Spring Cloud Alibaba 扫盲 [ 采坑1.2 ]
Netflix网飞公司 和 Spring Cloud 和 Spring Cloud Alibaba之间的爱恨情仇这里我们就不多BB了,今天总结一下Spring Cloud Alibaba各大组件的使用,做一个学习总结
创建Maven父工程,贴入以下版本约束
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</dependency>
<!--spring boot 2.2.2-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud Alibaba-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud Hoxton.SR1-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<scope>runtime</scope>
</dependency>
<!-- druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring.boot.version}</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<!--log4j-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<pluginManagement>
<plugins>
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<!--热部署配置, 后面没用,这个可以不用配-->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
Nacos = Eureka + Config + Bus
思想还是借鉴的Eureka的思想,大家可以当成Eureka来用,但功能只增不减
基础环境:JDK8 + Maven3.2+ (开发缺这两个环境 ?)
如果大家想在服务器上装Nacos的话,上面两个环境必须备好
Nacos windows下载安装:https://github.com/alibaba/nacos(版本随意)
下载后解压进入bin目录,双击startup.cmd即可启动服务,可以发现Nacos是Java开发的
-
可以发现Nacos是单独部署的,而不是想Eureka、Config那样起服务
启动之后访问localhost:8848/nacos即可看到web页面
键入账号和密码,默认均为:nacos,登陆监控页面
此时一个注册中心和一个配置中心服务就算搭建成功,后面我们要使用的时候,对号入座即可
Nacos的服务注册
基于我要写完几大组件,不想参杂无关的冗余模块,所以这里我们演示一下注册中心的功能,写一个后面会用到的模块,让他注册进Nacos,后面被其他模块调用或者演示服务限流、降级、熔断等通用的服务,下面我们就创建一个支付模块:payment_8801
创建一个maven项目,改pom,创yml,写入口函数,写接口,一步到位
-
改pom
<dependencies> <!-- nacos --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--监控--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--监控 以json格式输出信息--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-hateoas</artifactId> </dependency> </dependencies>
-
创yml
server: port: 8801 spring: application: name: payment-server cloud: nacos: discovery: #配置注册中心的地址 server-addr: localhost:8848 #监控 management: endpoints: web: exposure: include: '*'
-
写入口函数
@SpringBootApplication @EnableDiscoveryClient //开启注册中心 public class PaymentApplication8801 { public static void main(String[] args) { SpringApplication.run(PaymentApplication8801.class); } }
-
接口我们就不写了,我们这里只是演示一下注册中心
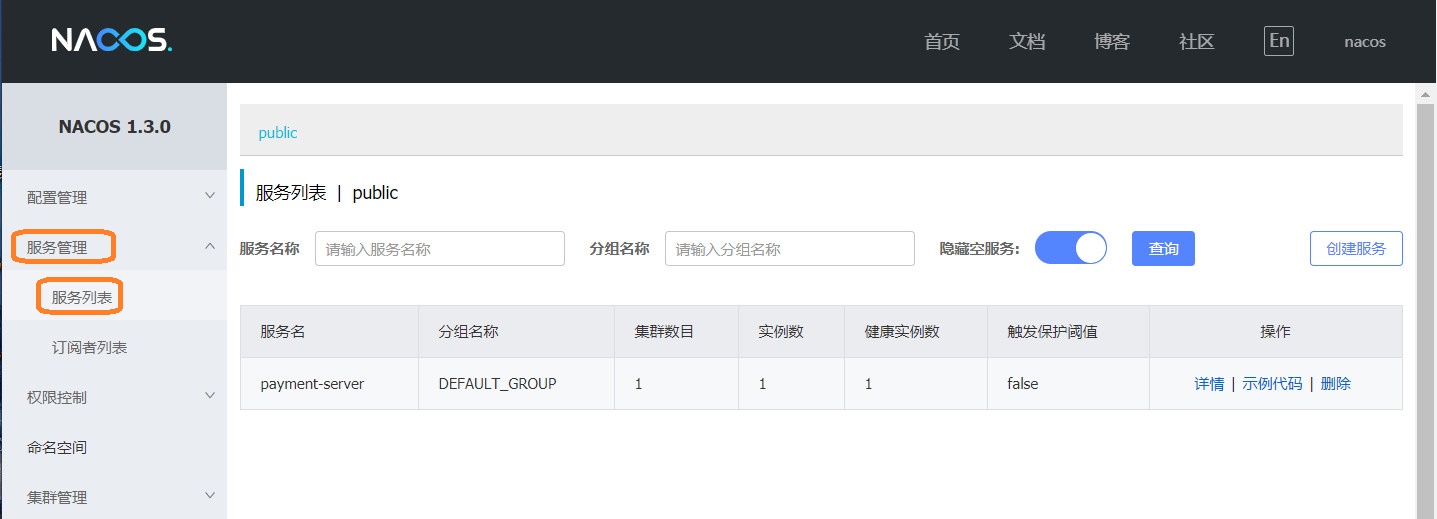
然后我们访问我们的Nacos的页面。如下所示,我们的服务已经在Nacos的服务列表上了,服务名和Eureka一样,都是默认使用项目名称
Nacos的配置中心
Config 配置中心 + Bus消息总线实现配置的实时刷新,Nacao打包一套带走
继续创建一个Maven项目,改pom,创yml,写入口函数,写接口,一步到位
-
改pom
<dependencies> <!-- SpringCloud ailibaba config--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!-- SpringCloud ailibaba nacos--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--监控--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--监控 以json格式输出信息--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-hateoas</artifactId> </dependency> </dependencies>
-
创建yml
-
这里会创建两个配置文件,bootstrap.yml 和 application.yml,这两者不做说明,大家应该懂吧
bootstrap.yml 如下
-
server: port: 8888 spring: application: name: nacos-config cloud: nacos: discovery: server-addr: localhost:8848 #作为注册中心的地址 config: server-addr: localhost:8848 #作为配置中心的地址 file-extension: yaml #指定yaml格式的配置 #监控 management: endpoints: web: exposure: include: '*'
application.yml配置如下
spring: profiles: active: dev #表示拉取配置中心开发环境的配置文件
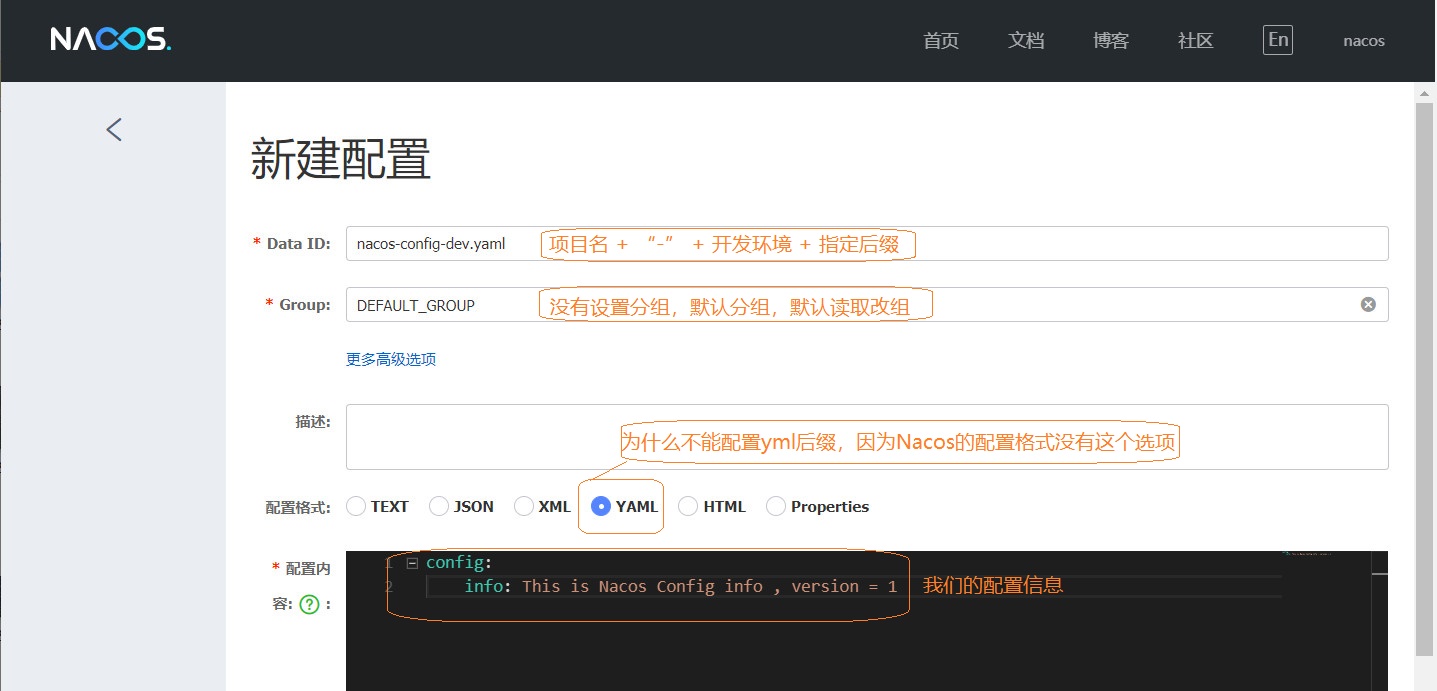
穿插一个特别说明:大家仔细看一下我配置的配置中心的属性
首先配置了配置中心的地址,就是Nacos的地址
然后我指定了一个读取配置文件的后缀为:yaml
我选择了运行环境为dev 开发环境
就这三个配置,已经足够我去配置中心读取配置了,他是这么定位文件的呢?
Nacos关于自己的配置中心锁定文件有一套自己的定位方法
项目名称 + “-” + 运行环境 + 后缀
上面的配置中
项目名称为: nacos-config
运行环境我们选择的:dev
指定了配置文件的后缀为:yaml (不能是yml,Nacos不能创建这个格式的文件)
所以我们的配置文件应该为:nacos-config-dev.yaml
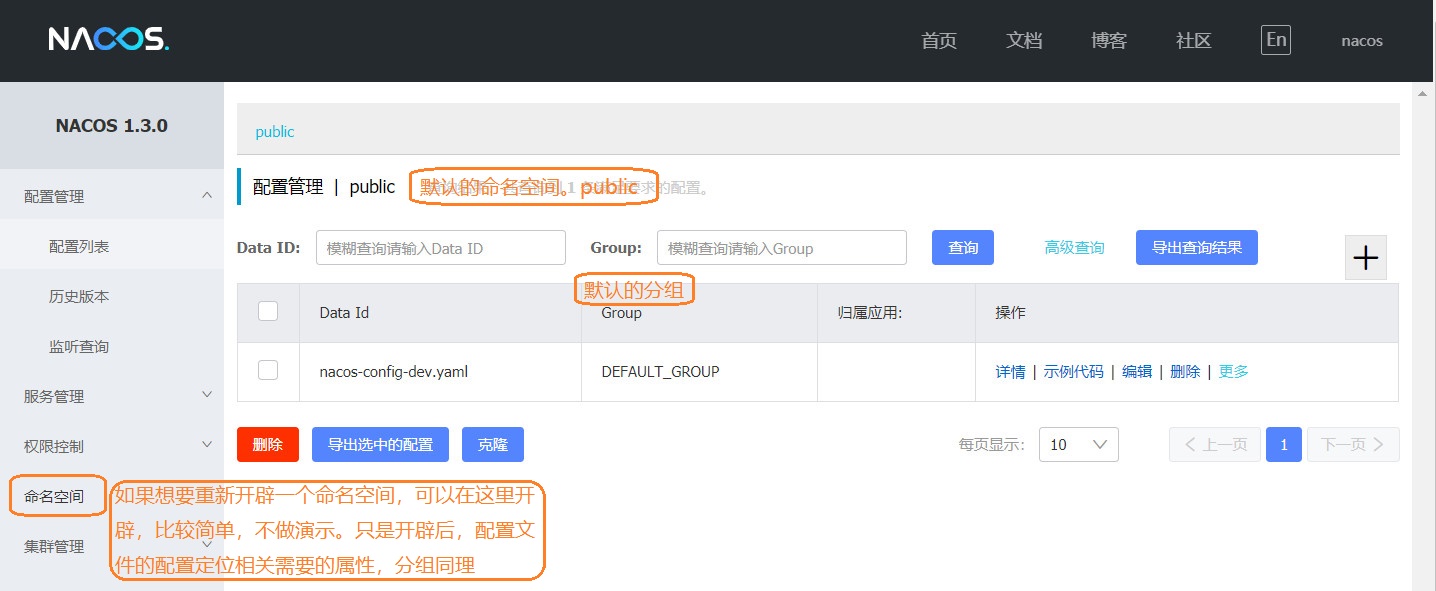
如果这里已经了解了的话,Nacos的web页面还可以配置一个命名空间和分组的功能,目的就是将各个配置文件分开来,一个命名空间有多个分组,每个分组里有多个配置文件,如果你设置了命名空间和分组,就得在上面的配置中加加两个配置,用来定位命名空间和分组的属性这个,如果我们不设置命名空间和分组,就是默认的,命名空间为public,分组为default,这个我们不用明文配置,默认读取。
一般我们在使用时,都会使用命名空间和分组,主要是隔离不同的配置,新加配置
namespace: 165e1f54-5249-521f-20d0-890d225974a #命名空间编号,页面会显示 group: DEV_GROUP # 分组信息
一般对于命名空间,我们会创建三个:开发,测试,生产,实现配置隔离
而对于分组,可以把不同的微服务划分到一个组,统一管理
既然配置已经完成了,那我们就去配置中心创建一个配置文件吧
然后当然就是发布啦,发布后返回配置列表可以发现多了一个配置
配置文件就绪,读取配置就绪,下面我们就写一个接口测一测我们是否可以读取到配置文件中的数据吧,读取的就是我们刚刚配置的数据,注意那个头上的注解,他代替了Bus
@RestController @RefreshScope //支持nacos作为config配置中心的动态刷新,一个注解干掉Bus public class NacosConfigController { //读取配置中心的数据 @Value("${config.info}") private String info; //将配置中心读取到的配置暴露出去测试一下 @GetMapping("/config/info") public String test1(){ return info; } }
启动服务,测试我们的接口,如下所示,成功读取到了配置中心配置的属性
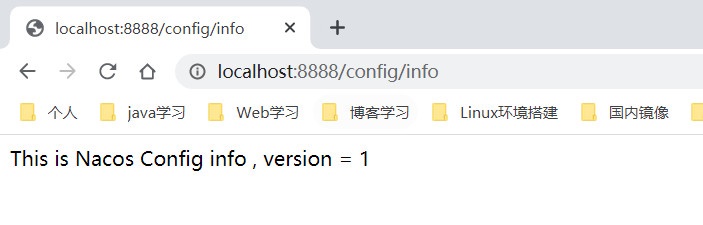
都到这一步了,不测测动态刷新就亏了,我们修改配置的version为2,保存后再次访问该接口,发现配置已经实现动态刷新,我们再也不需要通过Bus来打太极了
Nacos数据持久化
生产环境中必配,目前只支持持久化到mysql,官方建议一主一从
