高级数据操作(上)
数据的操作也叫做CRUD
C:Create
R:Read
U:Update
D:Delete
一.插入数据
标准语法:
1 insert into 表名[字段列表] values(值列表);
思考:
1,如何以最快的速度向数据表中插入100万条数据?
(1)蠕虫复制
含义:在已有的数据的基础之上,将原来的数据进行复制,插入到对应的表中(也可以插入到自己的表中);
1 -- 蠕虫复制 2 insert into 表名 select *|字段列表 from 表名; 3 4 create table ruchong1( 5 a int , 6 b int 7 ); 8 9 10 insert into ruchong1 values(12,23),(9,18),(34,56),(13,35); 11 12 create table ruchong2( 13 a int , 14 b int 15 ); 16 17 insert into ruchong2 select * from ruchong1; --重复插入10多次就行了
作用:
1, 以最快的速度将一张表的数据复制到另一张表中,前提是后面查询结果的结构与前面插入数据表的结构是一样的!
2, 短期内产生大量的数据,以测试服务器的压力!
(2)主键重复
常见的一个场景:
在进行数据插入的时候,主键已经存在,但是又需要将最新的数据更新到记录中,怎么办?
比如,更新手机号码的机主信息:
1 create table tel_info( 2 tel_no char(11) primary key, 3 tel_name varchar(20), 4 tel_id char(18) 5 ); 6 7 insert into tel_info values('13612345678','张三','440921199411080845'); 8 insert into tel_info values('13612345678','李四','440921199411080883');-- 出错了
此时,有两种解决方案:
1 -- 方案一: 2 -- 如果主键冲突,直接更新: 3 insert into 表名(字段列表) values(值列表) on duplicate key update 字段1=值1,字段2=值2...; 4 5 -- 执行流程:先执行插入语句,如果遇到主键重复,就变成执行一条更新语句。 6 7 insert into tel_info values('13612345678','李四','440921199411080883') on duplicate key update tel_name = '李四',tel_id='440921199411080883'; 8 -- 方案二: 9 -- 如果主键冲突,就直接删除原记录,再插入 10 replace into 表名(字段列表) values(值列表); 11 12 replace into tel_info values('13612345678','张三','440921199411080845'); 13 14 --执行流程:先判断主键有没有重复,如果没有,就执行正常的插入语句,如果有就先执行删除之前的再插入新的! 15
二.修改数据
1 -- 修改数据: 2 -- 标准语法: 3 4 update 表名 set 字段1 = 值1, 字段2 = 值2..where 条件; 5 6 7 -- 其他语法: 8 update 表名 set 段1 = 值1, 字段2 = 值2..where 条件 order by 字段名[asc|desc] limit 数据量; 9 -- asc是升序 默认值 10 -- desc 是降序 11 create table user_info( 12 user_id int unsigned primary key auto_increment, 13 user_name varchar(20), 14 user_tel char(11), 15 is_vip enum('Y','N'), 16 last_buy_time int unsigned, 17 user_score int unsigned 18 ); 19 20 -- 应用场景:商家做活动,给前最先到的100名的vip用户的积分增加500分! 21 22 update user_info set user_score = user_score + 500 where is_vip='Y' order by last_buy_time asc limit 100 23 24 /* 也就是说,修改数据的时候可以使用order by关键字进行排序然后再限制修改的数量! 25 注意:where修改条件、order by子句以及limit子句的顺序不能发生改变! 26 27 同样的,删除数据的时候也可以加上order by子句和limit子句: 28 */
