《汇编语言》学习笔记-2
注:本文档为“《汇编语言(第3版) 》王爽著”阅读过程中记的笔记。
参考视频:通俗易懂的汇编语言(王爽老师的书)_哔哩哔哩_bilibili
8 数据处理的两个问题
计算机进行数据处理,有两个基本的问题:
- 处理的数据在什么地方?
- 要处理的数据有多长?
这两个问题必须明确或隐含的说明,本章节就讨论这个问题。
为了描述方便, 引入两个描述性符号:reg和sreg
reg表示一个寄存器,包括:ax、bx、cx、dx、ah、al、bh、bl、ch、cl、dh、dl、sp、bp、si、di。
sreg表示一个段寄存器,包括:ds、ss、cs、es
8.1 bx、si、di和bp
bp:Pointer to base address (stack)
在8086CPU中,只有这四个寄存器可以用在'[...]'中进行内存单元的寻址。
比如,下面的指令是错误的:
mov ax, [cx]
Mov ax, [ax]
mov ax, [dx]
mov ax, [ds]
在'[...]'中,这4个寄存器可以单独出现,或只能以4种组合出现:bx和si、bx和di、bp和si、bp和di。
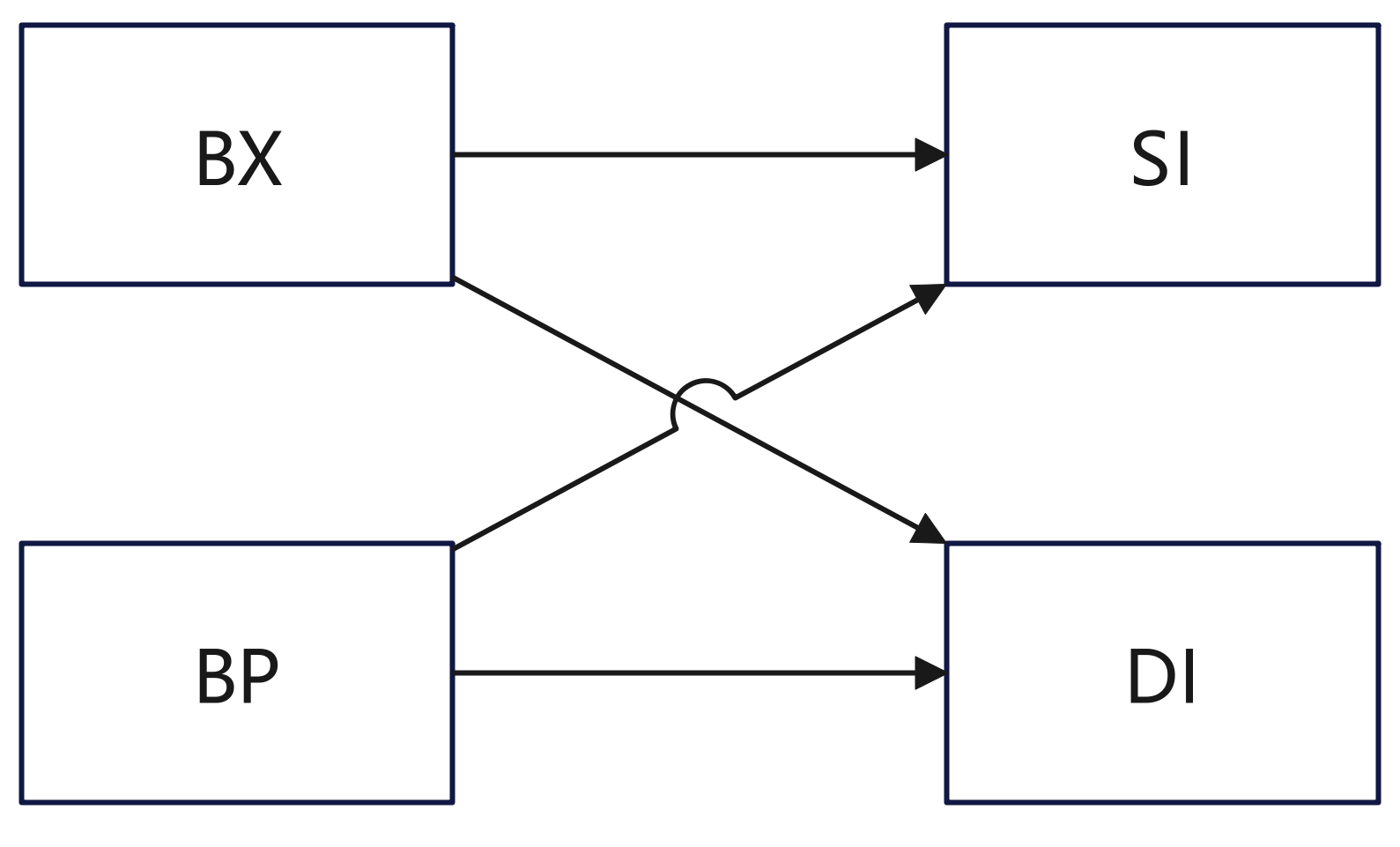
在'[...]'中使用寄存器bp,而指令没有显性的给出段地址,段地址默认在ss中,比如:
mov ax, [bp] ; (ax) = ((ss)*16+(bp))
mov ax, [bp+idata] ; (ax) = ((ss)*16+(bp)+idata)
mov ax, [bp+si] ; (ax) = ((ss)*16+(bp)+(si))
mov ax, [bp+si+idata] ; (ax) = ((ss)*16+(bp)+(si)+idata)
8.2 机器指令处理的数据在什么地方
大部分机器指令都是进行数据处理的指令,处理可大致分为三类:读取、写入、运算。
机器指令不关心数据的值是多少,而关心指令执行前一刻,它将要处理的数据所在的位置。
指令执行前,要处理的数据可以在三个地方:CPU内部、内存、端口。
| 机器码 | 汇编指令 | 指令执行前数据的位置 |
|---|---|---|
| 8E1E0000 | mov bx, [0] | 内存,ds:0单元 |
| 89C3 | mov bx, ax | CPU内部,ax寄存器 |
| BB0100 | mov bx, 1 | CPU内部,指令缓冲区 |
8.3 汇编语言中数据位置的表达
汇编语言中,用3种概念来表达数据的位置:
- 立即数(idata):对于直接包含在机器指令中的数据(在CPU的指令缓冲区),汇编语言称为立即数,在汇编指令中直接给出。
mov ax, 1
add bx, 2000H
- 寄存器:指令要处理的数据在寄存器中,在汇编指令中给出寄存器名。
mov ax, bx
push bx
- 段地址(SA)和偏移地址(EA):指令要处理的数据在内存中,在汇编指令中可用[X]的格式给出EA,SA在某个段寄存器中。
; 段地址默认在ds中
mov ax, [di]
mov ax, [bx+8]
; 段地址默认在ss中
mov ax, [bp]
mov ax, [bp+8]
; 段地址的寄存器也可以显示给出
mov ax, ds:[bp]
mov ax, es:[bx+si]
mov ax, ss:[bx+si]
8.4 寻址方式
当数据存放在内存中时,可以使用多种方式来给定内存单元的偏移地址,这种定位内存单元的方法一般称为寻址方式。
内存寻址方式总结:
| 寻址方式 | 含义 | 名称 | 常用格式举例 |