在Nacos中,内嵌了一个数据库derby,用作持久化数据,但是如果我们开启了多个Nacos节点,各内部的数据的一致性是不可保证的,所以集群部署的前提就是数据的一致性,而数据的一致性要求多节点使用同一个数据库。
因为我们现在是windows环境,Linux上操作一致
在我们的解压文件中下conf目录下有一个nacos-mysql.sql文件,这就是我们需要初始化数据库的建表语句,导入到mysql中,可能会有版本导致导入失败,这里各人解决
其次在conf下还有一个application.properties文件,在这里我们需要配置开启持久化数据到mysql,并配置mysql相关的连接信息,注释不用去打开,直接新增吧
spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true db.user=nacos_devtest #更改用户名 db.password=youdontknow #更改密码
数据库名要根据的数据库来定,数据库名无要求
然后重启Nacos即可,发现之前的配置已经小时了,且控制台没报错就已经切换,如果还想确定是否已经切换了持久化源,可以新增一个配置,然后去数据库看数据是否已经持久化到数据库
Nacos的集群部署
在生产环境中,这种服务都是集群部署的,防止单点故障,保证高可用
讲道理,搭这个集群搞崩了我三台虚拟机,现在我本地虚拟机都还没配制好,淦
也不能怪Nacos,只能怪VMWare太脆弱,莫名其妙就崩了,后面再补上集群实操,这里就说说操着手法吧,有基础的我建议使用Docker搭建,简单方便
根据官方示意图Nacos的集群搭建需要三个Nacos + 一个Nginx + 一个mysql(玩玩不用达主从),三个Nacos服务节点才能搭起集群,Nginx做最外层的访问入口和负载均衡
准备工作:
三台服务器,每台3G内存,不然你就要走我的后路,内存不足,服务多的那台给4G
每台服务器一个Nacos服务节点,Nginx和Mysql随便选一个节点部署
三台服务器需要JDK环境 + Maven环境
三台服务器均关闭防火墙,提醒一下

第一步:三台同步
修改Nacos持久化源为数据库,上面已经说明过,三台统一使用一个数据库
第二步:三台同步
修改conf目录下cluster.config.example 重命名为 cluster.config
在其中键入参与集群的三台Nacos节点的ip:port,如下所示
192.168.0.140:8848
192.168.0.141:8848
192.168.0.142:8848
依次启动三台服务,这其中可能会出现错误,在启动的控制台他会告诉你日志在哪,看看日志有没有抛出什么异常,目前我遇到过数据库连接不上,内存不够异常,均已修复
至于其他的异常,百度吧,后浪
第三步:配置Nginx
无非就是配一个反向代理,proxy_pass upstream指向三台服务
实现入口统一和负载均衡
配置完,Nginx配置文件检查一把 ./nginx -t
配置文件没错再重启 ./nginx -s reload
最后,访问Nginx监听的端口,成功访问Nacos的页面,搭建完成
Sentinel = Hystrix
说到Hystrix,我们就必须清清楚楚的明白什么是降级,什么是熔断,复制了一段以前学习Spring Cloud 时写的笔记,希望大家能够明白
服务熔断
服务雪崩:是一种因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程。
雪崩效应:服务提供者因为不可用或者延迟高造成的服务调用者的请求线程阻塞,阻塞的请求会占用系统的固有线程数、IO等资源,当这样的被阻塞的线程越来越多的时候,系统瓶颈造成业务系统瘫痪崩溃,这种现象成为雪崩效应
熔断机制:熔断机制是服务雪崩的一种有效解决方案,当服务消费者请求的服务提供者因为宕机或者网络延迟高等原因造成暂时不能提供服务时,采用熔断机制,当我们的请求在设定的最常等待响应阀值最大时仍然没有得到服务提供者的响应的时候,系统将通过断路器直接将吃请求链路断开,这种解决方案称为熔断机制
服务降级
理解了上面所说的服务熔断相关的知识,想想在服务熔断发生时,该请求线程仍然占用着系统的资源,为了解决这个问题,在编写消费者[重点:消费者]端代码时就设置了预案,当服务熔断发生时,直接响应有服务消费者自己给出的一种默认的,临时的处理方案,再次注意"这是由服务的消费者提供的",服务的质量就相对降级了,这就是服务降级,当然服务降级可以发生在系统自动因为服务提供者断供造成的服务熔断,也可运用在为了保证核心业务正常运行,将一些不重要的服务暂时停用,不重要的服务的响应都由消费者给出,将更多的系统资源用作去支撑核心服务的正常运行,比如双11期间,收货地址服务全部采用默认,不能再修改,就是收货地址服务停了,把更多的系统资源用作去支撑购物车、下单、支付等服务去了。
我们再简单归纳一下:简单来说就是服务提供者断供了,其一为了保证系统可以正常运行,其二为了增加用户的体验,由服务的消费者调用自己的方法作为返回,暂时给用户响应结果的一种解决方案;
Sentinel相对于Hystix:
和Nacos一样,需要自己独立部署一个服务
一套web界面可以进行更加细粒度的配置,流控,速率控制,服务熔断,服务降级。
摘抄一句官网的话:Sentinel 是面向分布式服务架构的流量控制组件,主要以流量为切入点,从限流、流量整形、熔断降级、系统负载保护、热点防护等多个维度来帮助开发者保障微服务的稳定性。
更多详细详见官网: Go Sentinel
下载地址:https://github.com/alibaba/Sentinel/releases
下载的是一个jar,下载后直接 java -jar 执行即可部署服务,可见也是Java开发的,启动之后默认端口为8080,我们访问localhost:8080即可,账号和密码默认均为:sentinel
-
我们继续创建一个maven项目,改pom,创yml,写启动函数,一步到位
<dependencies> <!-- SpringCloud ailibaba nacos--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel-datasource-nacos 持久化需要用到--> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <!-- 远程调用依然使用 openFeign --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> <version>2.2.0.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--监控--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--监控 以json格式输出信息--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-hateoas</artifactId> </dependency> </dependencies>
-
创yml
server: port: 8804 spring: application: name: sentinel-server cloud: nacos: discovery: server-addr: localhost:8848 sentinel: transport: #配置Sentinel的服务地址 dashboard: localhost:8080 #默认8719端口,本地启动 HTTP API Server 的端口号 port: 8719 #监控 management: endpoints: web: exposure: include: '*'
-
创启动函数
@EnableDiscoveryClient @SpringBootApplication public class SentinelApplication { public static void main(String[] args) { SpringApplication.run(SentinelApplication.class); } }
-
写测试接口
@RestController public class SentinelController { @GetMapping("/test1") public String test1(){ return "This is test1"; } @GetMapping("/test2") public String test2(){ return "This is test2"; } }
-
然后我们登入Sentinel监控页面,发现什么也没有,Sentinel是懒加载的,在监控接口之前,需要我们手动跑一下接口,即可激活监控 : localhost:8804/test1
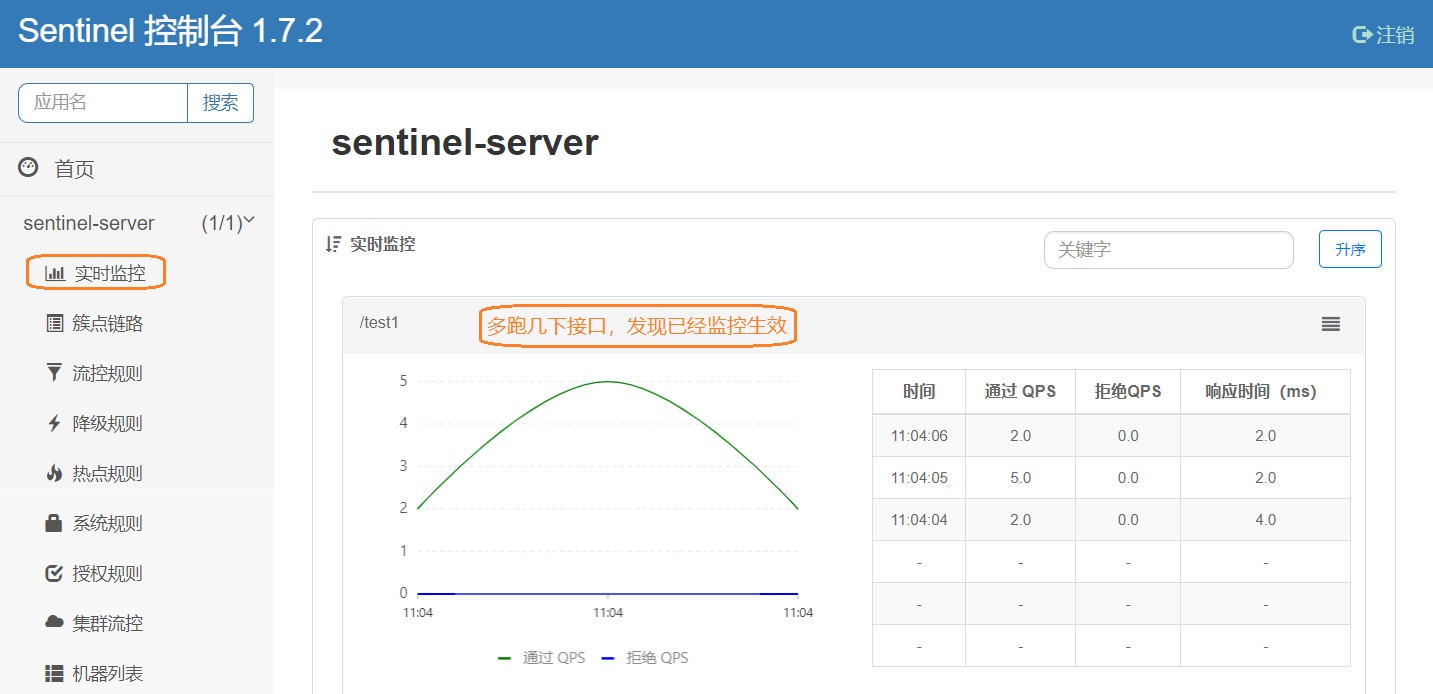
-
看见左边Tab栏的功能嘛,接下来我们把常用的说道说道,首先第一个实时监控就是一个监控展示页面,这个无需多讲,下面开工
簇点链路
在该Tab栏中,主要显示监控的的接口(需要有流量激活),右边的配置才是我们的学习重点也就流控规则、降级规则、热点规则、授权规则,在Tab栏中都有单独的模块进行设置,也可以在簇点链路中点击相应图标为某一个接口设置相关规则
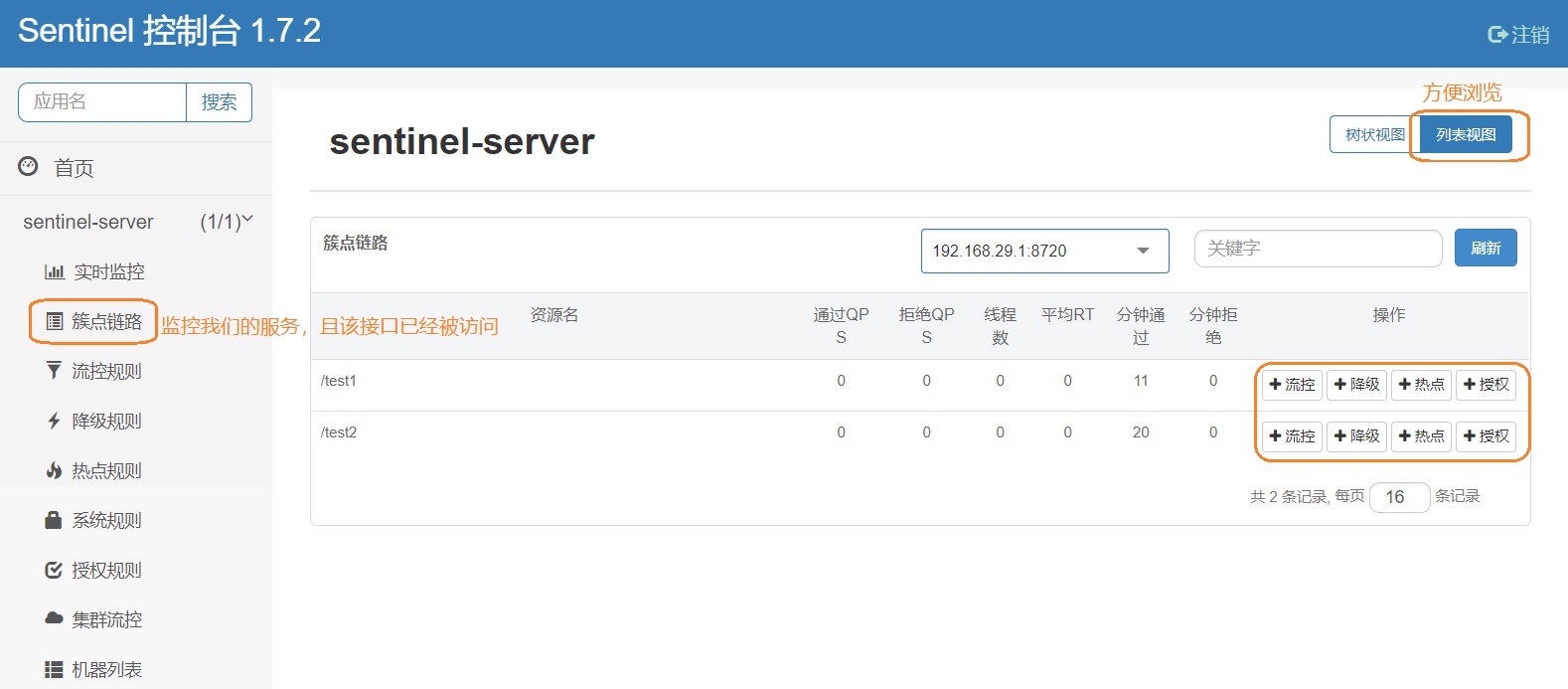
流控规则
我们看的第一个就是流控规则,我们对test1这个接口设置流控,来到下面这一个页面
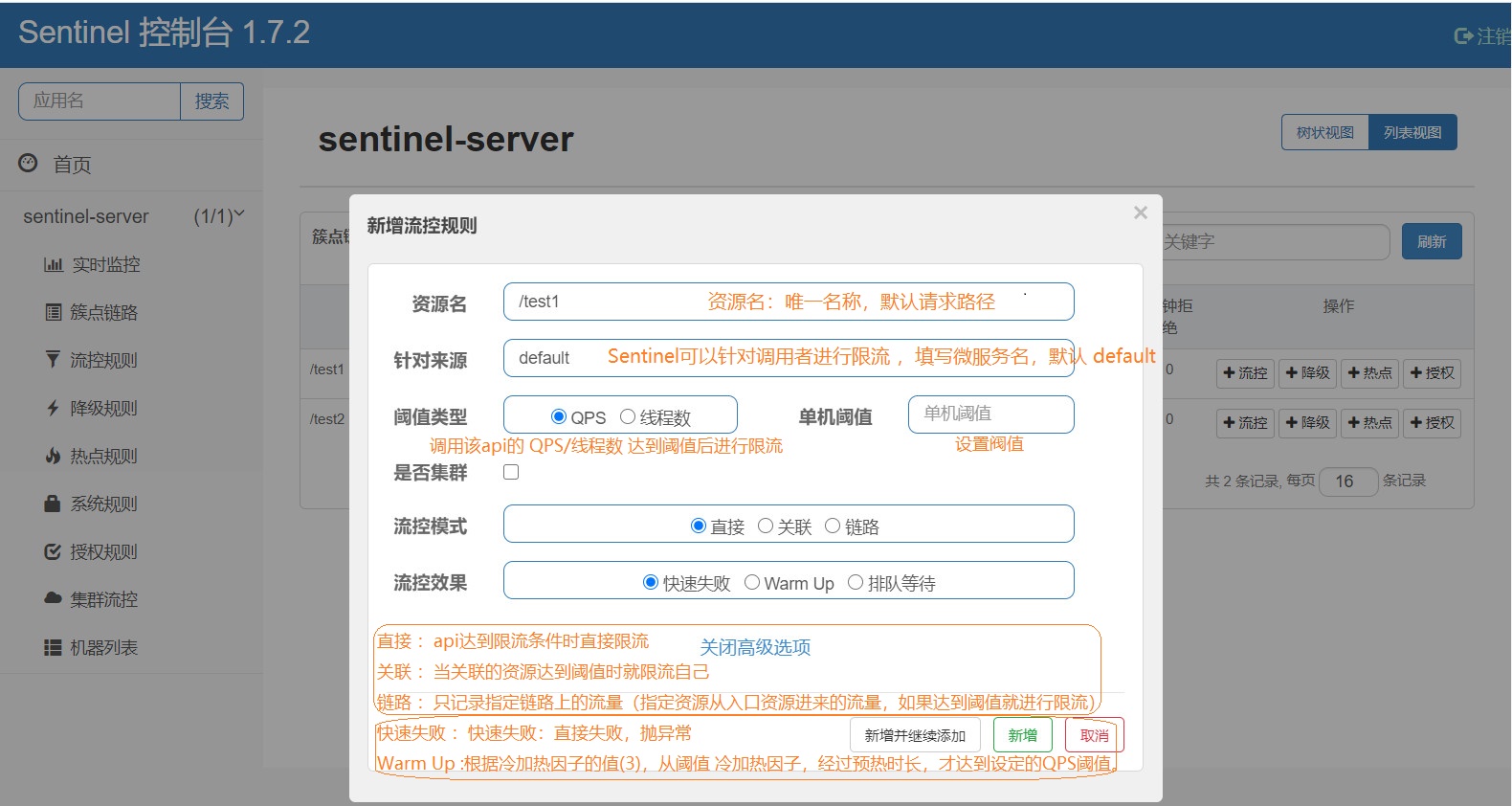
我们为test1接口,设置如下的流量控制规则阀值为1,其余的按照上面默认的来,
也就是:
阀值类型:QPS
阀值:1
流控模式:直接
流控效果:快速失败
接下来我们访问我们的test1接口,在一秒内访问一次一点问题都没有,如果在一秒内连续的访问超过阀值呢,我们来看看
也就是说当我们的流量超过阀值后,根据流控模式直接限流不让访问,且根据流控效果快速失败直接返回Sentinel定义的提示信息
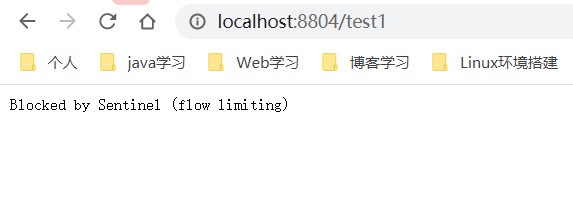
下面我们再来说一下流控模式的另一个模式:关联流控
-
需要说明的是:这个阀值对test1 、test2两个接口同时生效
效果是什么呢?