三.删除数据
1 -- 标准语法: 2 delete from 表名 where 删除条件 3 4 -- 其他语法: 5 delete from 表名 where 删除条件 order by 字段名[asc|desc] limit 数量;
四.查询数据
1 -- 查询数据是业务逻辑中使用的最多的也是最复杂的! 2 -- 以前的语法: 3 select *|字段列表 from 表名 where 查询条件; 4 -- 比较完整的语法: 5 6 7 select [select选项] *|字段列表 [as 别名] from 数据源 [where子句] [group by子句][having子句][order by子句][limit子句]; 8 9 /* 10 注意: 11 1, from后面的子句往往叫做五子查询,也叫做五子句 12 2, 五子查询的选项都可以没有,但是如果有,必须按顺序写! 13 */
五.select选项与别名
(1)select选项
1 /* 2 就是查询到数据之后,该如何保留查询结果! 3 一共有两个值: 4 all:也是默认值,保留所有的查询结果! 5 distinct:去重,去掉重复的记录,这里的重复是指所有的字段的值完全一样! 6 7 一般来说,如果查询的是所有的字段,用缺省值(省略即可)就行, 8 如果查询的是部分字段,可以进行去重操作! 9 */ 10 11 insert into ruchong2 values(23,24),(35,36),(10,35);
1 select b from ruchong2;
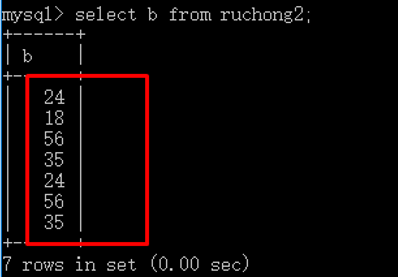
1 select distinct b from ruchong2; -- 去重

(2)别名
1 -- 所谓的别名就是给字段或者其他表达式等标识符起一个别名.基本语法: 2 -- 别名 3 字段名|表达式|表|子查询语句[as] 别名 4 -- 其中as可以省略,但是建议写上
1, 为什么给字段起别名呢?
因为在进行联表查询的时候,两张表可能会出现相同的字段名:

比如上面的学生表中的学生字段和成绩表中的学生字段!这样将来PHP在提取记录的时候,后面的数组元素会覆盖前面的(下标值是一样的),所以,有必须给她们两个中至少一个起一个别名!
2,为什么要给表达式起别名?
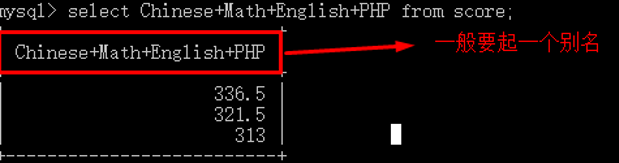
1 create table score( 2 chinese float, 3 Math float, 4 English float, 5 PHP float 6 ); 7 8 insert into score values 9 (78.5,89,76,93), 10 (77,69,70,98), 11 (76.5,79,96,90), 12 (75.5,99,96,93); 13 14 select Chinese+Math+English+PHP from score;
1 select Chinese+Math+English+PHP as sum from score;
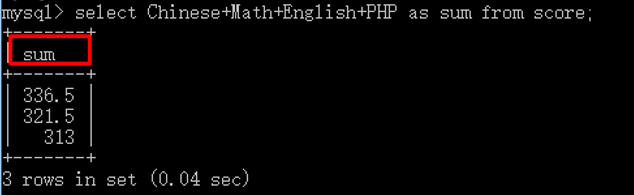
一般需要给一个表达式起一个别名,用于代表其所表达的含义,增强可读性!
3,为什么要给表起别名?
因为,在真实的项目中,数据表的表名往往比较长,懒得写!
4,为什么要给子查询语句起别名呢?
当数据源是一个子查询语句的时候,必须给子查询语句起一个别名
六.where子句
1 select [select选项] *|字段列表 [as 别名] from 数据源 [where子句] [group by子句][having子句][order by子句][limit子句];
语法与功能
where 表达式;
功能:通过限定条件对数据进行筛选过滤,得到想要的结果!
流程:逐一取出每一条记录,先通过当前的记录来计算where后面表达式的值,如果计算的结果为假(0),就不返回该记录,如果计算的结果为真(非0),就返回该记录!相当于对所有的记录进行了一次遍历!
