python数据分析练习--分析成都的房价
目的:使用python的numpy、pandas、matplotlib库来分析成都二手房的房价信息。
原始数据来源:贝壳找房网站上的数据https://cd.ke.com/ershoufang
环境:win10 python 3.7.3
环境:win10 python 3.7.3 vscode编辑器
(1)第一部分:使用python爬取贝壳网上的数据
爬取的数据是:锦江、青羊、武侯、高新、成华、金牛、天府新区、双流、温江、郫都、龙泉驿、新都等区的两室的二手房价信息,每个地区爬取了300个条目。
由于爬取的是静态页面,所以很容易,我就直接放代码了,不熟悉的网友可以参考一下这篇文章:https://www.cnblogs.com/mrlayfolk/p/12319414.html。
1 # encoding:utf-8 2 3 ''' 4 目的:从贝壳找房中爬取房价信息。网址:https://cd.ke.com/ershoufang/qingyang/l2/ 5 分别是:锦江、青羊、武侯、高新、成华、金牛、天府新区、双流、温江、郫都、龙泉驿、新都等区的房价信息 6 环境:python 3.7.3 7 所需的库:requests、BeautifulSoup、xlwt 8 ''' 9 10 import requests 11 import string 12 import csv 13 import re 14 from bs4 import BeautifulSoup 15 16 headers = { 17 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',\ 18 "Host": "cd.ke.com", 19 } 20 21 # 将获取的信息保存到表格中 22 def save_info(content, title): 23 head = ('position', 'floor', 'builtYear', 'layout', 'size', 'orientation', 'totalPrice', 'perPrice') 24 with open('%s.csv' % title, 'w', newline='', encoding='utf-8-sig') as f: 25 writer = csv.writer(f) 26 writer.writerow(head) 27 for i in range(len(content)): 28 row = content[i] 29 writer.writerow(row) 30 31 32 33 # 获取房屋相关的信息 34 # 主要包括:'position', 