|---|---|---|---|
| [idata] | EA=idata;SA=(ds) | 直接寻址 | [idata] |
| [bx] [si] [di] [bp] |
EA=(bx);SA=(ds) EA=(si);SA=(ds) EA=(di);SA=(ds) EA=(bp);SA=(ss) |
寄存器间接寻址 | [bx] |
| [bx+idata] [si+idata] [di+idata] [bp+idata] |
EA=(bx)+idata;SA=(ds) EA=(si)+idata;SA=(ds) EA=(di)+idata;SA=(ds) EA=(bp)+idata;SA=(ss) |
寄存器相对寻址 | 用于结构体:[bx].idata 用于数组:idata[si],idata[di] 用于二维数组:[bx][idata] |
| [bx+si] [bx+di] [bp+si] [bp+di] |
EA=(bx)+(si);SA=(ds) EA=(bx)+(di);SA=(ds) EA=(bp)+(si);SA=(ss) EA=(bp)+(di);SA=(ss) |
基址变址寻址 | 用于二位数组:[bx][si] |
| [bx+si+idata] [bx+di+idata] [bp+si+idata] [bp+di+idata] |
EA=(bx)+(si)+idata;SA=(ds) EA=(bx)+(di)+idata;SA=(ds) EA=(bp)+(si)+idata;SA=(ss) EA=(bp)+(di)+idata;SA=(ss) |
相对基址变址寻址 | 用于表格(结构)中的数组项:bx.idata[si] 用于二维数组:idata[bx][si] |
8.5 指令要处理的数据有多长
8086CPU可以处理两种长度的数据:byte和word。在机器指令中要指明操作的是字还是字节。汇编语言中用以下办法处理。
- 通过寄存器名指明要处理的数据的尺寸。
; 寄存器指明进行字操作
mov ax, 1
mov bx, ds:[0]
; 寄存器指令进行字节操作
mov al, 1
mov al, bl
- 用操作符X ptr指明内存单元的长度,X在汇编指令中可以为word或byte
用word ptr指明了指令访问的内存单元式一个字单元:
mov word ptr ds:[0], 1
inc word ptr [bx]
inc word ptr ds:[0]
add word ptr [bx], 2
用byte ptr指明了指令访问的内存单元是一个字节单元:
mov byte ptr ds:[0], 1
inc byte ptr [bx]
inc byte ptr ds:[0]
add byte ptr [bx], 2
在没有寄存器参与的内存单元访问指令中,用word ptr或byte ptr显性的指明所要访问的内存单元的长度是必要的,否则CPU无法知道访问的是字单元还是字节。
mov ax, 2000h
mov ds, ax
mov byte ptr [1000h], 1 ; 字节操作
mov word ptr [1000h], 1 ; 字操作
- 其他办法:有些指明默认了访问的是字单元还是字节单元。
push [1000H] ; push指令只能进行字操作
8.6 div指令
div是除法指令,使用时需要注意:
- 除数:有8位和16位两种,在一个reg或者内存单元中。
- 被除数:默认放在AX或DX和AX中,如果除数为8位,被除数则为16位,默认在AX中存放;如果除数为16位,被除数则为32位,在DX和AX中存放,DX存放高16位,AX存放低16位。
