pandas rank()函数简介
本文简单的说一下自己对pandas的rank()函数的简单讲解。
函数原型:rank(axis=0, method: str = 'average', numeric_only: Union[bool, NoneType] = None, na_option: str = 'keep', ascending: bool = True, pct: bool = False)
官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.rank.html
《使用python进行数据分析》一书中的解释为:rank是通过“为各组分配一个平均排名”的方式破坏平级关系的。pandas排名会增加一个排名值(从1开始,一直到数组中有效数据的数量)。但是还是不好理解,我简单的做了一个图片来说明。
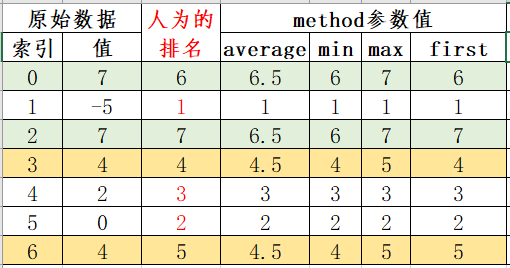
假设创建了一个Series对象obj = Series([7, -5, 7, 4, 2, 0, 4]),就是上图中”索引“和”值“这两列,我们人为的按照值的大小进行了一个排名,并且产生了一个序列(”人为的排名“)这一列,关于有两个索引(0和2)的值都是7的这种情况的排名的规则是,首先出现的值排名靠前。
下面就来说一下method参数的作用。
- 若为”average“,不相同的值,排名就取”人为的排名“的排名值,相同值的,排名需要求平均值,例如:索引0和2的值都为7,则平均值为(7+6)/2=6.5;
- 若为”min“,不相同的值,排名就取”人为的排名“的排名值,相同值的,排名取最小值,例如:索引0和2的值都为7,则排名都取6;
- 若为”max“,不相同的值,排名就取”人为的排名“的排名值,相同值的,排名取最大值,例如:索引0和2的值都为7,则排名都取7;
- 若为”first“,则就取”人为的排名“这列的值。
|
method |
说明 |
|
‘average’ |
默认,在相等分组中,为各个值分配平均排名 |
|
‘min’ |
使用整个分组的最小排名 |
|
‘max’ |
使用整个分组的最大排名 |
|
‘first’ |
按值在原始数据中出现顺序分配排名 |
关于”first“参数值的解释”值在原始数据中出现顺序“的解释如下:从1开始排序,若序列中出现了相同的值,则首先出现的值排名靠前。
下面进行测试:
(1)method='average'
1 >>> obj 2 0 7 3 1 -5 4 2 7 5 3 4 6 4 2 7 5 0 8 6 4 9 dtype: int64 10 >>> obj.rank( method='average') 11 0 6.5 12 1 1.0 13 2 6.5 14 3 4.5 15 4 3.0 16 5 2.0 17 6 4.5 18 dtype: float64
(2)method='min'
1 >>> obj 2 0 7 3 1 -5 4 2 7 5 3 4 6 4 2 7 5 0 8 6 4 9 dtype: int64 10 >>> obj.rank( method='average') 11 0 6.5 12 1 1.0 13 2 6.5 14 3 4.5 15 4 3.0 16 5 2.0 17 6 4.5 18 dtype: float64
(3)method='max'
1 >>> obj 2 0 7 3 1 -5 4 2 7 5 3 4 6 4 2 7 5 0 8 6 4 9 dtype: int64 10 >>> obj.rank( method='max') 11 0 7.0 12 1 1.0 13 2 7.0 14 3 5.0 15 4 3.0 16 5 2.0 17 6 5.0 18 dtype: float64
(4)method='first'
1 >>> obj 2 0 7 3 1 -5 4 2 7 5 3 4 6 4 2 7 5 0 8 6 4 9 dtype: int64 10 >>> obj.rank( method='first') 11 0 6.0 12 1 1.0 13 2 7.0 14 3 4.0 15 4 3.0 16 5 2.0 17 6 5.0 18 dtype: float64

 浙公网安备 33010602011771号
浙公网安备 33010602011771号