Spring Data JPA谁说你不会,你就抡键盘!
JPA和Hibernate和Spring Data JPA可不是一样的,这里先声明,但他们都作用于一个方向,那就是ORM(对象关系映射),JPA只是一套规范,Hibernate和Spring Data JPA是它规范下的两种实现
另一个方向就是非关系映射,比如我们常用的MyBatis,他是通过写sql语句直接与数据库产生关系,当然MyBatis Plus虽然是他的哥哥,但未了弥补MyBatis的缺陷,它也将手伸向了ORM
在我们的项目中,不是用了JPA就不能用MyBatis的,都是可以一起使用的,这看老大允不允许吧,两者是不冲突的
Spring Data JPA入门
Spring Data JPA 是Spring 基于JPA规范做出的自己的实现,Spring Data是一个系列,里面是关于Spring 对各种持久化数据库做出的一揽子封装,我们可以其来操作各种数据库,比如MySQL、MongoDB、Redis、ElasticSearch等:更多详细信息见官网
现在不会Java程序员说不会SpringBoot,这有点说不过去吧,我们就直接使用SpringBoot集成Spring Data JPA来学习一下JPA的常用手法
-
创建一个SpringBoot项目,依赖如下
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.example</groupId> <artifactId>demo</artifactId> <version>0.0.1-SNAPSHOT</version> <name>demo</name> <description>Demo project for Spring Boot</description> <properties> <java.version>1.8</java.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <spring-boot.version>2.3.0.RELEASE</spring-boot.version> </properties> <dependencies> <!--Spring Data JPA 的starter--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <!--mysql--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <!--所有Demo都写测试验证--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>${spring-boot.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
-
定义Dao接口,一般我们把它叫做Repository接口,如下所示
-
在定义接口之前,我们先要确定我们操作的对象,因为是面向对象的
-
package com.example.demo.entity.basic; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; /** * @Description * @Author Ninja * @Date 2020/9/13 **/ @Data @AllArgsConstructor @NoArgsConstructor @Entity @Table(name = "user") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) //主键自增 private Long id; private String name; private Long age; public User(String sname, long sage) { this.name = sname; this.age = sage; } } package com.example.demo.repository; import com.example.demo.entity.basic.User; import org.springframework.data.jpa.domain.Specification; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.stereotype.Repository; @Repository public interface UserRepository extends JpaRepository<User,Long> {}
就上面这段代码,使用Spring Data JPA已经入门了,下面我详细解释一下
在实体类User中,有以下几个注解需要注意一下
@Entity :表示该实体为一个ORM实体,与数据库映射
@Table(name = "user") ;:表示该实体在数据库中的表名
@Id :标注该字段为主键,每个ORM实体比如有该注解标注的属性
@GeneratedValue(strategy = GenerationType.IDENTITY) :主键生成策略有以下几种
GenerationType.TABLE, //特定表生成 [一般不使用]
GenerationType.SEQUENCE, //数据库底层 [一般不使用]
GenerationType.IDENTITY, //自增序列生成 [一般]
GenerationType.AUTO //默认,自动选择 [一般]
不写 GeneratedValue //由程序控制 [一般]
至于更多的注解,下面我会归纳到一起,这里我们还是开始使用吧
-
SpringBoot配置Spring Data JPA
-
application.yml
-
server: port: 3333 spring: datasource: url: jdbc:mysql://localhost:3306/test_jpa2?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&useSSL=false username: root password: root jpa: database: MySQL database-platform: org.hibernate.dialect.MySQL5InnoDBDialect show-sql: true # hibernate.ddl-auto: create hibernate: ddl-auto: update # naming: # implicit-strategy: org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl # : create "每次运行程序时,都会重新创建表,故而数据会丢失" # : create-drop "每次运行程序时会先创建表结构,然后待程序结束时清空表" # : upadte "每次运行程序,没有表时会创建表,如果对象发生改变会更新表结构,原有数据不会清空,只会更新(推荐使用)" # : validate "运行程序会校验数据与数据库的字段类型是否相同,字段不同会报错" # : none "禁用DDL处理" # properties.hibernate.dialect: org.hibernate.dialect.MySQL5InnoDBialect
