Backpropagation
一般都是用链式法则解释
比如如下的神经网络
![]()
![w_5]()
对隐藏层的![w_1]()
=======================
上述![\delta]() 就是教程Unsupervised Feature Learning and Deep Learning Tutorial 中第三步计算的由来。。
就是教程Unsupervised Feature Learning and Deep Learning Tutorial 中第三步计算的由来。。
![]()
【1】A Step by Step Backpropagation Example
【2】Unsupervised Feature Learning and Deep Learning Tutorial
比如如下的神经网络
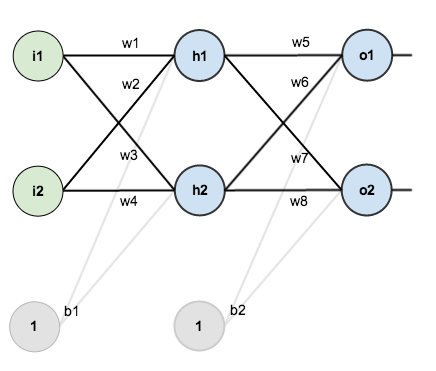
- 前向传播
对于节点来说,
的净输入
如下:
接着对做一个sigmoid函数得到节点
的输出:
类似的,我们能得到节点、
、
的输出
、
、
。
- 误差
得到结果后,整个神经网络的输出误差可以表示为:
其中就是刚刚通过前向传播算出来的
、
;
是节点
、
的目标值。
用来衡量二者的误差。
这个也可以认为是cost function,不过这里省略了防止overfit的regularization term(
)
展开得到
- 后向传播
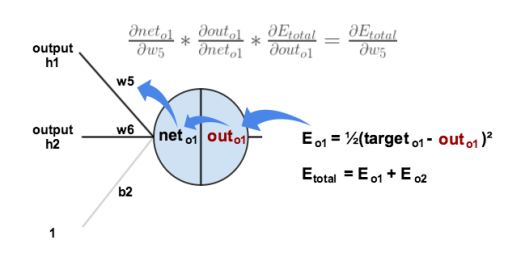
通过梯度下降调整,需要求
,由链式法则:
,
如下图所示:
以上3个相乘得到梯度,之后就可以用这个梯度训练了:
很多教材比如Stanford的课程,会把中间结果记做
,表示这个节点对最终的误差需要负多少责任。。所以有
。
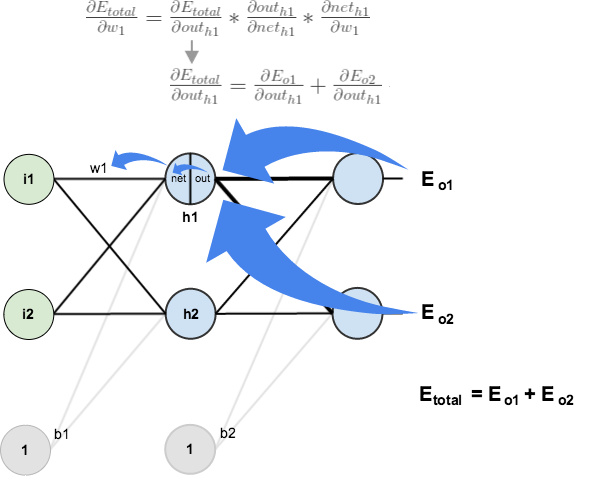
对隐藏层的
通过梯度下降调整,需要求
,由链式法则:
,
如下图所示:参数
影响了
,进而影响了
,之后又影响到
、
。
求解每个部分:,
其中,这里
之前计算过。
的计算也类似,所以得到
。
的链式中其他两项如下:
,
相乘得到
得到梯度后,就可以对迭代了:
。
在前一个式子里同样可以对进行定义,
,所以整个梯度可以写成
 参数
参数=======================
上述

所谓的后向传播,其实就是『将来在宣传传播上出了偏差,你们要负责的!』,每一个节点负责的量用表示,那么,隐藏节点需要负责的量,就由输出节点负责的量一层层往前传导。
【1】A Step by Step Backpropagation Example
【2】Unsupervised Feature Learning and Deep Learning Tutorial

 浙公网安备 33010602011771号
浙公网安备 33010602011771号