Redis的增量同步主要是指Slave完成初始化同步已经开始正常时,Master发生的数据变更同步到Slave的过程
-
通常情况下Master每执行一个写命令就会向Slve发送相同的写命令,然后Slave接受并执行
主从配置(有个小故事)
主Master
-
无需额外配置
从Slave
-
修改redis.conf配置文件
-
4.0版本之前 : slaveof masterIP 6379
-
4.0版本之后
-
slaveof masterIP 6379
-
-
4.0版本之后(随意更改一个即可)
-
slaveof masterIP 6379
-
replicaof masterIP 6379
-
-
可以看到Redis 4.0之后的Slave更改的配置变更多了一个,为什么呢?
Redis的Sentinel工作原理
哨兵(Sentinel)主要是为了解决在主从复制架构中出现宕机的情况,主要分为两种情况
-
从Redis宕机
-
这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据。
-
在Redis2.8版本后,主从断线后恢复的情况下实现增量复制
-
-
主Redis宕机
-
在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务
-
将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来
-
假设我们现在是一主三从的架构,一个master,二个slave

Sentinel定时监控
-
Sentinel虽然明面上只配置了对Master的监控,但其实通过Master也在监控所有的Slave
-
每个哨兵10S/次向Master发送info命令,获取最新主从架构信息,监控所有节点
-
-
每个哨兵以2S/次的频率向Redis数据节点的指定频道发送数据相互了解架构信息
-
发送自己哨兵的状态信息(是否可用)
-
发送自己哨兵对Master状态的判定信息(是否可用)
-
其实就是通过消息publish和subscribe来完成的
-
-
每个哨兵以1S/次的频率向当前主节点、从节点、以及其余哨兵节点发送一个ping命令,这个是心跳检测
-
也是哨兵用来判断节点是否正常的重要依据
-
主观下线
-
又叫:sdown
-
就是单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)
-
通过1S/次的频率向当前主节点、从节点、以及其余哨兵节点发送一个ping命令
-
-
sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度
-
如果超出时间长度还没有正确回复就认为主观下线
客观下线
-
又叫:odwon
-
当主观下线的节点是主节点时,此时该哨兵3节点会通过指令sentinel is-masterdown-byaddr寻求其它哨兵节点对主节点的判断
-
如果其他的哨兵也认为主节点主观线下了
-
当认为主观下线的票数超过了quorum(选举)个数
-
大部分哨兵节点都同意下线操作 ,这样就客观下线了
-
Sentinel Leader选取流程
如果主节点被判定为客观下线之后,就要选取一个哨兵节点来完成后面的故障转移工作
选举出一个leader的流程如下 :
-
第一个发现主节点下线的哨兵,会向其它哨兵发ismaster-down-by-addr命令,征求判断并要求将自己设置为领导者
-
只要超过 哨兵集群节点数 / 2 + 1 的同意,就能成为哨兵Leader
-
然后哨兵Leader负责下面的故障转移,选举新的Redis主从Master
故障转移机制
-
在剩下可用的从节点中选择新的主节点
-
sentinel状态数据结构中保存了主服务的所有从服务信息
-
sentinel Leader按照如下的规则从从服务列表中挑选出新的主从Master
-
过滤掉主观下线的节点
-
选择slave-priority最高的节点,如果由则返回没有就继续选择 ,默认都是100,一般不做更改
-
选择出复制偏移量最大的系节点
-
因为复制偏移量越大则数据复制的越完整,如果由就返回了,没有就继续
-
-
选择run_id最小的节点
-
-
-
更新主从状态
-
通过slaveof no one命令,让选出来的从节点成为主节点;并通过slaveof命令让其他节点成为其从节点。
-
当宕机的master恢复正常时,复制新的master节点,变成新的master的slave
-
同理,当已下线的slave服务重新上线时,sentinel会向其发送slaveof命令,让其成为新master的slave
-
哨兵进程的作用
-
监控( Monitoring ):
-
哨兵( sentinel ) 会不断地检查你的 Master 和 Slave 是否运作正常
-
-
提醒( Notification ):
-
当被监控的某个 Redis 节点出现问题时, 哨兵( sentinel ) 可以通过 API向管理员或者其他应用程序发送通知。
-
-
自动故障迁移( Automatic failover ):
-
当一个 Master 不能正常工作时,哨兵( sentinel ) 会开始一次自动故障迁移操作
-
Redis的集群框架&选择