- 结果:如果除数为8位,则AL存储除法操作的商,AH存储除法操作的余数;如果除数为16位,则AX存储除法操作的商,DX存储除法操作的余数。
格式如下:
div reg
div 内存单元
| 被除数 | 除数 | 商 | 余数 |
|---|---|---|---|
| AX | 8位内存或寄存器 | AL | AH |
| DX和AX | 16位内存或寄存器 | AX | DX |
可以用多种方法来表示一个内存单元:
| 示例指令 | 被除数 | 除数 | 商 | 余数 |
|---|---|---|---|---|
| div bl | (ax) | (bl) | (al) = (ax)/(bl)的商 | (ah) = (ax)/(bl)的余数 |
| div byte ptr ds:[0] | (ax) | ((ds)*16+0) | (al) = (ax)/((ds)*16+0)的商 | (ah) = (ax)/((ds)*16+0)的余数 |
| div byte ptr [bx+si+8] | (ax) | ((ds)*16+(bx)+(si)+8) | (al) = (ax)/((ds)*16+(bx)+(si)+8)的商 | (ah) = (ax)/((ds)*16+(bx)+(si)+8)的余数 |
| div bx | (dx)*10000H+(ax) | (bx) | (ax)=((dx)*10000H+(ax))/(bx)的商 | (dx)=((dx)*10000H+(ax))/(bx)的余数 |
| div word ptr es:[0] | (dx)*10000H+(ax) | ((es)*16+0) | (ax) = [(dx)*10000H+(ax)]/((es)*16+0)的商 | (dx) = [(dx)*10000H+(ax)]/((es)*16+0)的余数 |
| div word ptr [bx+si+8] | (dx)*10000H+(ax) | ((ds)*16+(bx)+(si)+8) | (ax) = [(dx)*10000H+(ax)]/((ds)*16+(bx)+(si)+8)的商 | (dx) = [(dx)*10000H+(ax)]/((ds)*16+(bx)+(si)+8)的余数 |
实验:利用除法指令计算100001/100
思路:100001(186A1H)大于65535,需要两个寄存器存放,被除数所以也需要使用16位寄存器存放。
mov dx, 1
mov ax, 86A1H
mov bx, 100
div bx
程序执行后,(ax)=03E8H(即100),(dx)=1(余数为1)。
实验:利用除法指令计算1001/100
思路:1001可用ax寄存器存放,除数100可用8位寄存器存放,进行8位的除法
mov ax, 1001
mov bl, 100
div bl
程序执行后,(ax)=0AH(即10),(ah)=1(余数为1)。
8.7 伪指令dd
前面用db和dw定义字节类型和字类型数据。dd是用来定义dword(double word,双字)类型数据。
data segment
db 1 ; 定义字节型数据,在data:0处,占1个字节
dw 1 ; 定义字型数据0001H,在data:1处,占2个字节
dd 1 ; 定义双字型数据00000001H,在data:3处,占2个字(4个字节)
data ends
实验:用div计算data段中第一个数据除以第二个数据后的结果,商存在第三个数据的存储单元中。
思路:data段中的第一个数据是被除数,为dword类型,32位,用dx和ax存储。