当我们对test2接口进行流量跑通的时候,超过阀值1秒/次,就会对test1接口进行限流以及根据快速失败返回Sentins定义的提示信息
场景如下:
订单服务调用支付服务完成下单操作,但是当支付服务已经快撑不住的时候,需要告诉订单服务,我吃不消了,你限流从而减轻我的压力,我们应该对订单服务限流,从而缓解支付服务的压力 ,就是这么个意思!
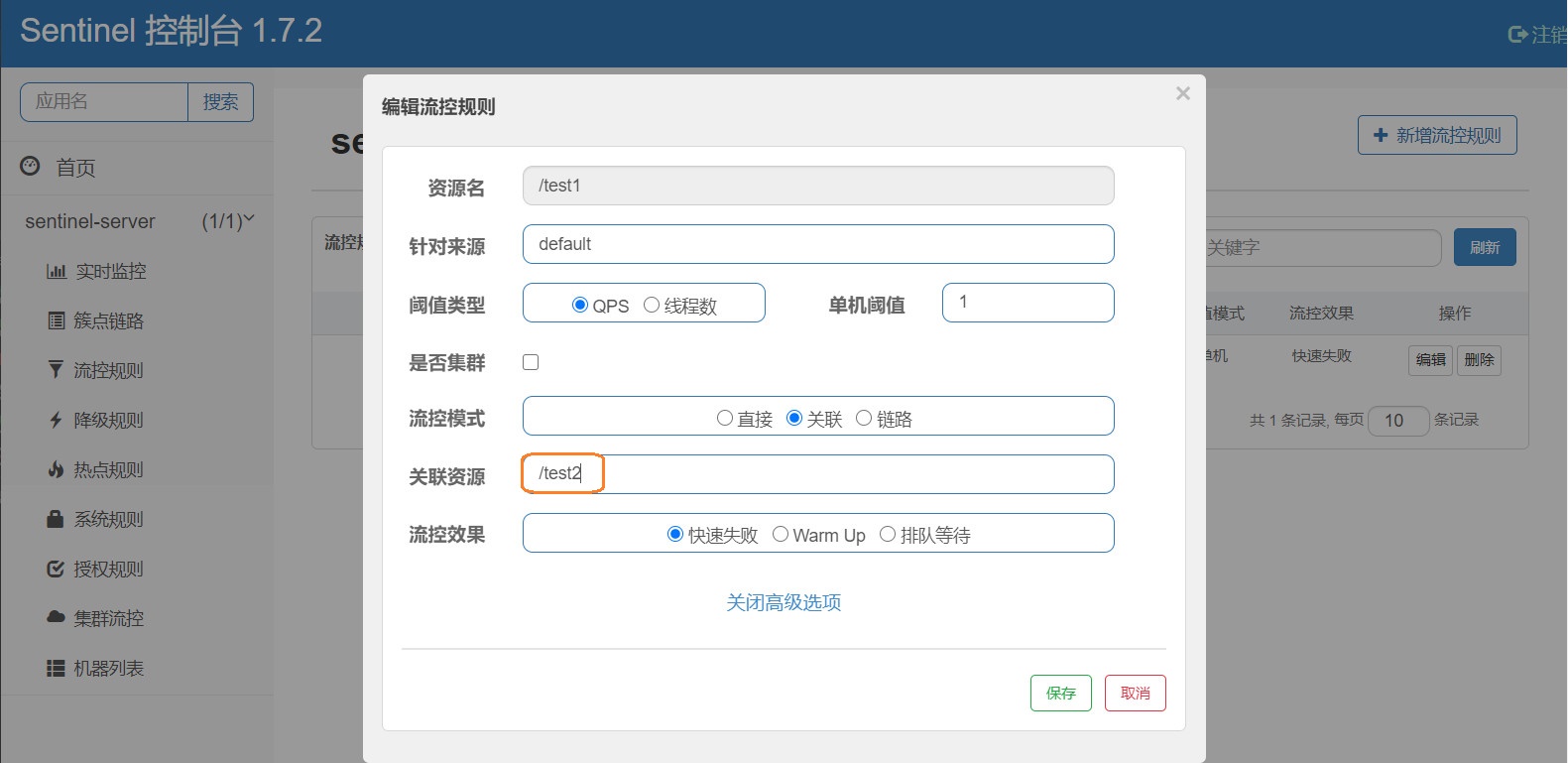
下面我们再来说一下流控模式的最后一个模式:链路流控
这里,我还没有涉及到服务之间的相互调用,但这个也很简单,我就口头阐述,链路流控什么意思?
首先对直接访问接口进行流控,也就是test1这个接口阀值只允许在1秒/次
其次服务之间的相互调用,形成很多的调用链路下面我们用两个链路来说明
链路1 :A -> Z
链路2 :X -> Z
Z作为一个两个调用链路中的一个公共服务服务,被大家调用
如果我配置了如下流控规则:没写的默认上述配置
资源名 A
流控模式:链路
入口资源:Z
这个时候 A -> Z 这条链路就被流控了,在该链路中无论A或者Z 超过阀值就会触发流控,而X -> Z这条链路我可没给他配置流控,他还是随便访问的,就是这么个意思
上面我们已经将流控效果解释完了,下面我们来说道说道流控效果:快速失败、Warn Up、排队等候
-
第一个说明的也就是最简单的流控效果:快速失败(直接拒绝访问)
每次我们流控生效的时候,看到的那个页面就是默认的快速失败产生的页面(默认)
-
然后就是第二个流控效果:Warm Up (预热)
这个比较适用与秒杀系统,平时流量得心应手的处理着,某个瞬间突然高并发的流量大炮接踵而至,直接把系统拉升到高水位可能瞬间把系统压垮,通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。warm up预热主要用于启动需要额外开销的场景,例如建立数据库连接等。
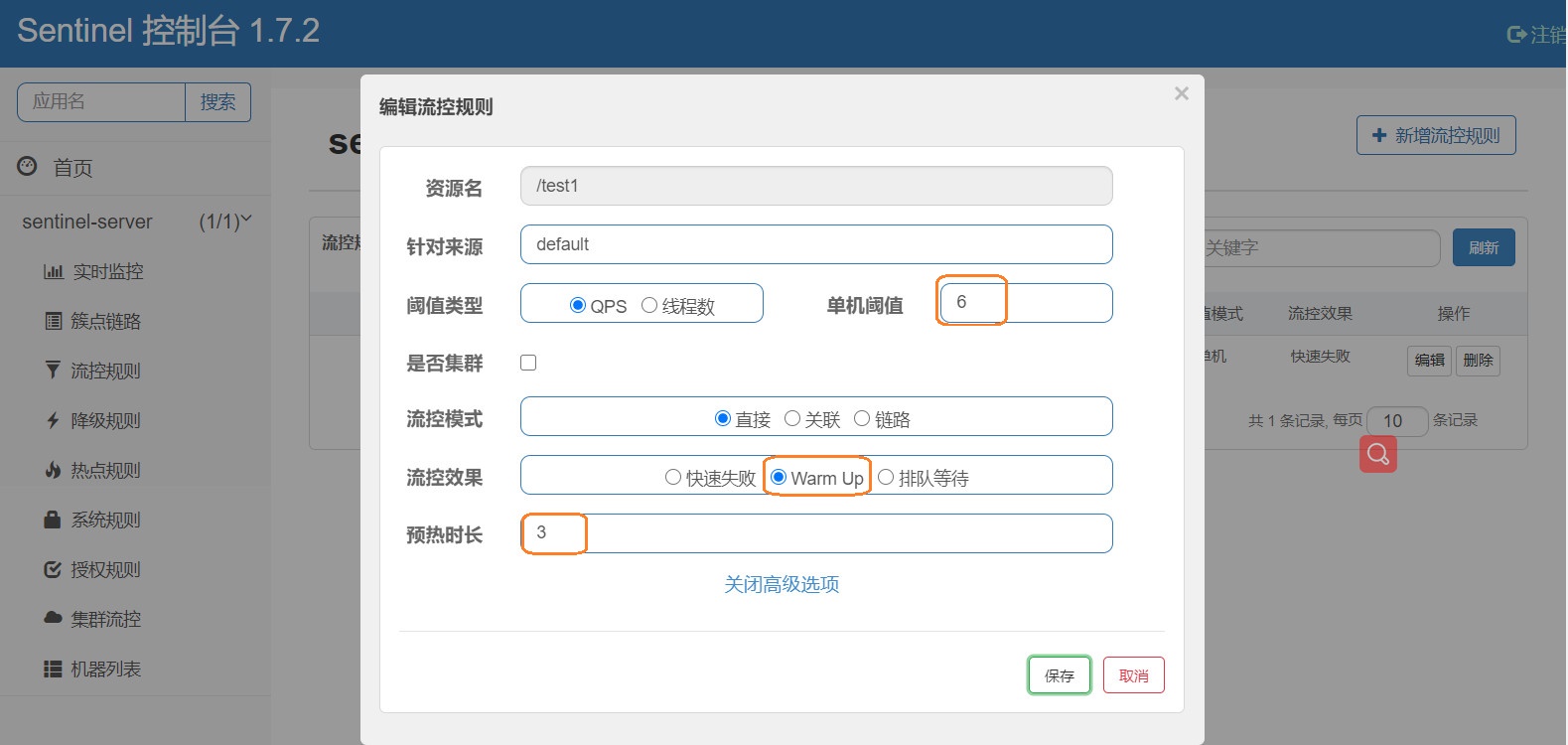
我们来详细说一下这个预热流控效果到底是怎么回事
官方说的是根据冷加载因子(默认3),阀值我们设置的为6,那儿会得到一个计算公式
阀值 / 冷加载因子(3)会得到一个值,这个值就是我们系统初开始提供的qps,
然后我们设置了一个预热时长为3
意思就是test1这个接口最开始的QPS阀值为6 / 3 = 2 QPS,然后再3S之内,慢慢的将QPS提高,直到达到6为止
我设置的是个数据就很方便测试,刚开始,我们一秒按三次F5不过分吧,这点手速都没有不配单身,最开始我们的QPS只有2,我们请求三次试一试发现被流控了,然后我们保持2次/秒继续发着请求,三秒之后发现QPS提高到了6
然后我们就还剩最后一个流控效果了: 排队等候
顾名思义,就是排队嘛,当我们的QPS阀值为3的时候,加入来了10个并发怎么办,直接拒绝访问并提示流控信息?排队等候不会不让他们访问,而是会让他们等候,我们只有允许三个请求进来,其余的在外面等到,依次处理,当等待时长过长,无非就是超时重试嘛,有点类似于消息队列的异步削峰效果
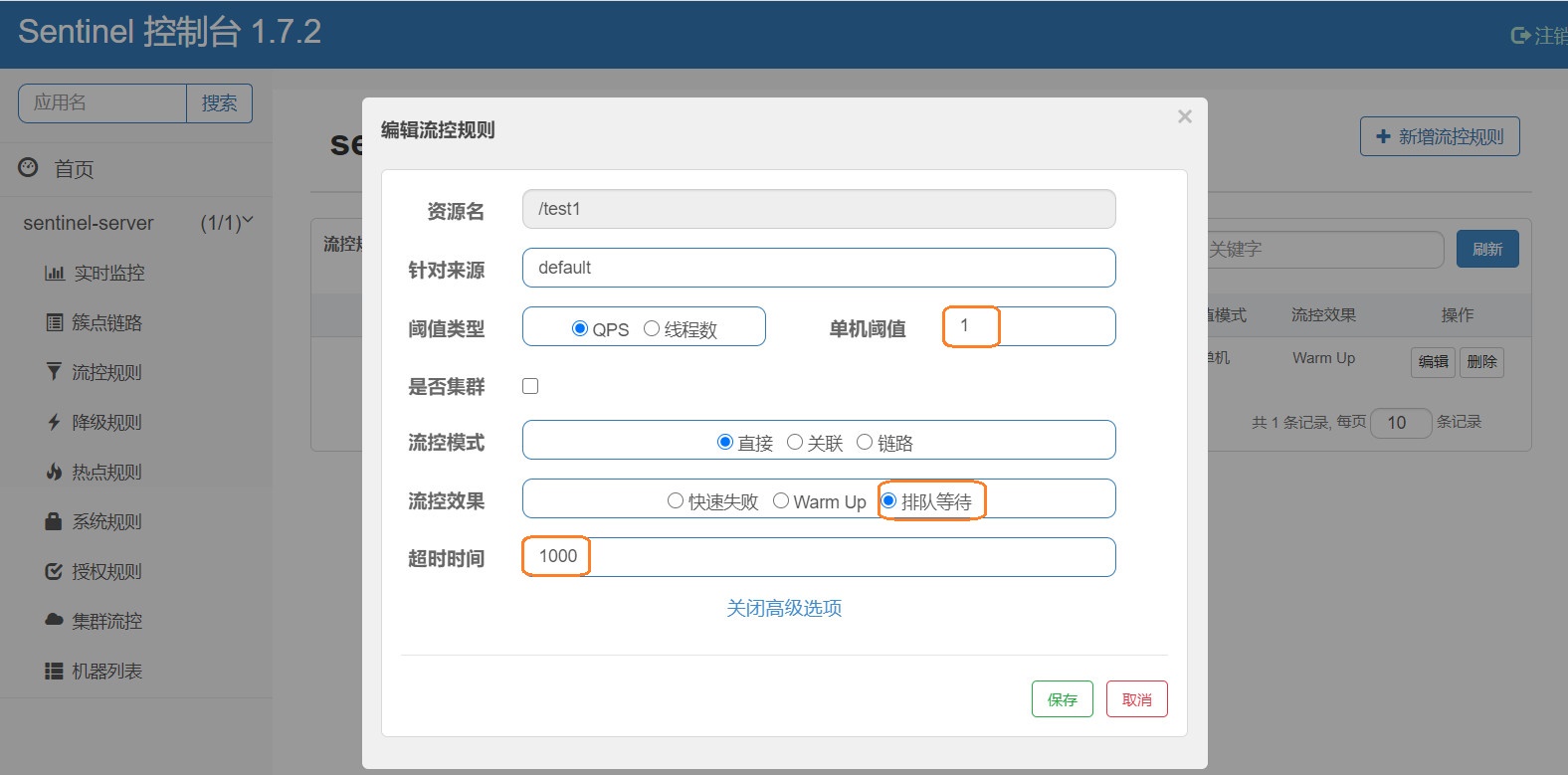
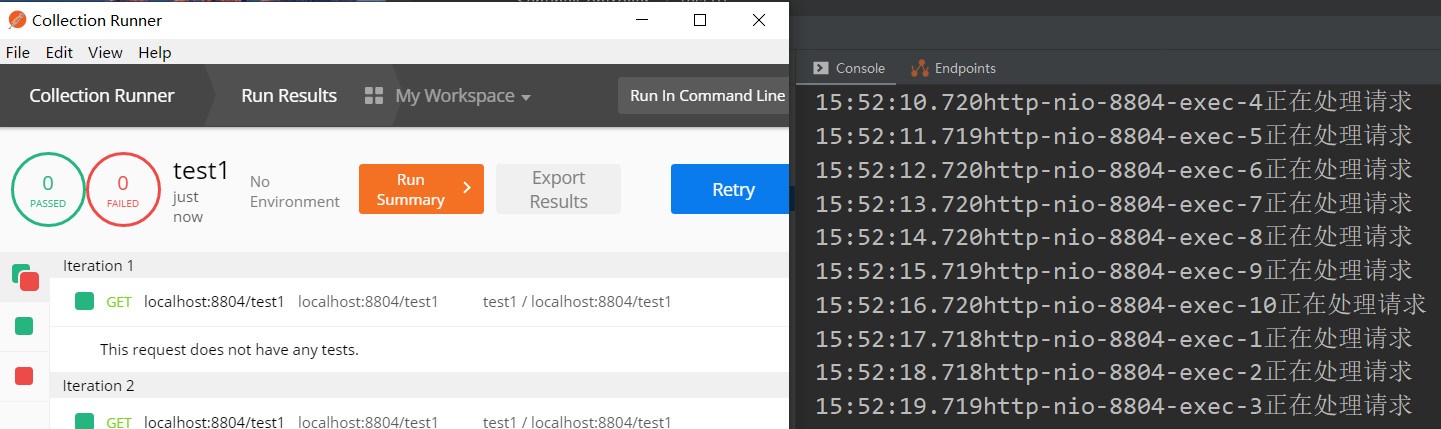
上面我们为test1接口配置了流控,QPS为1,超时时长为1秒,为了方便测试,我们需要在test1接口中打印一下相关信息,看一看
@GetMapping("/test1") public String test1() { System.out.println( LocalTime.now() + Thread.currentThread().getName() + "正在处理请求"); return "This is test1"; }
重启后开始测试,这次我们不能再手点了,我们使用postman压测,开10个线程,每个线程执行一次该请求,请注意观察我打印的时间,就是一秒只处理一个请求
流控相关的就到这里结束吧,下面我们开始另一个篇章,降级规则
降级规则
熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。 ==Hystrix有半开状态测试接口是否恢复,Sentinel通过设置降级时间来重新测试==
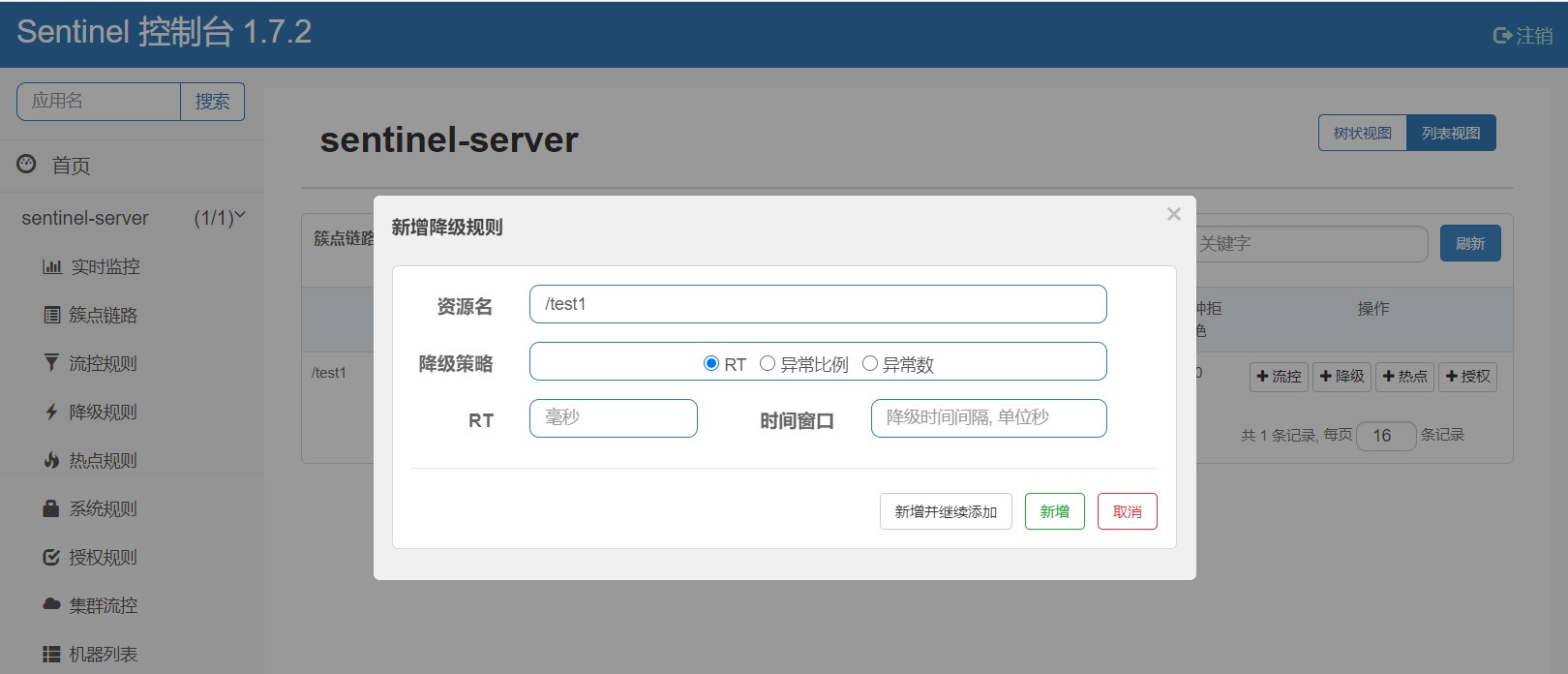
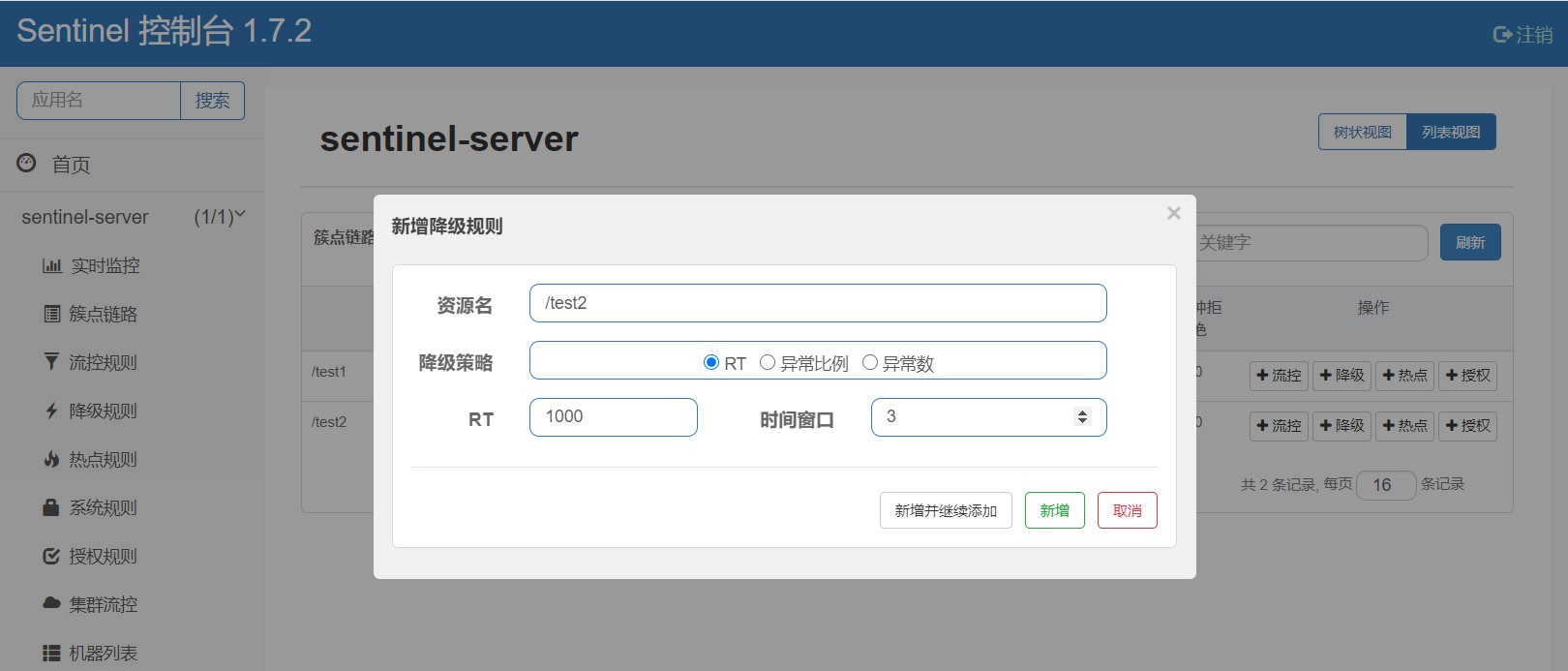
一共有三个降级策略,我们简单说一下
-
时间窗口是固有的,通过时间窗口设置的时限来恢复关闭降级
RT(平均响应时间):当 1s 内持续进入 N 个请求,对应的平均响应时间均超过阈值,且在时间窗口时间以内的请求 >= 5,那么就会触发降级,那么在接下的时间窗口期之内,对这个方法的调用都会自动地熔断。窗口期过后,降级失效,恢复调用,注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。
异常比例 :当资源的每秒请求量 >=5(默认,可配置),并且每秒异常总数占通过量的比值超过阈值之后,资源进入降级状态,即在接下的时间窗口之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
异常数 :当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态。
-
首先我们来测试一下平均响应时间:RT
-
接口中,我们睡眠1秒,然后平均响应时间也设置为1秒,这样一个请求的响应肯定会超过阀值,用作测试RT,这个 test2接口 我们就单独针对降级,流控就不设置了
-
@GetMapping("/test2") public String test2() throws InterruptedException { Thread.sleep(1000); System.out.println("测试RT"); return "This is test2"; }
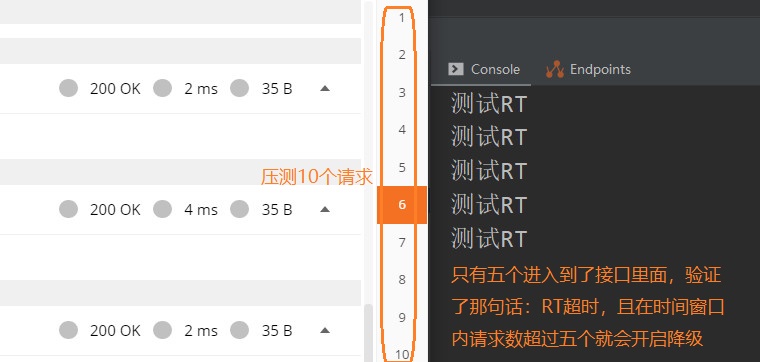
我们在时间窗口之内再通过浏览器的方式访问接口,发现降级已经生效,等过了时间窗口设置的时间后,降级关闭,可正常访问
下面我们开始说第二个降级策略:异常比例
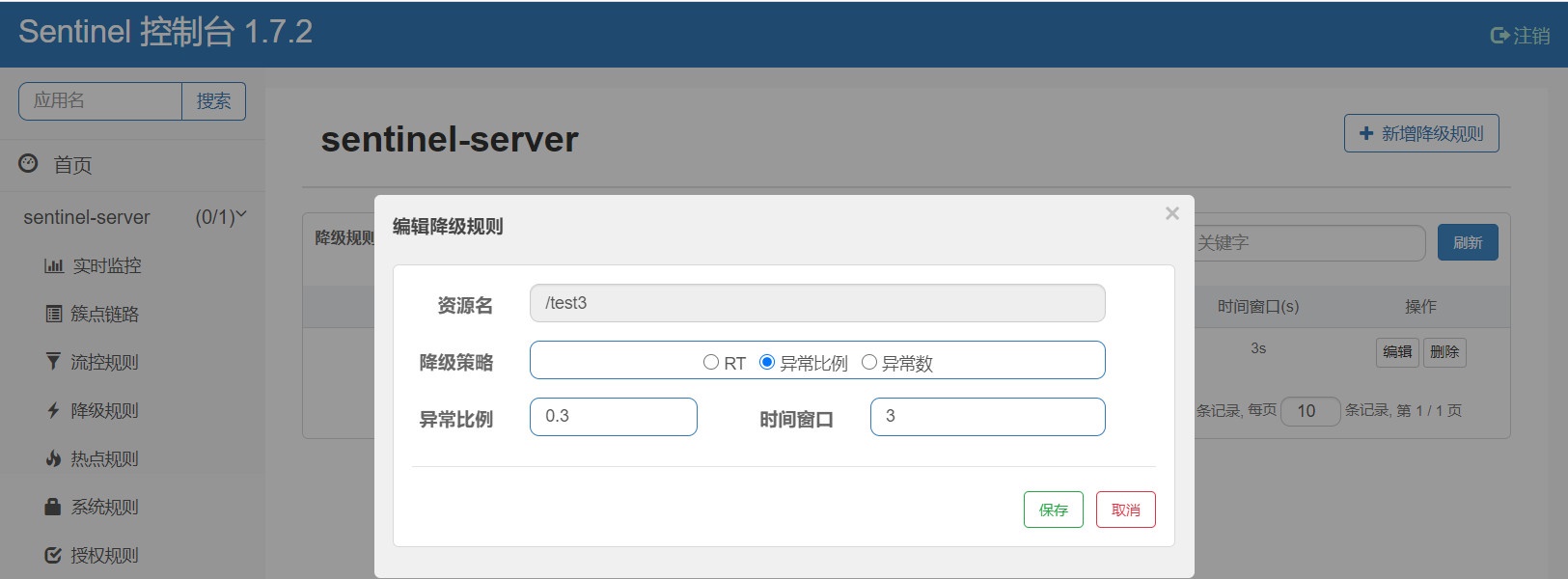
@GetMapping("/test3") public String test3() throws InterruptedException { System.out.println("测试异常比例"); int i = 10 / 0; return "This is test2"; }
压测10个请求,代码中,我们在抛出异常之前进行了控制台输出,因为抛出了异常,不好截图,我就直说了吧,只处理了五个请求,所以得出一个结论:
当单秒请求并发超过5
且出现异常的请求占总的请求的比列超过了我们配置异常比例时就会发生降级
-
至于最后一个异常数,我相信大家看都能看明白,这里就不做代码测试了,知道有这么个东西就好了,那么我们就翻篇进入下一个知识点吧
热点规则
[来自官方] 何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
@GetMapping("/test4") @SentinelResource(value = "test4",blockHandler = "duty_test4") public String test4(@RequestParam(value = "p1" ,required = false)String p1, @RequestParam(value = "p2" ,required = false)String p2) { System.out.println("测试热点参数" + "--" +p1 + "--" + p2); return "This is test4"; } //test4de 兜底方法,现在我们不用Sentinel默认的那个提示了,用自定义的 public String duty_test4(String p1, String p2, BlockException e){ System.out.println( p1 + p2); return "好像出了点问题"; }

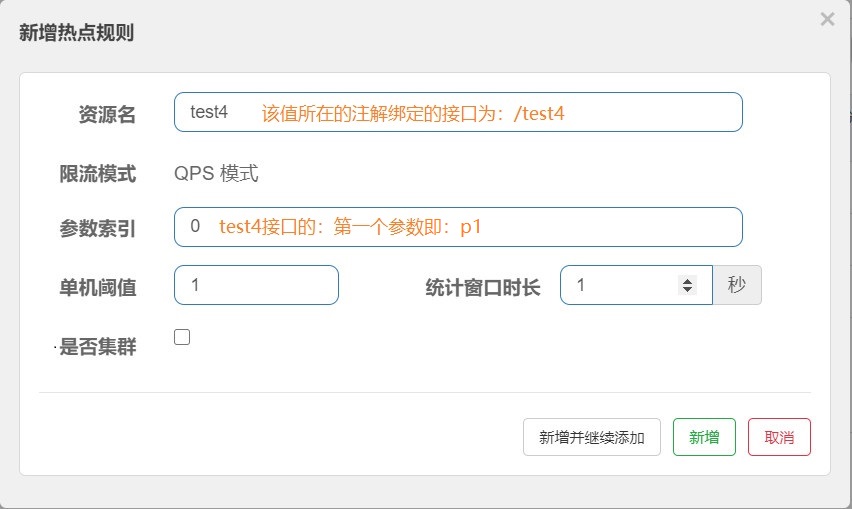
添加了该热点规则后,如果我们的请求中的只要带有p1这个字段,在达到阀值的时候就会降级,因为自定义了降级后处理函数:duty_test4,就会执行这个兜底函数
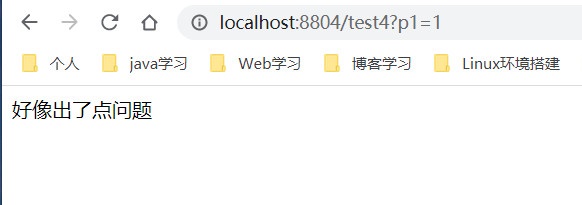
为了更加明白的解释他的意思,我门访问一下接口试试:
http://localhost:8804/test4?p1=1 [ 降级生效 ]
http://localhost:8804/test4?p2=2 [ 降级没有生效 ]
明白了吗?也就是说,在我们配置参数索引为0的时候,就绑定了p1参数,一旦请求中有这个参数,且QPS达到阀值,就会启用降级
下面还有个高级选项,一起来看看吧
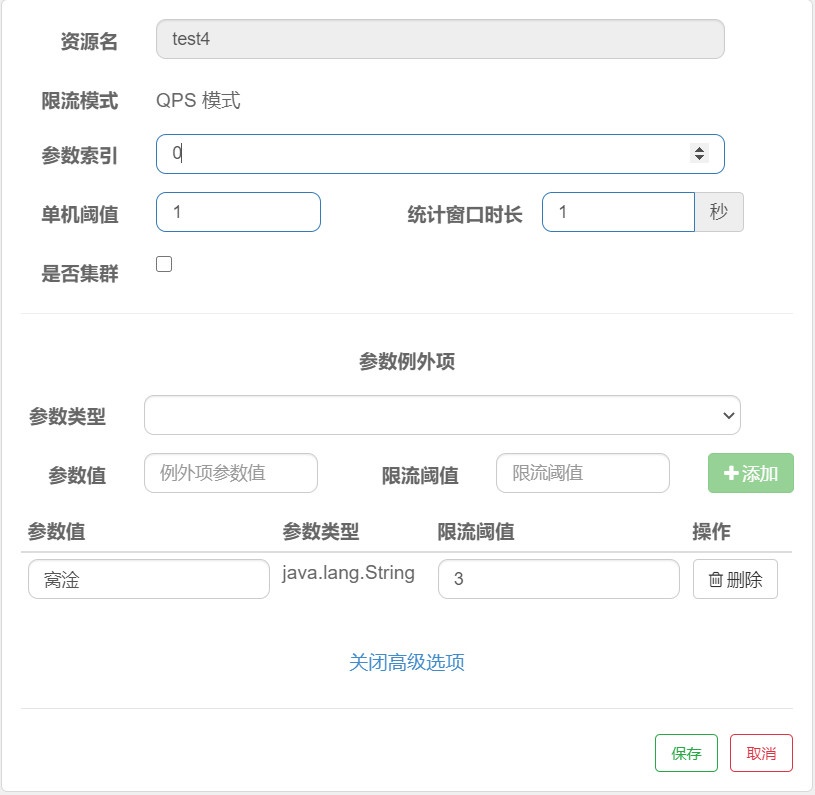
首先参数类型那一栏是个下拉框,包含了8大基本类型和一个String类型,选择String,参数值我们设定为 “窝淦”,限流阀值为3,添加即可出现和我上面这图一样的效果,当然这些高级选项都是基于我们前面配置的参数下标为0的p1的,效果就是,如果没有这些设置,我们的p1在热点规则的制约下只能达到1QPS,但是当我们给p1赋值为 “我淦” 的时候,QPS可以调到3,不会触发降级效果,这就是参数列外形,顾名思义 列外,列外...,就是不走寻常路
系统规则
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(
EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
效果就是:对整个系统添加限流但是,我们不建议使用,这个跳过
SentinelResource注解
要说的就是配置兜底函数的实现
-
自定义方法,就拿我们刚刚测试代码做说明,原封不动