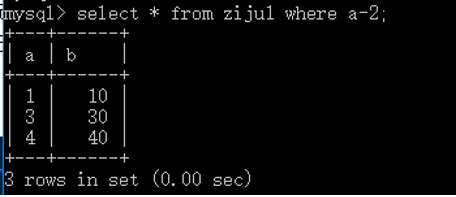
1 create table ziju1( 2 a int primary key auto_increment, 3 b int 4 ); 5 insert into ziju1 values 6 (null,10), 7 (null,20), 8 (null,30), 9 (null,40), 10 (null,50); 11 select * from ziju1 where a-2;
七.MySQL运算符
关系运算符
= !=(<>)
< >
>= <=
注意:这里的等于就是一个等号=
between…and…
范围比较,相当于数学上的闭区间!
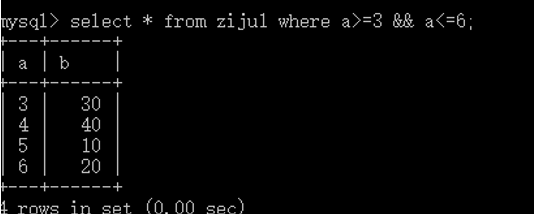
相当于:
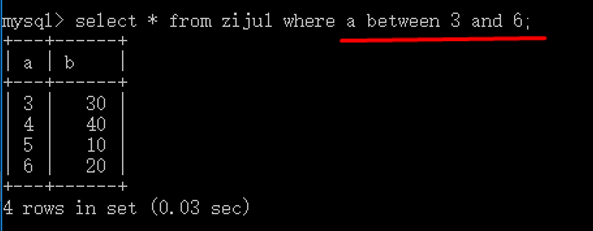
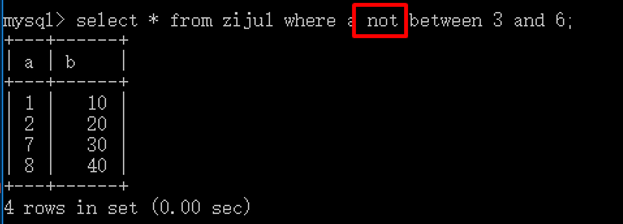
当然,between and的前面也可以加上not,代表相反!
in 和 not in
语法形式:
in | not in(集合元素)
1 in 和not in 2 3 -- 语法形式; 4 in| not in(集合元素) 5 select * from ziju1 where a in(2,4,6,8,10,12); 6 select * from ziju1 where a not in(2,4,6,8,10,12); 7 -- 其中:in可以用 = any 或者 =some 代替
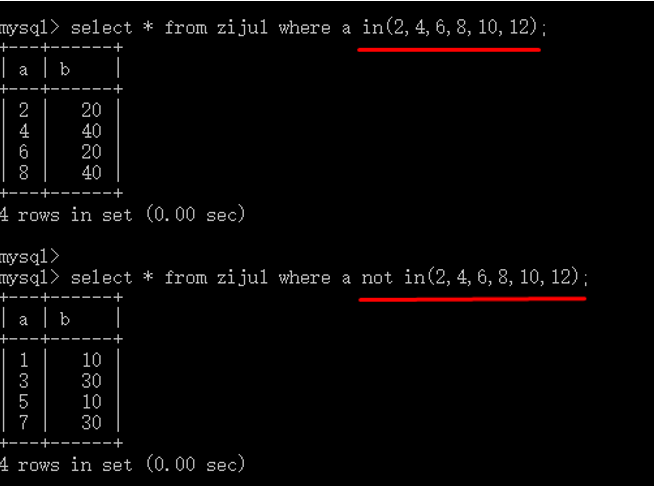
其中:
in 可以用 = any 或= some代替!
