绘图与可视化--pandas中的绘图函数
matplotlib API函数都位于matplotlib.pyplot模块中。
本节代码中引入的约定为:import matplotlib.pyplot as plt
numpy库也会用到,约定:import numpy as np
pandas库也会用到,约定:import pandas as pd
2 pandas中的绘图
matplotlib是一种比较低级的工具,要组装一张图表,你得用它得各种基础组件才行:数据展示(即图表类型:线型图、柱状图、盒型图、散布图、等值线图等)、图例、标题、刻度标签以及其它注释型信息。
在pandas中,有行标签、列标签及分组信息,要绘制一张图,需要很多matplotlib代码。pandas有很多能够利用DataFrame对象数据组织特点来创建标准图表的高级绘图方法。
2.1 线型图
Series和DataFrame都有一个用于生成各类图表的plot方法,默认情况下,生成的是线型图。
1 >>> s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
2 >>> s.plot()
3 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F35B8A898>
4 >>> plt.show()

该Series对象的索引会传给matplotlib,并用以绘制X轴,可通过use_index=False禁用该功能。X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim。
官方说明:pandas.Series.plot — pandas 1.3.4 documentation (pydata.org)
plot参数完整列表如下所示:
| 参数 | 说明 |
|---|---|
| label | 用于图例的标签 |
| ax | 要在其上进行绘制的matplotlib subplot对象,如果没有设置,则使用当前matplotlib subplot |
| style | 将要传给matplotlib的风格字符串(如’ko--’) |
| alpha | 图表的填充不透明度(0到1之间) |
| kind | 可以是’line’、’bar’、’barh’、’kde’ |
| logy | 在Y轴上使用对数标尺 |
| use_index | 将对象的的索引用作刻度标签 |
| rot | 旋转刻度标签(0到360) |
| xticks | 用作X轴刻度的值 |
| yticks | 用作Y轴刻度的值 |
| xlim | X轴的界限(例如[0, 10]) |
| ylim | Y轴的界限 |
| grid | 显示轴网格线(默认打开) |
pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。
DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例。
官方说明:pandas.DataFrame.plot — pandas 1.3.4 documentation (pydata.org)
1 >>> df = pd.DataFrame(np.random.randn(10, 4).cumsum(0), columns=['A', 'B', 'C', 'D'], index=np.arange(0, 100, 10))
2 >>> df.plot()
3 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F35B8AFD0>
4 >>> plt.show()
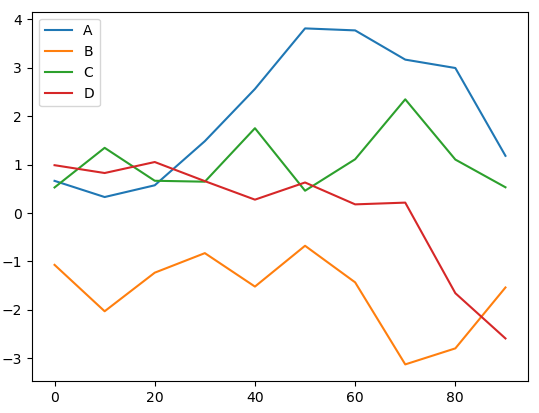
DataFrame还有一些用于对列进行灵活处理的选项。下表是专用于DataFrame的plot参数。
| 参数 | 说明 |
|---|---|
| subplots | 将各个DataFrame列绘制到单独的subplot中 |
| sharex | 如果subplots=True,则共用同一个X轴,包括刻度和界限 |
| sharey | 如果subplots=True,则共用同一个Y轴 |
| figsize | 表示图像大小的元组 |
| title | 表示图像标题的字符串 |
| legend | 添加一个subplot实例(默认为True) |
| sort_columns | 以字母顺序绘制各列,默认使用当前列顺序 |
2.2 柱状图
