GNU GCC学习
1 Introduction
参考书籍:《An Introduction to GCC (Brian J. Gough, Richard.pdf》
GCC简介:GCC(GNU Compiler Collection,GNU编译器集合)。其主要特性如下:
- GCC是一个兼容的编译器,可以运行在大部分平台下,可以根据处理器不同产生许多类型的输出可执行文件。
- GCC不只是一个编译器,可以交叉编译产出不同系统的可执行文件。这允许为不能运行编译器编的嵌入式系统编译软件。GCC使用C语言编写的,可以自行编译。
- GCC有多个不同的语言前端,用于解析不同的语言。对于任何架构,每种语言的程序都可以编译或交叉编译。
- GNU使用模块化设计,允许添加新的语言和架构。在提供必要的运行工具(比如库)前提下,添加一个新的语言前端,可以在任何架构上使用该语言。同样的,添加对新架构的支持可以使它适用所有语言。
- 最后也是最重要的,GCC是自由软件,在GNU General Public License(GNU GPL)下发布。这意味着你可以任意的使用和修改GCC,如果你需要支持一个新的CPU类型,一种新语言,一种新特性,可以自行添加它们。此外,你可以自由分享对GCC的改进。由于这种自由,你也可以利用他人对GCC的改进。GCC提供的许多特性,都是这种自由合作方式来让大家受益的。
2 Compiling a C program
程序可以从一个或多个源文件被编译出来,也可以使用系统库和头文件。
编译是指将程序从源文件,比如C/C++编写的,转换为机器码,也就是0、1序列,然后在CPU上执行。机器码存放在一个可执行文件中,也就是二进制文件。
2.1 Compiling a simple C program
源程序,假设存放在hello.c:
#include <stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
编译和运行方式:
$ gcc -Wall hello.c -o hello
$ ./hello
hello world
"-o"选项:指定了输出文件名,通常作为最后的命令参数,不指定默认输出a.out,如果当前目录存在同名的输出文件,则会进行覆盖。"-Wall"选项:打开所有的commonly-used编译选项,建议始终使用此选项,如果不使用此选项,则编译不会产生警告,编译警告是定位问题的重要手段。
2.2 Finding errors in a simple program
为了验证GCC编译错误提示,下面使用通过错误的使用printf来证明,源程序:
#include <stdio.h>
int main(void)
{
printf("Two plus is %f\n", 4);
return 0;
}
- 编译使用
-Wall选项,会提示错误的信息在第5行,提示参数类型错误:
$ gcc -Wall bad.c -o bad
bad.c: In function ‘main’:
bad.c:5:2: warning: format ‘%f’ expects argument of type ‘double’, but argument 2 has type ‘int’ [-Wformat=]
printf("Two plus is %f\n", 4);
一般的错误信息提示格式为:file:line-number:message.
编译器区分错误消息error(阻止成功编译)和警告消息warning(指出可能存在的问题,但不停止程序编译)。
- 编译不使用
-Wall选项,程序编译没有警告,但运行会得到错误结果:
$ gcc bad.c -o bad
$ ./bad
Two plus is 0.000000
可以看出,不使用编译警告选项进行开发是非常危险的,甚至可能导致程序崩溃,或者得到错误的结果。打开编译器警告选项-Wall可以检测到很多C程序中常见的错误。
2.3 Compling multiple source files
一个程序可能划分为多个文件,这样可以便于编辑和理解。当然也允许独立的进行编译。
下面举例包括三个文件:main.c、hello.c和hello.h。
main.c源文件:
#include "hello.h"
int main (void)
{
hello ("world\n");
return 0;
}
hello.c源文件:
#include <stdio.h> /* 仅在系统头文件目录搜索 */
#include "hello.h" /* 先在当前目录中搜索,再去系统头文件目录搜索 */
void hello (const char * name)
{
printf ("Hello, %s!\n", name);
}
hello.h头文件:
int hello(const char *str);
编译多个源文件方式,然后运行:
$ gcc -Wall main.c hello.c -o newhello
$ ./newhello
Hello, world!
注意头文件hello.h并没有在命令行中指定,源文件中的#include "hello.h"会指示编译器在适当的位置自动包含它。
2.4 Compiling files independently
如果一个程序存放在一个文件中,那么任何一个函数的改动都需要重新编译整个程序,重新生成可执行文件。那么编译一个大型程序就很费时间。
当程序存放在独立的源程序文件中时,仅需要重新编译有改动的文件。基于这种方式,源文件分别编译,然后链接在一起,分为两个阶段:
-
在编译阶段,一个文件被编译不产生可执行文件,而是产生一个目标文件,文件为
.o后缀。 -
在链接阶段,目标文件
.o被通过链接器合并到一起,然后产生一个可执行文件。
目标文件包含机器码,其中对其它文件中函数(或变量)内存地址的任何引用都是未定义的。这允许在不直接引用彼此的情况下编译源文件。链接器会填充这些丢失的地址。
2.4.1 Creating object files from source files
命令行参数-c被用来编译一个源文件生成一个目标文件。比如编译一个main.c生成一个目标文件main.o:
$ gcc -Wall -c main.c
比如编译一个hello.c生成一个目标文件hello.o:
$ gcc -Wall -c hello.c
- 不需要使用
-o参数去指定输出文件名,当使用-c参数时,编译器自动创建一个使用.o替换源文件后缀的目标文件名。 - 不需要在命令行中指定头文件,因为在源文件中会使用
#include来自动包含内容。
2.4.2 Creating executables from object files
最后一步是使用gcc链接器去链接目标文件和填充外部函数的地址,然后生成可执行文件。
链接目标文件的命令为:
$ gcc main.o hello.o -o hello
$ ./hello
Hello, world!
这是少数不需要使用-Wall警告选项的情况之一,因为各个源文件已经成功编译为了目标文件。
一旦源文件编译完成,链接是一个明确的过程,要么成功要么失败(存在不能解析的引用时会失败)。
为了执行链接步骤,gcc使用链接器ld,这是一个独立的程序,通过执行链接器,产生一个可执行文件。
2.4.3 Link order of object files
在传统的类UNIX系统中,编译器和链接器查找外部函数的顺序是从命令行中从左到右的目标文件中查找。这意味着包含函数定义的文件应该出现在调用函数的后面。
在上面的例子中,hello.o包含了hello函数,应该出现在main.o的后面:
$ gcc main.o hello.o -o hello
现代大部分编译器和链接器会无序的搜索所有的目标文件,但不是所有的编译器都会这么做,所以最好遵循从左到有的顺序。
如果遇到了未定义引用的问题,并且所有的目标文件都在命令行中,那么可以注意一下这一点。
2.5 Recompiling and relinking
为了显示源文件编译,更改main.c,打印内容更改:
#include "hello.h"
int main (void)
{
hello ("everyone");
return 0;
}
更改main.c的重新编译命令:
$ gcc -Wall -c main.c
将生成一个新的目标文件main.o,不需要重新创建一个新的目标文件hello.o,因为文件的依赖,比如头文件,并没有改变。
新编译的目标文件可以重新和hello.o进行链接,然后创建一个新的可执行文件。
$ gcc main.o hello.o -o hello
$ ./hello
Hello, everyone!