@GetMapping("/test4") @SentinelResource(value = "test4",blockHandler = "duty_test4") public String test4(@RequestParam(value = "p1" ,required = false)String p1, @RequestParam(value = "p2" ,required = false)String p2) { System.out.println("测试热点参数" + "--" +p1 + "--" + p2); return "This is test4"; } //test4de 兜底方法,现在我们不用Sentinel默认的那个提示了,用自定义的 public String duty_test4(String p1, String p2, BlockException e){ System.out.println( p1 + p2); return "好像出了点问题"; }
在接口函数的上方的注解:@SentinelResource(value = "test4",blockHandler = "duty_test4")
value:作为绑定接口的唯一标识,在Sentinel控制台中国添加热点规则或者其他规则使用,用于定位
blockHandler :指定另一个函数,用作替换当降级发生时执行的默认函数,以后不会出现系统定义的那个降级提示了,替换的是我们自定义的函数,我们可以在这里返回一些我们应该返回的错误信息和状态码等
对比Hystrix,他也可以实现将自定义返回封装到一个专门的类中,实现复用和代码防融合,另外搭配一个属性:blockHandlerClass指定该类即可,blockHandler 找的就是该类中的兜底函数了。
-
fallback 和 blockHandler
上一个列子我们记录了 blockHandler 属性的作用是当发生降级时,blockHandler指定的函数会替换掉 Sentinel自定义函数用作返回
而fallback属性的作用在于:未触发降级的情况下,接口函数抛出异常就会执行fallback指定的兜底函数
-
忽略异常
@SentinelResource注解还可以配置异常忽略,属性为:exceptionsToIgnore ,下面我们开启Openfein的时候统一做演示,目前我们常用的属性就以下几个:
@SentinelResource( value = "flag", fallback = "fallback_method", blockHandler = "block_method", exceptionsToIgnore = RuntimeException.class)
OpenFeign服务熔断
好了,来到我们熟悉的领域,远程调用OpenFeign,在上一章的开头,我详细再次咬文嚼字的阅读了熔断和降级的意思后,很明显Sentinel返回的那些默认信息就是一种降级措施,而服务熔断,接下来我们配合着Nacos + Sentinel再次学习一把。
首先提供两个消息提供者,复用之前的模块,我们修修补补就能揭竿为旗,草木皆兵
创建两个除了端口不一致,其余全部一致的两个模块,用作服务提供者,待会实现负载均衡
再创建服务的消费者,通过OpenFeign远程调用两个服务提供者的服务
服务提供者 payment_8801改造
-
pom
<dependencies> <!-- nacos --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel-datasource-nacos 持久化需要用到--> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <!--web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--监控--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--监控 以json格式输出信息--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-hateoas</artifactId> </dependency> </dependencies>
-
yml
server: port: 8801 spring: application: name: payment-server cloud: nacos: discovery: server-addr: localhost:8848 sentinel: transport: #配置地址 dashboard: localhost:8080 #默认8719端口,本地启动 HTTP API Server 的端口号 port: 8719 #监控 management: endpoints: web: exposure: include: '*'
-
主启动函数
@SpringBootApplication @EnableDiscoveryClient public class PaymentApplication8801 { public static void main(String[] args) { SpringApplication.run(PaymentApplication8801.class); } }
-
业务接口,主要返回自己服务的端口,便于区分负载均很是否生效
@RestController @RequestMapping("/payment") public class PaymentController { @Value("${server.port}") private String port; @GetMapping("/test1/{id}") public String test1(@PathVariable("id") Integer id){ return "This is Payment server,Port is " + port + "\t id为" + id; } }
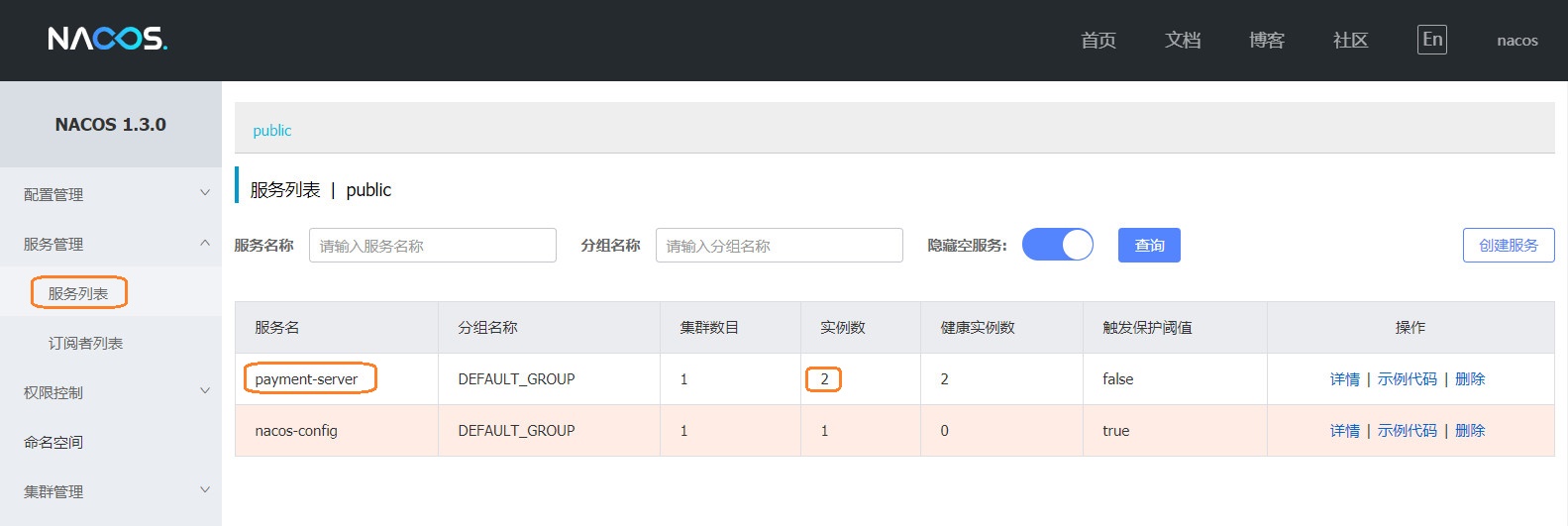
然后当然是直接启动这两个服务提供者啦,注意项目名称要一致,这样形成集群,我们去Nacos看看呢,之前config那个项目被我停掉了,他所以显示为红色,表示服务不可用
服务消费者order_8803 改造
-
pom
<dependencies> <!-- nacos --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel-datasource-nacos 持久化需要用到--> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <!--远程调用 OpenFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> <version>2.2.1.RELEASE</version> </dependency> <!--web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--监控--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--监控 以json格式输出信息--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-hateoas</artifactId> </dependency> </dependencies>
-
yml
server: port: 8803 spring: application: name: order-server cloud: nacos: discovery: server-addr: localhost:8848 sentinel: transport: #配置地址 dashboard: localhost:8080 #默认8719端口,本地启动 HTTP API Server 的端口号 port: 8719 #feign集成hystrix需要配置开启,实现降级 feign: sentinel: enabled: true #监控 management: endpoints: web: exposure: include: '*'
-
主启动函数
@EnableDiscoveryClient @SpringBootApplication @EnableFeignClients(basePackages = "com.nacos.order.clients") public class OrderApplication { public static void main(String[] args) { SpringApplication.run(OrderApplication.class); } }
-
远程调用Feign接口
@FeignClient(value = "payment-server",fallback = PaymentClientDuty.class) public interface PaymentClient { @GetMapping("/payment/test1/{id}") public String test1(@PathVariable("id") Integer id); }
-
远程调用兜底方法实现
@Component public class PaymentClientDuty implements PaymentClient { @Override public String test1(Integer id) { return "OpenFeign远程调用失败调用" + id; } }
-
Controller
@RestController public class OrderController { @Autowired private PaymentClient paymentClient; @GetMapping("/order/{id}") public String openfeignTest(@PathVariable("id") Integer id){ return paymentClient.test1(id); } }
-
好,起服务,看一下我们的订单服务是否可以实现远程负载均很的调用两个支付模块
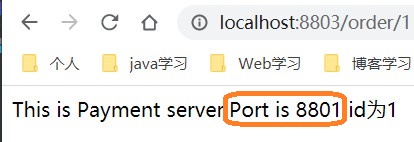
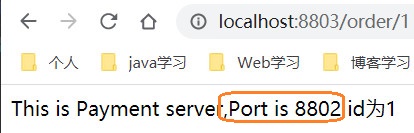
-
再测试一下降级,我们将两个支付模块都给停掉,再访问该接口,如我们预测一般无二
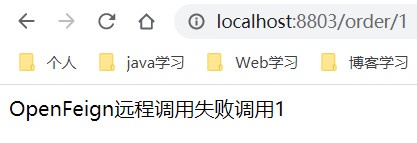