'floor', 'builtYear', 'layout', 'size', 'orientation', 'totalPrice', 'perPrice' 35 def get_info(place): 36 37 all_info = [] 38 position_list = [] 39 floor_list = [] 40 builtYear_list = [] 41 layout_list = [] 42 size_list = [] 43 orientation_list= [] 44 totalPrice_list = [] 45 unitPrice_list = [] 46 47 for i in range(10): 48 link = 'https://cd.ke.com/ershoufang/%s/pg%dl2/' % (place, i) 49 r = requests.get(link, headers=headers, timeout=10) 50 print (str(i+1), 'status_code: ', r.status_code) 51 soup = BeautifulSoup(r.text, 'lxml') 52 positionInfo = soup.findAll('div', {'class': 'positionInfo'}) 53 houseInfo = soup.findAll('div', {'class': 'houseInfo'}) 54 totalPrice = soup.findAll('div', {'class': 'totalPrice'}) 55 unitPrice = soup.findAll('div', {'class': 'unitPrice'}) 56 for item in positionInfo: 57 postion = item.a.text.strip() 58 position_list.append(postion) 59 for item in houseInfo: 60 house_info = item.text.strip().replace('\n', ' ').replace(' ', '') 61 floor = re.search('.楼层\(共[\d]+层\)', house_info).group() 62 s = re.search('[\d]*年建', house_info) 63 if s is not None: builtYear = s.group().replace("年建", '') 64 else: builtYear = None 65 layout = re.search('.