【JVM】class文件解析
class文件解析
-
在我们编译后的class文件内部都是存的16进制的数据
-
里面到底储存了什么数据,又有什作用呢,下面我们一起来学习学习
Class文件结构示意图
下面的图是一字排开形式,都是平级关系,由于图片排开太长,所以我画成了下面这样【容易误会,特此说明】

Class常量池如何储存数据
看上面的组织结构图,第一层的常量池数据区,那是我们这一小节的攻克目标
常量池里面又是什么结构组织呢?
-
首先我们看到常量池数据区的左边是常量池计数器
-
常量池计数器:记录的是常量池数据区中的常量池项cp_info的数量
-
从1开始计数,第一个有用常量池项为1,所以常量池项的索引也是从1开始
-
至于索引为0的数据空间,class文件规范是如此定义的
-
-
常量池项 (cp_info) 的结构
cp_info{
tag:xx
info[]:xx
}
-
tag:类型,用标记下面info数组的数据类型
-
-
info[]:若干个字节构成数组

细化了的常量池的结构会是类似下图所示的样子:
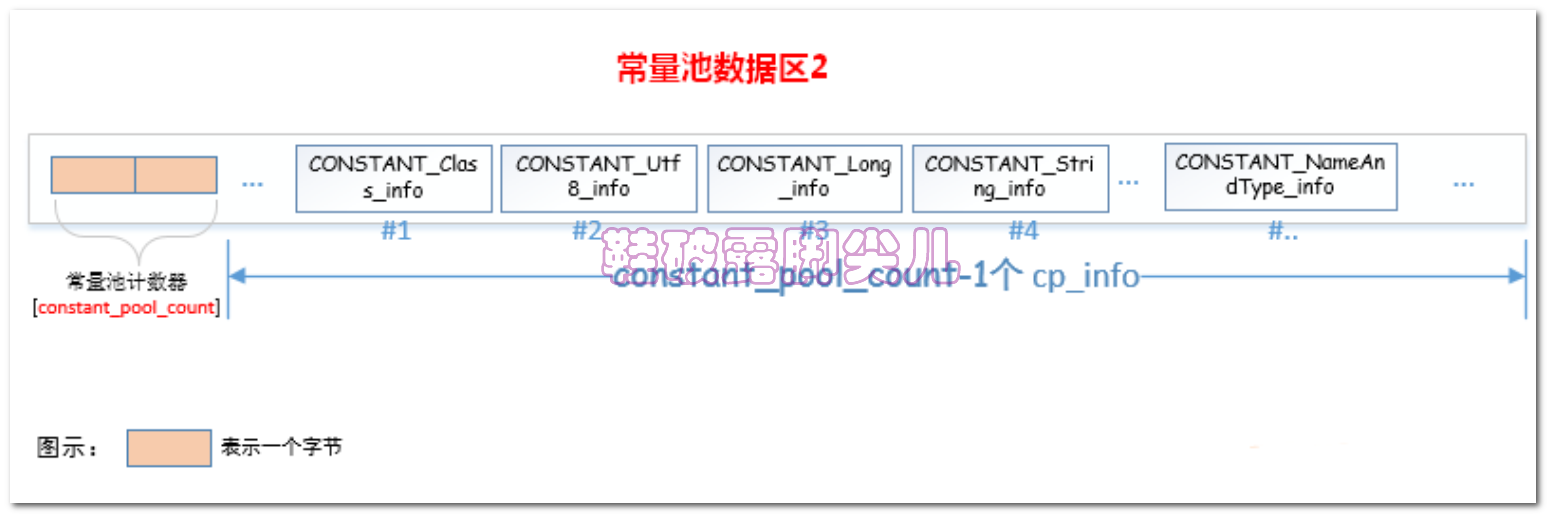
int和float数据类型在常量池中的储存?
