06.深入学习redis replication的完整流程和原理
一、replication的完整流程
- slave配置master ip和port
# slaveof <masterip> <masterport>
slaveof 127.0.0.1 6379
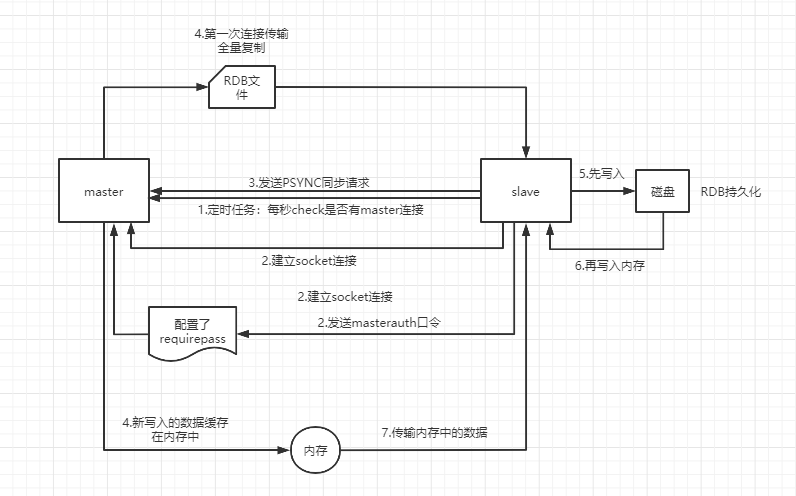
- slave node内部有个定时任务,每秒检查是否有新的master node要连接和复制,如果发现,就跟master node建立socket网络连接
- slave node发送ping命令给master node。如果master设置了requirepass,那么salve node必须发送masterauth的口令过去进行认证
- master node第一次执行全量复制,将所有数据发给slave node
- master node后续持续将写命令,异步复制给slave node
二、全量复制
- master执行bgsave,在本地生成一份rdb快照文件
- master node将rdb快照文件发送给salve node,如果rdb复制时间超过60秒(repl-timeout),那么slave node就会认为复制失败,可以适当调节大这个参数
- master node在生成rdb时,会将所有新的写命令缓存在内存中,在salve node保存了rdb之后,再将新的写命令复制给salve node
- client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间,内存缓冲区持续消耗超过64MB,或者一次性超过256MB,那么停止复制,复制失败
- slave node接收到rdb之后,清空自己的旧数据,然后重新加载rdb到自己的内存中,同时基于旧的数据版本对外提供服务
- 如果slave node开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF
注意:rdb生成、rdb通过网络拷贝、slave旧数据的清理、slave aof rewrite,很耗费时间
三、增量复制
- 如果全量复制过程中,master-slave网络连接断掉,那么salve重新连接master时,会触发增量复制
- master直接从自己的backlog中获取部分丢失的数据,发送给slave node,默认backlog就是1MB
- msater就是根据slave发送的psync中的offset来从backlog中获取数据的
四、心跳
主从节点互相都会发送heartbeat信息
master默认每隔10秒发送一次heartbeat,salve node每隔1秒发送一个heartbeat
相关名词解释
- offset
master和slave都会在自身不断累加offset
slave每秒都会上报自己的offset给master,同时master也会保存每个slave的offset
作用:1)用在全量复制,2)可以彼此了解数据不一致的情况
- backlog
master node有一个backlog,默认是1MB大小。master给slave复制数据时,也会将数据在backlog中同步写一份。主要是用来做全量复制中断候的增量复制的。
- master run_id
执行info server命令可以看到run_id。
如果master重启,容易导致主从结点数据不一致的情况,重启后run_id会重新生成,那么slave应该根据变化的run_id知道master有变化,需要做全量复制。
如果需要不更改run_id重启redis,可以使用redis-cli debug reload命令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号