仅main.c可以重新被编译,然后重新和已存在的目标文件进行链接。同样的,如果hello.c被更改,也可以重新编译hello.c重新生成一个目标文件,然后链接已有的main.o文件。
通常,在一个大型工程(有很多源文件)中,链接的速度快于编译的速度,重新编译仅更新过的文件可以节省大量的成本。只编译项目中修改过的文件可以通过GNU Make自动完成。
2.6 Linking with external libraries
本章节仅介绍静态库,下一个章节介绍动态库和动态链接。
库是预编译目标文件的集合,可以链接到程序中。通常大部分库提供系统函数,比如C数学库的sqrt函数。
库通常存放在具有特殊文件名后缀的文件中,.a表示静态库。他们用单独的工具(GNU ar)创建,并在链接器在编译阶段进行解析函数的引用。
标准系统库通常可以在/usr/lib和/lib中找到(32位系统)。比如在类UNIX系统中,C math库通常存放在/usr/lib/libm.a。这个库中函数相应原型声明在头文件/usr/include/math.h。
C标准库存放在/usr/lib/libc.a,并且包含ANSI/IOS C标准指定的函数,比如printf,这个库默认被链接。
下面的例子中会调用外部函数sqrt,存放在libm.a:
#include <math.h>
#include <stdio.h>
int main (void)
{
double x = sqrt (2.0);
printf ("The square root of 2.0 is %f\n", x);
return 0;
}
在旧版的GCC中,编译时会出现一个错误,找不到sqrt函数所在的库。
新版本GCC默认把libm.a加载了编译路径,加个-v参数可以查看。
$ gcc -v -Wall main.c -o main
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix --enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu --enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array --disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install --with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install --enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
COLLECT_GCC_OPTIONS='-v' '-Wall' '-o' 'main' '-mtune=generic' '-march=x86-64'
/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/cc1 -quiet -v main.c -quiet -dumpbase main.c -mtune=generic -march=x86-64 -auxbase main -Wall -version -o /tmp/ccuDiCoN.s
GNU C (GCC) version 4.8.5 20150623 (Red Hat 4.8.5-44) (x86_64-redhat-linux)
compiled by GNU C version 4.8.5 20150623 (Red Hat 4.8.5-44), GMP version 6.0.0, MPFR version 3.1.1, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/lib/gcc/x86_64-redhat-linux/4.8.5/include-fixed"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../x86_64-redhat-linux/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-redhat-linux/4.8.5/include
/usr/local/include
/usr/include
End of search list.
GNU C (GCC) version 4.8.5 20150623 (Red Hat 4.8.5-44) (x86_64-redhat-linux)
compiled by GNU C version 4.8.5 20150623 (Red Hat 4.8.5-44), GMP version 6.0.0, MPFR version 3.1.1, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: 231b3394950636dbfe0428e88716bc73
COLLECT_GCC_OPTIONS='-v' '-Wall' '-o' 'main' '-mtune=generic' '-march=x86-64'
as -v --64 -o /tmp/ccAjnTeX.o /tmp/ccuDiCoN.s
GNU assembler version 2.27 (x86_64-redhat-linux) using BFD version version 2.27-44.base.el7
COMPILER_PATH=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/:/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/:/usr/libexec/gcc/x86_64-redhat-linux/:/usr/lib/gcc/x86_64-redhat-linux/4.8.5/:/usr/lib/gcc/x86_64-redhat-linux/
LIBRARY_PATH=/usr/lib/gcc/x86_64-redhat-linux/4.8.5/:/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/:/lib/../lib64/:/usr/lib/../lib64/:/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../:/lib/:/usr/lib/
COLLECT_GCC_OPTIONS='-v' '-Wall' '-o' 'main' '-mtune=generic' '-march=x86-64'
/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/collect2 --build-id --no-add-needed --eh-frame-hdr --hash-style=gnu -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o main /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crt1.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crti.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtbegin.o -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5 -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64 -L/lib/../lib64 -L/usr/lib/../lib64 -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../.. /tmp/ccAjnTeX.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtend.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crtn.o
使编译器去链接sqrt函数生成可执行文件,需要支持libm.a库。在命令行中可以显示的指定静态库:
$ gcc -Wall main.c /usr/lib/libm.a -o main
生成的可执行文件包含main函数的机器码,也包括sqrt函数的机器码(从libm.a库中复制一份)。
为了避免在命令行执行太长的库路径,编译器支持通过-l选项去链接库,和指定完整路径是等效的,比如:
$ gcc -Wall main.c -lm -o main
通常,编译选项-lNAME会尝试去标准库中链接名为libNAME.a的目标文件。也可以使用命令行参数和环境变量指定其它目录,后续会讨论。一个大型的程序通常使用-l选项去链接库。
2.6.1 Link order of libraries
在命令行中,库的顺序和目标文件的顺序是一致的,从左到右搜索。一个库包含函数的定义应该出现在使用它的源文件或目标文件的后面,比如:
$ gcc -Wall main.c -lm -o main
但是,在新版的GCC中,这个可以是无序的。
$ gcc -Wall -lm main.c -o main
2.7 Using library header files
当使用库时,为了去声明函数参数和正确的返回值类型,必须包含适当的头文件。没有函数声明,可能得到错误的类型和结果。
接下来的例子展示了一个程序调用了C数学库中的函数pow,但是程序没有包含math.h头文件,因此函数的原型编译器并不知道。
#include <stdio.h>
int main (void)
{
double x = pow (2.0, 3.0);
printf ("Two cubed is %f\n", x);
return 0;
}
编译会有一个警告,也显示了-Wall参数的重要性:
$ gcc -Wall calc.c -o calc
calc.c: In function ‘main’:
calc.c:5:5: warning: implicit declaration of function ‘pow’ [-Wimplicit-function-declaration]
double x = pow (2.0, 3.0);
^
calc.c:5:16: warning: incompatible implicit declaration of built-in function ‘pow’ [enabled by default]
double x = pow (2.0, 3.0);
3 Compilation options
这个章节描述了一些常用的GCC编译选项。这些选项控制了一些特性,比如本地库和头文件搜索路径、额外的告警和诊断、预处理宏和非标准C。
3.1 Setting search paths
在上一个章节,说明了如何在程序中链接C标准数学库,使用选项-lm和头文件。
当编译使用了库头文件的程序的一个常见的错误:FILE.h: No such file or directory。如果一个头文件不在GCC使用的标准头文件中,就会出现这种情况。
库也会出现一个类似的问题:/usr/bin/ld: cannot find library。如果一个链接的库没有出现在GCC使用的标准库中,就会出现这种情况。
通常,GCC去以下路径中搜索头文件:/usr/local/include/、/usr/include/(32位系统)。
去以下路径中搜索库文件:usr/local/lib/、/usr/lib/(32位系统)
头文件的目录通常被称为include path,库文件路径通常被称为library search path或link path。
当其它库被放在其它目录,为了找到库需要去扩展搜索路径。编译选项-I和-L被用来添加新的目录到include path和library search path。
注意:64位系统/lib64也是默认搜索路径。
3.1.2 Environment variables
头文件和库文件的搜索路径也可以通过shell中的环境变量指定。可以在适当的登录文件(比如.bash_profile)为每个会话自动设置这些参数。
其它的搜索目录可以使用环境变量C_INCLUDE_PATH(对于C头文件) 和CPLUS_INCLUDE_PATH(C++头文件)来添加。指定的目录会在使用-I选项执行的目录之后搜索,在标准默认目录之前搜索。
同样的,使用环境变量LIBRARY_PATH可以指定链接库搜索路径。该目录将在命令行中使用选项-L指定的目录之后搜索,在标准目录之前搜索。
3.1.3 Extended search paths
按照UNIX搜索路径约定,几个目录可以在一个环境变量中以冒号分隔列表形式一起指定。
DIR1:DIR2:DIR3:...
这些目录被有序的从左到右搜索,一个单独的.可以指定当前目录。
比如,下面的例子指定搜索路径和链接路径包含当前路径和其它路径:
$ C_INCLUDE_PATH=.:/opt/gdbm-1.8.3/include:/net/include
$ LIBRARY_PATH=.:/opt/gdbm-1.8.3/lib:/net/lib
在命令行中指定多个搜索路径和链接路径的方式如下:
$ gcc -I. -I/opt/gdbm-1.8.3/include -I/net/include -L. -L/opt/gdbm-1.8.3/lib -L/net/lib .....