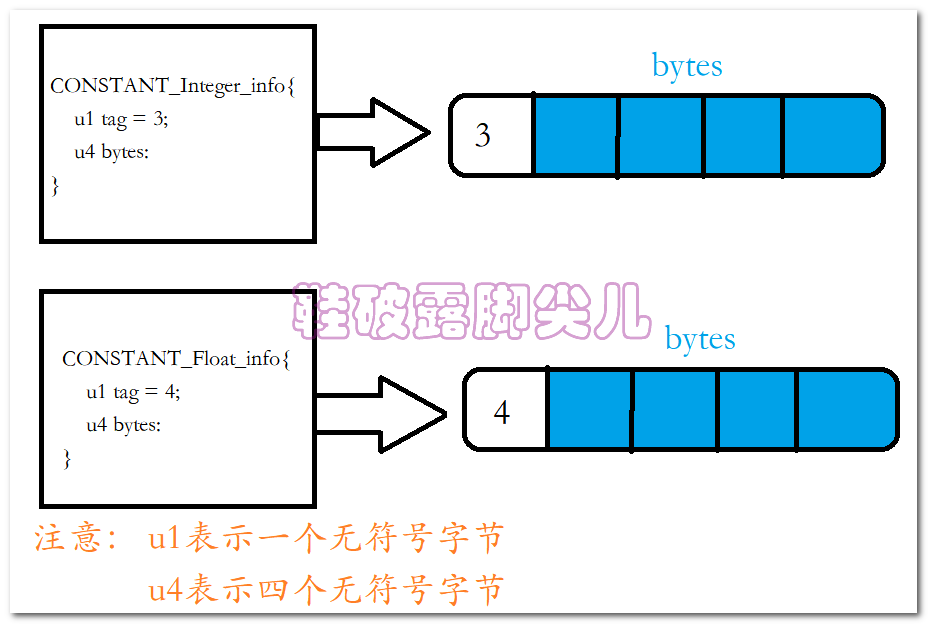
比如我们用这个代码做测试:
-
我们声明了五个变量,但是取值就两种int类型的10 和Float类型的11f
public class IntAndFloat{ private final int a = 10; private final int b = 10; private float c = 11f; private float d = 11f; private float e = 11f; }
javac编译为字节码.class文件,然后我们使用:javap -v IntAndFloat.class观察其常量池中的信息
-
编译器会将10和11f分别包装成consant_integer_info和consant_float_info结构体
-
然后放置搭到常量池中去
-
-
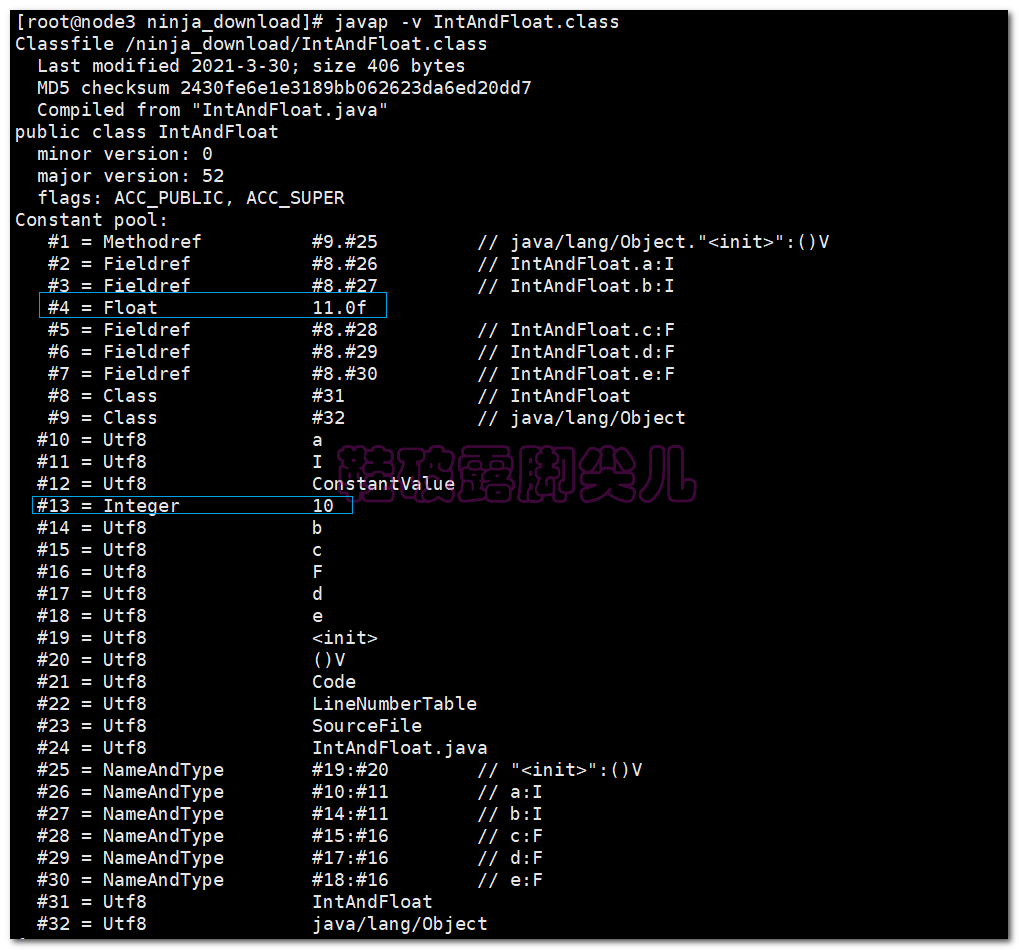
可以看到虽然我们在代码中写了两次10 和三次11f,但是常量池中,就只有一个常量10 和一个常量11f