室.厅', house_info).group() 66 size = re.search('([\d]*\.[\d]*|[\d]*)平米', house_info).group().replace('平米', '') 67 orientation = re.search('东南|东北|西南|西北|东|西|南|北', house_info).group() 68 floor_list.append(floor) 69 builtYear_list.append(builtYear) 70 layout_list.append(layout) 71 size_list.append(size) 72 orientation_list.append(orientation) 73 for item in totalPrice: 74 total_price = item.span.text.strip() 75 totalPrice_list.append(total_price) 76 for item in unitPrice: 77 unit_price = item.span.text.strip().replace('单价', '').replace('元/平米', '') 78 unitPrice_list.append(unit_price) 79 print (len(position_list)) 80 print (len(floor_list)) 81 print (len(builtYear_list)) 82 print (len(layout_list)) 83 print (len(size_list)) 84 print (len(orientation_list)) 85 print (len(totalPrice_list)) 86 print (len(totalPrice_list)) 87 for i in range(len(position_list)): 88 item = [position_list[i], floor_list[i], builtYear_list[i], layout_list[i], \ 89 size_list[i], orientation_list[i], totalPrice_list[i], unitPrice_list[i]] 90 all_info.append(item) 91 92 return all_info 93 94 95 if __name__ == "__main__": 96 97 area_list = ['jinjiang', 'qinyang', 'wuhou', 'gaoxin', 'chenghua', 