持久化规则
在上面的测试之中,你有没有发现一个问题,当我们配置了相关规则后,只要服务重启,这些规则就会不在,需要从新配置规则,那是因为他们都随着服务的不可用而从Sentinel的内存中销毁了,下面我们来配置将其持久化到Nacos之中,Nacos持久化到哪呢?之前已经说到过,当然是持久化到Mysql啦。
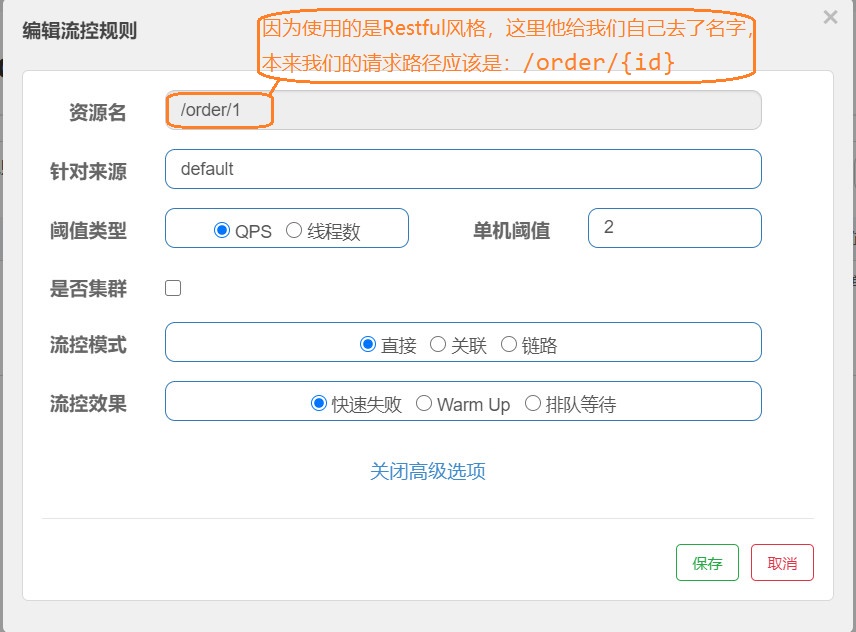
这次我们就是用订单服务做一个演示吧,我们对其进行配置规则
相关的依赖,之前我已经将其添加到pom中,就是
<!-- 后续做持久化用到 --><dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency>
-
在Nacos中配置信息,如下所示,然后发布即可
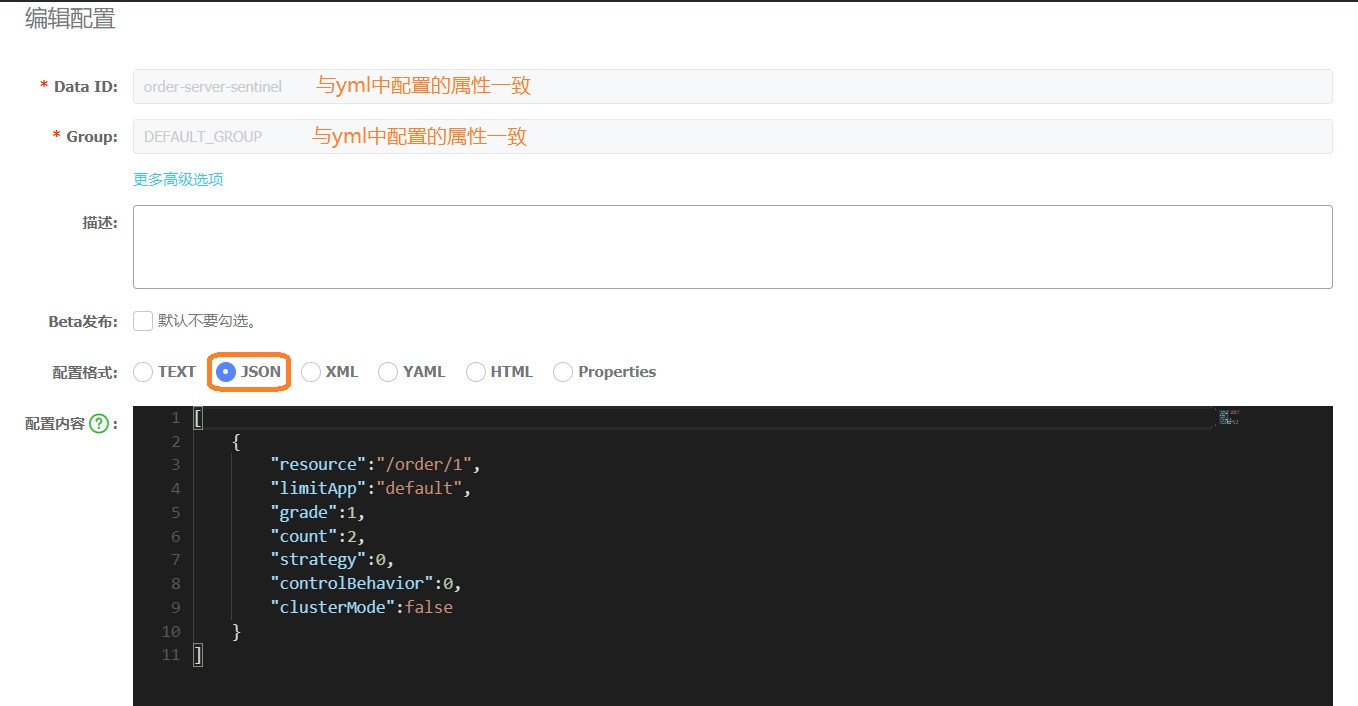
[
{
"resource":"/order/1",//资源名称,这个根据Sentinel给定的为准,定位的
"limitApp":"default",//来源应用
"grade":1,//阈值类型,0线程数,1QPS
"count":10,//单机阈值
"strategy":0,//流控模式,0表示直接,1表示关联,2表示链路
"controlBehavior":0,//流控效果 ,0表示快速失败,1表示warm up,2表示排队等待
"clusterMode":false //是否集群
}
]
-
我们重启订单服务,访问一下接口,让Sentinel监控到,发现配置还在,并没有消失。
Seata(最新版本巨坑)
写在最前面:这个1.2为目前最前最新版,异常错误层出不穷,目前网上相关的博客也少的可怜,只有自己慢慢的测,大多是版本依赖问题,官方文档又糙的很,自定义配置的载入可以为配在用yml中,也可以配在Seata默认读取的文件,这个是我折腾两天才发现的,所以得出那个道理,坐在二排看戏永远是最稳当的,下面的所有配置和依赖都是我排错最后留下的
分布式事务简单介绍
设想在分布式项目中,一个微服务项目照顾一个到多个数据库,数据源也是一个到多个,当一个业务需要服务调用服务的方式才能完成的时候,如何保证两个服务在的统一事务控制,举个列子,下单服务调用支付服务和配送服务,完成一个商品的购买,当下单后,支付服务调用失败怎么办,本地事务肯定是管控不了这个业务线的,不可能下单不付款就给配送吧,宇宙条都经不起这种亏损。
Seata的出现就是应对分布式事务而生的一个组件,下面我们的总结分为两个大的部分进行说明
第一大模块就是建立业务线模块,创建三个模块,分别是订单模块、库存模块、账户模块 实现用户下单减库存且扣除用户金额的业务线,我们使用Seata控制整条业务线的分布式事务
第二大模块就是对Seata的执行原理进行debug解读,Seata的使用时超级简单的,但执行原地是有点复杂的,这个是我们今天总结的重点所在
准备工作
先统筹一下全局,让大家心里有个谱,三个模块,每个模块对应一个数据库订单模块对应订单数据库,库存模块对应库存数据库、账户模块对应账户数据库
Seata下载,这里我们使用最新的版本1.2,注意0.9之前(含)的版本解压文件结构有变化
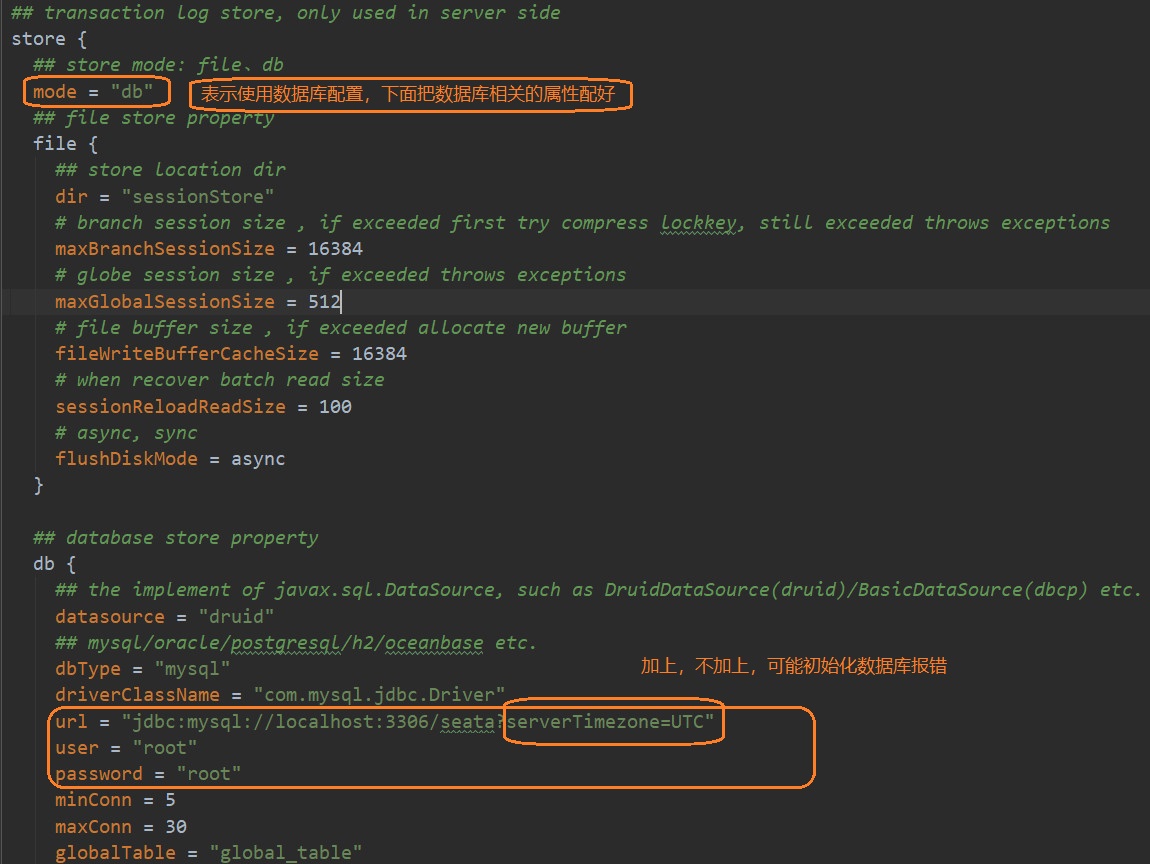
注意下载的版本和引入的seata依赖版本要一致,因为我们使用1.2学习,所以在引入依赖时也得为1.2版本,下载解压开来,修改以下配置文件
conf / file.conf :这个文件会配置在每个参与分布式事务的服务的resource目录下面
conf / registry.conf :这个文件会配置在每个参与分布式事务的服务的resource目录下面
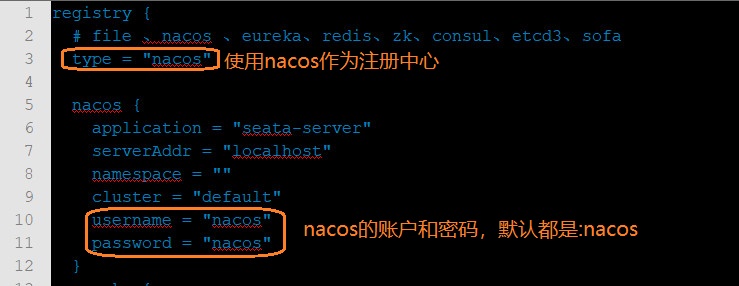
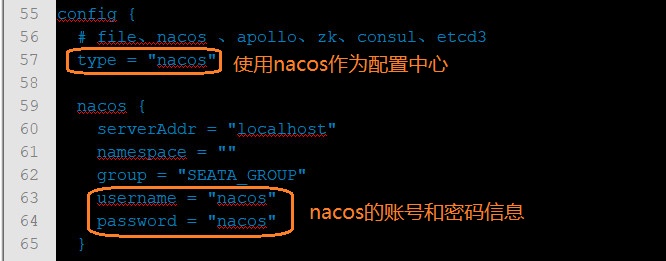
0.9之前Seata需要的数据库sql都是放在conf下面的,到了1.0往后在conf目录下给了一个README-zh.md的脚本说明文件,所有配置都去他指定的网站上自己取舍,下面我们各个去取并配置在我们本地
然后我们访问 : https://github.com/seata/seata/tree/develop/script/config-center
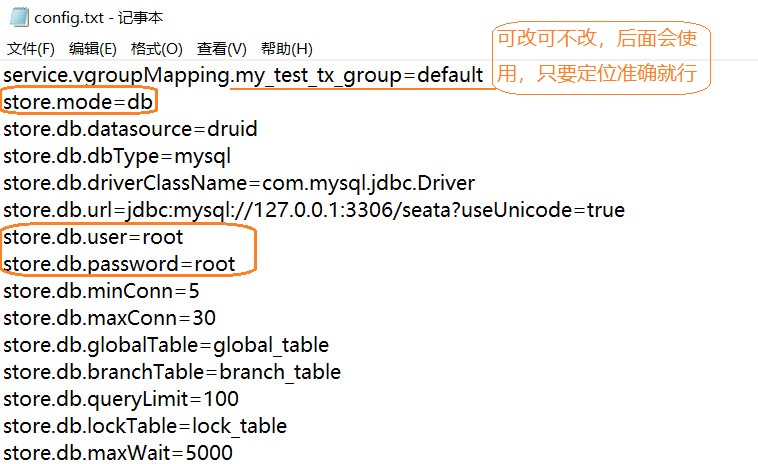
将其下的config.txt拷贝到本地seata安装目录下,修改见下面
将其下nacos目录下的nacos-config.sh 拷贝至本地seata下的conf目录下
将其下的config的内容拷贝下来,写在Seata目录下,我将无关或者多余的配置去掉了留下了下面的内容,我们用的就是数据库做为我们的配置
至于拷贝在conf目录下的nacos-config.sh,我们需要这样操作:
先将Nacos启动,下面会初始化一些数据库的配置配置到Nacos中,以后改数据库相关的属性直接就在Nacos上去改就可以,参与分布式事务业务线的服务都会连接Nacos
然后进入到conf目录,敲开Git的Git Bash Here (右键啊)然后执行下面命令 :
sh nacos-config.sh
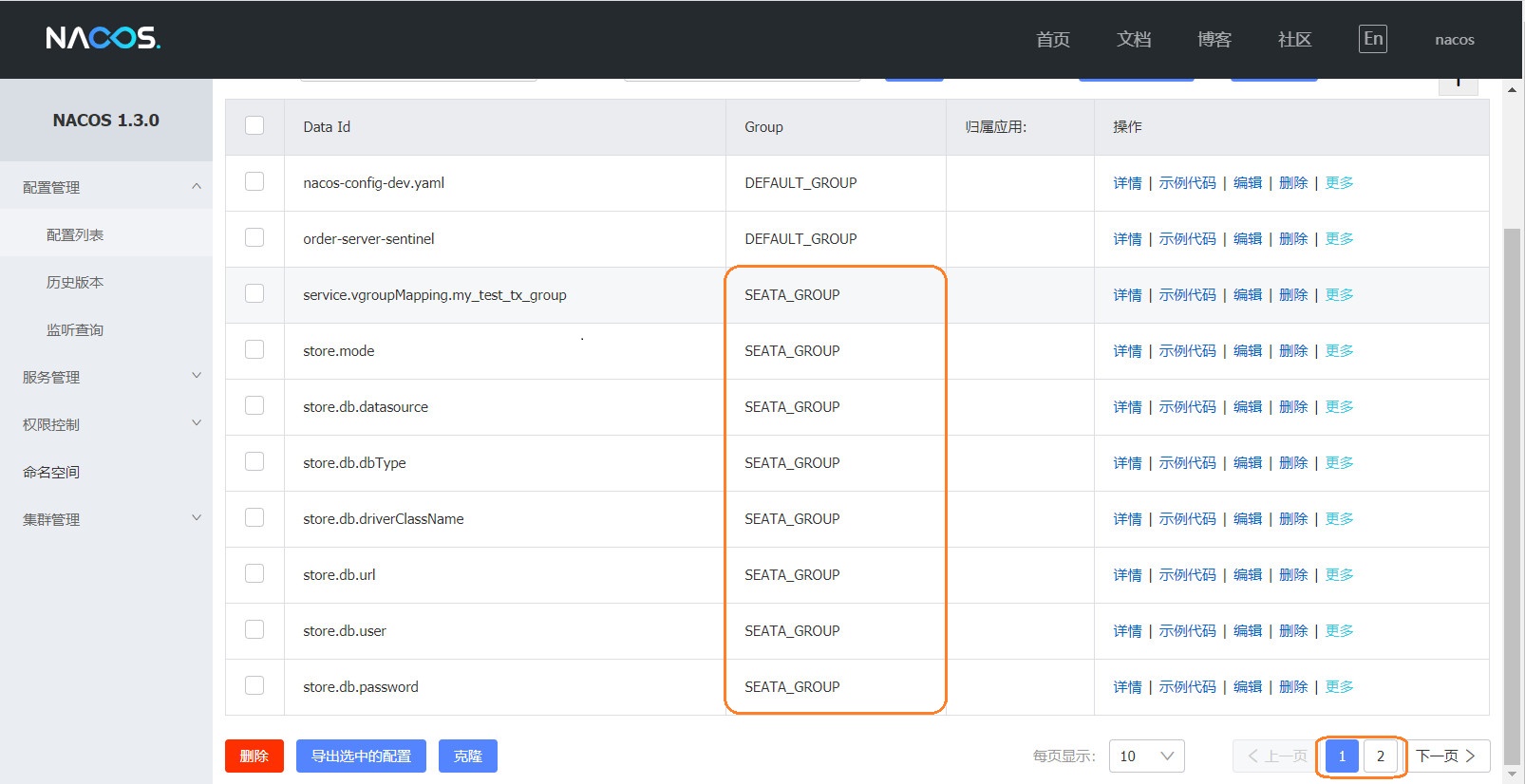
然后我们去我们的Nacos就会看到多了很多的关于数据库连接信息的配置,如下
数据库准备,因为三个模块,三个库,我们建库建表开始(业务表)
建库就自己建吧,这里我就只贴了相关的sql表
-- 在订单数据库 - 创建订单表 CREATE TABLE `order`.`Untitled` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `user_id` bigint(11) NOT NULL COMMENT '用户id', `product_id` bigint(11) NOT NULL COMMENT '产品id', `ount` int(11) NOT NULL COMMENT '购买数量', `money` decimal NOT NULL COMMENT '金额', `tatus` int(11) NOT NULL COMMENT '订单状态:0:创建中,1:已完成', PRIMARY KEY (`id`) ); --在库存数据库 - 创建库存表 CREATE TABLE `storage` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `product_id` bigint(11) NOT NULL COMMENT '产品id', `total` int(11) NOT NULL COMMENT '总库存', `residue` int(11) NOT NULL COMMENT '剩余库存', PRIMARY KEY (`id`) ) ; --在账户数据库 - 创建账户表 CREATE TABLE `account` ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `user_id` bigint(11) NOT NULL COMMENT '用户id', `total` decimal NOT NULL COMMENT '总额度', `residue` decimal NOT NULL COMMENT '剩余可用额度', PRIMARY KEY (`id`) );
还没完,要想被Seata监控全局事务,我们得在参与事务的数据库中多建一个表
也就是 seata/conf 下的 README-zh.md中的 client,那是一个连接,我们点击进去
-
当然你可以可以点击我准备好的: Client
-
将sql语句copy下来,在我们的 订单数据库 和 库存数据库 均执行,
-
这个表是Seata掌控全局事务的基础
CREATE TABLE IF NOT EXISTS `undo_log` ( `branch_id` BIGINT(20) NOT NULL COMMENT 'branch transaction id', `xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id', `context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization', `rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info', `log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status', `log_created` DATETIME NOT NULL COMMENT 'create datetime', `log_modified` DATETIME NOT NULL COMMENT 'modify datetime', UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8 COMMENT ='AT transaction mode undo table';
然后就是最后一个sql脚本了,里面还有Steta自身需要的sql脚本
也就是 seata/conf 下的 README-zh.md中的 server,那是一个连接,我们点击进去
-
当然你也可以直接点击我准备好的 : server
-
进入db目录下,可以发现目前只支持三种数据库,分别是mysql、oracle、pgsql,我们使用的是mysql,那么我们就mysql的内容拷贝下来,在刚刚我们准备的seata数据库中创建seata运行时需要的表,这里我也提供一下,一共三张表,随着版本有点小变化,注意版本问题哦,我是1.2
CREATE TABLE IF NOT EXISTS `global_table` ( `xid` VARCHAR(128) NOT NULL, `transaction_id` BIGINT, `status` TINYINT NOT NULL, `application_id` VARCHAR(32), `transaction_service_group` VARCHAR(32), `transaction_name` VARCHAR(128), `timeout` INT, `begin_time` BIGINT, `application_data` VARCHAR(2000), `gmt_create` DATETIME, `gmt_modified` DATETIME, PRIMARY KEY (`xid`), KEY `idx_gmt_modified_status` (`gmt_modified`, `status`), KEY `idx_transaction_id` (`transaction_id`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8;