目前Redis的集群选择最火热的就是 Redis自带的 Redis Cluster,其余都只做了解使用
主从复制
-
参考上面所说的主从复制笔记
Replication + Sentinel *高可用 (了解)
-
这套架构使用的是社区版本推出的原生高可用解决方案

工作原理
-
当Master宕机的时候,Sentinel会选举出新的Master,
-
并根据Sentinel中client-reconfig-script脚本配置的内容,去动态修改VIP(虚拟IP),
-
将VIP(虚拟IP)指向新的Master。我们的客户端就连向指定的VIP即可
-
比如现在指向的是:192.168.217.150
-
如果192.168.217.150宕机,160当选Master,此时VIP指向192.168.217.160
-
缺陷
-
主从切换过程中会丢失数据
-
Redis只能单点写,不能水平扩容
Proxy + Replication + Sentinel (了解)
-
这里的proxy有两种选择:Codis(豌豆荚)和Twemproxy(推特)
-
这里以Twemproxy为例说明,如下图所示
-
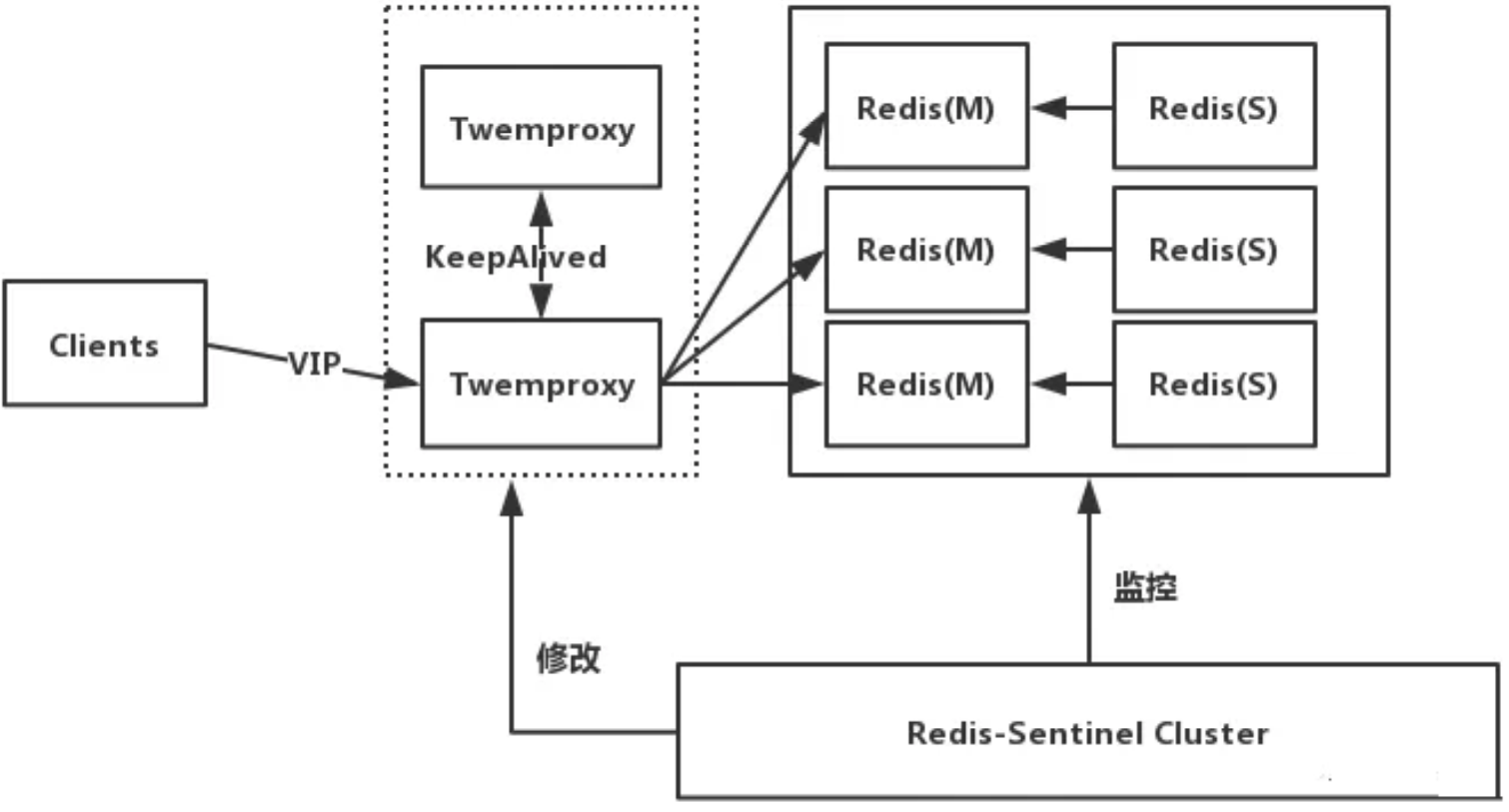
工作原理
-
前端使用Twemproxy+KeepAlived做代理,将其后端的多台Redis实例分片进行统一管理与分配
-
每一个分片节点的Slave都是Master的副本且只读
-
Sentinel持续不断的监控每个分片节点的Master,
-
当Master出现故障且不可用状态时,Sentinel会通知/启动自动故障转移等动作
-
-
Sentinel 可以在发生故障转移动作后触发相应脚本(通过 client-reconfig-script 参数配置 )
-
脚本获取到最新的Master来修改Twemproxy配置
-
缺点
-
部署结构超级复杂
-
可扩展性差,进行扩缩容需要手动干预
-
运维不方便
Redis Cluster(核心原理)

核心原理
-
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
-
节点的fail是通过集群中超过半数的节点检测失效时才生效
-
客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
-
redis-cluster把所有的物理节点映射到[0-16383]一共16384个插槽slot上,
-
cluster 负责维护node<->slot<->value
-
插槽Slot
-
Redis 集群中内置了 16384个哈希槽
-
当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果
-
然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽
-
redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
-
然后将该数据转发到包含了该哈希槽的节点上进行保存
Redis Cluster 投票

-
节点失效判断
-
如果半数以上master节点与其中一个master节点通信超过(cluster-node-timeout),认为该master节点挂掉.
-
-
集群失效判断:什么时候整个集群不可用 ?
-
如果集群任意master挂掉,且当前master没有slave
-
这样导致插槽数据不完整,宕掉的master节点数据无法获取,则集群进入fail状态
-
-
如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态
-
Redis Cluster高可用集群搭建指南
服务器清单
-
此集群三主三从,一共六台服务器,对应的职责如下所示
-
masert1 : 192.168.217.120
-
slave:192.168.217.150
-
-
master2:192.168.217.130
-
slave:192.168.217.160
-
-
master3:192.168.217.140
-
slave:192.168.217.170
-
-
-
所有服务器Redis阶段清空全部数据,搭建时不能有节点有数据
-
flushdb
-
各服务器搭建Redis服务
-
下载Redis:wget http://download.redis.io/releases/redis-6.0.9.tar.gz
-
解压:tar -zxvf redis-6.0.9.tar.gz
-
下载Redis所需环境,下载并升级gcc
-
yum install gcc yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils scl enable devtoolset-9 bash
-
-
进入解压目录编译且安装:
-
cd redis-6.0.9
-
make
-
make install
-
-
跳转到默认安装目录
-
cd /usr/local/bin/
-
-
复制Redis的配置文件到/usr/local/bin/并修改
-
将解压得到的配置文件复制一份到/usr/local/bin/中,方便启动服务使用