-
第四个常量池项为 :11.0f
-
第十三个常量池项:10
-
其他的常量池项的意义我们后面会说道
-
-
代码中所有用到 int 类型 10 的地方,会使用指向常量池的指针值#13 定位到第#13 个常量池项(cp_info),即值为 10的结构体CONSTANT_Integer_info
-
而用到float类型的11f时,也会指向常量池的指针值#4来定位到第#4个常量池项(cp_info) 即值为11f的结构体CONSTANT_Float_info
long和double数据类型在常量池中的储存?
我们都知道long和double都是占用8个字节的数据类型,那么他妈的储存和上面四个字节有何区别呢?
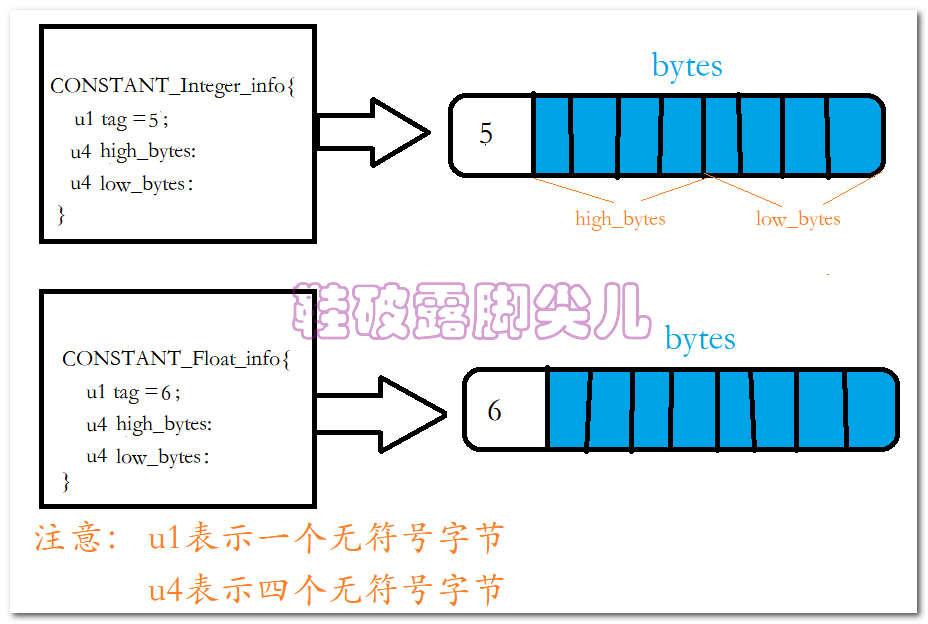
如int和float的演示代码一致,我们也会发现,无论在代码中声明了几个变量,只要取值相同,那么该值只会在常量池中存有一份
String 类型的字符串在常量池中如何储存?