逻辑运算符
&& 或 and
|| 或 or
!或not
八.where子句的其他形式
(1)空值查询
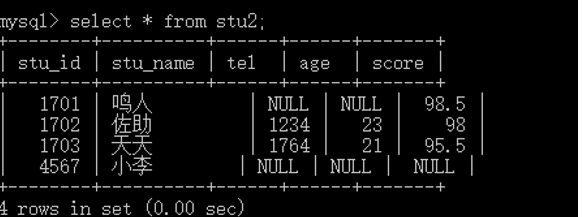
比如,想查询上面tel字段为NULL的记录,怎么办?
1 select * from stu3 where tel = NULL; //错误的 2 3 select * from stu3 where tel is NULL;-- 正确的 4 5 -- 还有is not NULL 不为空的
(2)模糊查询
1 select *| 字段列表 from 表名 where 字段名[not] like '通配符字符串';
所谓的通配符字符串,就是含有通配符的字符串!
MySQL通配符有两个:
_ :代表任意的一个字符!
% :代表任意的字符,包括0个!
1 create table student( 2 id int unsigned primary key auto_increment, 3 name varchar(20) 4 ); 5 insert into student values 6 (null,'张三'), 7 (null,'张三德'), 8 (null,'李四'), 9 (null,'李俊德'), 10 (null,'李三德'), 11 (null,'三德子'), 12 (null,'三师弟'), 13 (null,'三德');
例1:查找student表中name字段所有以张姓开头的记录
1 select * from student where name like'张%';
例2:查找student表中name字段所有以张姓开头的并且名有两个字的记录
1 select * from student where name like '张__';
例3:查找student表中name字段以李开头,以德结尾的
1 select * from student where name like '张%德';
例4:查找student表中name字段中所有包含“三”字的记录
1 select * from student where name like '%三%';
注意:
由于,%和_有特殊的含义,所以,如果确实想查询某个字段中含有%或_的记录,需要对它们进行转义,也就是查询\% 和 \_
例5:查找student表中name字段中所有包含“%”字的记录
1 insert into student values 2 (null,'李%'), 3 (null,'张_德'), 4 (null,'%李四'); 5 select * from student where name like '%\%%'; 6 select * from student where name like '%\_%';
九.group by子句
1 select [select选项] *|字段列表 [as 别名] from 数据源 [where子句] [group by子句][having子句][order by子句][limit子句]; 2 3 -- 也叫做分组统计查询语句!
语法
group by 字段名1 select * from php_student group by home; -- 分组后,相当于从每一个组内取出一条记录,这种查询结果毫无意义 -- 分组统计的主要作用是为了统计,此时就要用到mysql系统内置函数
十.统计函数(聚合函数)
sum():求和
max():求最大值
min():求最小值
avg():求平均值
count():求非NULL记录的个数,通常用count(*)来表示!
在实际的运用中,group by通常就是配合上面的统计函数一起使用的!!
比如:现在需要求每一个家乡的总人数、年龄之和以及平均分!
select home,count(*),sum(age),avg(score) from php_student group by home;
思考:
先分组后统计还是先统计后分组?
很显然,是先分组后统计!
上面的执行流程是:先根据home字段进行分组,然后再统计每一个分组内的总人数,年龄之和以及平均分!
当然,一般要给统计函数起一个别名:
1 select home,count(*) as count, 2 sum(age) as sum, 3 avg(score) as avg 4 from php_student group by home;
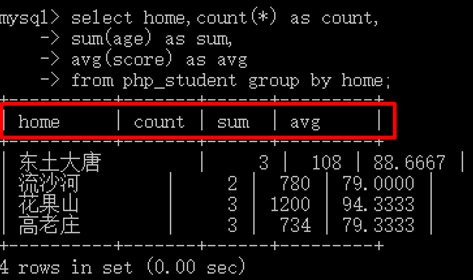
注意:
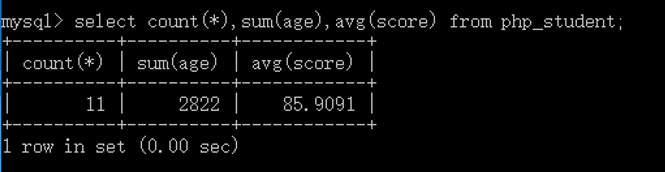
一旦使用到了统计函数,系统默认的一定是有分组!即使没有后面的group by子句,系统也默认的是将所有的记录当成一个分组!
