【JVM】类加载详解
类加载详解
类加载的时机
遇到 new 、 get static 、 put static 和 invoke static 这四条指令时,如果对应的类没有初始化,则对应的类要进行初始化
这四个指令对应到我们java代码中的场景分别是 :
-
new关键字实例化对象的时候,比如new Student()
-
读取或设置一个类的静态字段(读取被final修饰,已在编译器把结果放入常量池的静态字段除外
-
调用类的静态方法时
-
使用 java.lang.reflect 包方法时对类进行反射调用的时候
-
初始化一个类的时候发现其父类还没初始化,要先初始化其父类
-
当虚拟机开始启动时,用户需要指定一个主类(main),虚拟机会先执行这个主类的初始化
类加载过程
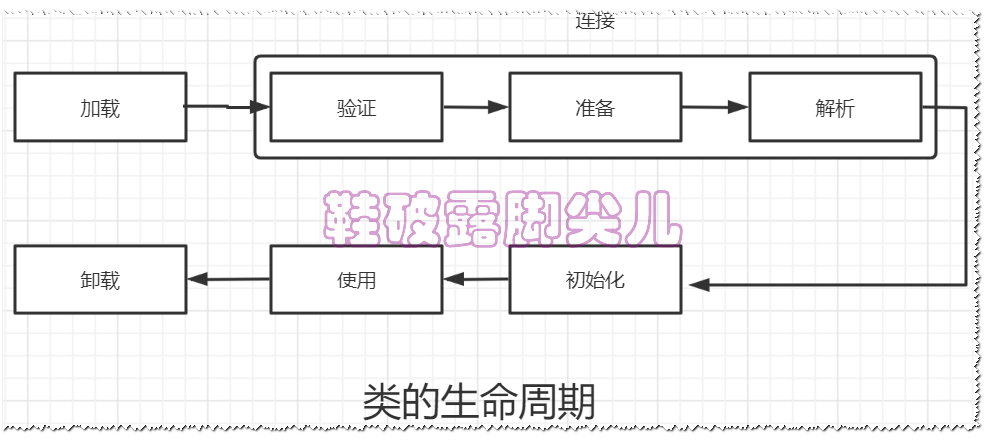
加载
加载 --> class文件 --> Class对象
-
这个加载过程主要就是靠类加载器ClassLoader实现,当然也包括用户自定义的类加载器
在加载的过程中,JVM主要做三件事情:
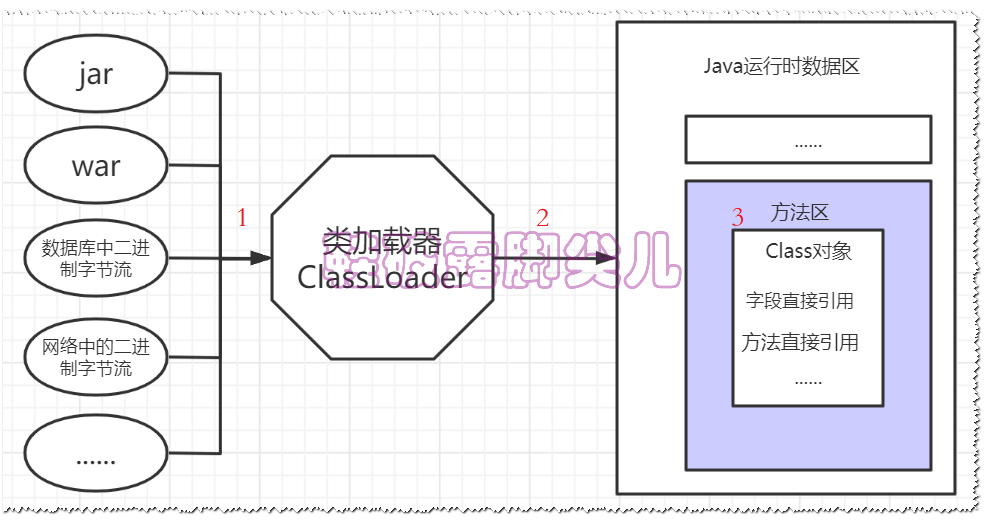
-
通过一个类的全限定名来获取定义此类的二进制字节流(class文件)
-
在程序运行过程中,当要访问一个类时,若发现这个类尚未被加载,并满足类初始化的条件时,就根据要被初始化的这个类的全限定名找到该类的二进制字节流,开始加载过程
-
-
将这个字节流的静态存储结构转化为方法区的运行时数据结构
-
在内存中创建一个该类的java.lang.Class对象,作为方法区该类的各种数据的访问入口
-
程序在运行中所有对该类的访问都通过这个类对象,也就是这个Class对象是提供给外界访问该类的接口
-
加载源
JVM规范对于加载过程给予了较大的宽松度.一般二进制字节流都从已经编译好的本地class文件中读取,
此外还可以从以下地方读取 :
-
zip包 :【Jar、War、Ear ...】
-
其它文件生成:由JSP文件中生成对应的Class类
-
数据库中:将二进制字节流存储至数据库中,然后在加载时从数据库中读取,用来实现代码在集群间分发
-
网络:从网络中获取二进制字节流.典型就是Applet
-
运行时计算生成:动态代理技术,用ProxyGenerator.generateProxyClass为特定接口生成形式为"*$Proxy"的代理类的二进制字节流
类和数组加载的区别
String[] str = new String[10]
