MySQL的索引分类
MySQL的索引分类问题一直让人头疼,几乎所有的资料都会给你列一个长长的清单,给你介绍什么主键索引、单值索引,覆盖索引,自适应哈希索引,全文索引,聚簇索引,非聚簇索引等……给人的感觉就是云里雾里,好像MySQL索引的实现方式有很多种,但是都没有一个清晰的分类。所以本人尝试总结了一下如何给MySQL的索引类型分类,便于大家记忆,由于MySQL中支持多种存储引擎,在不同的存储引擎中实现略微有所差距,下文中如果没有特殊声明,默认指的都是InnoDB存储引擎。
索引从不同维度划分可以有很多种名称,但是需要明确一个问题——索引的本质是一种数据结构,其他索引的划分则是针对实际应用而言。
一、根据底层数据结构划分
索引是提高查询效率的数据结构,而能够提高查询效率的数据结构有很多,如二叉搜索树,红黑树,跳表,哈希表(散列表)等,而MySQL中用到了B+Tree和散列表(Hash表)作为索引的底层数据结构(其实也用到了跳表实现全文索引,但这不是重要考点,所以可以忽略)。
- 1. hash索引
- MySQL并没有显式支持Hash索引,而是作为内部的一种优化。具体在Innodb存储引擎里,会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,就为之建立hash索引。因此,在MySQL的Innodb里,对于热点的数据会自动生成Hash索引。这种hash索引,根据其使用的场景特点,也叫自适应Hash索引。
- 2. B+树索引
- 这个是MySQL索引的基本实现方式。除了全文索引、hash索引,Innodb、MyISAM的索引都是通过B+树实现的。
二、根据索引字段个数划分
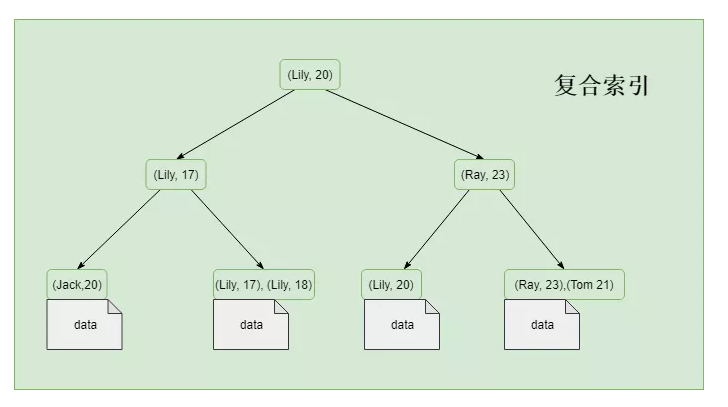
为了能应对不同的数据检索需求,索引既可以仅包含一个字段,也可以同时包含多个字段。单个字段组成的索引可以称为单值索引,否则称之为复合索引,也称为组合索引或多值索引。
这个很好理解,假如我们有一张表,有三个属性,分别是 id,age 和 name 。假如在id上建立索引,那这就是单值索引;如果在 name 和 age 上建立索引,那这就是复合索引。
复合索引的索引的数据顺序跟字段的顺序相关,包含多个值的索引中,如果当前面字段的值重复时,将会按照其后面的值进行排序。
使用覆盖索引的前提是字段长度比较短,对于值长度较长的字段则不适合使用覆盖索引,原因有很多,比如索引一般存储在内存中,如果占用空间较大,则可能会从磁盘中加载,影响性能。
三、根据是否是在主键上建立的索引进行划分
- 1. 主键索引
- MySQL中是根据主键来组织数据的,所以每张表都必须有主键索引,主键索引只能有一个,不能为null同时必须保证唯一性。建表时如果没有指定主键索引,则会自动生成一个隐藏的字段作为主键索引。
- 2. 辅助索引
- 如果不是主键索引,则就可以称之为非主键索引,又可以称之为辅助索引或者二级索引。主键索引的叶子节点存储了完整的数据行,而非主键索引的叶子节点存储的则是主键索引值,通过非主键索引查询数据时,会先查找到主键索引,然后再到主键索引上去查找对应的数据。