当环境变量和命令行中的选项一起使用的时候,编译器会按照以下顺序搜索路径:
1、命令行选项-I和-L,从左到右搜索;
2、环境变量C_INCLUDE_PATH和LIBRARY_PATH指定的路径;
3、默认的系统目录。
在日常使用中,通常使用命令行参数的方式来指定路径。
3.2 Shared libraries and static libraries
尽管程序可以被成功的编译和链接,但在能加载和运行之前还需要最后一步,可能会缺少执行的库文件。
外部库通常有两种呈现方式:静态库和动态库。静态库以.a方式呈现。当一个程序使用静态库进行链接时,使用到外部库函数会被程序拷贝一份到可执行文件中。
共享库使用更高级的方式来处理,它使得可执行文件更小。通过使用.so文件表示共享库。
链接到共享库的可执行文件只包含它需要的函数的一个小表,而不是完全的从外部函数的目标文件。在可执行文件运行之前,外部函数的机器码通过操作系统被从磁盘中存放的共享库中拷贝到内存,这一过程称为动态链接。
动态链接使得可执行文件更小并且节省磁盘空间,因为动态库的一次拷贝可以被多个程序使用。大部分操作系统提供了虚拟内存机制,这允许一次物理内存的共享库拷贝可以被所有运行中的程序使用,既节省内存也节省磁盘空间。
此外,共享库使更新库而不需要更新使用它的程序成为可能。
由于这些优势,在大部分系统中,gcc默认使用动态库编译程序。
当使用链接选项-LNAME链接静态库libNAME.a时,编译器首先检测同名的动态库libNAME.so。
但是,当可执行文件启动时,它的加载器必选先找到共享库,以便将其加载到内存中。默认情况下,加载器只能在预定义的系统目录中搜索共享库,比如/usr/local/lib和/usr/lib。如果库没有在系统目录,则需要添加到加载路径下。
最简单的方式是通过环境变量LD_LIBRARY_PATH设置加载路径。比如下面的例子:
$ LD_LIBRARY_PATH=/opt/gdbm-1.8.3/lib
$ export LD_LIBRARY_PATH
为了方便,环境变量LD_LIBRARY_PATH的值可以在适当的登录文件(比如.bash_profile)为每个会话自动设置这些参数。
可以将多个共享库目录放在加载路径,比冒号分隔的列表方式:DIR1:DIR2:DIR3:...:DIRN,比如:
$ LD_LIBRARY_PATH=/opt/gdbm-1.8.3/lib:/opt/gtk-1.4/lib
$ export LD_LIBRARY_PATH
如果加载路径环境变量已经有值,可以使用下面的语法进行扩展:LD_LIBRARY_PATH=NEWDIRS:$LD_LIBRARY_PATH,比如:
$ LD_LIBRARY_PATH=/opt/gsl-1.5/lib:$LD_LIBRARY_PATH
$ echo $LD_LIBRARY_PATH
/opt/gsl-1.5/lib:/opt/
gcc可以使用-staic选项强制使用静态链接,以避免使用共享库。
如前所述,也可以在命令行中指定完整路径来链接到各个库文件,比如下面的命令直接链接静态库:
$ gcc -Wall -I/opt/gdbm-1.8.3/include dbmain.c /opt/gdbm-1.8.3/lib/libgdbm.a
下面的命令链接动态库,但是仍然需要在运行可执行文件时设置库加载路径:
$ gcc -Wall -I/opt/gdbm-1.8.3/include dbmain.c /opt/gdbm-1.8.3/lib/libgdbm.so
3.3 C language standards
通常,GCC编译工具使用GNU C语言,也称为GNU C。GNU C结合了C语言官方标准ANSI/ISO和一些有用的扩展,比如嵌套函数和可变大小数组。大部分ANSI/ISO程序可以无需更改就可以在GNU C下编译。
有几个编译选项可以控制GNU C的使用,最常使用的是-ansi和-pedantic。还可以使用-std选项选择每种标准C语言的特定方言。
3.3.1 ANSI/ISO
偶尔一个合法的ANSI/ISO程序可能不兼容GNU C。为了解决这个问题,编译器选项-ansi禁用那些与ANSI/ISO标准冲突的GNU扩展。在使用GNU C库(glibc)的系统上,它还禁止对C标准库的扩展。这使得为ANSI/ISO C编写的程序在编译时,不会受到GNU扩展的影响。
下面的例子中,使用asm变量在ANSI/ISO C标准是合法的:
#include <stdio.h>
int main (void)
{
const char asm[] = "6502";
printf ("the string asm is ’%s’\n", asm);
return 0;
}
但是,由于asm是GNU C的一个关键字,在GNU C下变量asm是不合法的,会提示下面的错误:
$ gcc -Wall ansi.c -o ansi
ansi.c: In function ‘main’:
ansi.c:5:16: error: expected identifier or ‘(’ before ‘asm’
const char asm[] = "6502";
^
ansi.c:6:45: error: expected expression before ‘asm’
printf ("the string asm is ’%s’\n", asm);
使用-ansi选项禁止asm关键字的扩展,可以正确的编译:
$ gcc -Wall -ansi ansi.c -o ansi
$ ./ansi
the string asm is ’6502’
作为参考,由GNU C扩展用于的非标准C关键字和宏有:asm、inline、typeof、unix和vax。
下面的例子显示了-ansi选项在使用GNU C库的系统上的效果,下面的程序从math.h中预处理的宏定义M_PI打印pi的值:
#include <math.h>
#include <stdio.h>
int main (void)
{
printf("the value of pi is %f\n", M_PI);
return 0;
}
常量M_PI不是ANSI/ISO标准C的一部分,程序使用-ansi选项编译会报错:
$ gcc -Wall pi.c -ansi -o pi
pi.c: In function ‘main’:
pi.c:6:39: error: ‘M_PI’ undeclared (first use in this function)
printf("the value of pi is %f\n", M_PI);
^
pi.c:6:39: note: each undeclared identifier is reported only once for each function it appears in
不使用-ansi选项,程序可以编译成功:
$ gcc -Wall pi.c -o pi
$ ./pi
the value of pi is 3.141593
通过只使用GNU C库本身的扩展,也可以使用ANSI/ISO编译选项。这可以通过定义特殊的宏来实现,比如_GNU_SOURCE,它支持GNU C库的扩展。
$ gcc -Wall pi.c -ansi -D_GNU_SOURCE -o pi
$ ./pi
the value of pi is 3.141593
GNU C库提供了很多这样的宏(称为feature test macros)。
3.3.2 Strict ANSI/ISO
命令行参数-pedantic和-ansis的组合可以让GCC禁止所有GNU C扩展,而不仅仅是那些与ANSI/ISO标准不兼容的扩展。这有助于编写符合ANSI/ISO标准的可移植程序。
下面的例子中使用了GNU C扩展的可变大小数组:
int main (int argc, char *argv[])
{
int i, n = argc;
double x[n];
for (i = 0; i < n; i++)
x[i] = i;
return 0;
}
使用-ansi选项编译,对可变长数组的支持不会有问题,因为向后兼容,
$ gcc -Wall -ansi gnuarray.c
但是,使用-ansi -pedantic选项就会报一个警告:
$ gcc -Wall -ansi -pedantic gnuarray.c
gnuarray.c: In function ‘main’:
gnuarray.c:4:5: warning: ISO C90 forbids variable length array ‘x’ [-Wvla]
double x[n];
注意,没有-ansi -pedantic选项的警告不能保证程序严格符合ANSI/ISO标准,标准本身只指定了生成诊断的一些有限的情况。
3.3.3 Selecting specific standards
-std选项可以指定标准的版本,以下C语言标准可以支持:
-std=c89或者-std=iso9899:1990
-std=iso9899:199409