-
启动类
-
很常规的一个启动类,无需多说
-
package com.example.demo; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class DemoApplication { public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } }
JpaRepository API
package com.example.demo.repository; import com.example.demo.entity.basic.User; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import java.util.Optional; @SpringBootTest public class UserRepositoryTest { @Autowired private UserRepository userRepository; } //最普通的JPA提供的API调用----------- //保存一条数据 @Test public void test1() { User user = new User(1L, "玛卡巴卡", 23L); User save = userRepository.save(user); if (save != null) { System.out.println(save); } } //查询、修改数据 //JPA默认以id为依据,当ID已经存在时,save()为修改操作,当ID不存在时为插入操作 @Test public void test2() { Optional<User> optional = userRepository.findById(1L); if (optional.isPresent()) { User user = optional.get(); System.out.println("得到User数据" + user); user.setName("胡汉三"); User save = userRepository.save(user); if (save != null) { System.out.println(save); } } } //删除一条数据 @Test public void test3() { userRepository.deleteById(1L); } //分页、排序查询 @Test public void test4() { //构建排序对象 Sort Sort sort = Sort.by(Sort.Direction.DESC, "age"); //通过page、size、排序对象:构建分页对象 PageRequest PageRequest pageRequest = PageRequest.of(0, 3,sort); Page<User> page = userRepository.findAll(pageRequest); System.out.println("数据总条数为:" + page.getTotalElements()); System.out.println("当前page:" + page.getNumber()); System.out.println("当前size:" + page.getSize()); System.out.println("数据为:" + page.getContent()); System.out.println("总页数为: " + page.getTotalPages()); }
方法命名规则查询
上面我们使用了JpaRepository提供的一些基本的CRUD的API,下面我们来使用JPA的一个有意思的用法
方法命名规则查询 :
通过定制符合规则的接口命名来实现CRUD
@Repository public interface UserRepository extends JpaRepository<User,Long> { //查询位于某个年龄段的人员信息 List<User> findByAgeBetween(Long start, Long end); //对name进行模糊查询 List<User> findByNameLike(String name); }
//中级难度: 接口命名查询----------- @Test public void test5() { List<User> list = userRepository.findByAgeBetween(18L, 30L); list.forEach(user -> { System.out.println(user); }); } //模糊查询,记得自己给定是前置模糊还是后置模糊,JPA将这个权利交给用户指定 @Test public void test6() { List<User> list = userRepository.findByNameLike("%" + "三" + "%"); list.forEach(user -> { System.out.println(user); }); }
至于更多命名规则关键字
| Keyword | Sample | JPQL |
|---|---|---|
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| IsNull | findByAgeIsNull | … where x.age is null |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| Is,Equals | findByFirstnameIs, findByFirstnameEquals | … where x.firstname = ?1 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
JPQL操作
-
使用 @Query注解配合JPQL的语句即可实现
-
这里值得注意的是:如果是要对数据库产生数据变更操作,需要额外添加一个注解 : @Modifying
@Repository public interface UserRepository extends JpaRepository<User,Long> { //JPQL的用法演示 //对数据库有变化的操作,应该额外添加一个注解: @Modifying @Query(value = "from User") List<User> jpqlFindAll(); @Query(value = "from User where name = ?1") User jpqlFindByName(String name); }
原生SQL操作
-
也是使用 @Query注解,但得开启本地SQL
-
nativeQuery=true :开启本地sql,这个就是原生的SQL,使用原生SQL,必须给该属性
