elasticSearch新认知
之前已经学习使用过ElasticSearch的使用,今天补充巩固一下...
上一次的环境是在 linux下使用 EalsticSearch(安装教程详见:https://www.cnblogs.com/msi-chen/p/10335794.html),
今天的笔记内容为:
1.今天的环境我windows本地使用和 docker内的使用;
2.Head插件在windows和docker的简单配套使用;
3.logstash 完成mysql 和 ES 的数据同步;
ES相对于solr:在面对实时查询大数据量数据时提供强劲的查询速度,无需过多配置支持分布式,开箱即用,
ES的体系结构: 索引 ( index ) ——> 类型 ( type ) ——> 文档 ( document )
在 windows 上的使用:
ES 在windows上的使用,没有 Linux上的复杂配置,解压开箱即用即可
提供服务的ES提供了两个接口以供调用 9200(其他), 9300 (java)
ES是基于Resyful web接口的,我们可以使用 rest请求 对其进行简单操作
比如put提交新建索引,post提交新建文档,get提交查询文档,delete提交删除文档...不多赘述
Head插件的安装与使用:
ES有跨域保护,默认不允许跨域调用,Head想调用需要修改相关配置:
elasticsearch.yml 追加两个配置:
http.cors.enabled: true
http.cors.allow‐origin: "*"
安装node js ,安装cnpm : npm install ‐g cnpm ‐‐registry=https://registry.npm.taobao.org
将 grunt 安装我全局命令 : npm install ‐g grunt‐cli
安装依赖 : cnpm install
cmd 找到解压目录 : grunt server 运行即可,访问:localhost:9100
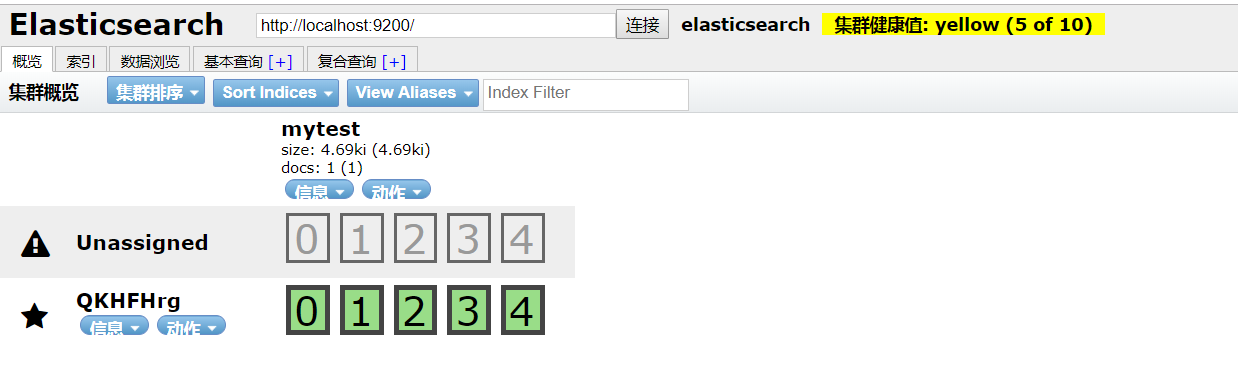
在这里,我们可以看到我们创建了一个名为 myTest 的索引,这个工具着实是简陋,下面我们来粗略的了解一下
创建索引:
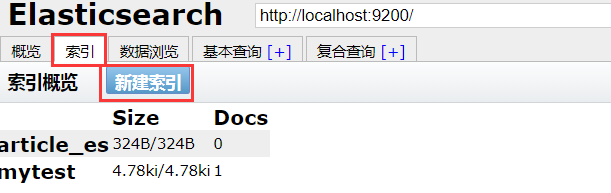
整个页面很简单,多熟悉熟悉即可(put 可用于创建,如果已经被创建,则视为修改)
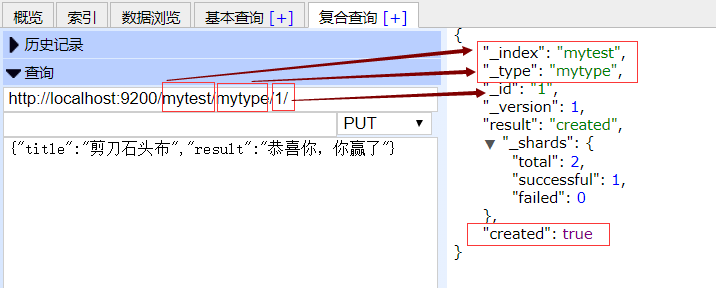
接下来就是了解一下 IK 分词器:
ES 默认自带的中文分词器是一个字为一个词,显然这个不是偶棉想要的结果
于是便引入了现在很流行的 IK分词器,配置也很简单:
将 IK分词器解压到 elasticsearch/plugins / 重启ES服务即可
IK分词器 提供了两种分词算法:
ik_smart :最少切分
iik_max_word :最细粒度划分
测试:
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我喜欢快乐
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我喜欢快乐
然后就是自定义词库,会把一些没有收纳为词条的字段自定义为词条
自定义以 .dic为尾缀的文件 比如: custom.dic
在其内部第一行空格 下一行键入你要的词条: 比如 人艰不拆(注意保存格式诶utf-8)
人艰不拆这个词本来不是词语,现在我们将其作为自定义词条加入分词器
再次测试:

接下来就是 java 代码的运用了,在与数据库的交互中,我们都要创建一个实体类作为结果反射的容器,
在ES中也是一样的,也需要创建一个实体类,用作装载查询到的数据

在ES中有三个概念比较重要,可以理解一下:
是否索引:就是看该字段是否能被作为检索字段被搜索
是否分词 : 搜索的时候是整体匹配,还是分词词条匹配
是否存储:就是在查询结果上,设置是否显示出来
其次就是配置整合需要的 ES 的ip 及 port (java的端口是 : 9300)

然后就是持久层对 ES 的访问了,我们只需要定义接口继承 ElasticsearchRepository<T, ID>
是不是很这种玩法很熟悉,再给你一个列子看
换汤不换药,还是原来的味道,还是原来的配方。然后就可以愉快的搬砖了......
接下来的笔记为 ES 和 MySQL 的数据同步: LogStash
网上对LogStash的介绍为 : Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
在 ES 上的运用表现为: 定时将 MySQL中的数据 刷新到 ES ,完成数据更新同步
开箱即用,bin目录中调用 cmd : logstash -e 'input { stdin { } } output { stdout {} }' (测试语法)
-e :是执行,当命令很短时,可以运用这个语法,一般我们都是运行文件
-f : 跟路径,读取配置文件执行命令,一般用这种
开箱使用:
在解压文件夹内创建一个文件夹(随意,读取里面的配置文件)
在该文件夹内创建一个以 .conf 为尾缀的配置文件
文件内容如下: (酌情改动,以自己的配置为主)
input {
jdbc {
# mysql jdbc connection string to our backup databse
jdbc_connection_string => "jdbc:mysql://192.168.41.130:3306/article?characterEncoding=UTF8"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123456"
# the path to our downloaded jdbc driver
jdbc_driver_library => "C:\MyFrame\logstash-5.6.8\mysqletc\mysql-connector-java-5.1.46.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#以下对应着要执行的sql的绝对路径。
#statement_filepath => ""
statement => "select id,title,content from tb_article"
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新(测试结果,不同的话请留言指出)
schedule => "* * * * *"
}
}
output {
elasticsearch {
#ESIP地址与端口
hosts => "127.0.0.1:9200"
#ES索引名称(自己定义的)
index => "article_es"
#自增ID编号
document_id => "%{id}"
document_type => "article"
}
stdout {
#以JSON格式输出
codec => json_lines
}
}
然后在 bin 中执行 : logstash -f ../mysqletc/mysql.conf
然后就可以看到控制台在为我们刷数据到 ES中的,一分钟后刷新 Head


已经实现数据的同步,接下里我们启动代码看看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号