CREATE TABLE IF NOT EXISTS `branch_table` ( `branch_id` BIGINT NOT NULL, `xid` VARCHAR(128) NOT NULL, `transaction_id` BIGINT, `resource_group_id` VARCHAR(32), `resource_id` VARCHAR(256), `branch_type` VARCHAR(8), `status` TINYINT, `client_id` VARCHAR(64), `application_data` VARCHAR(2000), `gmt_create` DATETIME, `gmt_modified` DATETIME, PRIMARY KEY (`branch_id`), KEY `idx_xid` (`xid`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8;
CREATE TABLE IF NOT EXISTS `lock_table` ( `row_key` VARCHAR(128) NOT NULL, `xid` VARCHAR(96), `transaction_id` BIGINT, `branch_id` BIGINT NOT NULL, `resource_id` VARCHAR(256), `table_name` VARCHAR(32), `pk` VARCHAR(36), `gmt_create` DATETIME, `gmt_modified` DATETIME, PRIMARY KEY (`row_key`), KEY `idx_branch_id` (`branch_id`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8;
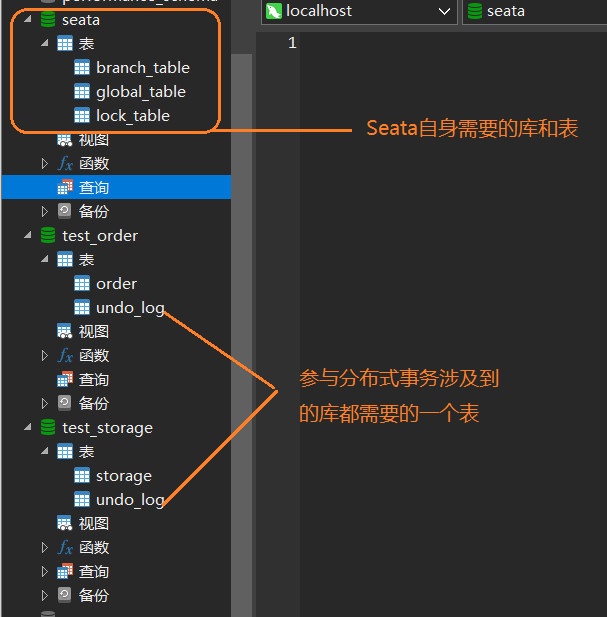
数据库相关的准备工作到这里就算告一段落。现在我们的数据如下所示
订单模块创建
订单模块 : seata_order_9000
-
pom
<dependencies> <!-- nacos --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel-datasource-nacos 持久化需要用到--> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency> <!-- SpringCloud ailibaba sentinel--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <!--Seata--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> <exclusions> <exclusion> <groupId>io.seata</groupId> <artifactId>seata-all</artifactId> </exclusion> </exclusions> </dependency> <!-- 引入与自己版本相同的 --> <dependency> <groupId>io.seata</groupId> <artifactId>seata-all</artifactId> <version>1.2.0</version> </dependency> <!--远程调用 OpenFeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> <version>2.2.1.RELEASE</version> </dependency> <!--web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--监控--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--监控 以json格式输出信息--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-hateoas</artifactId> </dependency> <!--lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> <scope>provided</scope> </dependency> <!-- Mybatis整合SpringBoot --> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.1</version> </dependency> <!-- mysql --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.19</version> </dependency> <!-- jdbc --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> <version>2.3.0.RELEASE</version> </dependency> <!-- druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.22</version> </dependency> </dependencies>
-
ymlserver:
port: 9000 spring: application: name: seata-order-server cloud: nacos: discovery: #Nacos注册中心地址 server-addr: localhost:8848 datasource: type: com.alibaba.druid.pool.DruidDataSource #数据源类型 driver-class-name: com.mysql.cj.jdbc.Driver #mysql驱动包 url: jdbc:mysql://localhost:3306/test_order?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false username: root password: root feign: hystrix: enabled: true logging: level: io: seata: info mybatis: mapper-locations: classpath:mapper/*.xml #这种是采用yml配置Seata的注册中心和配置中心的方式,我们采用特定文件方式 #seata: # enabled: true # application-id: order # 应用 id 为唯一便于区分 # tx-service-group: my_test_tx_group # 事务分组,这个是默认分组,配置文件中修改 # config: # type: nacos # nacos: # namespace: # serverAddr: 127.0.0.1:8848 # group: SEATA_GROUP # userName: "nacos" # password: "nacos" # registry: # type: nacos # nacos: # application: seata-server # server-addr: 127.0.0.1:8848 # namespace: # userName: "nacos" # password: "nacos"
# enable-auto-data-source-proxy: false
#这边自动代理关掉是因为,, seata源码中SeataDataSourceBeanPostProcessor的初始化要比我的datasource初始话晚,导致datasoure不会被包装为代理类,此处我自己代码做了处理
-
入口启动函数
//排除Spring Boot的自动数据源装配,采用我们自己的 @SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) @EnableFeignClients(basePackages = "com.ninja.seata.client") @EnableDiscoveryClient @MapperScan(value = "com.ninja.seata.mapper") public class OrderApplication9000 { public static void main(String[] args) { SpringApplication.run(OrderApplication9000.class); } }
-
实体类
@Data public class Order implements Serializable { private long id; private long userId; private long productId; private long count; private double money; private long status; }
@Data @NoArgsConstructor @AllArgsConstructor public class CommonResult <T> implements Serializable { private Integer statu; private String Messgae; private T data; public CommonResult(Integer statu, String messgae) { this.statu = statu; this.Messgae = messgae; } }
-
mapper以及映射文件