在生成线性图的代码中加上kind=’bar’(垂直柱状图)或kind=’barh’(水平柱状图)即可生成柱状图。这时,Series和DataFrame的索引将会被当作X(bar)或Y(barh)刻度。
1 >>> fig, axes = plt.subplots(2, 1)
2 >>> data = pd.Series(np.random.rand(16), index=list('abcdefghijklmnop'))
3 >>> data.plot(kind='bar', ax=axes[0], color='k', alpha=0.7)
4 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F37F3FE48>
5 >>> data.plot(kind='barh', ax=axes[1], color='k', alpha=0.7)
6 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F37F794A8>
7 >>> plt.show()
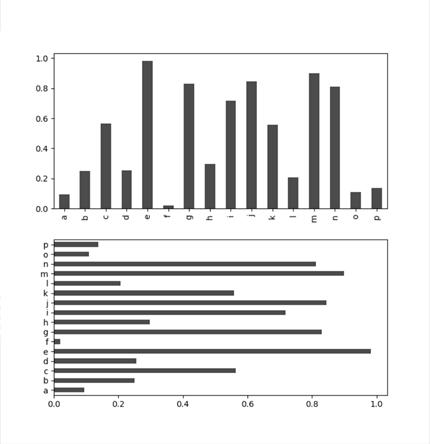
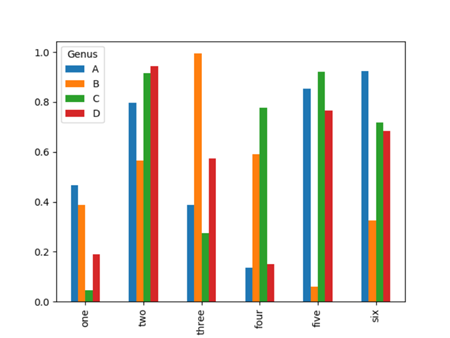
对于DataFrame,柱状图会将每一行的值分为一组。
1 >>> df = pd.DataFrame(np.random.rand(6, 4), index=['one', 'two', 'three', 'four', 'five', 'six'], columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
2 >>> df
3 Genus A B C D
4 one 0.466419 0.388390 0.045920 0.188829
5 two 0.795635 0.566636 0.916473 0.944628
6 three 0.386224 0.993829 0.273204 0.573622
7 four 0.134991 0.591803 0.778073 0.150384
8 five 0.854561 0.058758 0.922147 0.764897
9 six 0.923109 0.324739 0.717597 0.682992
10 >>> df.plot(kind='bar')
11 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F37FB1F28>
12 >>> plt.show()
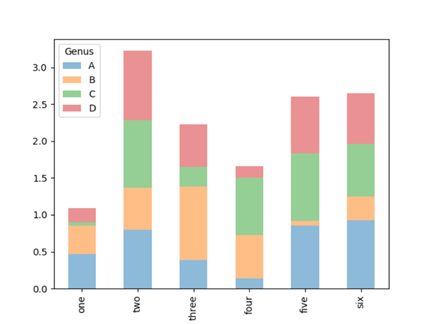
设置stacked=True即可生成堆积柱状图,每行的值会被堆积在一起。
1 >>> df.plot(kind='bar', stacked=True, alpha=0.5)
2 <matplotlib.axes._subplots.AxesSubplot object at 0x0000024F3A2F2048>
3 >>> plt.show()
2.3 直方图和密度图
直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。
1 >>> s
2 0 -0.674014
3 1 0.342018
4 2 -0.189962
5 3 0.528294
6 4 1.597546
7 5 1.530765
8 6 2.699712
9 7 1.422388
10 8 -1.295660
11 9 -1.539913
12 dtype: float64
13 >>> s.hist(bins=5)
14 <matplotlib.axes._subplots.AxesSubplot object at 0x000002295B737978>
15 >>> plt.show()
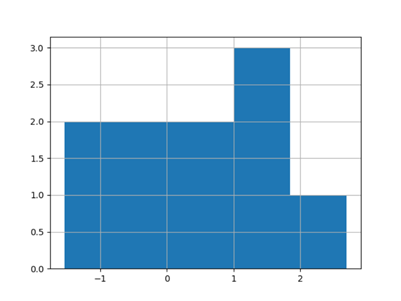
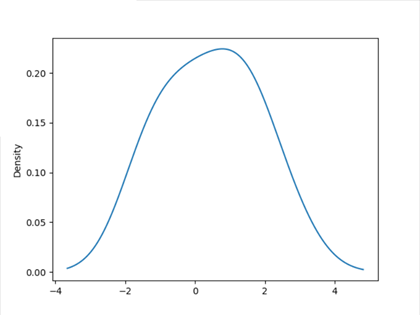
与此相关的一种图表类型是密度图,它是通过计算“可能产生观测数据的连续概率分布的估计”而产生的。一般的过程是将该部分近似为一组核(即诸如正态(高斯)分布之类的较为简单的分布)。因此,密度图也被称为KDE(kernel density estimate核密度估计)图。调用plot时加上kind=’kde’即可生成一张密度图(标准混合正态分布KDE)。
1 >>> import scipy
2 >>> s.plot(kind='kde')