-
cp /ninja_install/redis-6.0.9/redis.conf ./
-
vim ./redis.conf
-
#bind 127.0.0.1 :注释掉外网可以访问
-
protected-mode no : yes改为no,外网可以访问
-
daemonize yes :no改成yes,后台运行
-
-
-
以配置文件方式启动redis服务,并连接
-
./redis-server ./redis.conf
-
./redis-cli
-
-
为Redis的客户端建立软连接,这样我们键入redis就如同使用了全路径的redis-cli
-
ln -s /usr/local/bin/redis-cli /usr/bin/redis
-
同理,当然你也可以为redis-server创建软连接
-
修改配置搭建集群
-
修改作为master节点的Redis的配置文件,打开一下注释即可
-
cluster-enabled yes
-
cluster-config-file nodes-6379.conf
-
-
以配置文件的方式启动,重启所有Redis服务
-
在随意一台redis节点的机器上,执行以下命令
-
./redis-cli --cluster create 192.168.217.120:6379 192.168.217.130:6379 192.168.217.140:6379 192.168.217.150:6379 192.168.217.160:6379 192.168.217.170:6379 --cluster-replicas 1-
./redis-cli :执行redis安装目录的客户端连接根据
-
--cluster :集群标识
-
create :创建标识
-
-
中间一堆IP下面详说
-
-
上面一共涉及到6台机器的ip和port
因为我们设置的副本数量为1,所以这个集群每一个master都会有一个slave
所以,前三个ip是master,后三个ip分别是前三个master的slave

-
看上图左边橘色三个M,代表三个Master信息
-
红色标注的是16384个插槽的分布情况,分别分给了三个Master
-
-
看上图左边黄色三个S,代表三个Slave信息
查看Redis集群信息,使用客户端命令 redis-cli -c 登陆任意主从节点
查看集群状态:cluster info
查看集群中的节点 :cluster nodes
Redis Cluster优缺对比
-
客户端与Redis节点直连,不需要中间Proxy层,直接连接任意一个Master节点
-
根据公式计算出映射到哪个分片上,然后Redis会去相应的节点进行操作
-
无需Sentinel哨兵监控,如果Master挂了,Redis Cluster内部自动将Slave切换Master
-
可以进行水平扩容
-
支持自动化迁移
-
当出现某个Slave宕机了,那么就只有Master了,
-
这时候的高可用性就无法很好的保证了,万一Master也宕机了,咋办呢?
-
针对这种情况,如果说其他Master有多余的Slave ,
-
集群自动把多余的Slave迁移到没有Slave的Master 中
-
-
批量操作是个坑
-
多键的命令操作(如MGET、MSET),如果每个键都位于同一个节点,则可以正常支持,否则会提示错误。
-
-
资源隔离性较差,容易出现相互影响的情况
-
集群中的节点只能使用0号数据库,如果执行SELECT切换数据库会提示错误
-
代码测试
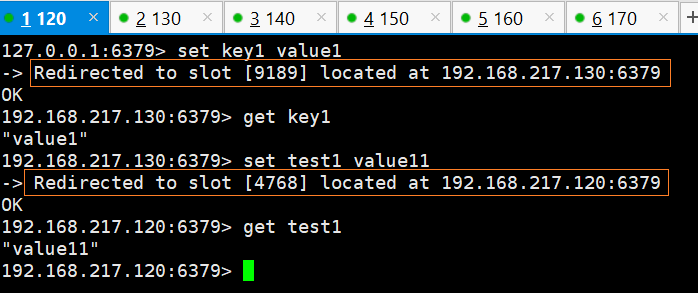
-
可以发现:
-
我们在任意节点上操作数据
-
该节点可能不包含该key的插槽hash,也就是该数据并不在该服务器上
-
但是我们仍然可以操作数据,集群会帮我们转发该请求到包含该数据的服务器上
-
我们使用代码来测试一下,创建一个SpringBoot工程
-
依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.3.0</version> </dependency> <!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind --> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> <!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-core --> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> </dependency> </dependencies>
application.yml
