20172327 2018-2019-1 《程序设计与数据结构》第五周学习总结
20172327 2018-2019-1 《程序设计与数据结构》第五周学习总结
教材学习内容总结
第九章 排序与查找
| 查找 |
1.查找:在某个项目组中找到指定元素或判断是否存在。该项目组被称为查找池。
2.常见查找方式,线性查找。
3.查找目标:高效地完成查找,用最小化比较操作。通常查找池中项目数目定义了该问题的大小。
4.静态方法(类方法):可通过类名激活
5.在方法声明中,通过static修饰符就可以把它声明为静态的。
6.泛型方法:与泛型类相似,不是创建引用泛型参数的类,而是创建一个引用泛型的方法。
7.线性查找:从表头开始依次比较每个值,直到找到该目标元素。
8.二分查找将利用查池已是排序的这一事实,每次比较都会删除一半的可行候选项。
9.线性查找时间复杂度是O(n),二分查找时间复杂度为log2n,所以n值较大时,二分查找要快的多。
| 排序 |
1.排序:基于某一标准,升序或者降序将某一组项目按照某个规定顺序排列。
2.基于效率排序算法通常也分为两类:顺序排序(使用一个嵌套循环对n个元素排序,大约有N^2次比较),对数排序(对n个元素进行排序,通常大约需要nlog2n次)
3.顺序排序:选择排序,插入排序,冒泡排序
4.对数排序:快速排序,归并排序
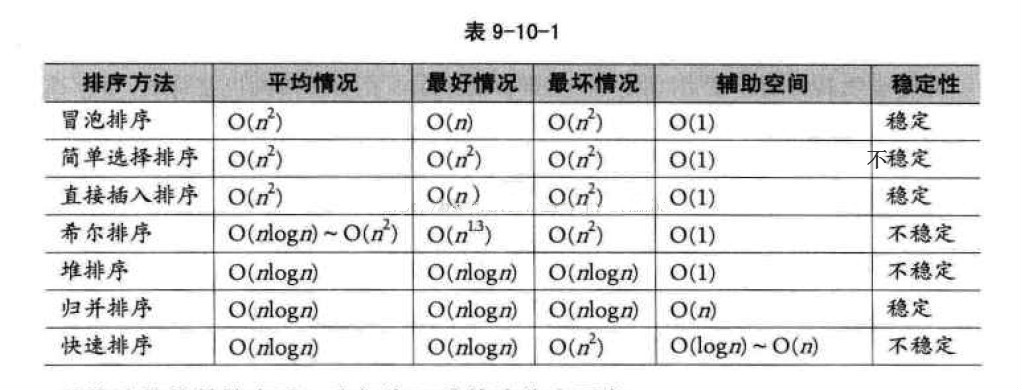
5.选择排序法:
-
初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列;然后,再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
-
selectionSort方法实现两个循环,外层循环控制下一个最小值存储在那个位置,内层循环通过扫描所有大于等于外层循环指定索引的位置来找出剩余列表的最小值。
-
序列{ 8, 5, 2, 6, 9, 3, 1, 4, 0, 7 }进行选择排序的实现过程:
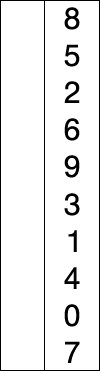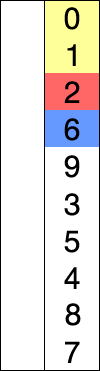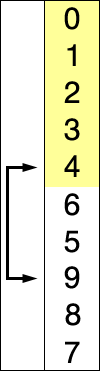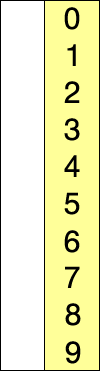
-
宏观图:

6.插入排序法:
-
插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
-
insertionSort方法使用了两个循环来对某个对象数组进行排序,外层循环控制下一个插入值在数组中的索引,内层循环将前插入值和储存在更小索引处的值进行比较。
-
插入排序算法运作如下:
1.从第一个元素开始,该元素可以认为已经被排序