数组也有类型,称为“数组类型” ,比如上面的str,而String只是这个str数组的元素类型
数组类和非数组类的类加载是不同的,具体情况如下:
-
非数组类:是由类加载器来完成
-
数组类:数组类本身不通过类加载器创建,它是由java虚拟机直接创建
-
但数组类与类加载器有很密切的关系,因为数组类的元素类型最终要靠类加载器创建
-
加载过程的注意点
-
JVM规范并未给出类在方法区中存放的数据结构
-
类完成加载后,二进制字节流就以特定的数据结构存储在方法区中
-
但存储的数据结构是由虚拟机自己定义的,虚拟机规范并没有指定
-
-
JVM规范并没有指定Class对象存放的位置
-
在二进制字节流以特定格式存储在方法区后,JVM会创建一个java.lang.Class类对象,作为本类的外部访问接口
-
既然是对象就应该存放在Java堆中,不过JVM规范并没有给出限制,不同的虚拟机根据自己的需求存放这个对象
-
-
加载阶段和连接阶段是交叉的
-
类加载的过程中每个步骤的开始顺序都有严格限制,但每个步骤的结束顺序没有限制
-
也就是说,类加载过程中,必须按照如下顺序开始:加载 -> 连接 -> 初始化
-
但结束顺序无所谓,因此由于每个步骤处理时间的长短不一就会导致有些步骤会出现交叉
-
验证
验证阶段比较耗时,它非常重要但不一定必要(因为对程序运行期没有影响),如果所运行的代码已经被反复使用和验证过,那么可以使用 -Xverify:none 参数关闭,以缩短类加载时间,验证的目的就是为了:保证二进制字节流中的信息符合虚拟机规范,并没有安全问题
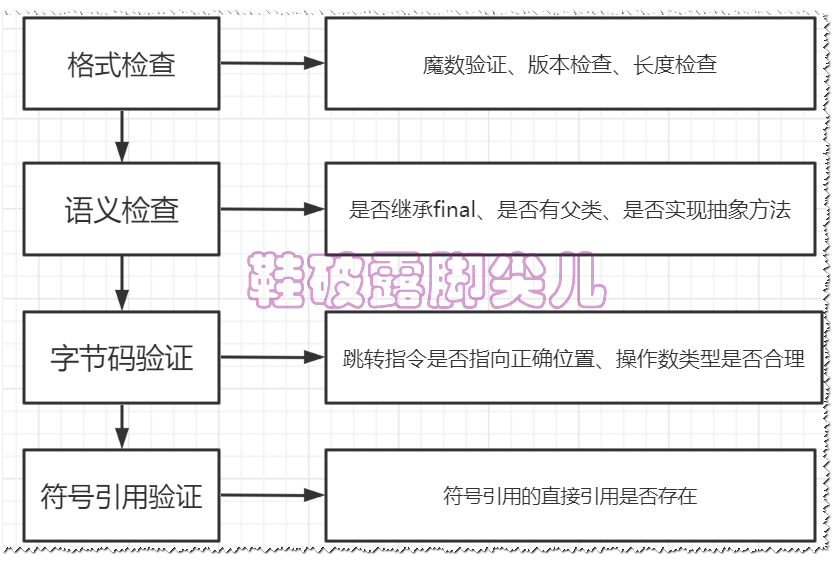
格式验证
-
验证字节流是否符合Class文件格式的规范,并且能被当前的虚拟机处理
-
验证阶段是基于二进制字节流进行的,只有通过本阶段验证,才被允许存到方法区
-
后面的三个验证阶段都是基于方法区的存储结构进行,不会再直接操作字节流
-
印证了之前说到的加载和验证是交叉进行的理论
-
语义检查
-
对字节码描述信息进行语义分析,确保符合Java语法规范
字节码验证
-
本阶段是验证过程的最复杂的一个阶段,对方法体进行语义分析,保证方法不会危害虚拟机
符号引用验证
-
发生在JVM将符号引用转化为直接引用的时候的解析阶段
-
这个转化动作发生在解析阶段,对类自身以外的信息进行匹配校验,确保解析能正常执行
准备
为static分配内存并初始化0值 1.7之前方法区 1.7之后堆 主要做事:
为已在方法区中的类的静态成员变量分配内存