-
value=" " :值为原生SQL,其中的值使用占位符的方式给定
-
?1 :函数的第一个入参
-
?2:函数的第二个入参
-
?3:依次类推
-
-
这里值得注意的是:如果是要对数据库产生数据变更操作,需要额外添加一个注解 : @Modifying
@Repository public interface UserRepository extends JpaRepository<User,Long> { //原生本地sql演示 //对数据库有变化的操作,应该额外添加一个注解: @Modifying @Query(nativeQuery=true, value = "select * FROM user where name like ?1 and age BETWEEN ?2 and ?3 ORDER BY id ASC") List<User> localSql(String name, Long age1, Long age2); }
//使用原生sql @Test public void test7() { List<User> users = userRepository.localSql("%三", 18L, 50L); users.forEach(user -> { System.out.println(user); }); }
高级查询
Example条件构造器
Example条件构造器的使用相比上面简单的api的使用,它实现的就是动态SQL,使用JPQL的思想,只需要一个装有条件值的Entity就可以完成动态SQL查询,免去了繁琐的if判断,但是缺点也很明显,就是对象Entity中只支持String类型的字段做一些条件查询,比如(starts/contains/ends/regex...),对于其他的类型目前只支持精确匹配,比如Long,Double类型是不支持大于、小于、Between条件给定的,只能精确判断,想要更精确的查询,我们还是得去看看下面的Specification条件构造器进行复杂查询,但是Example使用上相对简单的多,也让人很好理解,对于一些比较简单的动态查询还是可以满足的,下面我们就来简单认识一下
//高级难度: 条件构造器查询----------- //Example查询 ------ 基本的默认全部精确匹配 @Test public void test10(){ User user = new User(); user.setName(" 法外狂徒"); user.setAge(34L); Example<User> example = Example.of(user); List<User> list = userRepository.findAll(example); System.out.println(list); } //Example查询 ------ 对String类型的属性进行规则匹配 @Test public void test11(){ User user = new User(); user.setName("三"); user.setAge(34L); ExampleMatcher matching = ExampleMatcher.matching() //下面api相当于 : like '%三%' //因为name字段为String类型,所以我们可以对其做很多规则匹配,详细见下面解释 .withMatcher("name", match -> match.contains()) //下面api相当于: sage = 34 .withMatcher("age", ExampleMatcher.GenericPropertyMatchers.exact()) // 忽略该值 .withIgnorePaths("id"); Example<User> example = Example.of(user,matching); //加一个排序和分页 Sort sort = Sort.by(Sort.Direction.ASC, "id"); PageRequest pageRequest = PageRequest.of(0, 1); Page<User> page = userRepository.findAll(example, pageRequest); System.out.println("数据总条数为:" + page.getTotalElements()); System.out.println("当前page:" + page.getNumber()); System.out.println("当前size:" + page.getSize()); System.out.println("数据为:" + page.getContent()); System.out.println("总页数为: " + page.getTotalPages()); }
-
关于对String类型的一些规则匹配,以前我写过的一篇博客中有说明到,详细不再赘述
Specification 条件构造器
上面我们说道了,Example只能对String类型的字段进行多规则匹配,下面来了解一下其他字段的多规则匹配,Example的增强版:Specification
-
创建实体
@Entity @Table(name = "orders") @Data @NoArgsConstructor @AllArgsConstructor @ToString public class Orders { @Id private String orderNumber; private double initialPrice; private double price; private LocalDate startTime; private LocalDate endTime; private String status; private String userId; private String details; }
-
创建Repository
@Repository public interface OrdersRepository extends JpaRepository<Orders,String>, JpaSpecificationExecutor<Orders>{}
Specification里面我们常用就是就只有一个方法,大家可以去看看,那就是:toPredicate()
//root :代表查询的根对象,可以通过root获取实体中的属性
//query :代表一个顶层查询对象,用来自定义查询
//build :用来构建查询,此对象里有很多条件方法
Predicate toPredicate(Root<T> root,CriteriaQuery<?> query, CriteriaBuilder builder);
-
编写测试类进行测试