data segment
dd 100001
dw 100
dw 0
data ends
mov ax, data
mov ds, ax
mov ax, ds:[0] ; ds:0字单元的低16位存储在ax中
mov dx, ds:[2] ; ds:2字单元的高16位存储在dx中
div word ptr ds:[4]
mov ds:[6]:ax ; 将商存储在ds:6字单元中
8.8 dup
dup是一个操作符,由编译器识别处理的符号。可以和db、dw、dd等数据定义伪指令配合使用,用来进行数据的重复。
db 3 dup (0) ; 定义3个字节,它们的值都是0,相当于db 0,0,0
db 3 dup (0,1,2) ; 定义9个字节,它们的值都是0、1、2,相当于db 0,1,2,0,1,2,0,1,2
db 3 dup ('abc','ABC') ; 定义18个字节,它们是'abcABCabcABCabcABC'
dup的使用格式如下:
db 重复的次数 dup (重复的字节型数据)
dw 重复的次数 dup (重复的字型数据)
dd 重复的次数 dup (重复的双字型数据)
实验:定义一个容量为200个字节的栈段
stack segment
db 200 dup (0)
stack ends
9 指令转移的原理
可以修改IP,或同时修改CS和IP的指令统称为转移指令。转移指令就是可以控制CPU执行内存中某处代码的指令。
8086CPU的转移指令有以下几类:
- 只修改IP时,称为段内转移,比如:jmp ax。
- 同时修改CS和IP时,称为段间转移,比如:jmp 1000:0(仅debug.exe可以支持,汇编代码不支持直接写数字)。
由于转移指令对IP的修改范围不同,段内转移又分为:短转移和近转移
- 短转移IP的修改范围为-128~127
- 近转移IP的修改范围为-32768~32767
8086CPU的转移指令分为以下几类:
- 无条件转移指令(如:jmp)
- 条件转移指令(如:jcxz)
- 循环指令(如:loop)
- 过程
- 中断
9.1 操作符offset
用法:
offset 标号
操作符offset在汇编语言中是由编译器处理的符号,它的功能是取得标号的偏移地址。
assume cs:codesg
codesg segment
start:
mov ax, offset start ; 相当于mov ax, 0,占3个字节
s:
mov ax, offset s ; 相当于mov ax, 3
codesg ends
end start
9.2 jmp指令
jmp为无条件转移指令,可以只修改IP,也可以同时修改CS和IP。
jmp指令需要给出两种信息:
(1)转移的目的地址
(2)转移的距离
- 段间转移(远转移):jmp far ptr 标号;修改CS和IP
- 段内短转移:jmp short 标号;IP修改范围-128~127,8位的位移
- 段内近转移:jmp near ptr 标号;IP修改范围-32768~32767,16位的位移
9.2.1 依据位移进行转移的jmp指令
jmp short 标号 ; 转移到标号处执行指令
short:说明是短转移
标号:代码段的标号,指明指令要转移的目的地,转移指令结束后,CS:IP应该指向标号处的指令。
实现段内短转移,它对IP的修改范围为-128~127。向前最多可以越过128个字节,向后转移最多越过127个字节。
assume cs:codesg
codesg segment
start:
mov ax, 0
jmp short s
add ax, 1 ; 越过这条指令