-
对于字符串而言,JVM会将字符串类型的字面量以UTF-8 编码格式存储到在class字节码文件中
-
编译时会将这些字符串转换成CONSTANT_String_info结构体,然后放置于常量池中
用代码演示一下:
public class StringTest { private String s1 = "JVM原理"; private String s2 = "JVM原理"; private String s3 = "JVM原理"; private String s4 = "JVM原理"; }
操作手法一致,先变异后查看常量词信息:javap -v StringTest.class
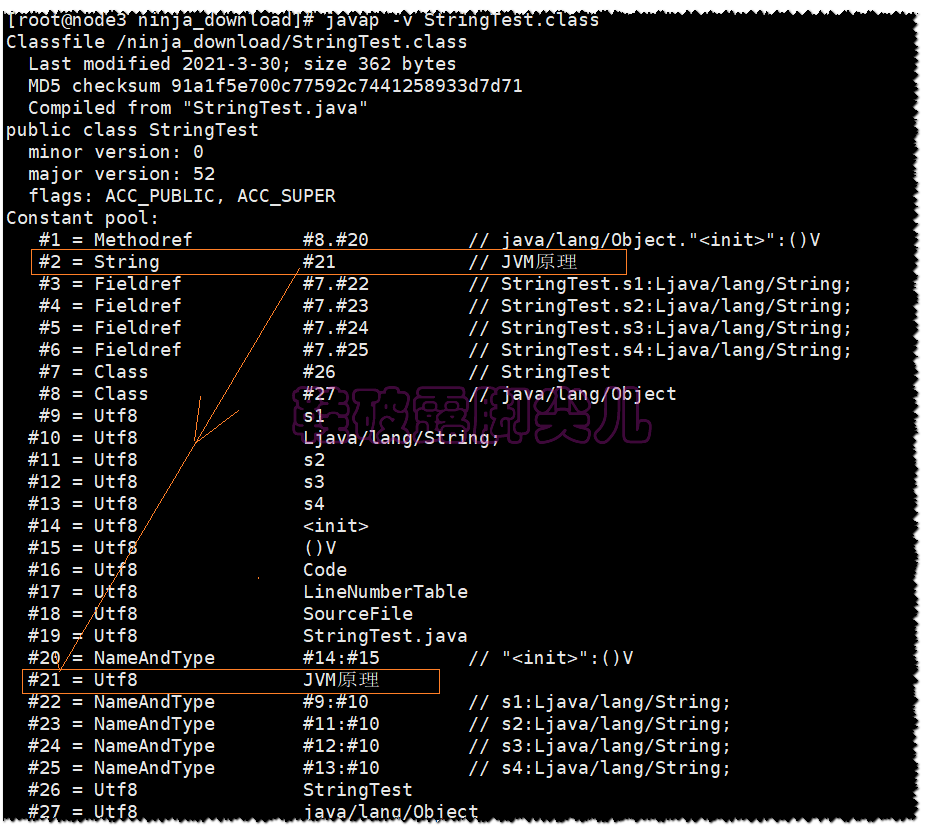
-
好像和上面有一点不同了,我们首先先把储存细节说一下,然后就明白哪里不同了
CONSTANT_String_info { u1 tag=8; u2 string_index; //常量池索引 }
-
这就是String在常量池中的储存的前一部分,可以发现不同的是
-
本来为数据的 u4 bytes 变成了 u2的 string_index
-
-
String类型的储存和其他类型的储存还是有很大的区别,他们是直接储存,而String不是
-
string_index储存的并不是直接的字节数组,而储存的是真实数据的一个索引值
-
被指定的索引值得对应的数据才是真实的数据所在
-
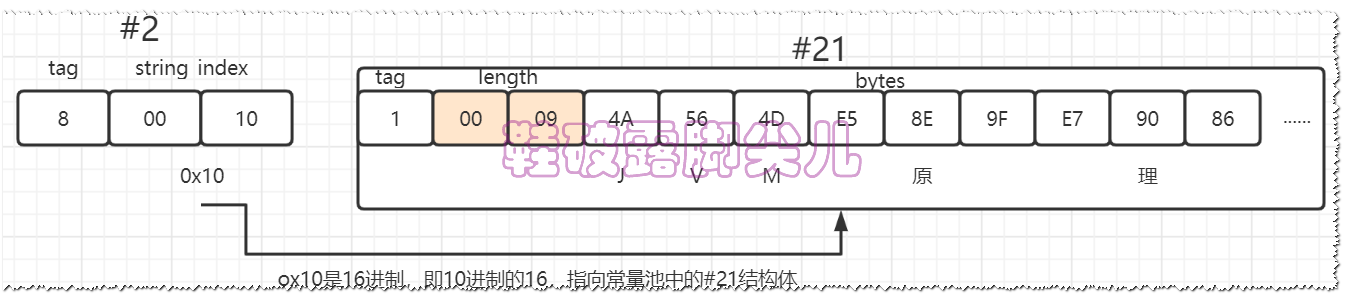
拿上图说话,#2 后面没有任何数据,指向的是#21
-
#21后面的数据才是我们的数据所在,而#21的结构体如下所示
-
CONSTANT_String_info { u1 tag=1; //为 utf8类型,而不是8 u2 length; //该字节数组的长度 u1 bytes[length]; //使用utf8编码后的字节数组数据 }
-
字符串储存的细节为:【联合上图的代码测试】
类文件中定义的类和类中使用到的类在常量池中的存储?
说了上面的String类型的储存,下面我们在说引用类型的储存就简单多了 JVM会将某个Java 类中所有使用到了的类的完全限定名 以二进制形式的完全限定名 封装成 CONSTANT_Class_info结构体中,然后将其放置到常量池里,其结构如下所示:
CONSTANT_String_info { u1 tag=7; u2 name_index }
-
name_index的值是某个constant_utf8_info结构体在常量池中的索引
-
对应的constant_utf8_info结构体储存了对应的二进制形式的完全限定名称的字符串
-
name_index是占有两个字节,也就是说它最大能表示65535(2的16次方 - 1)
-