@SpringBootTest public class OrdersRepositoryTest { @Autowired private OrdersRepository ordersRepository; //简单尝试一下 @Test public void test1() { Specification<Orders> specification = new Specification<Orders>() { @Override public Predicate toPredicate(Root<Orders> root, CriteriaQuery<?> query, CriteriaBuilder builder) { //对details模糊查询,模糊字段为 '详情%' // return builder.like(root.get("details").as(String.class), "详情%"); //对price字段进行大于等于 300的条件查询 //这里price 实体类型为Double,数据库Float,指定为Double报错 return builder.ge(root.get("price").as(Float.class), 300F); } }; List<Orders> list = ordersRepository.findAll(specification); System.out.println(list); } //分页、排序查询了解一下 @Test public void test2() { Specification<Orders> specification = new Specification<Orders>() { @Override public Predicate toPredicate(Root<Orders> root, CriteriaQuery<?> query, CriteriaBuilder builder) { return builder.like(root.get("details").as(String.class), "详情%"); } }; //单单只是分页 //构造分页page & size, page是从0开始的 //PageRequest pageRequest = PageRequest.of(0, 2); //分页 + 排序 Sort sort = Sort.by(Sort.Direction.DESC, "price"); PageRequest pageRequest = PageRequest.of(0, 2, sort); Page<Orders> page = ordersRepository.findAll(specification, pageRequest); System.out.println("数据总条数为:" + page.getTotalElements()); System.out.println("当前page:" + page.getNumber()); System.out.println("当前size:" + page.getSize()); System.out.println("数据为:" + page.getContent()); System.out.println("总页数为: " + page.getTotalPages()); } //多条件多规则匹配 @Test public void test3() { Specification<Orders> specification = new Specification<Orders>() { @Override public Predicate toPredicate(Root<Orders> root, CriteriaQuery<?> query, CriteriaBuilder builder) { //多字段的查询条件集合 List<Predicate> list = new ArrayList<>(); //构建对details字段的模糊查询 Predicate detailsLike = builder.like(root.get("details").as(String.class), "详情%"); //构建对price的大于查询 Predicate priceBetween = builder.between(root.get("price").as(Float.class), 200F, 400F); //对状态字段做一个精确匹配 Predicate statusEquals = builder.equal(root.get("status").as(String.class), "1"); list.add(detailsLike); list.add(priceBetween); list.add(statusEquals); //这里既然有 builder.and(),那就肯定有or() return builder.and(list.toArray(new Predicate[list.size()])); } }; List<Orders> all = ordersRepository.findAll(specification); System.out.println(all); } }
多表查询
这个其实有点偏话外题了,对于对象关系映射的JPA的框架来说,一般操作都是针对于单表操作的,大不了就是冗余字段嘛,如果设计到多表查询,JPA显得就很被动了,这就是MyBatis在国内很火的原因,因为国内业务复杂 ,表的设计能不冗余就不冗余,涉及多表操作那就是基操,一个接口对应的sql语句可能xml里面也就几十行吧,面对这种情况,JPA也不不能不能实现,但是相对就笨拙了一下,也失去了JPA的灵魂,一般企业里面也不会这样使用,纯属增加一下见识
我们就以国家和城市来做一个测试吧,将国家和城市关联起来查询得到一个虚拟结果表,将虚拟结果表数据封装起来拿到打印一下即可,一种方式就是使用原生sql操作,但是结果不好封装,我们只能封装到Map中,第二种是使用EntityManager去实现
第一种方式:原生sql + Map封装
@Query(nativeQuery = true,value = "select * from country c1 LEFT JOIN city c2 ON c2.country_country_id = c1.country_id where c1.country_id = ?1") List<Map<String, Object>> findInfoByCountryId(String countryId);
-
编写测试类
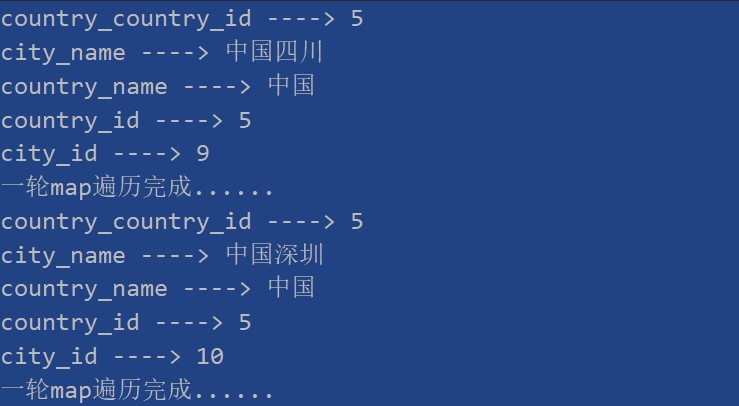
//测试多表关联查询 @Test public void test3(){ List<Map<String, Object>> result = cityRepository.findInfoByCountryId("5"); result.forEach(map -> { Set<String> keys = map.keySet(); keys.forEach(key -> { Object value = map.get(key); System.out.println(key + " ----> " + value); }); System.out.println("一轮map遍历完成......"); }); }
打印结果如下所示,至于你要怎么封装自己看着办吧!