- 在这里假设我们有张表user,具有三列:ID,age,name,create_time,id是主键,(age,create_time,,name)建立辅助索引。执行如下sql语句:
- select name from user where age>2 order by create_time desc。
- 正常的话,查询分两步:
- 1.按照辅助索引,查找到记录的主键,
- 2.按照主键主键索引里查找记录,返回name。
- 但实际上,我们可以看到,辅助索引节点是按照age,create_time,name建立的,索引信息里完全包含我们所要的信息,如果能从辅助索引里返回name信息,则第二步是完全没有必要的,可以极大提升查询速度。
- 按照这种思想Innodb里针对使用辅助索引的查询场景做了优化,叫覆盖索引(在这里小声吐槽一下,不知道业界起这种名词干嘛,太容易引起歧义了,叫个索引覆盖查询不是更好吗)。
四、根据数据与索引的存储关联性划分
根据数据与索引的存储关联性,可以分为聚簇索引和非聚簇索引(也叫聚集索引和非聚集索引)。聚簇索引也叫簇类索引,是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序。整个简洁的说法,这俩的区别就是索引的存储顺序和数据的存储顺序是否是关系的,有关就是聚簇索引,无关就是非聚簇索引。具体实现方式根据索引的数据结构不同会有所不同。下面以B+树实现的索引为例,举例来说明聚簇索引和非聚簇索引。
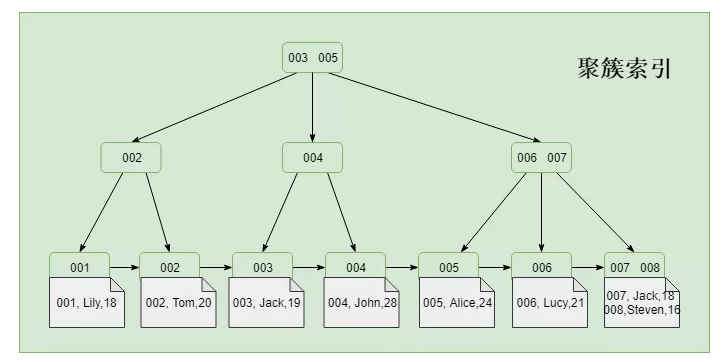
- 1. 聚簇索引
- Innodb的主键索引,非叶子节点存储的是索引指针,叶子节点存储的是既有索引也有数据,是典型的聚簇索引(这里可以发现,索引和数据的存储顺序是强相关的。因此是典型的聚簇索引),如图:
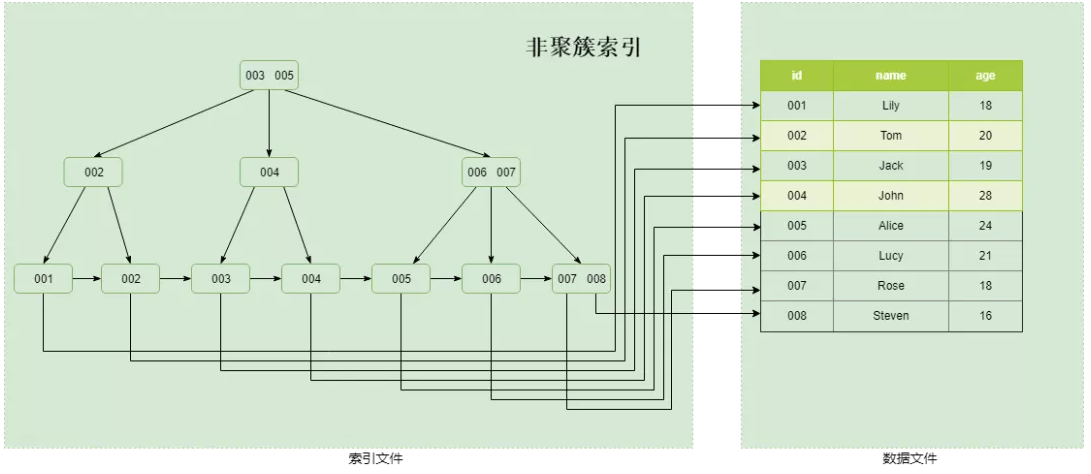
- 2. 非聚簇索引
- MyISAM中索引和数据文件分开存储,B+Tree的叶子节点存储的是数据存放的地址,而不是具体的数据,是典型的非聚簇索引;换言之,数据可以在磁盘上随便找地方存,索引也可以在磁盘上随便找地方存,只要叶子节点记录对了数据存放地址就行。因此,索引存储顺序和数据存储关系毫无关联,是典型的非聚簇索引,另外Inndob里的辅助索引也是非聚簇索引。
五、其他分类
- 1. 唯一索引
- 顾名思义,不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查, 如果有重复的值,则会操作失败,抛出异常。
- 需要注意的是,主键索引一定是唯一索引,而唯一索引不一定是主键索引。唯一索引可以理解为仅仅是将索引设置一个唯一性的属性。
- 2. 全文索引
- 在MySQL 5.6版本以前,只有MyISAM存储引擎支持全文引擎。在5.6版本中,InnoDB加入了对全文索引的支持,但是不支持中文全文索引.在5.7.6版本,MySQL内置了ngram全文解析器,用来支持亚洲语种的分词。主要用来利用关键词查询文本,不是MySQL的主要面向场景,使用较少,这里就不展开讨论了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号