2.取出下一个元素,在已经排序的元素序列中从后向前扫描
3.如果该元素(已排序)大于新元素,将该元素移到下一位置
4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5.将新元素插入到该位置后
6.重复步骤2~5 -
序列{ 6, 5, 3, 1, 8, 7, 2, 4 }进行插入排序的实现过程如下:
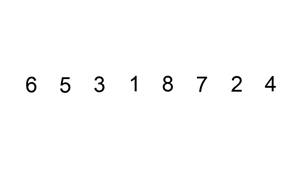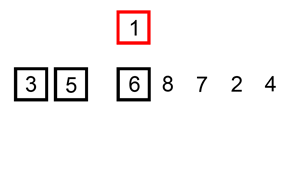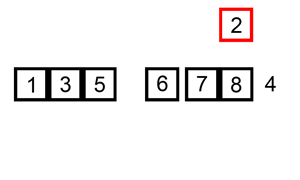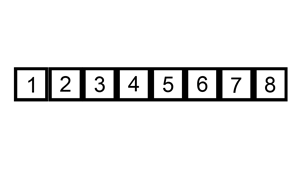
-
宏观图:

7.冒泡排序法:
- 它重复地走访过要排序的元素,依次比较相邻两个元素,如果他们的顺序错误就把他们调换过来,直到没有元素再需要交换,排序完成。这个算法的名字由来是因为越小(或越大)的元素会经由交换慢慢“浮”到数列的顶端。
- bubbleSort方法中的外层for循环表示n-1轮数据遍历,内层for循环将从头至尾扫描该数据,对相邻数据进行成对比较,如果必要将其交换。
- 冒泡排序算法的运作如下:
1.比较相邻的元素,如果前一个比后一个大,就把它们两个调换位置。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
序列{ 6, 5, 3, 1, 8, 7, 2, 4 }进行冒泡排序的实现过程如下: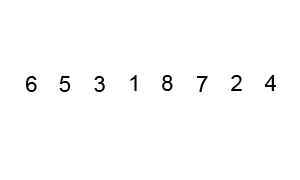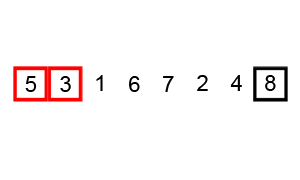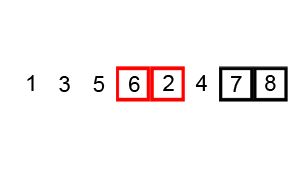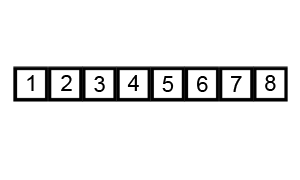
宏观: 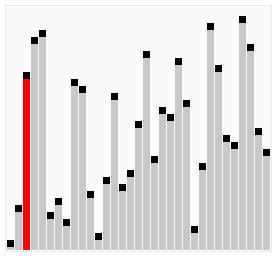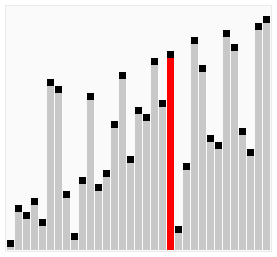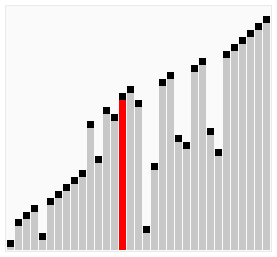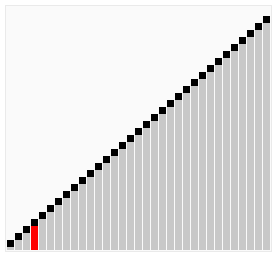
8.快速排序法:
- 快速排序算法通过将列表分区,然后对这两个分区进行递归式排序,从而完成对整个列表的排序。
- quicksort方法非常依赖partition方法,起初用其将排序区域分开。partition方法的两个内层while循环用于寻找位于错误分区的交换元素。第一个循环从左边扫描到右边,以寻找大于分区元素的元素,第二个循环从右边扫描到左边,以寻找小于分区元素的元素。
- 快速排序算法的运作过程:
1.从序列中挑出个一元素,作为"基准"(pivot).