第二种方式:EntityManager + Map封装
@Repository public class CityClassRepository { @PersistenceContext private EntityManager entityManager; public List entityManagerTest(String countryId){ String sql = "select * from country c1 LEFT JOIN city c2 ON c2.country_country_id = c1.country_id where c1.country_id = " + countryId; Query query = entityManager.createNativeQuery(sql); query.unwrap(SQLQuery.class).setResultTransformer(Transformers.ALIAS_TO_ENTITY_MAP); List list = query.getResultList(); return list; } }
-
编写测试类
@Autowired CityClassRepository cityClassRepository; @Test public void test4(){ List list = cityClassRepository.entityManagerTest("5"); list.forEach( item -> { System.out.println(item); }); }
结果无非就是这样,至于大家想怎么封装,自己还是看着办吧

第三种方式:Specification
这种方式还是封装的比较好的,如果有这方面需求还是可以考虑使用的,当然在业务不是很复杂的情况下,如果业务过于复杂,还是把Mybatis导进来吧
@Repository public interface CountryRepository extends JpaRepository<Country,Integer>, JpaSpecificationExecutor<Country> {} //Specification 多表查询 @Test public void test8(){ //创建 specification 对象 Specification<Country> specification = new Specification<Country>() { @Override public Predicate toPredicate(Root<Country> root, CriteriaQuery<?> query, CriteriaBuilder builder) { //第一个参数为关联对象的属性名称,第二个参数为连接查询的方式(left,inner,right) Join<Object, Object> join = root.join("list", JoinType.INNER); //where 城市的名字模糊查询为 '中国%' return builder.like(join.get("city_name").as(String.class),"中国%"); } }; List<Country> list = countryRepository.findAll(specification); list.forEach(country -> { System.out.println(country); }); }
JPA多表设计
关于映射的注解说明
@OneToMany
作用:建立一对多的关系映射;
属性: targetEntityClass:指定多的多方的类的字节码;
mappedBy:指定从表实体类中引用主表对象的名称;
cascade:指定要使用的级联操作;
fetch:指定是否采用延迟加载;
orphanRemoval:是否使用孤儿删除;
@ManyToOne
作用:建立多对一的关系 属性;
targetEntityClass:指定一的一方实体类字节码;
cascade:指定要使用的级联操作;
fetch:指定是否采用延迟加载;
optional:关联是否可选。如果设置为 false,则必须始终存在非空关系;
@ManyToMany
作用:用于映射多对多关系;
cascade:配置级联操作;
fetch:配置是否采用延迟加载;
targetEntity:配置目标的实体类。映射多对多的时候不用写;
@JoinTable
作用:针对中间表的配置 ;
name:配置中间表的名称;
joinColumns:中间表的外键字段关联当前实体类所对应表的主键字段;
inverseJoinColumn:中间表的外键字段关联对方表的主键字段;
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系;
name:指定外键字段的名称;
referencedColumnName:指定引用主表的主键字段名称;
unique:是否唯一。默认值不唯一;
nullable:是否允许为空。默认值允许;