-std=c99或者-std=iso9899:1999
GNU C语言标准可以通过这些选项指定:-std=gnu89和-std=gnu99
3.4 Warning options in -Wall
在之前的章节,警告选项-Wall可以对许多常见的错误发出警告,应该始终使用。它包含了大量的其它更具体的告警选项,这些选项也可以单独选择,下面是一些常见的选项:
-Wcomment(include in '-Wall'):这个对嵌套注释进行警告。嵌套注释通常出现在包含注释的代码段被注释的情况。
/* commented out
double x = 1.23; /* x-position */
*/
嵌套注释可能引起混淆,注释掉一段包含注释的代码更安全的方法是用预处理指定#if 0 ... #endif。
/* commented out */
#if 0
double x = 1.23; /* x-position */
#endif
-Wformat(include in '-Wall'):这个选项对在函数(比如printf和scanf函数)中不正确的使用格式化字符串进行警告,格式说明符和对应函数实际参数类型不一致。
-Wunused(include in '-Wall'):对未使用变量进行警告,当一个变量定义但未使用时,这可能是另一个变量意外的替换了它的位置。如果真的不需要这个变量,可以将它从源码中移除。
-Wimplicit(include in '-Wall'):此选项警告任何未声明就使用的函数,最常见的原因是忘记包含头文件。
-Wreturn-type(include in '-Wall'):此选项警告定义时没有返回类型,但未声明为void函数。它还捕获未声明未void函数中的空返回语句,比如下面的函数没有使用一个显示的返回值:
#include <stdio.h>
int main (void)
{
printf ("hello world\n");
return;
}
-Wall选项包含的所有警告项可以在GCC参考手册中查看。
-Wall包含的选项有一个共同点,即它们报告的内容总是错误的,或者可以很容易以正确的方式进行重写。这就是为什么它们如此有用,任何由-Wall产生的警告都可以视为指示了一种潜在的严重问题。
3.5 Additional warning options
GCC提供了许多没有包含在-Wall的其它警告选项,但也经常使用。通常这些编译项会对源码产生警告,这些在技术上可能有效,但也可能导致问题。这些选项的标准基于常见的错误经验--它们不包括在-Wall中,因为它们指示可能有问题或本来是正确的代码。
由于这些警告可能导致问题,因此没有必要一直使用它们进行编译。更适合的方法是定期使用它们并检查结果,检查是否有任何意外,或者仅某些程序或文件启用它们。
-W:和-Wall选项类似,警告一些常见的编程错误,比如带返回值的函数没有返回值,以及有符号值和无符号值之间的比较。比如,接下来的例子测试是否一个无符号整型是负数:
int foo (unsigned int x)
{
if (x < 0)
return 0;
/* cannot occur */
else
return 1;
}
使用-Wall进行编译不会产生一个警告:
$ gcc -Wall -c w.c
但使用-W会产生一个警告:
$ gcc -W -c w.c
w.c: In function ‘foo’:
w.c:3:5: warning: comparison of unsigned expression < 0 is always false [-Wtype-limits]
if (x < 0)
实际上,-W和-Wall通常一起使用。
-Wconversion:此选项警告可能导致意外结果的隐式类型转换。比如,给无符号变量赋负值,比如:
unsigned int x = -1;
ANSI/ISO C标准在技术上是允许的(根据机器表示法,将负整数转换为一个正整数),不能简单的当作一个编码错误。如果需要执行这样的转换,可以使用显示的强制转换,比如(unsigned int)(-1),来避免此选项的任何警告。
-Wshadow:此选项警告在已经声明过的变量的作用域中重新声明变量名。这种称为variable shadowing,并且可能导致使用哪个变量产生混淆。下面的例子声明了一个局部变量y,并且在函数内部声明了一个影子变量。
double test (double x)
{
double y = 1.0;
{
double y;
y = x;
}
return y;
}
在ANSI/ISO C标准中,这是合法的,返回值是1。当检查到行y=x时,变量y的影子变量可能使它看起来正确(不正确的)返回值为x。
影子变量也可以作为函数名出现,比如下面的程序尝试定义一个变量sin(sin也是一个标准函数):
double sin_series (double x)
{
/* series expansion for small x */
double sin = x * (1.0 - x * x / 6.0);
return sin;
}
这种错误可以通过-Wshadow选项检测到,sin示例在gcc 4.8.5版本中没检测到,不知是否版本有差异。
$ gcc -Wshadow -c shadowing.c
shadowing.c: In function ‘test’:
shadowing.c:5:10: warning: declaration of ‘y’ shadows a previous local [-Wshadow]
double y;
^
shadowing.c:3:9: warning: shadowed declaration is here [-Wshadow]
double y = 1.0;
-Wcast-qual:此选项警告为移除类型限定符(如const)而强制转换的指针。比如下面的函数,将输入的const参数,允许被重写:
void f (const char * str)
{
char * s = (char *)str;
s[0] = '\0';
}
对原始输入字符串str的修改违反了其const属性,此选项警告为了允许变量被修改而对变量str进行不正确的转换。
$ gcc -Wall -Wcast-qual -c cast_qual.c
cast_qual.c: In function ‘f’:
cast_qual.c:3:16: warning: cast discards ‘__attribute__((const))’ qualifier from pointer target type [-Wcast-qual]
char * s = (char *)str;
-
-Wwrite-strings:此选项隐式地给程序中所有字符串常量一个const属性,如果试图复写它们,将会产生编译警告。ANSI/ISO标准时不允许修改字符串常量,同时GCC中也不赞同对字符串常量就行改写, -
-Wtraditional:此选项警告ANSI/ISO编译器和传统的pre-ANSI编译器对代码编译不同。
上述选项都是产生诊断告警信息,但允许继续编译并生成目标文件或可执行文件。对于大型程序而言,在生成警告时,可以通过停止编译来捕获所有的警告。选项-Werror通过将警告转换为错误的方式来更改默认行为,并在出现警告时停止编译。
4 Using the preprocessor
这个章节描述使用GCC预处理器cpp,这是GCC工具包的一部分。预处理器在执行编译前扩展源文件中的宏。GCC编译C/C++源文件时,会自动调用。
4.1 Defining macros
下面的程序描述了C预处理最常见的用法,它使用预处理选项#ifdef去检查宏TEST是否被包含。
当宏定义时,预处理器包含相应的代码,直到#endif结束。
#include <stdio.h>
int main (void)
{
#ifdef TEST
printf ("Test mode\n");
#endif
printf ("Running...\n");
return 0;
}
GCC选项-DNAME在命令行中定义一个预处理器宏NAME。如果命令行增加-DTEST选项,则会定义一个宏TEST。
$ gcc -Wall dtest.c -o dtest
$ ./dtest
Running...
$ gcc -Wall -DTEST dtest.c -o dtest
$ ./dtest
Test mode
Running...
宏通常没有定义,除非在命令行中使用-D选项指定,或者在源文件或头文件或库文件使用#define定义。一些宏是编译器自动定义的,这些宏通常使用双下划线前缀__的命名方式。
完整的预处理宏集合可以通过在空文件上运行GNU预处理器cpp和选项-dM来查看:
$ cpp -dM /dev/null
#define __DBL_MIN_EXP__ (-1021)
#define __UINT_LEAST16_MAX__ 65535
#define __ATOMIC_ACQUIRE 2
... ...