为静态成员变量设置初始值,初始值为0、false、null等
-
仅仅为类变量(即static修饰的字段变量)分配内存并且设置该类变量的初始值即零值
-
这里不包含用final修饰的static,因为final在编译的时候就会分配了(编译器的优化)
-
同时这里也不会为实例变量分配初始化
-
类变量会分配在方法区中【1.7之后分到堆】,而实例变量是会随着对象一起分配到Java堆中
注意点:public static int x = 1000;
-
实际上变量x在准备阶段过后的初始值仍为0,而不是1000
-
将x赋值为1000的putstatic指令是程序被编译后,存放于类构造器<clinit>方法之中
但是如果这样声明:public static final int x = 1000;
-
在编译阶段会为x生成ConstantValue属性,在准备阶段虚拟机会根据ConstantValue属性将x赋值为1000
解析
解析是虚拟机将常量池的符号引用替换为直接引用的过程
-
解析动作主要针对类或接口、字段、类方法、接口方法四类符号引用进行
-
分别对应于常量池中的:
-
CONSTANT_Class_info 、
-
判断所要转化成的直接引用是对数组类型,还是普通的对象类型的引用,从而进行不同的解析
-
-
CONSTANT_Fieldref_info 、
-
对字段进行解析时,会先在本类中查找是否包含有简单名称和字段描述符都与目标相匹配的字段
-
如果有,则查找结束
-
如果没有,则会按照继承关系从上往下递归搜索该类所实现的各个接口和它们的父接口
-
如果还没有,则按照继承关系从上往下递归搜索其父类,直至查找结束
-
如果有一个同名字段同时出现在该类的接口和父类中,或同时在自己或父类的接口中出现,编译器可能会拒绝编译
-
-
CONSTANT_Methodref_info 、
-
对类方法的解析与对字段解析的搜索步骤差不多
-
只是多了判断该方法所处的是类还是接口的步骤
-
而且对类方法的匹配搜索,是先搜索父类,再搜索接口
-
-
CONSTANT_InterfaceMethodref_info
-
与类方法解析步骤类似,只是接口不会有父类,因此,只递归向上搜索父接口就行了
-
-
初始化
初始化是类加载过程的最后一步 在准备阶段,类变量已经被赋过一次系统要求的初始值 到了此阶段,才真正开始执行类中定义的Java程序代码(初始化成为代码设定的默认值)
其实初始化过程就是调用类初始化方法的过程,完成对static修饰的类变量的手动赋值还有主动调用静态代码块