insertable:是否允许插入。默认值允许;
updatable:是否允许更新。默认值允许;
columnDefinition:列的定义信息;
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系;
name:指定外键字段的名称;
referencedColumnName:指定引用主表的主键字段名称;
unique:是否唯一。默认值不唯一;
nullable:是否允许为空。默认值允许;
insertable:是否允许插入。默认值允许;
updatable:是否允许更新。默认值允许;
columnDefinition:列的定义信息;
关于注解中值的选择
cascade:指定要使用的级联操作
CascadeType.MERGE 级联更新
CascadeType.PERSIST 级联保存:
CascadeType.REFRESH 级联刷新:
CascadeType.REMOVE 级联删除:
CascadeType.ALL 包含所有
在数据库表的关系中,有三种关系存在,无非就是一对一、一对多、多对多,一对一这种东西我们再详细去说就有点大可不必的感觉了,简单带过吧
一对一
假如一个人一辈子只能买一套房,这个房子和这个人永远只能保证一对一关系,实体关系如下所示
两个实体类,无非就是你中有我,我中有你,反反复复,生死不休
-
住址实体类
@Entity @Table(name = "address") @Data @NoArgsConstructor @AllArgsConstructor @ToString public class Address { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id;//id private String phone;//手机 private String zipcode;//邮政编码 private String address;//地址 //如果不需要根据Address级联查询People,可以注释掉 @OneToOne(mappedBy = "address", cascade = {CascadeType.MERGE, CascadeType.REFRESH}, optional = false) private People people; }
-
人实体类
@Entity @Table(name = "people") @Data @NoArgsConstructor @AllArgsConstructor public class People { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id;//id private String name;//姓名 private String sex;//性别 @OneToOne(cascade = CascadeType.ALL)//People是关系的维护端,当删除 people,会级联删除 address @JoinColumn(name = "address_id", referencedColumnName = "id")//people中的address_id字段参考address表中的id字段 private Address address;//地址 @Override public String toString() { return "People{" + "id=" + id + ", name='" + name + '\'' + ", sex='" + sex + '\'' + '}'; }
-
编写测试类
-
注意Tostring的栈溢出问题,你包含我,我包含你,你又包含我,我又包含你,如此套娃到栈溢出
-
//测试一对一,查一个人,级联查询到他的地址信息 @Test public void test1(){ Optional<People> optional = peopleRepository.findById(100L); if (optional.isPresent()){ People people = optional.get(); Address address = people.getAddress(); //会将人员信息和人员的地址信息全部查询出来 //我手动将address排除在people的ToString中排除了,禁止套娃,禁止栈溢出 System.out.println(people); System.out.println(address); } } //测试一对一,查地址信息,得到该人的信息 //这一注意ToString造成的栈溢出问题,重写ToString函数,且不能包含一对一属性 @Test public void test2(){ Optional<Address> optional = addressRepository.findById(1L); if (optional.isPresent()){ Address address = optional.get(); System.out.println(address); } }