'jinniu', \ 98 'tianfuxinqu', 'shuangliu', 'wenjiang', 'pidu', 'longquanyi', 'xindu'] 99 100 for place in area_list: 101 all_info = get_info(place) 102 save_info(all_info, place)
上述代码执行的结果是:输出了存储成都各地区房价信息的csv文件。
以下地方需要说明一下:
1)当我们获取到房屋信息时(如:高楼层(共6层) | 2000年建 | 2室2厅 | 78平米 | 南),由于有些条目缺少年建(前面的“2000”年建),所以用字符串的内建函数来分割出楼层、年建、布局、面积、朝向等信息不是很方便,建议使用正则表达式,这样会方便很多。
2)当我们存储数据到csv文件时,把“ encoding='utf-8-sig' ”这条语句加上,不然我们使用pandas.read_csv()函数打开csv文件时会出现编码错误的问题,具体的原因可查看这篇文章:https://www.cnblogs.com/harrymore/p/10063775.html
(2)第二部分:分析爬取到的房价信息
接下来使用numpy、pandas、matplotlib库来分析。
1)首先,先导入这些库。
1 import numpy as np 2 import pandas as pd 3 from matplotlib import pyplot as plt 4 5 # 解决绘图时中文不显示的问题 6 plt.rcParams['font.sans-serif'] = ['SimHei'] 7 plt.rcParams['axes.unicode_minus'] = False
2)然后,我们将抓取到的文件使用pandas.read_csv()方法读取出来。
1 df_jinjiang = pd.read_csv('jinjiang.csv') 2 df_qinyang = pd.read_csv('qinyang.csv') 3 df_wuhou = pd.read_csv('wuhou.csv') 4 df_gaoxin = pd.read_csv('gaoxin.csv') 5 df_chenghua = pd.read_csv('chenghua.csv') 6 df_jinniu = pd.read_csv('jinniu.csv') 7 df_tianfuxinqu = pd.read_csv('tianfuxinqu.csv') 8 df_shuangliu = pd.read_csv('shuangliu.csv') 9 df_wenjiang = pd.read_csv('wenjiang.csv') 10 df_pidu = pd.read_csv('pidu.csv') 11 df_longquanyi = pd.read_csv('longquanyi.csv') 12 df_xindu = pd.read_csv('xindu.csv') 13 14 df = [df_jinjiang, df_qinyang, df_wuhou, df_gaoxin, df_chenghua, df_jinniu, df_tianfuxinqu, \ 15 df_shuangliu, df_wenjiang, df_pidu, df_longquanyi, df_xindu]
3)接着,我们先使用DataFrame的describe()方法先分析一下各地区的统计值,包括:最大值、最小值、平均值、中位数等。
1 area_name = ['jinjiang', 'qinyang', 'wuhou', 'gaoxin', 'chenghua', 'jinniu', 'tianfuxinqu', \ 2 'shuangliu', 'wenjiang', 'pidu', 'longquanyi', 'xindu'] 3 4 for i, item in enumerate(df): 5 print ('%s:' % area_name[i]) 6 print (item.describe())
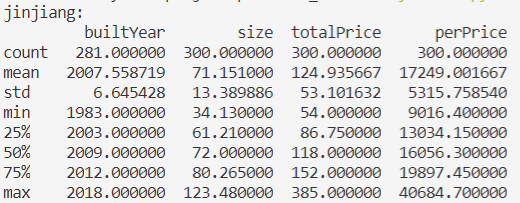
打印的数据很多,就不全部弄出来了,锦江区的数据如下,可以看到锦江区的二手房价平均值为124.93万元、中位数为118万元;每平米的单价的平均值为17249元,中位数为16056.3元。由于抓取的数据只是两室的房屋,可以看出面积平均为71.15平方米,中位数为72平方米。
4)接着分析一下每个地区的房屋的单价信息(元/平米),并以柱状图显示出来。
1 perPrice_list = [] 2 for item in df: 3 perPrice = item['perPrice'].mean() 4 perPrice_list.append(perPrice) 5 data = pd.Series(perPrice_list, index=area_name) 6 data.plot(kind='barh', color='g', alpha=0.7, title=u'成都各区每平米房价对比') 7 plt.ylabel('area') 8 plt.xlabel('perPrice') 9 plt.show()
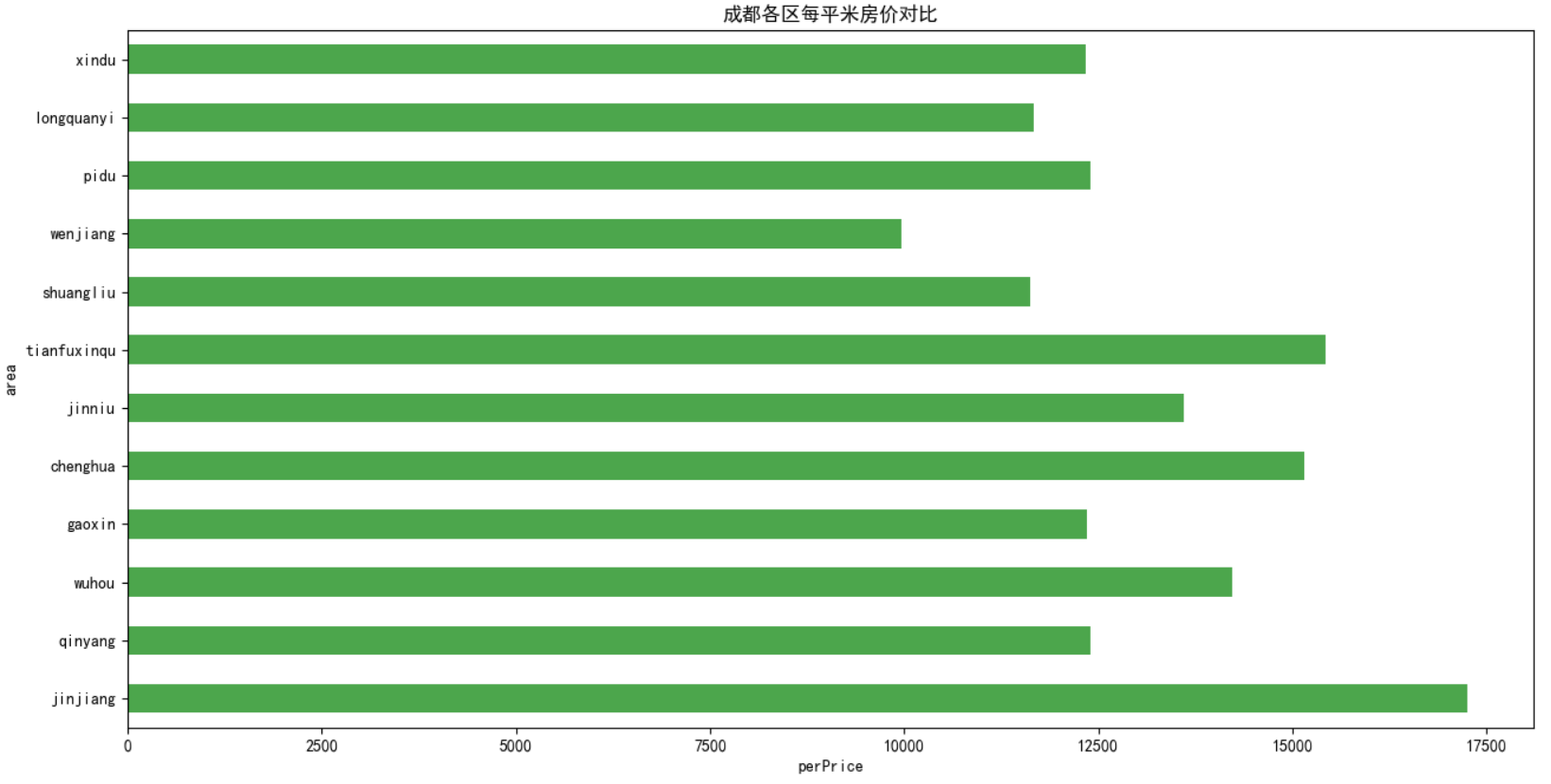