初始化过程的注意点
-
方法是编译器自动收集类中所有类变量的赋值动作和静态语句块中的语句合并产生的
-
编译器收集的顺序是由语句在源文件中出现的顺序所决定的
-
静态代码块只能访问到出现在静态代码块之前的变量
-
定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问
-
public class Test { static { i=0; System.out.println(i); //编译失败:"非法向前引用" } static int i = 1; }
-
-
实例构造器需要显式调用父类构造函数,而类不需要调用父类的类构造函数
-
虚拟机会确保子类的方法执行前已经执行完毕父类的方法
-
因此在JVM中第一个被执行的方法的类肯定是java.lang.Object
-
-
如果一个类/接口中没有静态代码块,也没有静态成员变量的赋值操作,那么编译器就不会为此类生成方法
-
接口也需要通过方法为接口中定义的静态成员变量显示初始化
-
接口中不能使用静态代码块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成方法
-
不同的是,执行接口的方法不需要先执行父接口的方法.只有当父接口中的静态成员变量被使用到时才会执行父接口的方法
-
-
虚拟机会保证在多线程环境中一个类的方法被正确地加锁
-
当多条线程同时去初始化一个类时,只会有一个线程去执行该类的方法,其它线程都被阻塞等待
-
直到活动线程执行方法完毕.其他线程虽会被阻塞,只要有一个方法执行完,其它线程唤醒后不会再进入方法
-
同一个类加载器下,一个类型只会初始化一次
-
-
使用静态内部类的单例实现:
-
public class Student { private Student() {} /* * 此处使用一个内部类来维护单例 JVM在类加载的时候,是互斥的,所以可以由此保证线 程安全问题 */ private static class SingletonFactory { private static Student student = new Student(); } /* 获取实例 */ public static Student getSingletonInstance() { return SingletonFactory.student; } }
-
类加载器介绍
OSGI---复杂的网格方式的热插拔方式的加载