s:
inc ax
codesg ends
end start
CPU在执行jmp指令的时候并不需要转移的目的地址,而是包含转移的位移,这个位移是编译器根据汇编指令中的“标号”计算出来的。
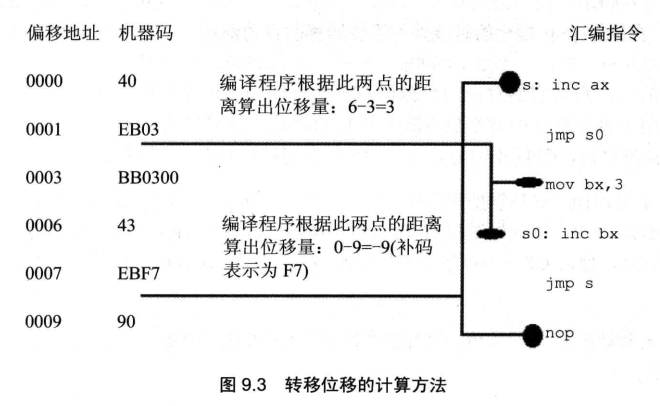
实际上,"jmp short 标号"的功能为:(IP)=(IP)+8位位移
- 8位位移=标号处的地址-jmp指令后的第一个字节的地址;
- short指明此处的位移为8位位移;
- 8位位移的范围为-128~127,用补码表示;
- 8位位移由编译程序在编译时算出。
另外,还有一种相近的指令格式:
jmp near ptr 标号 ; 段内近转移
- 16位位移=标号处的地址-jmp指令后的第一个字节的地址;
- near ptr指明此处的位移为16位位移;
- 16位位移的范围为-32768~32767,用补码表示;
- 16位位移由编译程序在编译时算出。
9.2.2 转移的目的地址在指令中的jmp指令
实现段间转移,又称为远转移,指明了转移到的目的地址。指令格式:
jmp far ptr 标号
功能如下:(CS)=标号所在段的段地址;(IP)=标号在段中的偏移地址。
far ptr:指明了指令用标号的段地址和偏移地址修改CS和IP。
assume cs:codesg
codesg segment
start:
mov ax, 0
mov bx, 0
jmp far ptr s
db 256 dup (0)
s:
add ax, 1
inc ax
codesg ends
end start
9.2.3 转移地址在寄存器中的jmp指令
指令格式:
jmp 16位reg
功能:(IP)=(16位reg)
jmp ax
jmp bx
9.2.4 转移地址在内存中的jmp指令
转移地址在内存中的jmp指令有两种格式:
- 格式一:
jmp word ptr 内存单元地址(段内转移)
功能:从内存单元地址处开始存放着一个字,是转移的目的偏移地址。
内存单元地址可用寻址方式的任一格式给出。
mov ax, 0123H
mov ds:[0], ax
jmp word ptr ds:[0] ; 执行后(IP)=0123h
mov ax, 0123H
mov [bx], ax
jmp word ptr [bx] ; 执行后(IP)=0123h
- 格式二:
jmp dword ptr 内存单元地址(段间转移)
功能:从内存单元地址处开始存放着两个字,高地址处的字是转移的目的段地址,低地址处是转移的目的偏移地址。
内存单元地址可用寻址方式的任一格式给出。
(CS)=(内存单元地址+2)
(IP)=(内存单元地址)
mov ax, 0123H
mov ds:[0], ax
mov word ptr ds:[2], 0
jmp dword ptr ds:[0] ; 执行后(CS)=0,(IP)=0123h
mov ax, 0123H
mov [bx], ax
mov word ptr [bx+2], 0
jmp dword ptr [bx] ; 执行后(CS)=0,(IP)=0123h
9.2.5 jmp指令小结
| jmp指令格式 | 示例 |
|---|---|
| jmp 标号 | - 段间转移(远转移):jmp far ptr 标号,修改CS和IP - 段内短转移:jmp short 标号 ;IP修改范围-128~127,8位的位移 - 段内近转移:jmp near ptr 标号 ;IP修改范围-32768~32767,16位的位移 |
| jmp 寄存器 | - jmp 16位寄存器 ;IP=16位的位移 |