#define __ORDER_BIG_ENDIAN__ 4321
注意,这些宏包含GCC定义的少量系统特征宏,这些宏不使用双下划线前缀。这些非标准宏可以通过GCC的-ansi选项禁用。
4.2 Macros with values
宏除了定义,还应该赋予一个具体的值。这个值会在每次宏出现的地方插入到源代码中。下面的程序定义了一个宏NUM,并打印它的值:
#include <stdio.h>
int main (void)
{
printf("Value of NUM is %d\n", NUM);
return 0;
}
注:宏不会在字符串内部展开,只有在字符串外部出现宏时才会被预处理器替换。
在命令行中定义宏的同时赋值的方式为:-DNAME=VALUE。比如下面的命令定义NUM的值为100:
$ gcc -Wall -DNUM=100 dtestval.c
$ ./a.out
Value of NUM is 100
不赋值,默认为1:
$ gcc -Wall -DNUM dtestval.c
$ ./a.out
Value of NUM is 1
另外,宏的值也可以是任何表达式(最好使用括号括起来),无论它的值是什么,都是直接在源码中进行替换。
$ gcc -Wall -DNUM='2+2' dtestval.c
$ ./a.out
Value of NUM is 4
注意:宏可以在命令行中定义为空值-DNAME="",这样的宏仍然视为definded,比如#ifdef,但扩展为空。
$ gcc -Wall -DTEST=”“ dtest.c -o dtest
$ ./dtest
Test mode
Running...
$ gcc -Wall -DNUM="" dtestval.c
dtestval.c: In function ‘main’:
dtestval.c:5:39: error: expected expression before ‘)’ token
printf("Value of NUM is %d\n", NUM);
可以使用Shell命令的转义字符双引号来定义包含引号的宏。比如:
-DMESSAGE="\"hello, world!\""
定义宏DMESSAGE的值为一个字符串"hello, world!"。
4.3 Preprocessing source files
可以使用-E选项来查看预处理器对源文件的直接效果。比如定义源文件内容为:
#define TEST "Hello, World!"
const char str[] = TEST;
$ gcc -E test.c
# 1 "test.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "test.c"
const char str[] = "Hello, World!";
-E选项使GCC运行预处理器,打印扩展的输出,然后退出,不会继续编译源文件。
预处理器也会以#line-number "source-file"的形式插入记录源文件和行号,以帮助调试,并允许编译器根据这些信息发出错误信息。
查看预处理源文件对于检查系统头文件和查看系统函数声明很有用。下面的例子包含头文件stdio.h,该文件中声明了printf函数。
#include <stdio.h>
int main (void)
{
printf ("Hello, world!\n");
return 0;
}
通过-E参数查看包含头文件内容:
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
... ...
typedef unsigned char __u_char;
typedef unsigned short int __u_short;
... ...
# 391 "/usr/include/libio.h" 3 4
extern int __underflow (_IO_FILE *);
extern int __uflow (_IO_FILE *);
... ...
# 2 "hello.c" 2
int main (void)
{
printf ("Hello, world!\n");
return 0;
}
预处理头文件通常包含大量的输出,可以重定向输出到一个文件,或者使用-save-temps选项。
$ gcc -c -save-temps hello.c
运行之后,会自动将预处理输出信息保存到hello.i文件中,同时也会保存名为hello.s的汇编文件和hello.o目标文件。
5 Compiling for debugging
通常,一个可执行文件不包含任何对源程序代码的引用,比如变量名、行号。可执行程序仅是一个简单的由编译器产生的机器码指令序列。这对于调试是不够的,如果程序崩溃,不容易找到错误原因。
GCC提供-g调试选项,用于在目标文件和可执行文件中存储一些额外的调试信息。调试信息允许将错误从特定的机器指令追溯源文件的相应行。也允许在调试器中跟踪程序的运行,比如GNU Debugger gdb。使用调试器允许在程序运行时检查变量的值。调试选项的工作原理是将函数和变量名(以及对它们的所有引用)及其对应的源代码行号存储到目标文件和可执行文件的符号表中。
5.1 Examining core files
除了允许在调试器中运行程序外,-g选项的另一个有用的应用是查看程序崩溃的情况。
当一个程序异常退出时,操作系统会输出一个core文件,通常命名为'core',它包含程序崩溃时内存中的状态信息。结合-g选项产生的符号表信息,core文件可以用来找到程序停止的行号,以及当时的变量的值。
这两点在开发软件的期间很有用,允许通过程序奔溃现场来对问题进行排查。
下面是一个例子,包含了非法内存访问导致程序崩溃:
int a (int *p);
int main (void)
{
int *p = 0;
/* null pointer */
return a (p);
}
int a (int *p)
{
int y = *p;
return y;
}
使用-g选项进行编译:
$ gcc -Wall -g null.c -o null
$ ./null
Segmentation fault (core dumped)
每当出现core dump时,操作系统应该在当前目录下生成一个名为core的文件。该文件包含程序在终止时使用的内存页的完整拷贝。segment fault通常指的是程序试图访问已分配内存区域外的受限内存。
由于core文件可能很大和填满磁盘空间,一些系统默认没有配置输出core文件。在GNU Bash Shell中可以使用命令行ulimit -c查看core files最大值。如果是0,则没有core文件产生。
$ ulimit -c
0
如果core files值为0,可以通过命令更改可写入任意文件,仅对当前shell有效:
$ ulimit -c unlimited
$ ulimit -c
unlimited
core文件也可以通过gdb进行加载,使用方式:gdb EXECUTABLE-FILE CORE-FILE
$ gdb a.out core
Core was generated by ‘./a.out’.
Program terminated with signal 11, Segmentation fault.
Reading symbols from /lib/libc.so.6...done.
Loaded symbols for /lib/libc.so.6
Reading symbols from /lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
#0
0x080483ed in a (p=0x0) at null.c:13
13
int y = *p;
(gdb)
调试器立即开始打印诊断信息,并显示程序奔溃行。
5.2 Displaying a backtrace
调试器可以显示程序当前执行点的函数调用关系和参数值,这称为stack backtrace,通过命令backtrace查看。
(gdb) backtrace
#0 0x0000000000400517 in a (p=0x0) at null.c:12
#1 0x0000000000400509 in main () at null.c:7
6 Compiling with optimization
GCC是一个可优化的编译器,它提供了许多选项来提高产生可执行文件的速度、减小可执行文件的内存。
优化是一个复杂的过程。在源文件中的每一个高级命令,通常都可能有很多种机器指令组合,可以用来实现最终的功能。编译器必须考虑这些可能性并选择它们。
通常,必须为不同的处理器生成不同的代码,因为它们使用不兼容的汇编和机器语言。在每种情况下都必须生成合适的机器码。
此外,不同指令需要不同的时间,取决于指令的顺序。GCC考虑了所有这些因素,并且在编译优化时试图为指定的系统生成更快的可执行文件。
6.1 Source-level optimization
GCC使用的第一种优化形式是源码级的,不需要任何机器指令的知识。有许多源码级优化技术,比如common subexpression elimination和function inlining。
6.1.1 Comment subexpression elimination
源码级优化一种比较容易理解的方法是,通过重用已经计算好的结果,用更好的指令在源码中计算表达式。比如:
x = cos(v)*(1+sin(u/2)) + sin(w)*(1-sin(u/2))
可以优化为:
t = sin(u/2)
x = cos(v)*(1+t) + sin(w)*(1-t)
这种方法叫做Comment subexpression elimination (CSE)技术,并且在打开优化时自动执行,这种技术功能强大,因为它同时提高了速度并且减小了代码的大小。
6.1.2 Function inlining
另一种源码级优化叫做function inlining,可以提供频繁调用函数的效率。
无论何时执行函数,CPU都需要一定的额外时间来执行调用:它必须将函数参数存储在适当的寄存器和内存位置,跳转到函数的开头(将适当的虚拟内存页放入物理内存或CPU缓存中),开始执行代码,然后在函数调用完成时返回到原来的执行点。这额外的工作叫做function-call overhead。内联函数通过用函数本身替换函数的调用(称为代码in-line)来消除这种开销。
在大部分情况下,函数调用开销是在程序的总运行时间中是微不足道的一部分。只有当函数包含相对较少的指令和这些函数占运行时的很大一部分时,开销才会变得重要。
如果函数只有一个调用点,那么内联时有利的。如果函数调用相比于内联函数需要更多的内存指令,那内联也更好。此外,内联可以通过将几个分开的单独函数合并为一个更大的函数来促进进一步的优化,比如消除公共子表达式。
下面的例子中函数sq(x)被当作内联更高效:
double sq (double x)
{
return x * x;
}
这个函数代码很少,因此调用函数的开销和执行函数本身的乘法计算相当。如果这个函数在一个循环中使用,那么函数调用开销就会很大:
for (i = 0; i < 1000000; i++)
{
sum += sq (i + 0.5);
}
使用内联优化替换程序的内部循环函数调用,执行效率更高:
for (i = 0; i < 1000000; i++)
{
double t = (i + 0.5);
/* temporary variable */
sum += t * t;
}
Shell下,可以使用time命令查看程序运行时间:
$ time ./hello
Hello, everyone!