多字段分组
1 group by 字段名1,字段名2... 2 3 -- 其实及就是先根据字段名1进行分组,再根据字段名2进行分组! 4 5 select home,gender,count(*) as count, 6 sum(age) as sum, 7 avg(score) as avg 8 from php_student group by home,gender;
结果分组的个数就变多了:
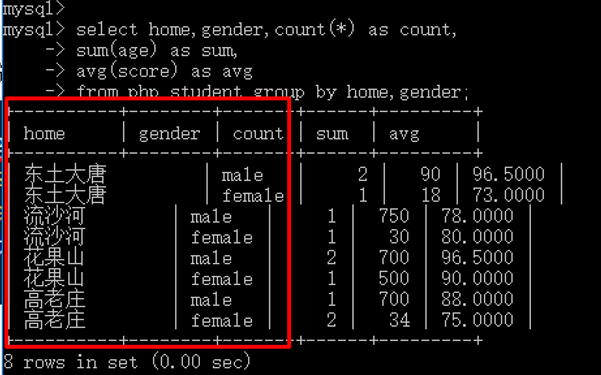
回溯统计:
1 /* 2 其实就是向上统计! 3 1班 53人 4 2班 65人 5 3班 85人 6 如果在统计的时候,做一次向上统计,于是就得到了所有班的总人数203! 7 */ 8 -- 在mysql中在语句里面加上with rollup 就行了! 9 10 select class_id,count(*) from php_student group by class_id with rollup;

十一.having子句
1 select [select选项]*|字段列表 from 数据源[where 子句][group by 子句][having 子句][order by 子句][limit 子句]; 2 3 4 -- having 子句与where 子句一样,也是用来筛选,一般针对group by统计之后再次进行筛选 5 6 select home,gender,count(*) as count, 7 sum(age) as sum, 8 avg(score) as avg 9 from php_student group by home,gender having avg>=80;
1 /* 2 having 与where子句有什么区别呢? 3 二者的比较: 4 1.如果语句中的五子查询中只有having子句或者where子句,此时,他们的作用一样, 5 */ 6 select * from php_student where age>100; 7 select * from php_student having age>100; 8 9 -- 2.二者最本质德区别是。where子句是把磁盘上的数据筛选到内存中,而having子句是把内存中的数据再次进行筛选! 10 11 -- 3.where 子句后面不能使用统计函数,而having是可以的,因为数据只有在内存中才能参与运算 12 select * from php_student having avg(score)>100;
十二.order by
1 -- 根据某个字段进行排序,有升序和降序之分,默认升序(asc) 2 3 -- 语法: 4 order by 字段名[asc|desc] 5 select * from php_student order by score;
十三. 多字段排序
order 字段名1[asc|desc],字段名2[asc|desc] -- 先按第一个字段进行排序,如果第一个字段相同,才按照第二个字段进行排序 select * from php_student order by score asc ,age asc;
十四.limit子句
(1)limit offset,length;或者limit length;
其中,offset是指偏移量,默认为0(也就是第一条记录),而length是指需要显示的总记录数!
比如:想获取第3条到第6条记录,应该怎么限制?
1 -- 获取第3条到第6条 2 select * from php_student limit 2,4;
如果规定的length超出了余下的记录数,相当于获取了剩余的所有的记录!
(2)分页原理
项目中如果要使用分页效果,就应该使用limit子句!
比如,每页显示10条:

-- 如果用$pageNum代表第多少多少页,用$rowsPerPage代表每页显示的记录数 -- 某一页$pageNum的limit子句应该是: limit ($pageNum-1)*$rowsPerPage,$rowsPerPage;