3 <matplotlib.axes._subplots.AxesSubplot object at 0x0000022959D0DA90>
4 >>> plt.show()
5 >>> s
6 0 -0.674014
7 1 0.342018
8 2 -0.189962
9 3 0.528294
10 4 1.597546
11 5 1.530765
12 6 2.699712
13 7 1.422388
14 8 -1.295660
15 9 -1.539913
16 dtype: float64
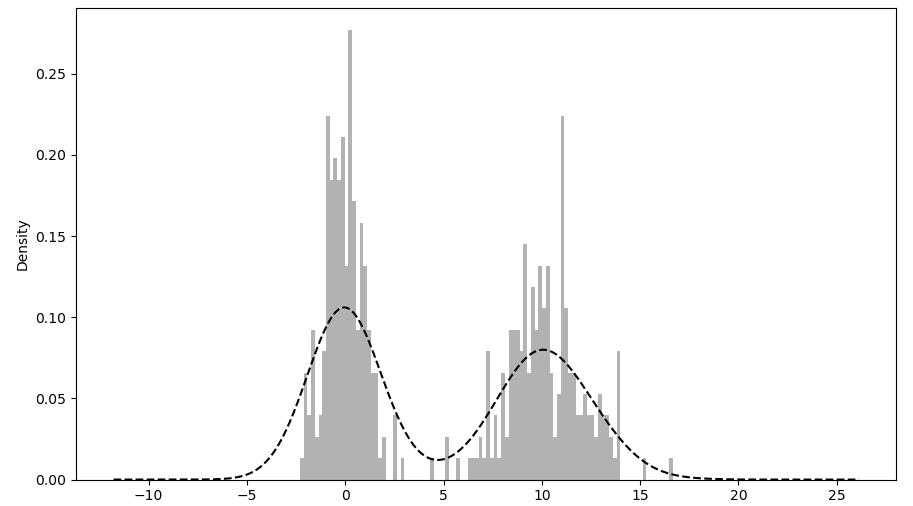
这两种图形常常画在一起,直方图以规格化形式给出(以便给出画元化密度),然后再在其上绘制核密度估计。下面给一个由两个不同的标准正态分布组成的双峰分布。
1 >>> comp1 = np.random.normal(0, 1, size=200)
2 >>> comp2 = np.random.normal(10, 2, size=200)
3 >>> values = pd.Series(np.concatenate([comp1, comp2]))
4 >>> values.hist(bins=100, alpha=0.3, color='k', density=True)
5 <matplotlib.axes._subplots.AxesSubplot object at 0x0000022959CFC6D8>
6 >>> values.plot(kind='kde', style='k--')
7 <matplotlib.axes._subplots.AxesSubplot object at 0x0000022959CFC6D8>
8 >>> plt.show()
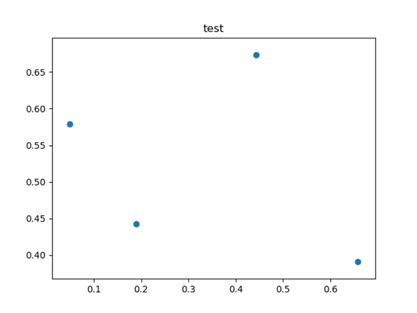
2.4 散布图
散布图(scatter plot)是观察两个一维数据序列之间关系的有效手段,matplotlib的scatter方法是绘制散布图的主要方法。
1 >>> df = pd.DataFrame(np.random.rand(4, 2), index=[1, 2, 3, 4], columns=['one', 'two'])
2 >>> df
3 one two
4 1 0.658181 0.390797
5 2 0.443482 0.673915
6 3 0.188783 0.442284
7 4 0.048783 0.578914
8 >>> plt.scatter(df['one'], df['two'])
9 <matplotlib.collections.PathCollection object at 0x000002295D2D77B8>
10 >>> plt.title('test')
11 Text(0.5, 1.0, 'test')
12 >>> plt.show()
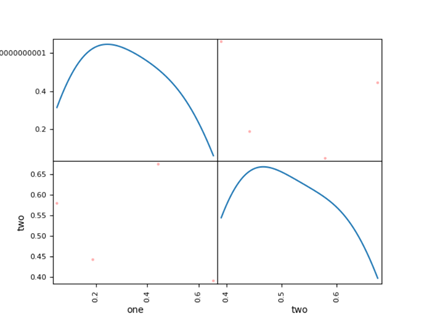
在探索式数据分析中,同时观察一组变量的散布图很有意义,这也被称为散布矩阵(scatter plot matrix)。pandas提供了从DataFrame创建散布图矩阵的scatter_matrix函数。还支持在对角线上放置各变量的直方图和密度图。
1 >>> df
2 one two
3 1 0.658181 0.390797
4 2 0.443482 0.673915
5 3 0.188783 0.442284
6 4 0.048783 0.578914
7 >>> pd.plotting.scatter_matrix(df, diagonal='kde', color='r', alpha=0.3)
8 array([[<matplotlib.axes._subplots.AxesSubplot object at 0x000002295D23D860>,
9 <matplotlib.axes._subplots.AxesSubplot object at 0x000002295D1A4940>],
10 [<matplotlib.axes._subplots.AxesSubplot object at 0x000002295D09EEF0>,
11 <matplotlib.axes._subplots.AxesSubplot object at 0x000002295D0DC4E0>]],
12 dtype=object)
13 >>> plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号