2.把所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准的后面(相同的数可以到任一边),这个称为分区(partition)操作。
3.对每个分区递归地进行步骤1~2,递归的结束条件是序列的大小是0或1,这时整体已经被排好序了。
序列:{ 1, 3, 4, 2, 8, 9, 8, 7, 5},基准元素是5,一次划分操作后5要和第一个8进行交换,从而改变了两个元素8
的相对次序。
宏观: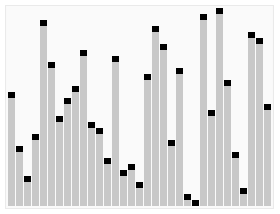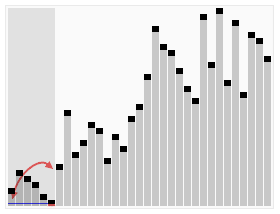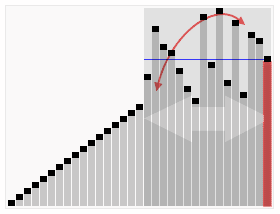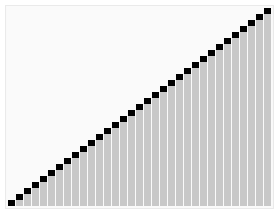
9.归并排序法:
- 归并排序算法通过将列表递归式分成两半直至每个子列表都含有一个元素,然后将这些子列表归并到一个排序顺序中,从而完成对列表的排序。
- 归并排序的实现分为递归实现与非递归(迭代)实现。递归实现的归并排序是算法设计中分治策略的典型应用,我们将一个大问题分割成小问题分别解决,然后用所有小问题的答案来解决整个大问题。非递归(迭代)实现的归并排序首先进行是两两归并,然后四四归并,然后是八八归并,一直下去直到归并了整个数组。
- 归并排序法运作如下:
1.申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
2.设定两个指针,最初位置分别为两个已经排序序列的起始位置
3.比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
4.重复步骤3直到某一指针到达序列尾
5.将另一序列剩下的所有元素直接复制到合并序列尾
序列{ 6, 5, 3, 1, 8, 7, 2, 4 }进行归并排序的实例如下: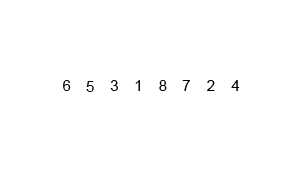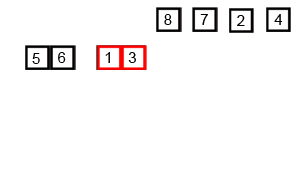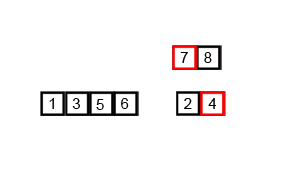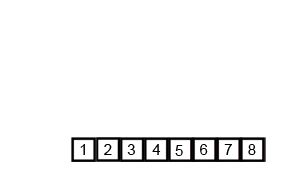
宏观: 
| 基数排序法 |
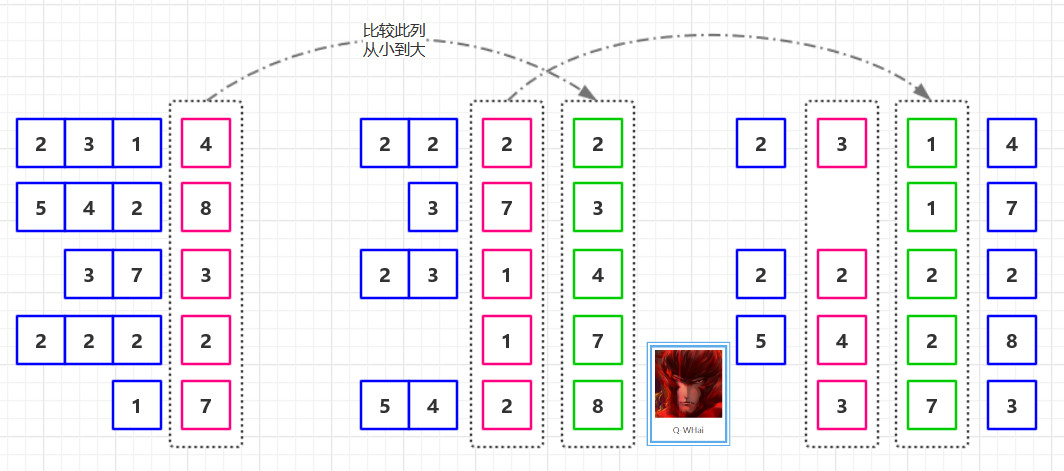
1.将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零. 然后, 从最低位开始, 依次进行一次排序.这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列.