@Mapper public interface OrderMapper { //添加一个订单,并返回订单id void addOrder(Order order); //修改订单的状态为 1 void updateStatus(@Param("id") long id); }
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.ninja.seata.mapper.OrderMapper"> <insert id="addOrder" parameterType="com.ninja.seata.domain.Order"> <selectKey resultType="java.lang.Long" order="AFTER" keyProperty="id"> SELECT LAST_INSERT_ID() </selectKey> INSERT INTO `order` values (null,#{userId},#{productId},#{count},#{money},0) </insert> <update id="updateStatus" parameterType="long"> UPDATE `order` set status = 1 where id = #{id} </update> </mapper>
-
库存、账户的远程调用接口
@FeignClient(value = "seata-storage-server") public interface StorageClient { //减库存 @GetMapping("/storage/reduce/{id}/{num}") public void reduce(@PathVariable("id") Long id, @PathVariable("num") Long num); }
@FeignClient(value = "seata-account-server") public interface AccountClient { //减余额 @GetMapping("/account/reduce/{userId}/{money}") public void reduce(@PathVariable("userId") Long userId, @PathVariable("money") Double money); }
-
service
@Service @Slf4j public class OrderService { @Autowired private OrderMapper orderMapper; @Autowired private StorageClient storageClient; @Autowired private AccountClient accountClient; //下面是我们发生分布式事务问题的函数 //Seata的使用就是这一个注解 + 一堆环境配置,哈哈哈哈哈 //seata开启分布式事务,异常时回滚,name保证唯一即可,也可以不填 //rollbackFor:指定发生什么异常时执行回滚,也可以设置指定什么异常不回归 @GlobalTransactional(rollbackFor = Exception.class) public Long createOrder(Order order){ log.info("----->饿了么来订单啦"); //1: 首先模拟业务线创建一个订单数据 orderMapper.addOrder(order); //2: 然后我们调用库存服务,减库存 storageClient.reduce(order.getProductId(),order.getCount()); //3: 调用账户服务,扣取该用户的钱钱 accountClient.reduce(order.getUserId(),order.getMoney()); //最后这个订单算完完成,我们修改订单状态为已完成:1 orderMapper.updateStatus(order.getId()); log.info("----->恭喜xx选手成功接单,订单号为:" + order.getId()); return order.getId(); } }
-
controller
@RestController @RequestMapping("/order") public class OrderController { @Autowired private OrderService orderService; //便于测试,我们只传数量和金额就可以了,使用get @GetMapping("/create/{count}/{money}") public CommonResult createOrder(@PathVariable("count") Long count, @PathVariable("money") Double money) { //自定义订单,模拟下单数据 Order order = new Order(); order.setCount(count); order.setMoney(money); order.setProductId(1); //商品表准备好这个商品 order.setUserId(1); //账户表也准备好这个账户 Long resultCode = orderService.createOrder(order); if (resultCode == null){ return new CommonResult<>(444, "新增订单失败"); } return new CommonResult<>(200, "新增订单成功",resultCode); } }
-
config :前面我们排除了SpringBoot自带的,这里使用我们的,将数据源交给Seata代理
@Configuration public class DataSourceConfig { @Bean @ConfigurationProperties(prefix = "spring.datasource") public DataSource druidDataSource() { return new DruidDataSource(); } //DataSourceProxy 这个是Seata的东西,初始化数据库代理,且只使用这个 @Bean @Primary public DataSourceProxy dataSourceProxy(DataSource druidDataSource) { return new DataSourceProxy(druidDataSource); } }
-
Seata关于注册中心和注册中心的配置文件
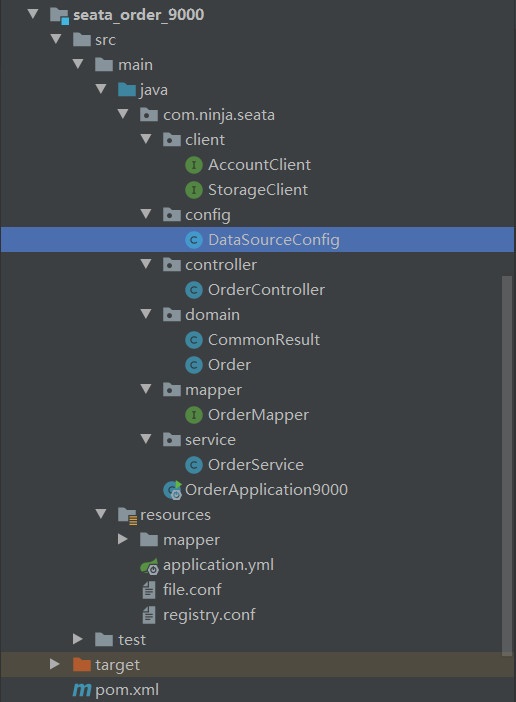
将上面的file.conf 和 registry.conf 拷贝到Resource目录下,整个工程就是这样的
库存模块创建
-
pom
和订单依赖一样
-
yml
修改端口 、 项目名称、数据库连接信息,其余和订单模块一致
-
入口启动函数
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) @EnableDiscoveryClient public class StorageApplication9004 { public static void main(String[] args) { SpringApplication.run(StorageApplication9004.class); } }
-
mapper和映射文件
@Mapper public interface StorageMapper { void redecu(@Param("id")long id, @Param("num")long num); }
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.ninja.seata.mapper.StorageMapper"> <update id="redecu" parameterType="long"> update `storage` set residue = residue - #{num} where id = #{id} </update> </mapper>
-
controller直接调mapper
@RestController @RequestMapping("/storage") @Slf4j public class StorageController { @Autowired private StorageMapper storageMapper; @GetMapping("/reduce/{id}/{num}") public void reduce(@PathVariable("id")Long id,@PathVariable("num")Long num){ storageMapper.redecu(id,num); log.info(id + "商品,扣取库存为:" + num); } }
-
config
配置数据源和订单模块一致
-
Seata关于注册中心和注册中心的配置文件
和订单模块一致
账户模块创建
-
pom
和订单模块一致
-
yml
修改端口 、 项目名称、数据库连接信息,其余和订单模块一致
-
启动入口函数
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) @EnableDiscoveryClient public class AccountApplication { public static void main(String[] args) { SpringApplication.run(AccountApplication.class); } }
-
mapper和映射文件
@Mapper public interface AccountMapper { void reduce(@Param("userId") long userId, @Param("money") double money); }
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.ninja.account.mapper.AccountMapper"> <update id="reduce"> update account set residue = residue - #{money} where user_id = #{userId} </update> </mapper>
