JVM基础
1、JVM内存模型
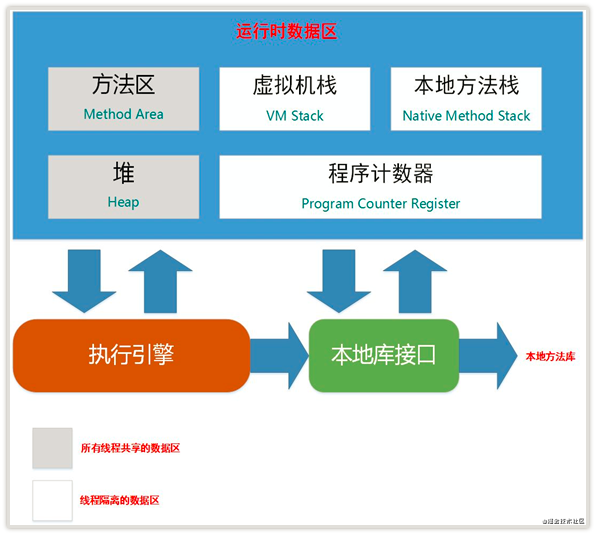
2、分区
JVM 内存区域主要分为线程私有区域【程序计数器、虚拟机栈、本地方法区】、线程共享区域【JAVA 堆、方法区】、直接内存。
2.1 程序计数器
一块较小的内存空间, 是当前线程所执行的字节码的行号指示器,每条线程都要有一个独立的程序计数器,这类内存也称为“线程私有”的内存。
正在执行 java 方法的话,计数器记录的是虚拟机字节码指令的地址(当前指令的地址)。如果还是 Native 方法,则为空。
这个内存区域是唯一一个在虚拟机中没有规定任何 OutOfMemoryError 情况的区域。
2.2 虚拟机栈
是描述 java 方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
2.3 本地方法区
本地方法区和 Java Stack 作用类似, 区别是虚拟机栈为执行 Java 方法服务, 而本地方法栈则为Native 方法服务, 如果一个 VM 实现使用 C-linkage 模型来支持 Native 调用, 那么该栈将会是一个C栈,但 HotSpot VM 直接就把本地方法栈和虚拟机栈合二为一。
2.4 堆-运行时数据区
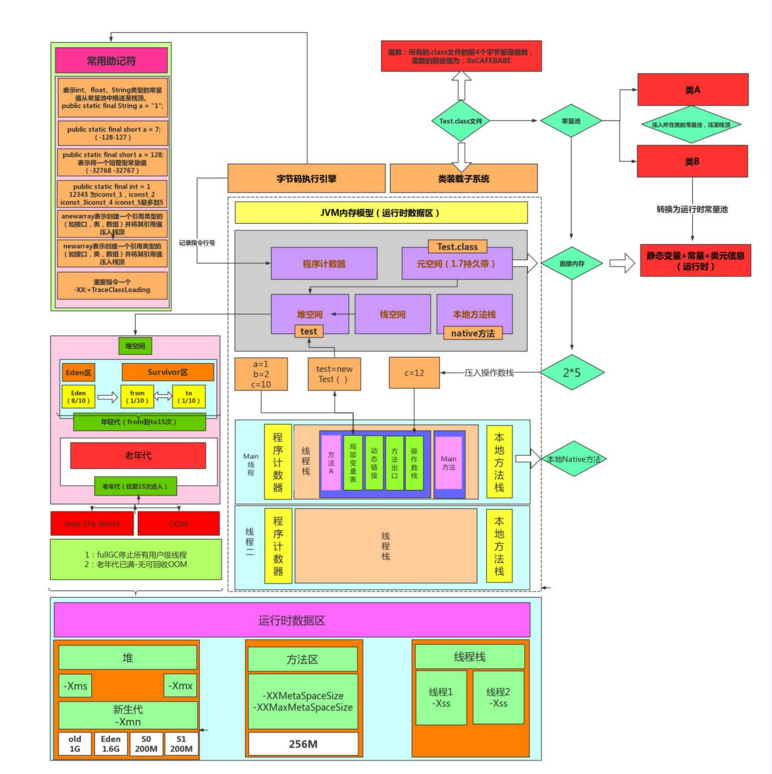
是被线程共享的一块内存区域,创建的对象和数组都保存在 Java 堆内存中,也是垃圾收集器进行垃圾收集的最重要的内存区域。由于现代 VM 采用分代收集算法, 因此 Java 堆从 GC 的角度还可以细分为: 新生代(Eden 区、From Survivor(S0) 区和 To Survivor (S1)区)和老年代。
2.5 方法区
即我们常说的永久代(Permanent Generation), 用于存储被 JVM 加载的类信息、常量、静态变量、即时编译器编译后的代码等数据. HotSpot VM把 GC分代收集扩展至方法区, 即使用Java堆的永久代来实现方法区, 这样 HotSpot 的垃圾收集器就可以像管理 Java 堆一样管理这部分内存, 而不必为方法区开发专门的内存管理器(永久带的内存回收的主要目标是针对常量池的回收和类型的卸载, 因此收益一般很小)。
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class 文件中除了有类的版
本、字段、方法、接口等描述等信息外,还有一项信息是常量池 。
1.7之后已经移除了永久代,而是元空间
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
3、JVM常用参数
查看jdk的jvm默认参数
java -XX:+PrintCommandLineFlags -version
-Xms :初始堆大小
-Xmx :最大堆大小
-XX:NewSize=n :设置年轻代大小
-XX:NewRatio=n :设置年轻代和年老代的比值.如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n :年轻代中Eden区与两个Survivor区的比值.注意Survivor区有两个.如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n :设置持久代大小
XX:+UnlockCommercialFeatures :启动飞行记录 -XX:+FlightRecorder
-Xss :线程堆栈大小,默认1M
-verbose:gc 发生gc时,打印gc相关信息,设置gc日志,等同-XX:+PrintGC
-XX:+PrintGCDetails : 打印gc日志详细信息
-XX:+PrintGCDateStamps :打印GC日志时间戳
-verbose:gc -Xloggc:E:\gc-log\gc.log : 生成gc日志
eg:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -verbose:gc -Xloggc:E:\gc-log\gc.log
-XX:+UseAdaptiveSizePolicy : UseParallelGC根据GC的情况自动计算计算 Eden、From 和 To 区的大小
-XX:+DisableExplicitGC :禁用System.gc()
-XX:+UseCompressedOops :开启(-XX:+UseCompressedOops) 可以压缩指针。 关闭(-XX:-UseCompressedOops) 可以关闭压缩指针。