一对多
这个我们使用国家和城市来做说明:一个国家对应多个城市
无非就是要在实体中体现出,一个国家有多个城市的信息,一个城市对应着一个国家的信息
在这里,我们就要理解一个概念
主表:就是一的一方,在这个列子中,国家应该是主表
从表:就是多的一方,在这个列子中,城市就是从表
主从关联:外键
-
国家实体类
@Data @Entity @Table(name = "country") public class Country { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer country_id; private String country_name; @OneToMany(cascade = CascadeType.ALL , mappedBy = "country",fetch = FetchType.EAGER) private List<City> list = new ArrayList(); @Override public String toString() { return "Country{" + "country_id=" + country_id + ", country_name='" + country_name + '\'' + ", list=" + list + '}'; }
-
城市实体类
@Data @Entity @Table(name = "city") public class City { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer city_id; private String city_name; @ManyToOne(cascade = CascadeType.ALL) private Country country; @Override public String toString() { return "City{" + "city_id=" + city_id + ", city_name='" + city_name + '\'' + '}'; }
针对以上的配置,下面们边说边讲,这里有点意思的
-
级联保存
//测试一对多,级联保存,你中有我,我中有你,互相套娃 @Test public void test1(){ Country country = new Country(); country.setCountry_name("中国"); City city1 = new City(); city1.setCity_name("中国四川"); //维护城市与国家的一对一关系 city1.setCountry(country); City city2 = new City(); city2.setCity_name("中国深圳"); //维护城市与国家的一对一关系 city2.setCountry(country); //维护国家与城市的一对多关系 country.getList().add(city1); country.getList().add(city2); //保存国家,会级联保存城市,并做好外键关系 Country save = countryRepository.save(country); System.out.println(save); }
-
级联查询
//测试一对多,级联查询 //一的一方: fetch = FetchType.EAGER @Test public void test2(){ Optional<Country> optional = countryRepository.findById(6); if (optional.isPresent()){ Country country = optional.get(); System.out.println(country); } } //测试一对多,级联查询 //多的一方 @Test public void test3(){ Optional<City> optional = cityRepository.findById(12); if (optional.isPresent()){ City city = optional.get(); Country country = city.getCountry(); System.out.println(city); System.out.println(country); } }
-
级联删除(孤儿删除不外如是)
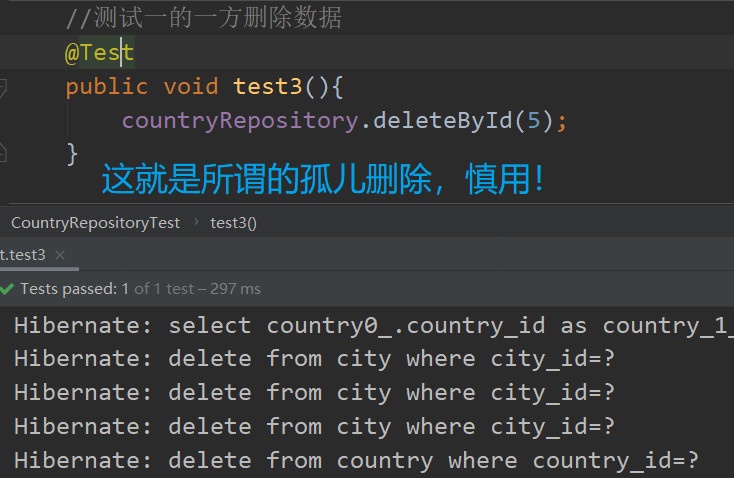
我们删除国家,国家是属于一的一方,当属主表
但是我们国家的id,正在被城市从表所外键关联,所以会删除失败
JPA的操作就是,我不管,反正我就是要干你,你从表阻碍我,那等我把你从表干掉再来干你
然后惨绝人寰,骇人听闻的全家丧命案就此拉开序幕
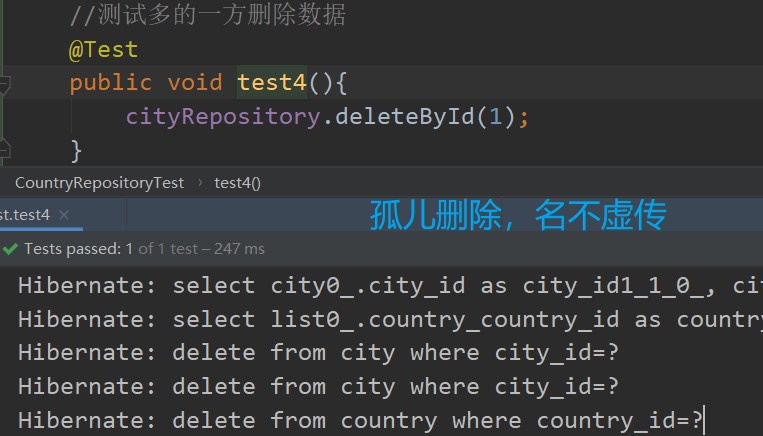
大家是否能看懂这里的逻辑?