real 0m0.017s
user 0m0.001s
sys 0m0.000s
GCC使用许多启发式方法来选择内联函数,比如函数要适当小。作为一种优化方法,内联只在每个目标文件中执行。inline关键字可用于显示地要求在任何可能地情况下将使用它的地方进行函数内联。
6.2 Speed-space tradeoffs
虽然某些形式的优化(比如公共子表达式消除)能够提高速度的同时减小程序的大小,但其他类型的优化以增加可执行文件的大小为代码生成更快的代码。在速度和内存之间的选择称为speed-space tradeoffs。速度和空间之间的优化可以使可执行文件更小,代价是使其运行更慢。
6.2.1 Loop unrolling
speed-space tradeoffs之间进行权衡的优化的一个例子是循环展开。这种形式的优化通过消除"end of loop"条件来提高循环的速度。比如,下面的例子从0到7循环执行,每次都会判断i < 8。
for (i = 0; i < 8; i++) {
y[i] = i;
}
在循环结束时,这个判断执行了9次,并且运行的很大一部分用于检查它。
一个更高效率的方式是简单的展开循环直接赋值:
y[0] = 0;
y[1] = 1;
y[2] = 2;
y[3] = 3;
y[4] = 4;
y[5] = 5;
y[6] = 6;
y[7] = 7;
这种执行方式速度最快。由于每次赋值是独立的,它还允许编译器在支持的处理器上使用并行性。循环展开是一种优化,它可以提高最终可执行文件的速度,但通常会增加其大小(除非循环非常短,比如一两次迭代)。
如果正确的处理了开始和结束条件,在循环的上限未知时也可以展开循环。例如,上限任意的循环:
for (i = 0; i < n; i++)
{
y[i] = i;
}
可以展开循环为:
for (i = 0; i < (n % 2); i++)
{
y[i] = i;
}
for ( ; i + 1 < n; i += 2) /* no initializer */
{
y[i] = i;
y[i+1] = i+1;
}
第一个循环处理当n为奇数时,i=0的情况,第二个循环处理剩下的迭代。第二个循环从第一个循环i的值开始进行,循环中的赋值可以并行化,测试的总次数减少了大约1/2。更高的因子可以通过在循环中展开更多的赋值来实现,代价是代码更大。
6.3 Scheduling
更低层次的优化是scheduling,其中编译器确定指令的最佳顺序。大多数CPU允许一个或多个指令在其它指令完成前开始执行。大部分CPU同时支持流水线,即多个指令在同一个CPU上并行执行。
当启用调度时,必须对指令进行安排,以便它们的结果在正确的时间对后面的指令可用,并允许最大程度的并行执行。调度提供了一个可执行文件的速度,并没有增加它的大小,但是在编译程序时需要额外的内存和时间(由于它的复杂性)。
6.4 Optimization levels
为了控制编译时间和编译内存的使用,以及在生成可执行文件的速度和空间之间进行权衡,GCC提供了一系列通用优化等级,从0到3编号,以及针对特定类型的优化的单独选项。
一个优化等级可以通过命令行参数-OLEVEL选择,LEVEL取值为0到3。不同优化等级的效果如下:
-O0或者没有-O选项(默认):此选项GCC不执行任何优化,而是以最直接的方式编译源码。源码中的每行代码直接转换为可执行文件中的相应指令,而不需要重新排列。调试程序时这是最好的选项。-O0选项等同于不指定-O选项。
-O1或-O:这个级别开启最常见的优化形式,而不需要任何速度和空间的权衡。使用此选项,生成的可执行文件应该比-O0选项产生的文件更小,速度更快。代价更高的优化,比如调度不在此等级使用。使用选项-O1编译通常比使用-O0编译花费更少的时间,因为在简单优化之后减少了数据量。
-O2:此选项除了打开-O1的优化项之后,还有更多的优化,包括指令调度。由于只使用不需要任何速度-空间权衡的优化,生成可执行文件的大小不增加。此选项相比于-O1,编译器需要更多的时间和内存。这个选项通常是部署程序的最佳选择,因为它在不增加可执行文件大小的情况下提供了最大的优化。
-O3:除了-O1和-O2的优化项外,此选项优化的程度更大,比如函数内联。此选项可能提供可执行文件的运行速度,但是也增加了它的大小。在某些情况下,这些优化可能会使程序变慢。
-funroll-loops:此选项打开循环展开,和其它优化项是独立的。它可能增加可执行文件的大小,此选项是否产生有益的结果,必须视具体情况而定。
-Os:这个选项是减少可执行文件大小的优化项。此选项的目的为受内存和磁盘空间大小限制的系统,最大可能的减少生成可执行文件大小。在某些情况下,由于更好的缓存作用,较小的可执行文件运行更快。
6.5 Examples
下面的例子可以证明不同优化等级的效果:
#include <stdio.h>
double powern (double d, unsigned n)
{
double x = 1.0;
unsigned j;
for (j = 1; j <= n; j++)
x *= d;
return x;
}
int main (void)
{
double sum = 0.0;
unsigned i;
for (i = 1; i <= 100000000; i++)
{
sum += powern (i, i % 5);
}
printf ("sum = %g\n", sum);
return 0;
}
程序运行的时间可以使用time命令查看,使用不同等级进行优化:
$ gcc -Wall -O0 test.c -lm
$ time ./a.out
sum = 4e+38
real 0m1.156s
user 0m1.156s
sys 0m0.000s
$ gcc -Wall -O1 test.c -lm
$ time ./a.out
sum = 4e+38
real 0m0.257s
user 0m0.256s
sys 0m0.001s
$ gcc -Wall -O2 test.c -lm
$ time ./a.out
sum = 4e+38
real 0m0.237s
user 0m0.237s
sys 0m0.000s
$ gcc -Wall -O3 test.c -lm
$ time ./a.out
sum = 4e+38
real 0m0.237s
user 0m0.236s
sys 0m0.001s
$ gcc -Wall -O3 -funroll-loops test.c -lm
$ time ./a.out
sum = 4e+38
real 0m0.257s
user 0m0.257s
sys 0m0.000s
输出中用于比较速度的是user时间,它表示了运行实际花费的CPU时间,可以看出使用-O2和-O3等级优化运行时间差不多,-O0等级运行时间最长,-funroll-loops选项的时间大于不加的时间,也说明了优化不一定都能使程序运行更快。
6.6 Optimization and debugging
在GCC中,可以将优化和debug选项-g结合使用,其它的编译器可能不允许这样。
当一起使用优化和debug时,编译器通过优化执行的内部重排可能导致调试器很难指导当前正在执行什么。比如,临时变量经常被消除,语句的顺序可能改变。
但是,当一个程序异常崩溃,有调试信息总比没有好,因此调试程序建议使用-g选项。默认的GNU发行版本,-g选项和-O2优化等级一起使能。
6.7 Optimization and compiler warnings
相比与不打开优化,当优化打开的时候,GCC可能会产生额外的告警。
作为优化过程的一部分,编译器检查所有变量及其初始化值的使用,这称为data-flow analysis。它是其它优化策略的基础,比如指令调度。data-flow analysis的一个副作用是编译器可以检测到未初始化变量的使用。
-Wuninitialized选项(-Wall中默认包含)警告关于未初始化变量就进行使用。此选项仅在程序使用优化等级去进行数据流分析的时候工作。下面的例子可以进行说明:
int sign (int x)
{
int s;
if (x > 0)
s = 1;
else if (x < 0)
s = -1;
return s;
}
这个函数在大部分情况下正确,但是当x=0时,存在一个bug(返回一个未初始化值)。
使用-Wall选项进行编译,编译不会告警,因为没有使用优化选项进行数据流分析:
$ gcc -Wall -c uinit.c
使用-Wall和-O2选项进行编译,会产生一个警告:
$ gcc -Wall -O2 -c uinit.c
uinit.c: In function ‘sign’:
uinit.c:8:5: warning: ‘s’ may be used uninitialized in this function [-Wmaybe-uninitialized]
return s;
注意,虽然GCC通常会找到未初始化变量,但它偶尔会漏掉一些复杂的情况或者产生错误的告警。对于后一种情况,通常可以用一种更简单的方式重写相关源代码,删除警告并提高程序的可读性。
9 Troubleshooting
GCC提供了一些帮助和诊断选项,以帮助排除编译过程中的问题。
9.1 Help for command-line options
GCC提供了顶层的GCC帮助命令,用于获取各种命令行的简要提示信息:
$ gcc --help
查看GCC相关的程序(比如链接器、汇编器)的完整选项列表,使用-v选项结合--help选项。