-XX:+UnlockExperimentalVMOptions : 解锁实验参数,允许使用实验性参数
G1相关参数
-XX:+UseG1GC : 使用G1收集器
-XX:G1MixedGCLiveThresholdPercent=50 : 默认值是85%。规定只有存活对象低于85%的Region才可以被回收
-XX:G1HeapRegionSize=16 :使用G1收集器时,设置java堆被分割的大小
-XX:ParallelGCThreads=8 :配置并行收集器的线程数
-XX:ConcGCThreads=6 : 并发GC的线程数量
-XX:MaxGCPauseMillis=200 : 设置GC的最大暂停时间为200ms
配置G1收集器,修改最大暂停时间进行调优
-XX:+UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200 -Xmx32g 设置堆内存的最大内存为32G
-XX:MaxGCPauseMillis=200设置GC的最大暂停时间为200ms
4、GC的种类
- 新生代回收(Minor GC/Young GC):指只是进行新生代的回收。
- 老年代回收(Major GC/Old GC):指只是进行老年代的回收。
- 堆收集(Full GC):收集整个Java堆和方法区(注意包含方法区)。
5、垃圾回收算法
5.1 复制算法
将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
复制算法实现简单,运行高效,内存复制,没有内存碎片。但是其内存利用率只有一半。
复制回收算法适合于新生代,因为大部分对象朝生夕死,那么复制过去的对象比较少,效率自然就高,另外一半的一次性清理是很快的。
5.2 标记-清除算法
算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
回收效率不稳定,如果大部分对象是朝生夕死,那么回收效率降低,因为需要大量标记对象和回收对象,对比复制回收效率很低。
标记清除之后会产生大量不连续的内存碎片。
回收的时候如果需要回收的对象越多,需要做的标记和清除的工作越多,所以标记清除算法适用于老年代。
5.3 标记-整理算法
首先标记出所有需要回收的对象,在标记完成后,后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。标记整理算法虽然没有内存碎片,但是效率偏低。
标记整理与标记清除算法的区别主要在于对象的移动。对象移动不单单会加重系统负担,同时需要全程暂停用户线程才能进行,同时所有引用对象的地方都需要更新。
5.4分代收集
新生代复制算法,老年代以标记整理算法为主。
6、垃圾收集器
6.1 Serial(串行)收集器
在jdk1.3.1之前,java虚拟机仅仅能使用Serial收集器。 Serial收集器是一个单线程的收集器,但它的“单线程”的意义并不仅仅是说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。
PS:开启Serial收集器的方式
-XX:+UseSerialGC
6.2 Parallel(并行)收集器
Parallel收集器也称吞吐量收集器,相比Serial收集器,Parallel最主要的优势在于使用多线程去完成垃圾清理工作,这样可以充分利用多核的特性,大幅降低gc时间。
PS:开启Parallel收集器的方式
-XX:+UseParallelGC -XX:+UseParallelOldGC
6.3 CMS(并发)收集器
MS收集器在Minor GC时会暂停所有的应用线程,并以多线程的方式进行垃圾回收。在Full GC时不再暂停应用线程,而是使用若干个后台线程定期的对老年代空间进行扫描,及时回收其中不再使用的对象。
PS:开启CMS收集器的方式
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
6.4 G1(并发)收集器
G1收集器(或者垃圾优先收集器)的设计初衷是为了尽量缩短处理超大堆(大于4GB)时产生的停顿。相对于CMS的优势而言是内存碎片的产生率大大降低。
G1将老年代新生代物理空间划分取消了,这样我们再也不用单独的空间对每个代进行设置了,不用担心每个代内存是否足够。
PS:开启G1收集器的方式
-XX:+UseG1GC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号