server: port: 8080 spring: redis: cluster: nodes: 192.168.217.120:6379,192.168.217.130:6379,192.168.217.140:6379,192.168.217.150:6379,192.168.217.160:6379,192.168.217.170:6379 max-redirects: 6 redisConnect: timeout: 10000 #客户端超时时间单位是毫秒 默认是2000 maxIdle: 300 #最大空闲数 maxTotal: 1000 #控制一个pool可分配多少个jedis实例,用来替换上面的redis.maxActive,如果是jedis 2.4以后用该属性 maxWaitMillis: 1000 #最大建立连接等待时间。如果超过此时间将接到异常。设为-1表示无限制。 minEvictableIdleTimeMillis: 300000 #连接的最小空闲时间 默认1800000毫秒(30分钟) numTestsPerEvictionRun: 1024 #每次释放连接的最大数目,默认3 timeBetweenEvictionRunsMillis: 30000 #逐出扫描的时间间隔(毫秒) 如果为负数,则不运行逐出线程, 默认-1 testOnBorrow: true #是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个 testWhileIdle: true #在空闲时检查有效性, 默认false password: #密码
-
配置类
@Configuration public class RedisClusterConfig { @Value("${spring.redis.cluster.nodes}") private String clusterNodes; @Value("${spring.redis.cluster.max-redirects}") private int maxRedirects; @Value("${redisConnect.password}") private String password; @Value("${redisConnect.timeout}") private int timeout; @Value("${redisConnect.maxIdle}") private int maxIdle; @Value("${redisConnect.maxTotal}") private int maxTotal; @Value("${redisConnect.maxWaitMillis}") private int maxWaitMillis; @Value("${redisConnect.minEvictableIdleTimeMillis}") private int minEvictableIdleTimeMillis; @Value("${redisConnect.numTestsPerEvictionRun}") private int numTestsPerEvictionRun; @Value("${redisConnect.timeBetweenEvictionRunsMillis}") private int timeBetweenEvictionRunsMillis; @Value("${redisConnect.testOnBorrow}") private boolean testOnBorrow; @Value("${redisConnect.testWhileIdle}") private boolean testWhileIdle; //Redis连接池的配置 @Bean public JedisPoolConfig getJedisPoolConfig() { JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); // 最大空闲数 jedisPoolConfig.setMaxIdle(maxIdle); // 连接池的最大数据库连接数 jedisPoolConfig.setMaxTotal(maxTotal); // 最大建立连接等待时间 jedisPoolConfig.setMaxWaitMillis(maxWaitMillis); // 逐出连接的最小空闲时间 默认1800000毫秒(30分钟) jedisPoolConfig.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis); // 每次逐出检查时 逐出的最大数目 如果为负数就是 : 1/abs(n), 默认3 jedisPoolConfig.setNumTestsPerEvictionRun(numTestsPerEvictionRun); // 逐出扫描的时间间隔(毫秒) 如果为负数,则不运行逐出线程, 默认-1 jedisPoolConfig.