| jmp 内存单元 | - 段内转移:jmp word ptr 内存单元地址(段内转移) - 段间转移:jmp dword ptr 内存单元地址(段间转移) |
9.3 jcxz指令
jcxz指令(jump cx zero)为有条件转移指令,所有的有条件跳转指令都是短转移,在对应的机器码中包含转移的位移,而不是目的地址。对IP的修改范围都为-128~127。
指令格式:
jcxz 标号 ; 如果(cx)=0,转移到标号处执行
操作:当(cx)=0,(IP)=(IP)+8位位移
- 8位位移=标号处的地址-jcxz指令后的第一个字节的地址;
- 8位位移的范围为-128~127,用补码表示;
- 8位位移由编译程序在编译时计算出。
当(cx)≠0时,程序什么都不做(向下执行),功能相当于:
if ((cx)==0)
jmp short 标号;
9.4 loop指令
loop指令为循环指令,所有的循环指令都是短指令,在对应的机器码中包含转移的位移,而不是目的地址。对IP的修改范围都为-128~127。
指令格式:
loop 标号 ; (cx)=(cx)-1,如果(cx)!=0,转移到标号处执行
操作:
(1) (cx)=(cx)-1
(2)如果(cx)≠0,(IP)=(IP)+8位位移。
- 8位位移=标号处的地址-loop指令后的第一个字节的地址;
- 8位位移的范围为-128~127,用补码表示;
- 8位位移由编译程序在编译时计算出。
当(cx)=0时,程序什么都不做(向下执行),功能相当于:
(cx)--;
if ((cx)!=0)
jmp short 标号;
9.5 根据位移进行转移的意义
对IP的修改是根据转移目的地址和转移起始地址之间的位移来进行:
- jmp short 标号
- jmp near ptr 标号
- jcxz 标号
- loop 标号
意义:
- 如果loop s的机器码中包含的是s的地址,则就对程序段在内存中的偏移地址有了严格的限制,容易引发错误。
- 当机器码中包含的是转移的位移,无论s处的指令的实际地址是多少,loop指令转移的相对位移是不变的。
10 CALL和RET指令
call和ret指令都是转移指令,它们都修改IP,或同时修改CS和IP。经常被共同来实现子程序的设计。
- 调用子程序:call指令
- 返回:ret指令
10.1 ret和retf
- ret指令用栈中的数据,修改IP的内容,从而实现近转移。
- retf指令用栈中的数据,修改CS和IP的内容,从而实现远转移。
CPU执行ret指令时,进行下面2步操作(出栈数据存到IP):
- (IP)=((ss)*16+(sp))
- (sp)=(sp)+2
CPU执行retf指令时,进行下面4步操作(出栈数据存到CS和IP):
- (IP)=((ss)*16+(sp))
- (sp)=(sp)+2
- (CS)=((ss)*16+(sp))
- (sp)=(sp)+2
用汇编语法解释ret和retf指令,则:
-
CPU执行ret指令时,相当于执行:
pop ip -
CPU执行retf指令时,相当于执行:
pop ip pop cs
示例:ret指令执行后,(IP)=0,CS:IP指向代码段的第一条指令。
assume cs:code
stack segment
db 16 dup (0)
stack ends
code segment
mov ax, 4c00h
int 21h
start:
mov ax, stack
mov ss, ax
mov sp, 16
mov ax, 0
push ax
mov bx, 0
ret ; (IP)=0
code ends
