JMeter学习笔记-关联(正则表达式提取器)(三)
D. User Defined Variables:用户自定义的变量,在此我们可以定义后面原件需要引用的变量并对其进行赋值。jsessionid一般是服务器返回的,每个用户返回的都不一样,所以在此不应该固定这个值,但Badboy转换的脚本把jsessionid放到了此元件中,所以我们把它去除掉。
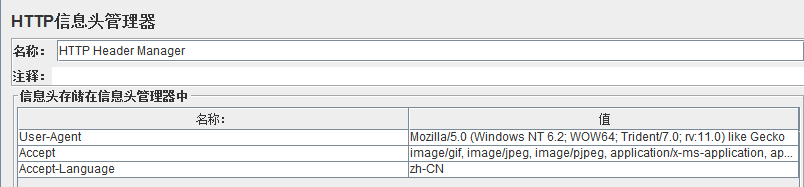
F. HTTP Header Manager:管理HTTP头信息,我们可以从中看到诸如User-Agent、Connection、content-type、Accept、Cookie、location302重定向地址等信息。
G. Step1:实际上这是一个循环控制器,可以在【逻辑控制器】下找到它,如图所示
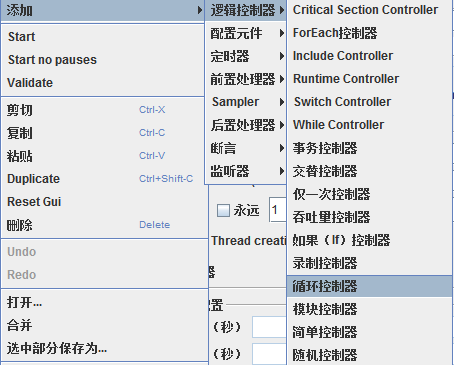
在此我们可以设置循环次数。
6.JMeter关联
正则表达式提取器
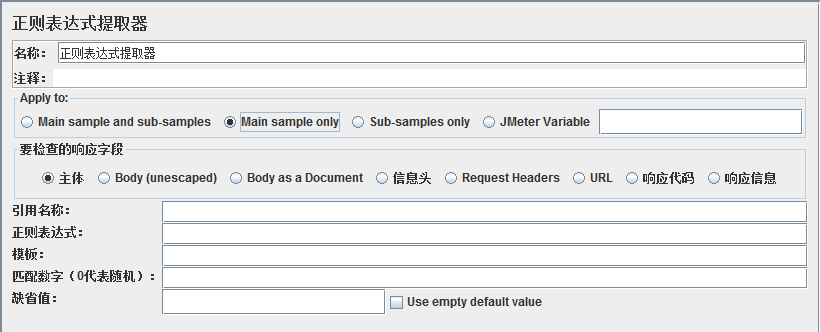
参数说明如下:
√ 名称:可以随意设置,最好有业务意义。
√ 注释:可以随意设置,可以为空。
√ Apply to:应用范围,四个选项。
√ Main sample and sub-samples:匹配范围包括当前父取样器并覆盖至子取样器。
√ Main sample only:匹配范围是当前父取样器。
√ JMeter Variable:支持对JMeter变量值进行匹配。
√ 要检查的响应字段:针对响应数据的不同部分进行匹配,共七个选项。
√ 主体:响应数据的主体部分,排除Header部分;HTTP协议返回请求的主体部分就是Body。
√ Body(unescaped):针对替换了转移码的Body部分。
√ Body as a Document:返回内容作为一个文档进行匹配。
√ 信息头:只匹配信息头部分的内容。
√ URL:只匹配URL链接。
√ 响应代码:匹配响应代码,比如HTTP协议返回码200代表成功。
√ 响应信息:匹配响应信息,比如处理成功返回“成功”字样,或者“OK”字样。
√ 引用名称:匹配出来的信息通过此名称进行访问,类似${引用名称}进行访问。
√ 正则表达式:正则表达式提取器使用此串进行信息匹配。
√ 模板:正则表达式可以设置多个模板进行匹配,在此只可制定运用哪个模板,模板自动编号,$1$指第一个模板,$2$指第二个模板,依次类推,$0$指全文匹配。
√ 匹配数字:在匹配时往往会出现多个值匹配的情况,如果匹配数为0则代表随机取匹配值;不同模板可能会匹配一组值,那么可以用匹配数字来确定取这一组值中的哪一个;负数取所有值,可以与For Each Controller一起使用来遍历。
√ 默认值:如果没有匹配到可以指定一个默认值。
7. JMeter参数化
CSV Data Set Config
CSV Data Set Config可以从指定的文件(一般是文本文件)中一行一行地提取文本内容,根据分隔符拆解这一行内容并把内容与变量名对应上,然后这些变量就可以供取样器引用了。
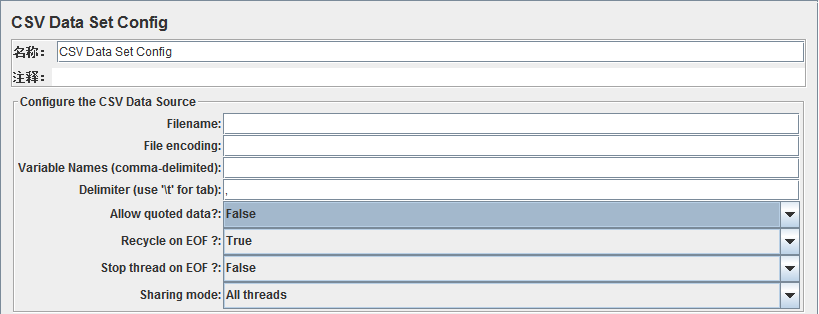
参数说明如下:
√ 名称:可以随意设置,最好有业务意义。
√ 注释:可以随意设置,可以为空。
√ Filename:引用文件地址,可以是相对路径也可以是绝对路径。相对路径的根节点是JMeter的启动目录(%JMETER_HOME%\bin)。
√ File encoding:读取参数文件用到的编码格式,建议使用UTF-8的格式保存参数文件。
√ Variable Names(comma-delimited):定义的参数名称,用逗号隔开,将会与参数文件中的参数对应,如果这里的参数个数比参数文件中的参数列多,多余的参数将取不到值;反之参数文件中不分列将没有参数对应。
√ Delimiter(use '\t' for tab):用来分割参数文件的分隔符,默认为都好,也可以用tab来分隔。
√ Allow quoted data? :是非选项,如果选择是,那么可以允许拆分完成的参数里面有分隔符出现。
√ Recycle on EOF?:是非选项,是,参数文件循环遍历;否,参数文件遍历完成后循环(JMeter在测试执行过程中每次迭代会从参数文件中新取一行数据,从头遍历到尾)。
√ Stop thread EOF?:与Recycle on EOF中的False选择服用;是,停止测试;否,不停止测试。
√ Sharing mode:参数文件共享模式,有以下三种:
All threads:参数文件对所有线程共享,这就包括同一测试计划中的不同线程组。
Current thread group:只对当前线程组中的线程共享。
Current thread:仅当前线程获取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号