上面我们说了类加载的流程,下面我针对第一步《加载》来具体了解一下详情
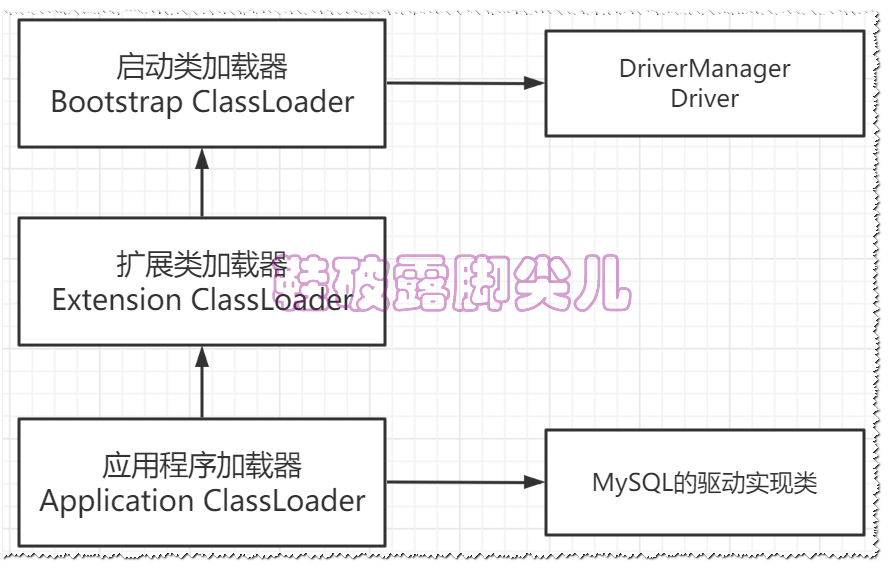
JVM的类加载是通过ClassLoader及其子类来完成的,类的层次关系和加载顺序可以由下图来描述
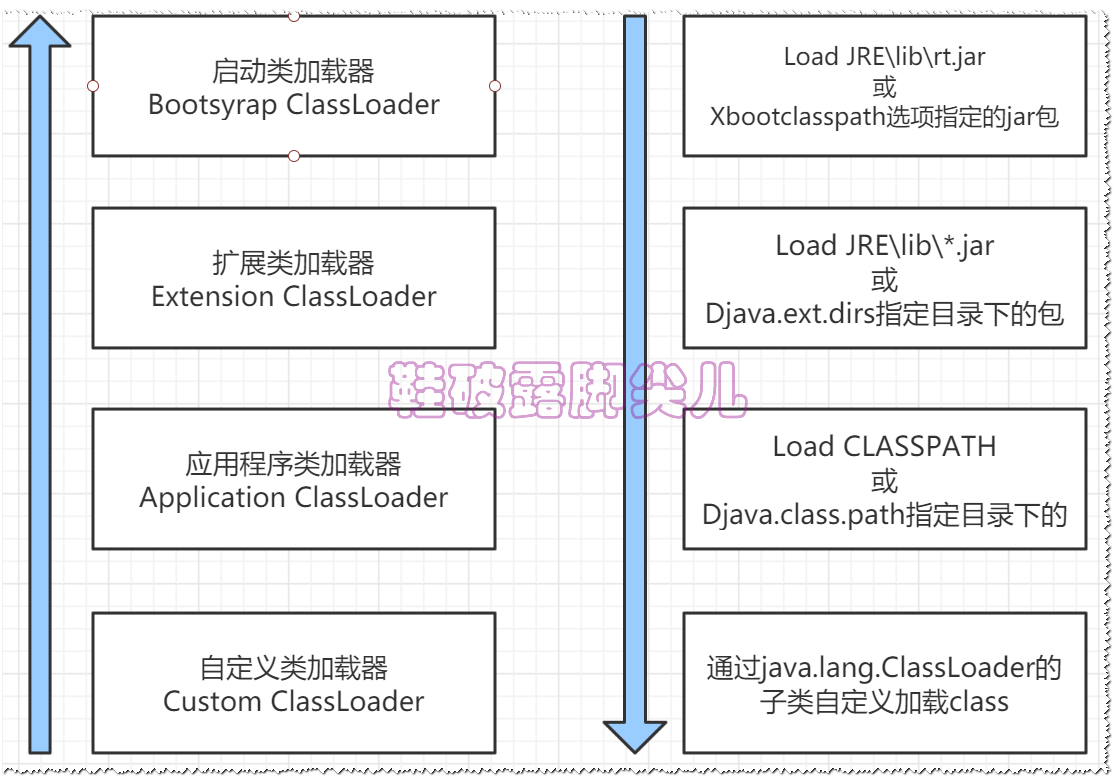
-
加载过程中会先检查类是否被已加载,检查顺序是自底向上逐层检查
-
而加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类
双亲委派模型
JVM通过双亲委派模型进行类的加载,当然我们也可以通过继承java.lang.ClassLoader实现自定义的类加载器
-
当一个类加载器收到类加载任务时,会先交给其父类加载器去完成,因此最终加载任务都会传递到顶层的启动类加载器
-
只有当父类加载器无法完成加载任务时,本加载器尝试执行加载任务
双亲委派的好处:比如加载位于rt.jar包中的类java.lang.Object
-
不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象
但是JVM在搜索类的时候,又是如何判定两个class是相同的呢?
-
类的全限定名完全相同,但是加载它的类加载器不同,那么在【方法区/堆】中会产生不同的【Class】对象
-
也就是说:JVM在判定两个class是否相同时,先判断两个类名是否相同,后判断是否由同一个类加载器实例加载的
为什么要使用双亲委托这种模型呢 ?
-
因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次
-
我们试想一下,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义的类型
-
这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况
-
因为String已经在启动时就被引导类加载器(Bootstrcp ClassLoader)加载,所以用户自定义的ClassLoader永远也无法加载一个自己写的String
-
既然JVM已经提供了默认的类加载器,为什么还要定义自已的类加载器呢?
-
因为Java中提供的默认ClassLoader,只加载指定目录下的jar和class,如果我们想加载其它位置的 类或jar时,只能将加载的数据放在指定的目录下,或者额外配置指定目录,及其不方便
破坏双亲委派模型
为什么要破坏双亲委派模型?