所以常量池中最大容量65535个常量项,在定义Java类时应该注意类的大小,不能太大
-
我们还是简单定义一个测试,来说明一下
import java.util.Date; public class ClassTest { private Date date =new Date(); }
老规矩,先编译后查看常量池信息:javap -v ClassTest.class
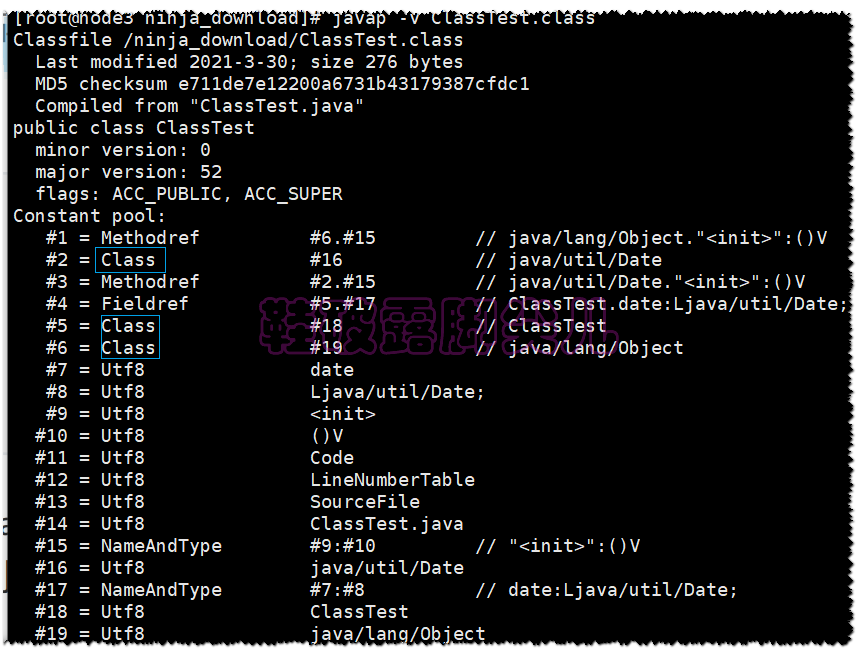
-
我们一个发现了三个CONSTANT_Class_info类型的结构体
-
#2 的name_index指向 #16
-
#16:承载的是Data类的二进制形式的完全限定名
-
-
#5 的name_index指向 #18
-
#18:承载的是ClassTest类的二进制形式的完全限定名
-
-
#6 的name_index指向 #19
-
#19:承载的是Object类的二进制形式的完全限定名,每个类都默认继承Object,不会忘了吧?
-
如果在类中使用到了其他的类,只有真正使用到了相应的类,JDK编译器才会将类的信息组成CONSTANT_Class_info常量池项放置到常量池中
import java.util.Date; public class ClassTest { private Date date; //只创建了引用,没有实列化的不会加载到常量池中 }
总结一波
-
对于某个类或接口而言,其自身、父类和继承或实现的接口的信息会被直接组装成CONSTANT_Class_info常量池项放置到常量池中
-
类中或接口中使用到了其他的类,只有在类中实际使用到了该类时,该类的信息才会在常量池中有对应的CONSTANT_Class_info常量池项
-
类中或接口中仅仅定义某种类型的变量,JDK只会将变量的类型描述信息以UTF-8字符串组成CONSTANT_Utf8_info常量池项放置到常量池中,上面在类中的private Date date;JDK编译器只会将表示date的数据类型的“Ljava/util/Date”字符串放置到常量池中,但不会有实列的二进制形式的完全限定名加载到常量池中
哪些字面量会进入常量池
-
【final修饰】的8种基本类型的值会进入常量池
-
【非final类型】(包括static的)的8种基本类型的值,只有【double、float、long】的值会进入常量池
-
常量池中包含的字符串类型字面量(【双引号引起来的字符串值】)
Class中的符号引用和直接引用
符号引用
-
符号引用以一组符号来定位所引用的目标,符号可以是任何形式的字面量
-
比如上面我们说到的String,Class类型等
-
符号引用与虚拟机的内存布局无关,引用的目标并不一定加载到内存中
-
在编译时,java类并不知道所引用的类的实际地址,因此只能使用符号引用来代替