end start
10.2 call指令
CPU执行call指令(调用子程序)时,进行两个步骤:
- 将当前的IP(下一条指令的地址)或CS和IP压入栈中;
- 转移。
call指令不能实现短转移。
10.2.1 依据位移进行转移的call指令
call 标号 ; 将当前的IP压栈后,转到标号处执行指令
CPU执行此种格式的call指令时,进行如下的操作:
-
(sp)=(sp)-2
((ss)*16+(sp))=(ip)
-
(IP)=(IP)+16位位移
- 16位位移=标号处的地址-call指令后的第一个字节的地址;
- 16位位移的范围为-32768~32767,用补码表示;
- 16位位移由编译程序在编译时计算出。
用汇编语法解释此种格式的call指令,则:
push ip
jmp near ptr 标号
10.2.2 转移的目的地址在指令中的call指令
call far ptr 标号 ; 实现段间转移
CPU执行此种格式的call指令时,进行如下的操作:
-
(sp)=(sp)-2
((ss)*16+(sp))=(CS)
(sp)=(sp)-2
((ss)*16+(sp))=(ip)
-
(CS)=标号所在段的段地址
(IP)=标号在段中的偏移地址
用汇编语法解释此种格式的call指令,则:
push CS
push IP
jmp far ptr 标号
10.2.3 转移地址在寄存器中的call指令
指令格式:
call 16位reg
功能:
- (sp)=(sp)-2
- ((ss)*16+(sp))=(IP)
- (IP)=(16位reg)
用汇编语法解释此种格式的call指令,则:
push IP
jmp 16位reg
10.6 转移地址在内存中的call指令
转移地址在内存中的call指令有两种格式:
- 格式一:
call word ptr 内存单元地址
用汇编语法解释此种格式的call指令,则:
push IP
jmp word ptr 内存单元地址
示例:
mov sp, 10h
mov ax, 0123h
mov ds:[0], ax
call word ptr ds:[0] ; 执行后,(IP)=0123H,(sp)=0EH
- 格式二:
call dword ptr 内存单元地址
用汇编语法解释此种格式的call指令,则:
push CS
push IP
jmp dword ptr 内存单元地址
示例:
mov sp, 10h
mov ax, 0123h
mov ds:[0], ax
mov word ptr ds:[2], 0
call dword ptr ds:[0] ; 执行后,(CS)=0,(IP)=0123H,(sp)=0CH
10.3 call和ret的配合使用
可以实现一个具有一定功能的程序段,称其为子程序,在需要的时候,用call指令转去执行,call指令转去执行子程序之前,call指令后面的指令的地址将存储在栈中,所以可以在子程序后面使用ret指令,用栈中的数据设置IP的值,从而转到call指令后面的代码处执行执行。
调用程序的框架:
... ...
call 标号
... ...
使用call和ret实现子程序的框架:
标号:
指令
ret
具有子程序的源程序的框架如下:
assume cs:code
code segment
main:
...
call sub1 ; 调用子程序sub1
...
mov ax, 4c00h
int 21h
sub1: ; 子程序sub1开始
...
call sub2 ; 调用子程序sub2
...
ret ; 子程序返回
sub2: ; 子程序sub2开始
...