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis); // 是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个 jedisPoolConfig.setTestOnBorrow(testOnBorrow); // 在空闲时检查有效性, 默认false jedisPoolConfig.setTestWhileIdle(testWhileIdle); return jedisPoolConfig; } //Redis集群的配置 @Bean public RedisClusterConfiguration redisClusterConfiguration() { RedisClusterConfiguration redisClusterConfiguration = new RedisClusterConfiguration(); // Set<RedisNode> clusterNodes String[] serverArray = clusterNodes.split(","); Set<RedisNode> nodes = new HashSet<RedisNode>(); for (String ipPort : serverArray) { String[] ipAndPort = ipPort.split(":"); nodes.add(new RedisNode(ipAndPort[0].trim(), Integer.valueOf(ipAndPort[1]))); } redisClusterConfiguration.setClusterNodes(nodes); redisClusterConfiguration.setMaxRedirects(maxRedirects); //redisClusterConfiguration.setPassword(RedisPassword.of(password)); return redisClusterConfiguration; } //redis连接工厂类 @Bean public JedisConnectionFactory jedisConnectionFactory() { // 集群模式 JedisConnectionFactory factory = new JedisConnectionFactory(redisClusterConfiguration(), getJedisPoolConfig()); return factory; } //实例化 RedisTemplate 对象 @Bean public RedisTemplate<String, Object> redisTemplate() { RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>(); // Template初始化 initDomainRedisTemplate(redisTemplate); return redisTemplate; } //设置数据存入 redis 的序列化方式 使用默认的序列化会导致key乱码 private void initDomainRedisTemplate(RedisTemplate<String, Object> redisTemplate) { // 开启redis数据库事务的支持 redisTemplate.setEnableTransactionSupport(true); redisTemplate.setConnectionFactory(jedisConnectionFactory()); // 如果不配置Serializer,那么存储的时候缺省使用String,如果用User类型存储,那么会提示错误User can't cast to // String! StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); redisTemplate.setKeySerializer(stringRedisSerializer); // hash的key也采用String的序列化方式 redisTemplate.setHashKeySerializer(stringRedisSerializer); // jackson序列化对象设置 Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>( Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); // value序列化方式采用jackson redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); // hash的value序列化方式采用jackson redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer); redisTemplate.afterPropertiesSet(); } }
-
测试代码
@SpringBootTest class NinjaStudyApplicationTests { @Autowired private RedisTemplate<String, Object> template; @Test void contextLoads() { template.opsForValue().set("ninja", "Hello Redis Cluster"); String str = (String) template.opsForValue().get("ninja"); System.out.println(str); } }
-
结果展示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号