-
比如我们的Test.class,引用了Data类,但是在编译的时候并不知道Data的实际内存地址
-
因此只能使用符号引用的方式定位到Data类的地址所在
-
直接引用
-
直接指向目标的指针(比如,指向“类型”【Class对象】、类变量、类方法的直接引用可能是指向方法区的指针)
-
相对偏移量(比如,指向实例变量、实例方法的直接引用都是偏移量)
-
一个能间接定位到目标的句柄
-
直接引用是和虚拟机的布局相关的 ,如果有了直接引用,那引用的目标必定已经被加载入内存中了,直接定位内存地址
引用替换的时机
符号引用替换为直接引用的操作发生在类加载过程(加载 -> 连接(验证、准备、解析) -> 初始化)中的解析阶段
将符号引用转换(替换)为对应的直接引用,放入运行时常量池中
Class中的特殊字符串
特殊字符串包括三种:
-
类的全限定名
-
字段和方法的描述符
-
特殊方法的方法名
类的全限定名
-
源文件中一个类的名字, 在class文件中是用全限定名表述的
-
Object类,在源文件中的全限定名是 java.lang.Object 。而class文件中的全限定名是将点号替换成“/” , 也就是 java/lang/Object
字段和方法的描述符
对于字段的数据类型,其描述符主要有以下几种:
-
基本数据类型:(byte、char、double、float、int、long、short、boolean):
-
除 long 和boolean,其他基本数据类型的描述符用对应单词的大写首字母表示。
-
long 用 J 表示,boolean 用 Z 表示
-
-
void:描述符是 V
-
对象类型: 描述符用字符 L 加上对象的全限定名表示,如 String 类型的描述符为Ljava/lang/String
-
数组类型:每增加一个维度则在对应的字段描述符前增加一个 [ ,如一维数组 int[] 的描述符为 [I ,二维数组 String
对于字段的描述符:
-
int i 中, 字段i的描述符就是 I Object o中, 字段o的描述符就是 Ljava/lang/Object; double[][] d中, 字段d的描述符就是 [[D
对于方法的描述符:
-
方法的描述符比较复杂, 包括所有参数的类型列表和方法返回值。 它的格式是这样的
-
(参数1类型 参数2类型 参数3类型 ...)返回值类型
-
-
不管是参数的类型还是返回值类型, 都是使用对应字符和对应字符串来表示的, 并且参数列表使用小括号括起来, 并且各个参数类型之间没有空格, 参数列表和返回值类型之间也没有空格
-
为了方便理解,下面我们来看看
| 方法描述符 | 方法声明 |
|---|---|
| ()I | int getSize() |
| ()Ljava/lang/String; | String toString() |
