Python实现求多个集合之间的并集-方法2
之前使用过一种方法实现求集合间的并集,参考文章:https://www.cnblogs.com/mrlayfolk/p/12373532.html,这次使用另外一种方法实现,这种方法效率更高。
目的:
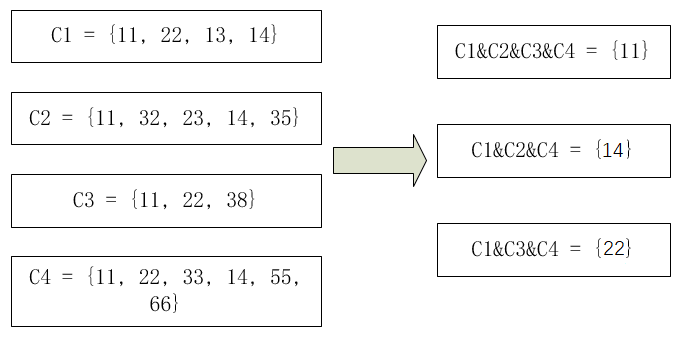
求多个集合之前的并集,例如:现有四个集合C1 = {11, 22, 13, 14}、C2 = {11, 32, 23, 14, 35}、C3 = {11, 22, 38}、C4 = {11, 22, 33, 14, 55, 66},则它们之间的并集应该为:
C1 & C2 & C3 = {11}、C1 & C2 & C4 = {14}、C1 & C3 & C4 = {22}。如下图所示:
实现步骤:
以上述的四个集合为例进行说明:C1 = {11, 22, 13, 14}、C2 = {11, 32, 23, 14, 35}、C3 = {11, 22, 38}、C4 = {11, 22, 33, 14, 55, 66}。
(1)首先找到成员数最多的集合,为C4 = {11, 22, 33, 14, 55, 66},将C4的每个成员依次和各个集合的成员进行比较,判断这个成员是否再其它集合中存在。
(2)经过比较我们可以得到:11∈C1、C2、C3、C4; 22∈C1、C3、C4; 14∈C1、C2、C4; 33、55、66∈C4。
(3)接着,将除C4以外,剩余集合的剩余成员找出来,C1 = {13},C2 = {32、23、35},C3 = {38}。
(4)找出成员数最多的集合,这里是C2,将C2的各个成员和其它集合进行比较。得到:32、23、35∈C2;
(5)接着只剩下C1和C3了,两个集合的成员数一样,例如使用C1的成员和C3进行比较之后,得到:13∈C1,38∈C3。
通过上述步骤,我们最终得到:C1 & C2 & C3 = {11}、C1 & C2 & C4 = {14}、C1 & C3 & C4 = {22}。
当然,也可以先找出成员数最少的集合,逐个使用这个集合的成员与其它集合的成员进行对比,也能够得到各个集合之间的交集。
实现代码:
下面python代码实现的是每次使用成员数最少的集合和其它集合的成员进行对比的情况:
1 # decoding: utf-8 2 3 import os 4 import sys 5 import xlrd 6 import logging 7 import csv 8 import numpy as np 9 10 # 设置logging.basicConfig()方法的参数和配置logging.basicConfig函数 11 FORMAT = '[%(funcName)s: %(lineno)d]: %(message)s' 12 LEVEL = logging.INFO 13 logging.basicConfig(level = LEVEL, format=FORMAT) 14 15 16 def func(content): 17 all_dict = {} 18 for d in content: 19 for k in d.keys(): 20 tmp_value = d[k] 21 if k in all_dict.keys(): 22 tmp_values = all_dict[k] 23 # 更新成员数 24 for i in range(len(tmp_value)): 25 if tmp_value[i] not in tmp_values: 26 tmp_values.append(tmp_value[i]) 27 all_dict[k] = tmp_values 28 29 if k not in all_dict.keys(): 30 # 这里需要处理一种情况:如13: [0, 0],某个字典的值有重复的元素。 31 tmp_values = [] 32 for i in range(len(tmp_value)): 33 tmp = tmp_value[i] 34 if tmp in tmp_values: 35 continue 36 tmp_values.append(tmp) 37 all_dict[k] = tmp_values 38 39 return all_dict 40 41 42 # get union sets from collections 43 def get_unions(content): 44 c_mems_list = [] 45 for c in content: 46 c_mems_list.append(len(c)) 47 # print (c_mems_list) 48 49 mems_list_index = np.argsort(c_mems_list) 50 # print (mems_list_index) 51 52 # 取成员数最小的集合的成员依次和其它集合进行比较 53 all_index_list = [] 54 for c_index in mems_list_index: 55 min_c = content[c_index] #成员数最小的集合 56 elem_index = {} # 存放成员所在集合的索引,格式如下:[elem, index] 57 for elem in min_c: # 判断成员数最小的集合的各个成员是否在其它集合中存在 58 index_tmp = [] 59 index_tmp.append(c_index) #首先存放成员数最小集合的索引 60 for other_index in mems_list_index[c_index+1: ]: # 开始判断本成员在其它集合中是否存在 61 if elem in content[other_index]: #若存在,加入到成员所在集合的索引中去 62 index_tmp.append(other_index) 63 elem_index[elem] = index_tmp 64 all_index_list.append(elem_index) 65 66 # print (all_index_list) 67 all_dict = func(all_index_list) #将重复的索引删除掉 68 69 return all_dict 70 71 72 if __name__ == "__main__": 73 74 # original data 75 C0 = {11, 22, 13, 14} 76 C1 = {11, 32, 23, 14, 35} 77 C2 = {11, 22, 38} 78 C3 = {11, 22, 33, 14, 55, 66} 79 80 print ('############## enter main ##############') 81 res = get_unions([C0, C1, C2, C3]) 82 for key in res: 83 print (key, ':', res[key]) 84 print ('############## end main ##############')
输出结果如下:
1 ############## enter main ############## 2 38 : [2] 3 11 : [2, 3, 0, 1] 4 22 : [2, 3, 0] 5 13 : [0] 6 14 : [0, 1, 3] 7 32 : [1] 8 35 : [1] 9 23 : [1] 10 33 : [3] 11 66 : [3] 12 55 : [3] 13 ############## end main ##############
下面我们换一组数据进行测试:
1 if __name__ == "__main__": 2 3 # original data 4 C0 = {11, 22, 13, 14, 15} 5 C1 = {11, 22, 23, 14, 35} 6 C2 = {11, 22, 38, 15, 66} 7 C3 = {11, 22, 33, 14, 55, 66} 8 C4 = {22, 33, 15, 89, 33} 9 10 print ('############## enter main ##############') 11 res = get_unions([C0, C1, C2, C3, C4]) 12 for key in res: 13 print (key, ':', res[key]) 14 print ('############## end main ##############')
输出结果如下:
1 ############## enter main ############## 2 89 : [4] 3 33 : [4, 3] 4 22 : [4, 0, 1, 2, 3] 5 15 : [4, 0, 2] 6 11 : [0, 1, 2, 3] 7 13 : [0] 8 14 : [0, 1, 3] 9 35 : [1] 10 23 : [1] 11 66 : [2, 3] 12 38 : [2] 13 55 : [3] 14 ############## end main ##############
可以看出,输出的结果和预期的一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号