首先我们调用api删除城市的相关信息
然后发现我们的城市好像关联了一个国家
不得行,以绝后患,大丈夫有所为有所不为,一锅端,把国家也干掉
在干掉国家的过程中,发现该国家又在被其他的城市的外键所关联
大丈夫一不做二不休,索性一梭子全部撂倒,先把关联的城市全部干掉,再把国家干掉
谁能知道,一个千城之主会因为一个小城找来杀生灭城之祸呢!
所以,人送孤儿删除,也不为过吖!
当然这些都是可以配置的,就在最上面的注解说明中进行配置,孤儿删除不建议使用,非常!
多对多
这里我们就使用学生和老实的关系来做一个说明
一个老师对应多个学生
一个学生对应多个老实
所谓的一个男人配多个女人,一个女人也配多个男人,心胸宽广点,对一群人都好;
-
学生实体类
@Data @AllArgsConstructor @NoArgsConstructor @Entity @Table(name = "student") public class Student { @Id private Integer s_id; private String s_name; @ManyToMany(cascade = CascadeType.ALL) @JoinTable( name = "student_teacher", joinColumns = @JoinColumn(name = "student_id"), inverseJoinColumns = @JoinColumn(name = "teacher_id") ) private List<Teacher> teachers = new ArrayList(); public Student(Integer id , String name){ this.s_id = id; this.s_name = name; } @Override public String toString() { return "Student{" + "s_id=" + s_id + ", s_name='" + s_name + '\'' + ", teacherss=" + teachers + '}'; } }
-
老师实体类
@Data @AllArgsConstructor @NoArgsConstructor @Entity @Table(name = "teacher") public class Teacher { @Id private Integer t_id; private String t_name; @ManyToMany(cascade = CascadeType.ALL) @JoinTable( name = "student_teacher", joinColumns = @JoinColumn(name = "teacher_id"), inverseJoinColumns = @JoinColumn(name = "student_id") ) // @ManyToMany(mappedBy = "teachers") private List<Student> students = new ArrayList(); public Teacher(Integer id , String name) { this.t_id = id; this.t_name = name; } @Override public String toString() { return "Teacher{" + "t_id=" + t_id + ", t_name='" + t_name + '\'' + '}'; }
-
编写测试类
//以一个学生关联多个老师,此时只需我中有你即可,无需你中再有我
@Test public void test1(){ Student student1 = new Student(1,"张三"); Student student2 = new Student(2,"李四"); Student student3 = new Student(3,"王五"); Teacher teacher1 = new Teacher(100,"钱老师"); Teacher teacher2 = new Teacher(200,"熊老师"); student1.getTeachers().add(teacher1); student2.getTeachers().add(teacher1); student3.getTeachers().add(teacher1); student1.getTeachers().add(teacher2); student2.getTeachers().add(teacher2); student3.getTeachers().add(teacher2); List<Student> students = studentRepository.saveAll(Arrays.asList(student1, student2, student3)); System.out.println(students); } //查询一个学生关联到的所有老师,学生类不能关闭懒加载:fetch = FetchType.EAGER,默认为LAZY @Test public void test2(){ Optional<Student> optional = studentRepository.findById(1); if (optional.isPresent()){ Student student = optional.get(); List<Teacher> teachers = student.getTeachers(); System.out.println(student); System.out.println(teachers); } } //查询一个老师关联的所有的学生,若想级联查询,老师类也必须防止懒加载 //fetch = FetchType.EAGER 立即加载 //fetch = FetchType.LAZY 懒加载 @Test public void test3(){ Optional<Teacher> optional = teacherRepository.findById(100); if (optional.isPresent()){ Teacher teacher = optional.get(); List<Student> students = teacher.getStudents(); System.out.println(teacher); System.out.println(students); } } //测试级联,我们的级联设置为cascade = CascadeType.ALL 所有操作都是级联 @Test public void test4(){ //孤儿删除起效果了 //该学生的老师被级联删除 //老师又级联到其他的学生 //其他的学生又级联到其他的老师 //禁止套娃,跑路吧,再不跑就来不及了 studentRepository.deleteById(1); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号