


愚弄神经网络
愚弄神经网络
如果我们添加上VGG的全连接层,然后试图最大化某个指定类别的激活值呢?你会得到一张很像该类别的图片吗?让我们试试。
这种情况下我们的损失函数长这样:
layer_output = model.layers[-1].get_output() loss = K.mean(layer_output[:, output_index])
比方说我们来最大化输出下标为65的那个类,在ImageNet里,这个类是蛇。很快,我们的损失达到了0.999,即神经网络有99.9%的概率认为我们生成的图片是一条海蛇,它长这样:
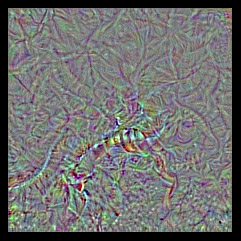
不太像呀,换个类别试试,这次选喜鹊类(第18类)

OK,我们的网络认为是喜鹊的东西看起来完全不是喜鹊,往好了说,这个图里跟喜鹊相似的,也不过就是一些局部的纹理,如羽毛,嘴巴之类的。那么,这就意味着卷积神经网络是个很差的工具吗?当然不是,我们按照一个特定任务来训练它,它就会在那个任务上表现的不错。但我们不能有网络“理解”某个概念的错觉。我们不能将网络人格化,它只是工具而已。比如一条狗,它能识别其为狗只是因为它能以很高的概率将其正确分类而已,而不代表它理解关于“狗”的任何外延。
革命尚未成功,同志仍需努力
所以,神经网络到底理解了什么呢?我认为有两件事是它们理解的。
其一,神经网络理解了如何将输入空间解耦为分层次的卷积滤波器组。其二,神经网络理解了从一系列滤波器的组合到一系列特定标签的概率映射。神经网络学习到的东西完全达不到人类的“看见”的意义,从科学的的角度讲,这当然也不意味着我们已经解决了计算机视觉的问题。想得别太多,我们才刚刚踩上计算机视觉天梯的第一步。
有些人说,卷积神经网络学习到的对输入空间的分层次解耦模拟了人类视觉皮层的行为。这种说法可能对也可能不对,但目前未知我们还没有比较强的证据来承认或否认它。当然,有些人可以期望人类的视觉皮层就是以类似的方式学东西的,某种程度上讲,这是对我们视觉世界的自然解耦(就像傅里叶变换是对周期声音信号的一种解耦一样自然)【译注:这里是说,就像声音信号的傅里叶变换表达了不同频率的声音信号这种很自然很物理的理解一样,我们可能会认为我们对视觉信息的识别就是分层来完成的,圆的是轮子,有四个轮子的是汽车,造型炫酷的汽车是跑车,像这样】。但是,人类对视觉信号的滤波、分层次、处理的本质很可能和我们弱鸡的卷积网络完全不是一回事。视觉皮层不是卷积的,尽管它们也分层,但那些层具有皮质列的结构,而这些结构的真正目的目前还不得而知,这种结构在我们的人工神经网络中还没有出现(尽管乔大帝Geoff Hinton正在在这个方面努力)。此外,人类有比给静态图像分类的感知器多得多的视觉感知器,这些感知器是连续而主动的,不是静态而被动的,这些感受器还被如眼动等多种机制复杂控制。
下次有风投或某知名CEO警告你要警惕我们深度学习的威胁时,想想上面说的吧。今天我们是有更好的工具来处理复杂的信息了,这很酷,但归根结底它们只是工具,而不是生物。它们做的任何工作在哪个宇宙的标准下都不够格称之为“思考”。在一个石头上画一个笑脸并不会使石头变得“开心”,尽管你的灵长目皮质会告诉你它很开心。
总而言之,卷积神经网络的可视化工作是很让人着迷的,谁能想到仅仅通过简单的梯度下降法和合理的损失函数,加上大规模的数据库,就能学到能很好解释复杂视觉信息的如此漂亮的分层模型呢。深度学习或许在实际的意义上并不智能,但它仍然能够达到几年前任何人都无法达到的效果。现在,如果我们能理解为什么深度学习如此有效,那……嘿嘿:)