$ gcc -v --help
这个命令了生成的完整选项列表很长,可以重定向到一个输出文件中,再结合more命令查看:
$ gcc -v --help | more
9.2 Version numbers
可以使用下面的命令查看gcc版本号:
$ gcc --version
gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
在检查编译问题时,编译版本很重要,旧的版本可能缺少一些特性。
版本号的格式为:major-version.minor-version或者major-version.minor-version.micro-version,其中micro-version用于发布系列中的后续错误修复版本。
9.3 Verbose compilation
-v选项可以使用来显示用于编译和链接程序的命令的确切序列的详细信息。下面是一个示例:
$ gcc -v -Wall hello.c
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
... ..
当编译程序本身出现问题时,-v产生的输出很有用,它显示了查找头文件和库的完整目录路径,预处理器产生的预定义符号,以及用于链接的目标文件和库。
10 Compiler-related tools
本章节描述一些与GCC结合使用的工具。包括包括创建库的GNU ar工具、GNU概要分析和覆盖测试程序gprof和gcov。
10. 1 Creating a library with the gnu archiver
GNU ar工具将一系列目标文件合并为一个库。一个库只是将大量相关的目标文件放在一起的方便方法。
下面演示创建一个libhello.a库,其包含两个函数hello和bye:
hello_fn.c包含hello函数的源代码:
#include <stdio.h>
#include "hello.h"
void hello (const char * name)
{
printf ("Hello, %s!\n", name);
}
bye_fn.c包含bye函数:
#include <stdio.h>
#include "hello.h"
void bye (void)
{
printf ("Goodbye!\n");
}
头文件hello.h中包含两个函数的声明:
void hello (const char * name);
void bye (void);
编译两个源文件生成目标文件:
$ gcc -Wall -c hello_fn.c
$ gcc -Wall -c bye_fn.c
生成静态库:
$ ar cr libhello.a hello_fn.o bye_fn.o
选项cr表示'create and replace',如果库不存在,就会创建;如果库已经存在,其中任何具有相同名称的源文件都被命令行中指定的新文件替换。
ar工具同时提供了选项t(table of contents),用于列出库中的目标文件:
$ ar t libhello.a
hello_fn.o
bye_fn.o
当一个库被使用时,应该同时提供公共函数和变量的头文件,这样用户才能获取到正确的函数原型。下面举例进行说明。
#include "hello.h"
int main (void)
{
hello ("everyone");
bye ();
return 0;
}
假设libhello.a已经在源文件的当前路径下,下面进行编译:
$ gcc -Wall main.c libhello.a -o hello
$ ./hello
Hello, everyone!
Goodbye!
快捷的库链接选项-l可以用来链接程序,而不需要显示的指定库的完整文件命名:
$ gcc -Wall -L. main.c -lhello -o hello
选项-L需要添加当前目录到库的搜索路径。
10.2 Using the profiler gprof
GNU分析工具gprof可以有用的测量程序的性能,它记录了调用每个函数的次数以及在每个函数上花费的时间。从gprof的输出可以容易的看出占用大量运行时间的函数。提高程序运行速度应该首先集中在那些占据费时的函数上。
我们将使用gprof来检查一个小型数值程序的性能,该程序包含的序列定义如下:
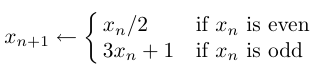
这个序列从一个初始值x0开始进行迭代,直到得到数值1。下面是对应的程序:
#include <stdio.h>
/* Computes the length of Collatz sequences */
unsigned int step(unsigned int x)
{
if (x % 2 == 0) {
return (x / 2);
} else {
return (3 * x + 1);
}
}
unsigned int nseq(unsigned int x0)
{
unsigned int i = 1, x;
if (x0 == 1 || x0 == 0)
return i;
x = step(x0);
while (x != 1 && x != 0) {
x = step(x);
i++;
}
return i;
}
int main(void)
{
unsigned int i, m = 0, im = 0;
for (i = 1; i < 500000; i++) {
unsigned int k = nseq(i);
if (k > m) {
m = k;
im = i;
printf("sequence length = %u for %u\n", m, im);
}
}
return 0;
}
要使用分析工具,编译和链接时必须使用-pg选项:
$ gcc -Wall -c -pg collatz.c
$ gcc -Wall -pg collatz.o
它会创建一个包含额外指令的可执行文件,这些指令记录了每个函数上花费的时间。
如果程序包含多个源文件,则在编译每个源文件时都要使用-pg选项,在链接目标文件生成最终可执行文件时也要使用-pg选项。
必须运行可执行文件来创建分析数据:
$ ./a.out
在运行可执行文件时,分析数据同时被写入当前目录下的gmon.out文件。可以用使用gprof工具带可执行文件名的方式来分析:
$ gprof a.out
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls ns/call ns/call name
68.09 0.33 0.33 62135400 5.37 5.37 step
26.82 0.47 0.13 499999 262.86 930.11 nseq
6.19 0.50 0.03 frame_dummy
可以看出,step函数花费了68.09%的时间,nseq函数花费了26.82%的时间。其它列包含了函数调用总次数,以及每个函数上花费的时间。
10.3 Coverage testing with gcov
GNU覆盖性测试工具gcov分析程序在运行期间每一行执行的次数。这可以用来分析程序中没有执行的区域。当与gprof工具一起结合分析时,gcov工具可以加快分析的速度,将其集中在程序源代码的特定行上。
下面演示gcov的使用:
#include <stdio.h>
int main (void)
{
int i;
for (i = 1; i < 10; i++)
{
if (i % 3 == 0)
printf ("%d is divisible by 3\n", i);
if (i % 11 == 0)
printf ("%d is divisible by 11\n", i);
}
return 0;
}
使用覆盖性测试工具,需要使用下面的编译选项:
$ gcc -Wall -fprofile-arcs -ftest-coverage cov.c
这创建了一个包含额外指令的可执行文件,这些指令记录程序每一行执行的次数。选项-ftest-coverage添加了计算每一行执行次数的指令,选项-fprofile-arcs包含了程序每个分支的插装代码。插装代码记录通过if语句和其它条件执行不同路径的频率。
必须运行可执行程序创建覆盖性分析数据:
$ ./a.out
3 is divisible by 3
6 is divisible by 3
9 is divisible by 3
运行时产生的数据被写入到当前目录下的几个扩展文件中.gcda、.gcno。这些数据可以通过使用gcov命令带源文件作为参数进行分析:
$ gcov cov.c
File 'cov.c'
Lines executed:85.71% of 7
Creating 'cov.c.gcov'
gcov命令生成了带注释版本的源文件,扩展名为cov.c.gcov,包含每一行执行的次数:
-: 0:Source:cov.c
-: 0:Graph:cov.gcno
-: 0:Data:cov.gcda
-: 0:Runs:1
-: 0:Programs:1
-: 1:#include <stdio.h>
-: 2:
1: 3:int main (void)
-: 4:{
-: 5: int i;
10: 6: for (i = 1; i < 10; i++)
-: 7: {
9: 8: if (i % 3 == 0)
3: 9: printf ("%d is divisible by 3\n", i);