从分析结果可以看出:锦江区的每平米房价最高,温江的最低。
5)接下来,分析一下面积和单价的对应关系。
为了方便后续处理,先将所有的面积,单价,总价进行一个汇总。
1 # 将各个条目数据进行汇总 2 size_list = [] 3 builtYear_list = [] 4 totalPrice_list = [] 5 perPrice_list = [] 6 for item in df: 7 size = item['size'] 8 builtYead = item['builtYear'] 9 price = item['totalPrice'] 10 perPrice = item['perPrice'] 11 for i in range(len(size)): 12 size_list.append(size[i]) 13 builtYear_list.append(builtYead) 14 totalPrice_list.append(price[i]) 15 perPrice_list.append(perPrice[i]) 16 print (len(size_list)) 17 print (len(builtYear_list)) 18 print (len(totalPrice_list)) 19 print (len(perPrice_list))
6)现在获取每平米的单价和面积之间的对应关系。
1 # 将各地区的面积和单价统计起来,看一下面积和单价之间的对应关系。 2 plt.scatter(totalPrice_list, size_list, s=np.pi) 3 plt.title('面积与房屋单价的对应关系') 4 plt.xlabel('size') 5 plt.ylabel('perPrice') 6 plt.show()
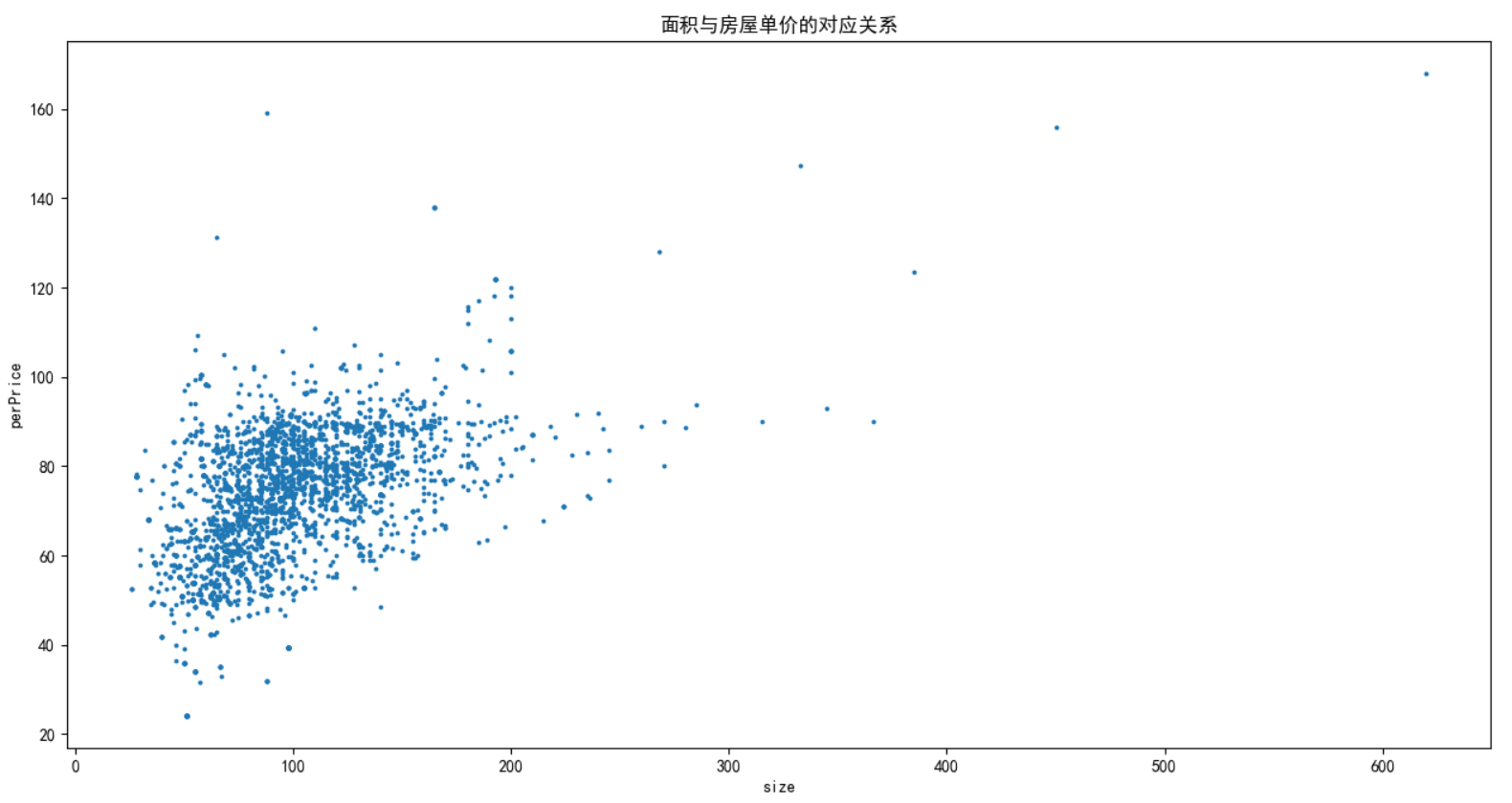
可以看出,面积和单价之间基本是成正相关的,只有几个少数的地方数据点除外。
7)分析每一个地区的房价(总价)与面积之间的关系,并绘制散布图
1 # 分析每一个地区的房价(总价)与面积之间的关系,并绘制散布图 2 totalPrice_list = [] 3 size_list = [] 4 for item in df: 5 totalPrice = item['totalPrice'] 6 size = item['size'] 7 totalPrice_list.append(totalPrice) 8 size_list.append(size) 9 fig, axes = plt.subplots(3, 4) 10 k = 0 11 for i in range(3): 