...
ret ; 子程序返回
code ends
end main
实验:计算2的N次方,N的值由CX提供。
assume cs:code
code segment
start:
mov ax, 1
mov cx, 3
call s
mov bx, ax
mov ax, 4c00h
int 21h
s:
add ax, ax
loop s
ret
code ends
end start
上面的程序是危险的程序,没有分配call需要使用的栈。
实验:为call和ret指令设置栈
assume cs:code
stack segment
db 8 dup (0)
db 8 dup (0)
stack ends
code segment
start:
mov ax, stack
mov ss, ax
mov sp, 16
mov ax, 1000
call s
mov ax, 4c00h
int 21h
s:
add ax, ax
ret
code ends
end start
10.4 mul指令
mul是乘法指令,使用mul做乘法的时候,需要注意:
- 两个相乘的数,要么都是8位,要么都是16位。如果是8位,一个默认在AL中,另一个默认放在8位的reg或内存单元中;如果是16位,一个默认在AX中,另一个放在16位reg或内存单元中。
- 如果是8位乘法,结果默认放在AX中;如果是16位乘法,结果高位默认在DX中存放,低位在AX中存放。
格式如下:
mul reg
mul 内存单元
内存单元可以用不同的寻址方式给出,比如:
mul byte ptr ds:[0] ; (ax)=(al)*((ds)*16+0)
; (ax)=(ax)*((ds)*16+(si)+8)结果的低16位
; (ax)=(ax)*((ds)*16+(si)+8)结果的高16位
mul word ptr [bx+si+8]
实验:
; 计算100*10
mov al, 100
mov bl, 10
mul bl ; 结果(ax)=1000(03E8H)
; 计算100*1000
mov ax, 100
mov bx, 1000
mul bx ; 结果(ax)=4240H,(dx)=000FH
10.5 参数和结果传递的问题
子程序一般要根据提供的参数处理一定的事务,处理后将结果提供给调用者。
讨论的问题就是如果存储子程序需要的参数和产生的返回值。
实验:设计一个子程序,可以根据提供的N,来计算N的3次方。
思路:将参数N存储在什么地方?计算得到的值,存储在什么地方?
; 参数:(bx)=N
; 结果:(dx:ax)=N^3
mov ax, bx
mul bx
mul bx
ret
用寄存器存储参数和结果是最常见的方法。调用者将参数送入参数寄存器,从结果寄存器中取得返回值;子程序从参数寄存器中取得参数,将返回值送入结果寄存器。
实验:计算data段中第一组数据的3次方,结果保存在后面一组dword单元中。
assume cs:code
data segment
dw 1, 2, 3, 4, 5, 6, 7, 8
dd 0, 0, 0, 0, 0, 0, 0, 0
data ends
code segment
start:
mov ax, data
mov si, 0 ; ds:si指向第一个数组word单元
mov di, 16 ; ds:di指向第二组dword单元
mov cx, 8
s: mov bx, [si]
call cube
mov [di], ax
mov [di].2, dx
add si, 2 ; ds:si指向下一个word单元
add di, 4 ; ds:di指向下一个dword单元
loop s
mov ax, 4c00h
int 21h
cube:
mov ax, bx
mul bx
mul bx
ret
code ends
end start
10.6 批量数据的传递
对于子程序需要传递多个参数的情况,将批量数据放到内存中,然后将它们所在内存空间的首地址放在寄存器中,传递给需要的子程序。对于具有批量数据的返回结果,也可用同样的方法。
实验:将data段中的字符串转换为大写。
assume cs:code
data segment
db 'conversation'
data ends
code segment
start:
mov ax, data
mov ds, ax
mov si, 0
mov cx, 12
call capital
mov ax, 4c00h
int 21h
capital:
and byte ptr [si],11011111b
inc si
loop capital
ret
code ends
end start
除了用寄存器传递参数外,还有一种通用的用栈来传递参数。
10.7 寄存器和冲突的问题
问题:主程序和子程序都可能用到相同的寄存器,子程序无法判断主程序用到了哪些寄存器。
解决方法:在子程序的开始将子程序中所有用到的寄存器中的内容都保存起来,在子程序返回前再恢复,可以用栈来保存寄存器中的内容。
因此,编写子程序的标准框架如下:
子程序开始:
子程序中使用的寄存器入栈
子程序中使用的寄存器出栈
返回(ret、retf)
需要注意寄存器入栈和出栈的顺序。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)