-
双亲委派模型是在JDK1.2以后才使用的,但是有一些类在JDK1.2之前都已经写好了
因为在某些情况下父类加载器需要加载的class文件由于受到加载范围的限制,父类加载器无法加载到需要的文件,这个时候就需要委托子类加载器进行加载
-
而按照双亲委派模式的话,是子类委托父类加载器去加载class文件
-
这个时候需要破坏双亲委派模式才能加载成功父类加载器需要的类
-
也就是说父类会委托子类去加载它需要的class文件
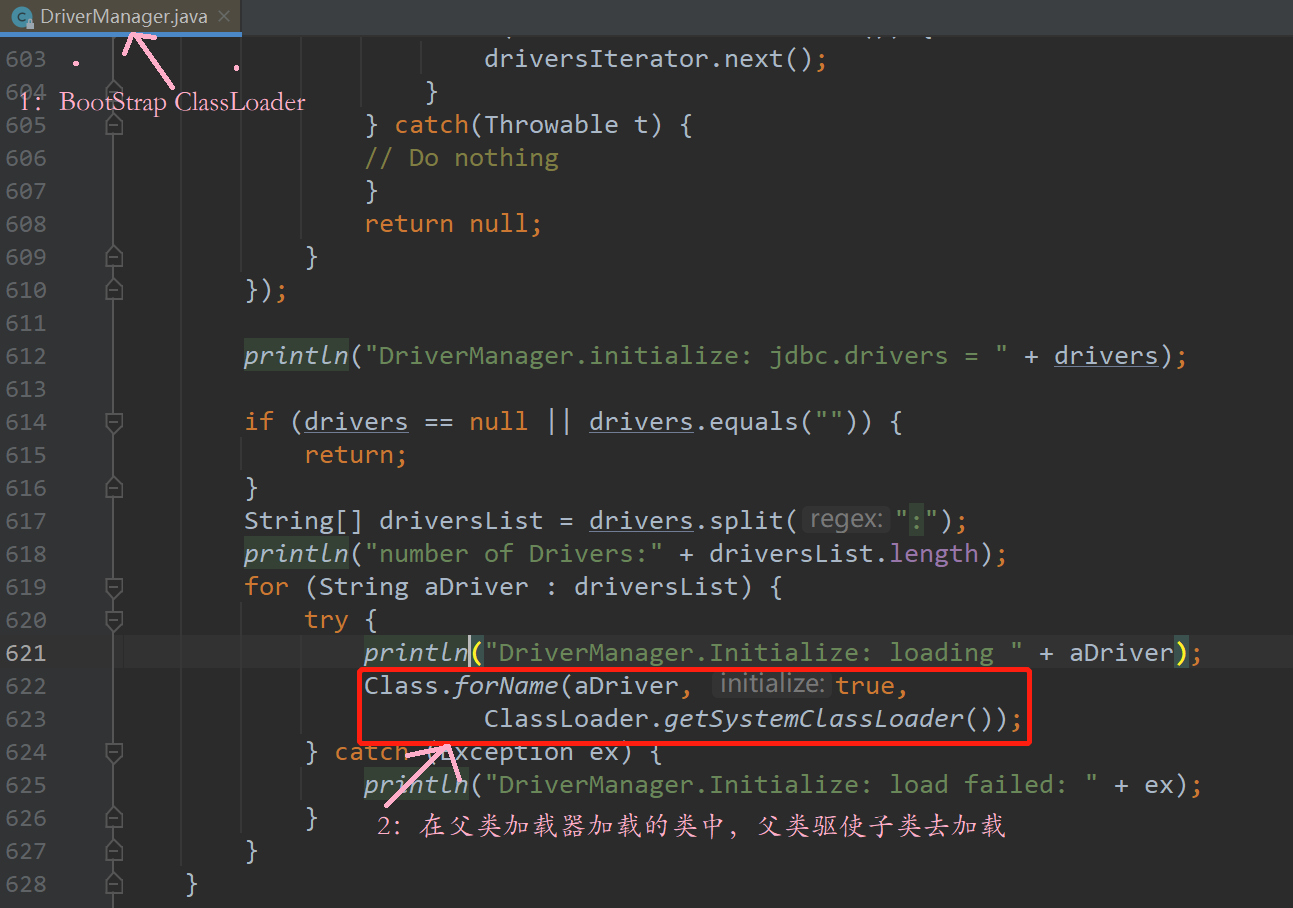
比如:以Driver接口为例
-
由于Driver接口定义在jdk当中的,而其实现由各个数据库的服务商来提供,比如mysql的就写了 MySQL Connector
-
这些实现类都是以jar包的形式放到classpath目录下
-
那么问题来了
-
DriverManager(也由jdk提供)要加载各个实现了Driver接口的实现类(classpath下),然后进行管理
-
但是DriverManager由启动类加载器加载,只能加载JAVA_HOME的lib下文件
-
而其实现是由服务商提供的,由系统类加载器加载
-
这个时候就需要启动类加载器来委托子类来加载Driver实现,从而破坏了双亲委派
-
这里仅仅是举了破坏双亲委派的其中一个情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号