| ([Ljava/lang/String;)V | void main(String[] args) |
| ()V | void wait() |
| (JI)V | void wait(long timeout, int nanos) |
| (ZILjava/lang/String;II)Z | boolean regionMatches(boolean ignoreCase, int toOffset, String other, int ooffset, int len) |
| ([BII)I | int read(byte[] b, int off, int len ) |
| ()[[Ljava/lang/Object; | Object |
特殊方法的方法名
-
首先要明确一下, 这里的特殊方法是指的类的构造方法和类型初始化方法
-
构造方法就不用多说了, 至于类型的初始化方法, 对应到源码中就是静态初始化块
-
静态初始化块, 在class文件中是以一个方法表述的, 这个方法同样有方法描述符和方法名,具体如下
-
类的构造方法的方法名使用字符串 表示
-
静态初始化方法的方法名使用字符串 表示
-
除了这两种特殊的方法外, 其他普通方法的方法名, 和源文件中的方法名相同
-
Javap命令
在上面的学习中,我们频繁的使用到了javap命令来查看class文件的常量池
现在我们来对他进行一个比较全面的掌握
-
javap是jdk自带的反解析工具
-
它的作用就是根据class字节码文件,
-
反解析出当前类对应的code区(汇编指令)、
-
本地变量表、
-
异常表、
-
代码行偏移量映射表、
-
常量池等等信息
-
语法格式:javap <options> <classes>
帮助命令查看所有options:javap -help
-version 版本信息,其实是当前javap所在jdk的版本信息,不是class在哪个jdk下生成的。 -v -verbose 输出附加信息(包括行号、本地变量表,反汇编等详细信息) -l 输出行号和本地变量表 -public 仅显示公共类和成员 -protected 显示受保护的/公共类和成员 -package 显示程序包/受保护的/公共类 和成员 (默认) -p -private 显示所有类和成员 -c 对代码进行反编译生成汇编代码 -s 输出内部类型签名 -sysinfo 显示正在处理的类的系统信息 (路径, 大小, 日期, MD5 散列) -constants 显示静态最终常量 -classpath <path> 指定查找用户类文件的位置 -bootclasspath <path> 覆盖引导类文件的位置
我们一般常用的就是:-v -l -c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号