12 for j in range(4): 13 axes[i, j].scatter(size_list[k], totalPrice_list[k], label=area_name[k], s=np.pi) 14 axes[i, j].legend(loc='best') 15 axes[i, j].set_xlabel('size') 16 axes[i, j].set_ylabel('price') 17 k += 1 18 plt.subplots_adjust(hspace=0.25) 19 plt.show()
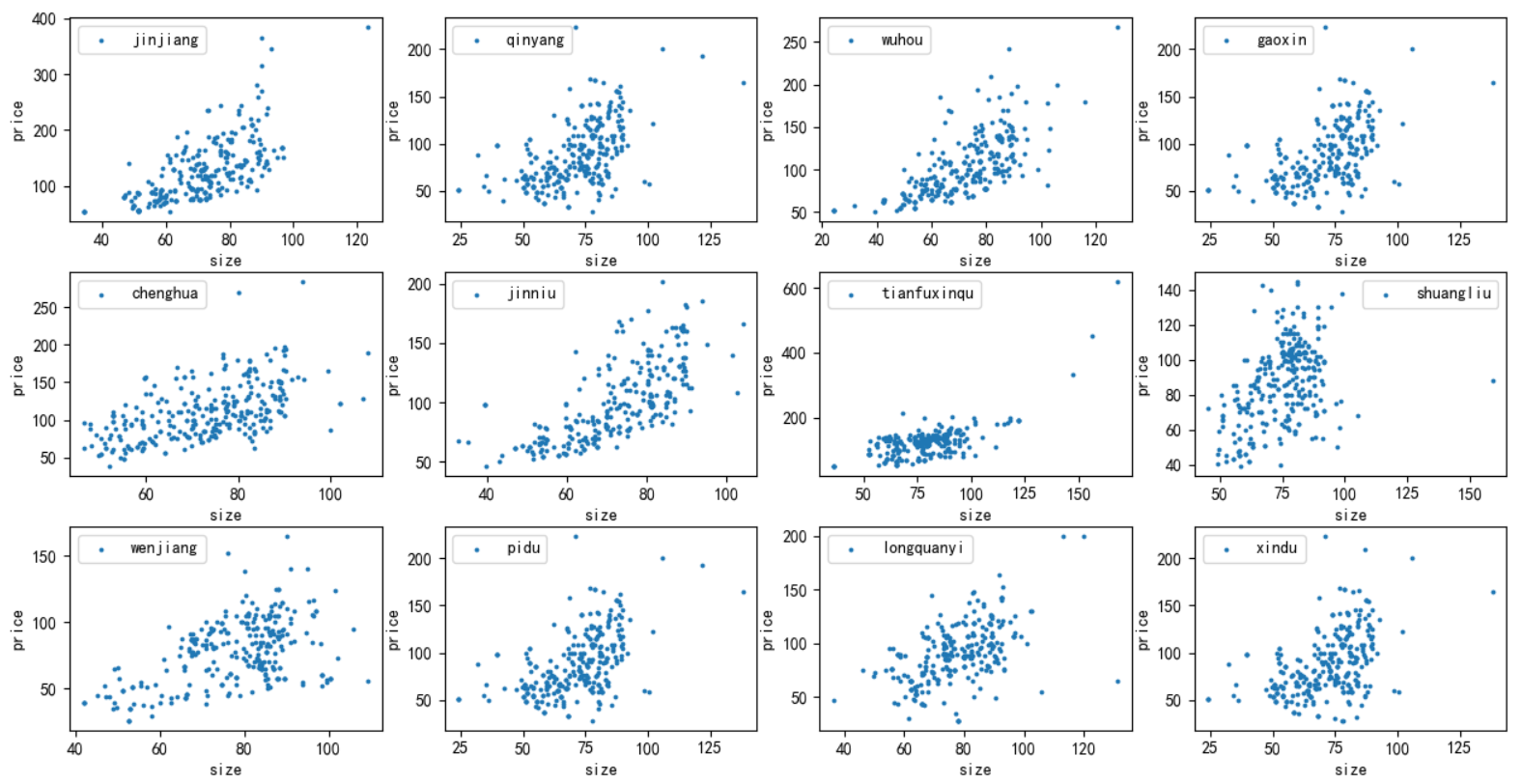
可以看出,大部分地区的房屋面积和价格是呈现出正相关的关系,而天府新区的面积与房价之间没有体现出这种关系,这似乎是不正常的。
8)分析一下房屋建立的时间与单价之间的关系。
1 # 分析房屋年限和单价的关系 2 builtYear_list = [] 3 perPrice_list = [] 4 for item in df: 5 perPrice = item['perPrice'] 6 builtYear = item['builtYear'] 7 perPrice_list.append(perPrice) 8 builtYear_list.append(builtYear) 9 fig, axes = plt.subplots(3, 4) 10 k = 0 11 for i in range(3): 12 for j in range(4): 13 axes[i, j].scatter(builtYear_list[k], perPrice_list[k], label=area_name[k], s=np.pi) 14 axes[i, j].legend(loc='best') 15 axes[i, j].set_xlabel('builtYear') 16 axes[i, j].set_ylabel('perPrice') 17 k += 1 18 plt.subplots_adjust(wspace=0.3, hspace=0.3) 19 plt.show()
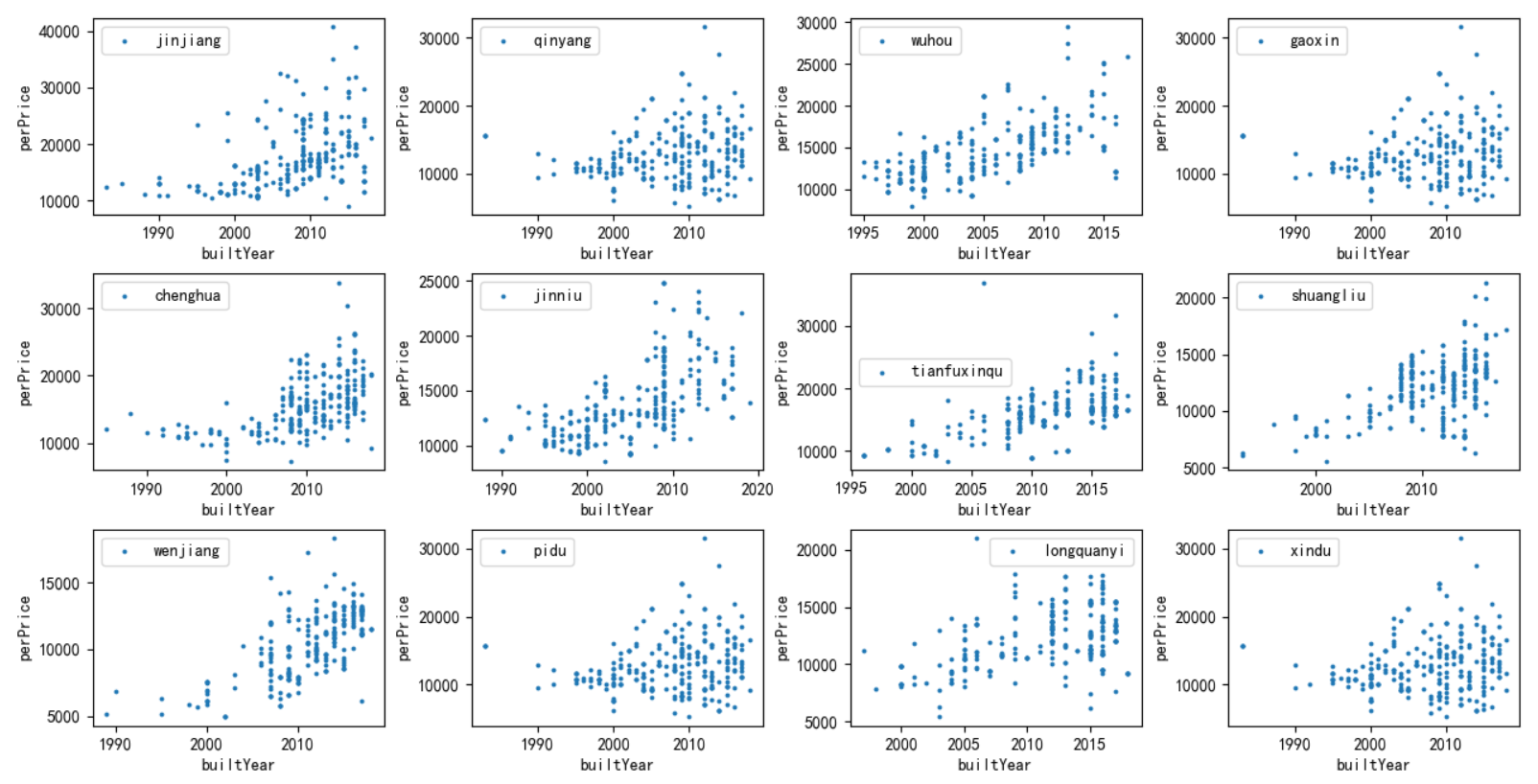
可看出,郫都和新都的房屋建立时间并没有体现出与房价的相关性,2000年建立的房屋和2010年建立的房屋价格差不多,这似乎是不正常的。
(3)总结
我才开始学习python和python的数据分析没有多久,对于数据分析的模型更是不懂。我把这当作一个学习的记录过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号