9: 10: if (i % 11 == 0)
#####: 11: printf ("%d is divisible by 11\n", i);
-: 12: }
1: 13: return 0;
-: 14:}
输出文件的第二列为行号,未执行的行号使用'#####:'标记。
11 How the compiler works
本章节描述了GCC编译源文件到可执行文件的细节。编译是一个涉及多个工具的多阶段过程,包括GNU 编译器(gcc或g++)、GNU 汇编器ar、GNU链接器ld。这些工具集合叫做工具链。
11.1 An overview of the compilation process
GCC一次调用所执行的命令序列由以下阶段组成:
- 预处理(扩展宏)
- 编译(源代码编译为汇编语言)
- 汇编(汇编语言转换为机器码)
- 链接(创建最终的可执行文件)
下面通过hello.c来独立展示这几个步骤:
#include <stdio.h>
int main (void)
{
printf ("Hello, world!\n");
return 0;
}
GCC内部会自动地执行这几个工具,但为了展示编译是如何工作,我们独立地进行这几个步骤。
11.2 The preprocessor
编译程序的第一步是使用预处理器扩展宏和头文件,可以使用下面的命令:
$ cpp hello.c > hello.i
结果输出在hello.i文件,这个文件包含了源代码和扩展宏,通常C程序使用'.i'后缀,C++程序使用'.ii'后缀。通常,预处理产生的文件不会存放,除非使用-save-temps选项。
11.3 The compiler
下一步是针对特定处理器,编译源文件预处理产生的文件,生成汇编语言代码。GCC命令选项-S表示编译C源代码生成汇编代码,结果存放在'.s'后缀文件中:
$ gcc -Wall -S hello.i
$ cat hello.s
.file "hello.c"
.section .rodata
.LC0:
.string "Hello, world!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
.section .note.GNU-stack,"",@progbits
11.4 The assembler
汇编器的目的是将汇编代码转换为机器码,产生一个目标文件。当在汇编源程序中调用外部函数,汇编程序不定义外部函数的地址,由后面的链接器填充。
汇编使用下面的命令:
$ as hello.s -o hello.o
-o选项指定输出文件名,输出文件包含了程序的机器指令和printf函数的未定义引用。
11.5 The linking
最后一步是链接目标文件生成可执行文件。通常,可执行文件需要很多系统库和C运行库中的外部函数。因此,GCC内部使用的实际链接命令非常复杂,比如,链接的完整命令:
$ ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crt1.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crti.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtbegin.o -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5 -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64 -L/lib/../lib64 -L/usr/lib/../lib64 -L/usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../.. hello.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/x86_64-redhat-linux/4.8.5/crtend.o /usr/lib/gcc/x86_64-redhat-linux/4.8.5/../../../../lib64/crtn.o
幸运的是不需要直接输入上面的命令,当调用时,gcc会透明地处理整个链接过程。
$ gcc hello.o
$ ./a.out
Hello, world!
12 Examining compiled files
本章节提供几个检查可执行文件和目标文件地几个有用工具。
12.1 Identifying files
当源文件编译为目标文件或可执行文件时,用于编译它地选项不再明显。file命令可以查看目标文件或可执行文件内容,并确定它的一些特征,比如它是动态链接还是静态链接。
$ file a.out
a.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, not stripped
输出显示可执行文件是动态链接,使用x86-64编译处理器,一个完整的输出信息解释为:
- ELF:可执行文件的内部格式(ELF代表'Executable and Linking Format')
- 64-bit:The word size
- LSB:Compiled for a platform with
least significant bytefirst word-ordering, - x86-64:编译可执行文件的处理器
- version 1 (SYSV):文件的内部格式版本
- dynamically linked:可执行文件使用共享库(statically linked表示使用静态库)
- not stripped:可执行文件包含符号表
12.2 Examining the symbol table
可执行文件和目标文件包含符号表,符号表按名称存放了函数和变量的位置,可以通过nm命令查看:
$ nm a.out
0000000000601034 B __bss_start
0000000000601034 b completed.6355
0000000000601030 D __data_start
0000000000601030 W data_start
0000000000400470 t deregister_tm_clones
00000000004004e0 t __do_global_dtors_aux
0000000000600e18 t __do_global_dtors_aux_fini_array_entry
00000000004005d8 R __dso_handle
0000000000600e28 d _DYNAMIC
0000000000601034 D _edata
0000000000601038 B _end
00000000004005c4 T _fini
0000000000400500 t frame_dummy
0000000000600e10 t __frame_dummy_init_array_entry
0000000000400718 r __FRAME_END__
0000000000601000 d _GLOBAL_OFFSET_TABLE_
w __gmon_start__
00000000004005f0 r __GNU_EH_FRAME_HDR
00000000004003e0 T _init
0000000000600e18 t __init_array_end
0000000000600e10 t __init_array_start
00000000004005d0 R _IO_stdin_used
0000000000600e20 d __JCR_END__
0000000000600e20 d __JCR_LIST__
00000000004005c0 T __libc_csu_fini
0000000000400550 T __libc_csu_init
U __libc_start_main@@GLIBC_2.2.5
000000000040052d T main
U puts@@GLIBC_2.2.5
00000000004004a0 t register_tm_clones
0000000000400440 T _start
0000000000601038 D __TMC_END__
大部分符号是编译器和操作系统内部使用,第二列中的'T'表示在目标文件中定义的函数,'U'表示一个未定义的函数(应该是链接到另一个目标文件来解析)。
nm的通常用法是检查库中是否特定函数的定义,在第二列中查找-T项。
12.3 Finding dynamically linked libraries
当使用共享库编译程序时,它需要在运行时动态加载这些库,一般调用外部函数。命令ldd检查可执行文件所需要的共享库列表。这些库称为可执行文件的共享库依赖。
$ ldd a.out
linux-vdso.so.1 => (0x00007ffebafe3000)
libc.so.6 => /lib64/libc.so.6 (0x00007f17f2a7d000)
/lib64/ld-linux-x86-64.so.2 (0x00007f17f2e4b000)
输出显示可执行文件依赖C库libc、linux-vdso、/lib64/ld-linux-x86-64。
ldd命令还可以用于检查共享库本身,以便跟踪共享库依赖关系链。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号