-
controller直接调用mapper
@RequestMapping("/account") @RestController @Slf4j public class AccountController { @Autowired private AccountMapper accountMapper; @GetMapping("/reduce/{userId}/{money}") public void reduce(@PathVariable("userId")Long userId, @PathVariable("money")Double money){ accountMapper.reduce(userId,money); log.info(userId + "用户,扣除" + money + "余额"); } }
-
Seata关于注册中心和注册中心的配置文件
和订单模块一致,还是那两个配置文件
环境测试(没有Seata)
上面我们已经将三个模块整装待发,下面是我在没有引入Seata相关配置和依赖下做的测试,先把他跑通,你们可以不用跳过这一步
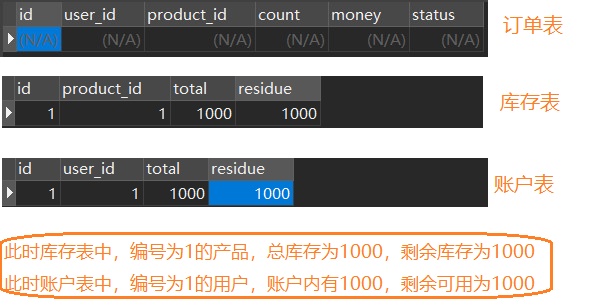
首先商品数据和账户信息在数据库定义好,如下所示
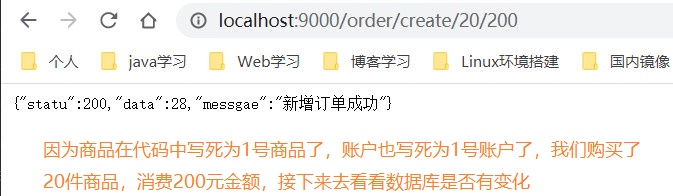
下面我们开测:
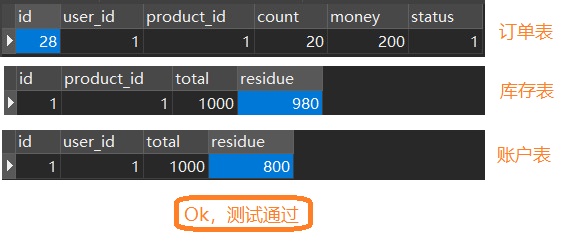
模拟异常环境
因为我们的业务是下订单 -> 减库存 ->扣账户 —>修改状态的业务线,
这里我们就对扣账户这一个服务动点手脚,抛点异常或者线程随眠都可以,让订单模块无法调用账户模块即可,我们就会发订单已经创建了,库存也扣了,但是没有扣钱,怎么办,分布式事务问题就这么如意料般的出现了,下面我们来解决
Seata登场
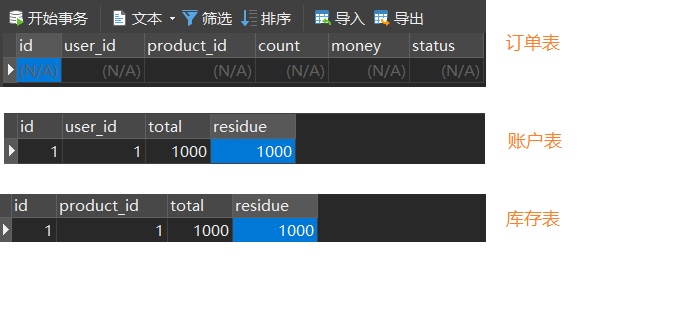
上面三个模块的创建,已经创建好,下面我们启动三个服务,发起请求之前,容我先把我的业务数据库初始化一下,以便待会测试方便观察
下面我们跑接口创建订单,发现抛出了异常,我们再去数据库观察一把,发现三张表还是如我们初始化那般,没有任何变化,到这里,Seata管控全局事务生效,Demo到此结束,下一篇我将会分析Seata的管控全局事务的执行原理(浅到逻辑,不涉及源码)
Seata执行原理分析(AT模式)
在说原理之前,我们先回顾一下我们上面的所作所为,首先我们修改了Seata服务的配置,并将数据库相关的属性推送到了nacos上,其次为我们三个项目添加了Seata相关的依赖,并分别配置了两个Seata的注册中心为Nacos和配置中心为Nacos的文件,最后我们将我们自定义的数据源(Seata代理)加入了容器,并排除了SpringBoot自动封装的数据源,让Seata代理了数据库的超控,然后我们在我们涉及分布式事务的业务类上加了一个Seata的注解,使的全局事务生效,理明白了这些后,下面我们来讲述原理,这个执行原理,主要是通过数据库产生的数据为依据
引入官方的套话:主要实现是靠:一个id + 三组件
-
id : 全局唯一的事务Id,在我们的seata数据库中,每启用一个全局事务,就会产生一个事务ID
TC组件 : 事务协调者 维护全局和分支事务的状态,驱动全局事务提交或回滚。
管控我们三个微服务事务的老大,他来决定一起提交还是一起回滚
TM组件 :事务管理器 定义全局事务的范围:开始全局事务、提交或回滚全局事务。
加了注解的那个服务发起了一个全局事务,在经过老大TC同意后上线一个全局事务
RM组件 :资源管理器 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
相当于就是寄生在各服务上的一个监控者,监控本地事务的执行是否顺利,及时向老大报告各服务的本地事务的情况,
处理过程
-
TM向TC申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的XID
-
XID在微服务调用链路的上下文中传播
-
RM向TC注册分支事务,将其纳入XID对应全局事务的管辖
-
TM 向 TC 发起针对 XID 的全局提交或回滚请求
-
TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求
数据库分析
-
我们将账户表的那个人为异常消除掉,现在属于正常业务线,不会出现异常,在账户服务返回之前我们打一个断点,观察seata数据库中的系统三张表的变化如下所示
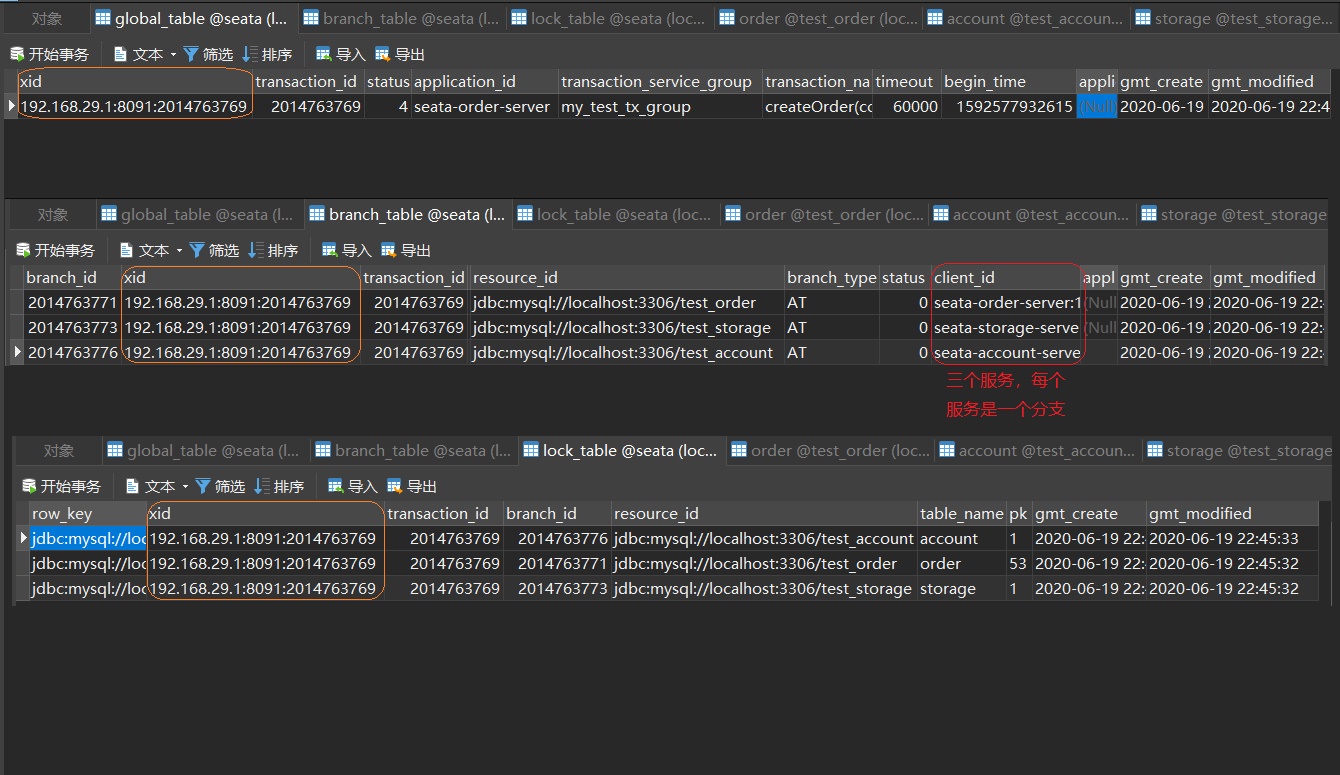
看图说话:
glbal_table:全局事务表 ,是TM向TC申请上线的一个全局事务,这个事务的信息存在在这张表中,关于全局事务的一些信息也在这个表中,特别留意我们上面说到的XID,可以看到,在后面的两张表中,他是贯彻始终没有变的
branch_table :分支表,我们一共三个微服务,每个微服务都是一个分支,他们都在以XID为基准的某个全局事务的管理下
lock_table:锁表,这里应该看row_key这个属性,也是在XID的管辖下,将三张表锁了起来,有了上锁就会有解锁,下面我们通过我们来分析我们的业务在Seata的动向,来解释他们的意思
-
一阶段(RM操盘)
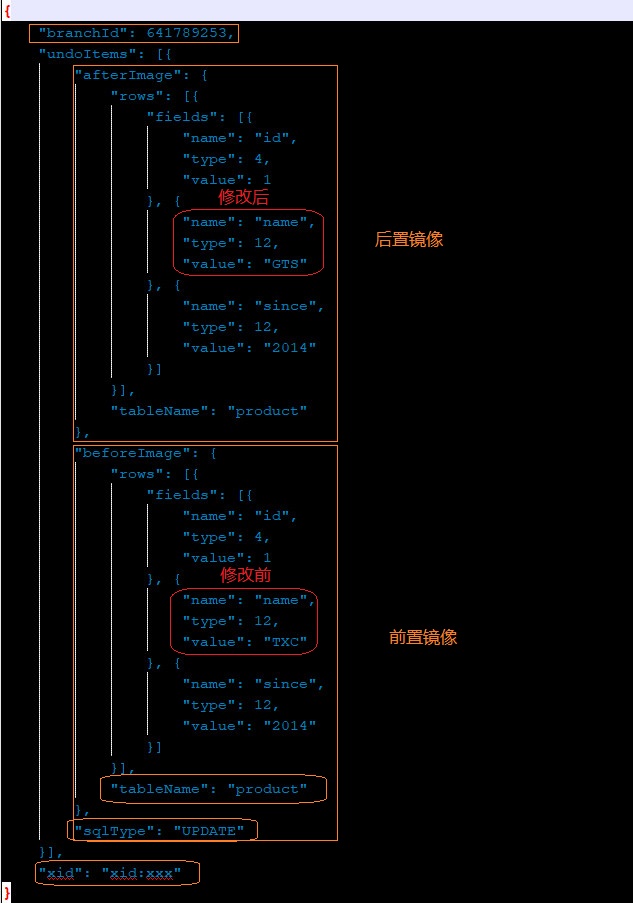
全局事务开启,Seata代理了我们的数据源,他会得到我们的sql,并解析sql,得到其中的关键信息,比如是修改库存:update storage set residue = 100 where id = 1,Seata就会从这条sql中得到操作信息(CRUD)、表信息、修改信息、条件信息,然后会根据这些解析信息先去查询 select residue from storage where id = 1,得到一个我们还没修改前的一条数据,并将这条数据存起来,放在我们的undo_log表(参与分布式事务的库都应该有的表)中,这个操作叫生成“前置镜像”,然后再执行我们的update语句,对该条数据进行修改(并未提交),修改完之后还没结束,Seata会从前镜像中得到此次修改的数据的主键,并根据该主键再去查询修改后的数据,继续存在undo_log表(和前置镜像混合为一个json,在一条数据中)中,看下图的rollback_info,里面就存了前置镜像和后置镜像一些XID等信息
我在官网找到了一张图来验证这个文件,rollback.info的内容如下所示
当生成了日志后,就会想TC注册一个本服务的分支,(上面的图中,三个服务注册了三个分支),注册分支后,还会根据主键id申请表中修改的数据的全局锁(该锁存于锁表中),得到全局锁之后,然后提交本地事务,释放本地锁,最后向TC汇报本地事务的提交情况
一阶段本地事务提交前,需要确保先拿到 全局锁 。
拿不到 全局锁 ,不能提交本地事务。
拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
举一个官方给的列子:
两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。
tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的 全局锁 ,本地提交释放本地锁。 tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的 全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待 全局锁 。

二阶段之回滚(RM操盘)
在全局事务的管理下,当某一个服务出现异常时,TC就会给RM发布回滚请求,这个时候RM就会开启一个本地事务,进行下面的操作
通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录。
数据校验:拿 UNDO LOG 中的后置镜像与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理,
根据 UNDO LOG 中的前置镜像和业务 SQL 的相关信息生成并执行回滚的语句:
提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC
二阶段之提交
收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录
提交后会释放全局锁,其他全局事务才能继续对这条数据进行操作
-
总结一下,我们使用的是Seata的AT模式,该模式的提交一共有两个阶段
-
一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
-
二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
-
二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
-
-
这两个阶段中的读写问题,我们就用官方文档给的列子和说明来理解
-
写隔离
-
一阶段本地事务提交前,需要确保先拿到 全局锁 。
-
拿不到 全局锁 ,不能提交本地事务。
-
拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
比如 :两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的 全局锁 ,本地提交释放本地锁。 tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的 全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待 全局锁 。
如果 tx1 的二阶段全局提交:全局提交,则tx1释放 全局锁 。tx2 拿到 全局锁 提交本地事务。
如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题。
-
-
读隔离
-
在数据库本地事务隔离级别 读已提交 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交 。
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号