2.如果我们的无序是 T = [ 2314, 5428, 373, 2222, 17 ],那么其排序的过程就如下两幅所示。
基数排序过程图-1 :
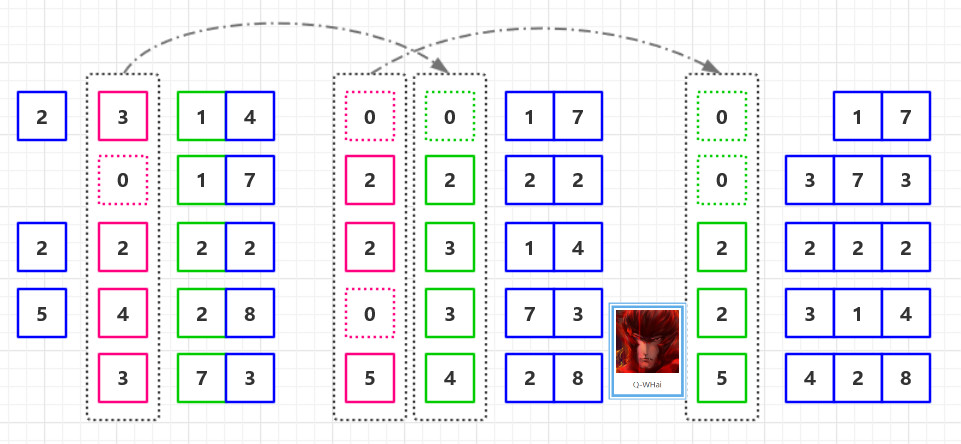
教材学习中的问题和解决过程
-
问题1:在静态方法那一节,有一个实例变量,我不太了解这是什么意思?
-
问题解决和分析:实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部,但在类的其他成员方法之外声明的。类的每个对象维护它自己的一份实例变量的副本。
-
问题2:@SuppressWarnings是啥,怎么用。
-
问题解决和分析:
1.指示应该在注释元素(以及包含在该注释元素中的所有程序元素)中取消显示指定的编译器警告。注意,在给定元素中取消显示的警告集是所有包含元素中取消显示的警告的超集。例如,如果注释一个类来取消显示某个警告,同时注释一个方法来取消显示另一个警告,那么将在此方法中同时取消显示这两个警告。
2.根据风格不同,程序员应该始终在最里层的嵌套元素上使用此注释,在那里使用才有效。如果要在特定的方法中取消显示某个警告,则应该注释该方法而不是注释它的类。
代码调试中的问题和解决过程
-
问题1:在实现pp9.3sorting类改编时,我对于归并排序和快速排序的循环次数的计算感觉到很迷茫,我不知道该如何计算。
-
解决分析:
通过对同学方法的研究,我觉得有两种方法可以解决,一种是直接
public static <T extends Comparable<T>>
void mergeSort(T[] data)
{
times = times2 = 0;
long startTime=System.nanoTime();
mergeSort(data, 0, data.length - 1);
long endTime = System.nanoTime();
long temp = times + times2;
System.out.println("程序运行时间:" + (endTime - startTime) + "ns");
System.out.println("比较次数为:"+ temp);
}
private static int times;
private static <T extends Comparable<T>>
void mergeSort(T[] data, int min, int max)
{
if (min < max)
{
times++;
int mid = (min + max) / 2;
mergeSort(data, min, mid);
mergeSort(data, mid+1, max);
merge(data, min, mid, max);
}
}
通过引入times,来在循环中通过计算最后times相加的和。
还有一种是:
public static <T extends Comparable<T>>
void mergeSort(T[] data)
{
int count=0;
long startTime = System.nanoTime();//获取开始的时间;
count = mergeSort(data, 0, data.length - 1);
long endTime = System.nanoTime();//获取结束的时间;
System.out.println("程序所需时间:"+ (endTime - startTime) + "ns");
System.out.println("比较次数:"+ count);
}
private static <T extends Comparable<T>>
int mergeSort(T[] data, int min, int max)
{
int count = 0;
if (min < max)
{
int mid = (min + max) / 2;
mergeSort(data, min, mid);
mergeSort(data, mid+1, max);
merge(data, min, mid, max);
}
return count;
}
通过对下边类改成有返回值的类,将count返回。
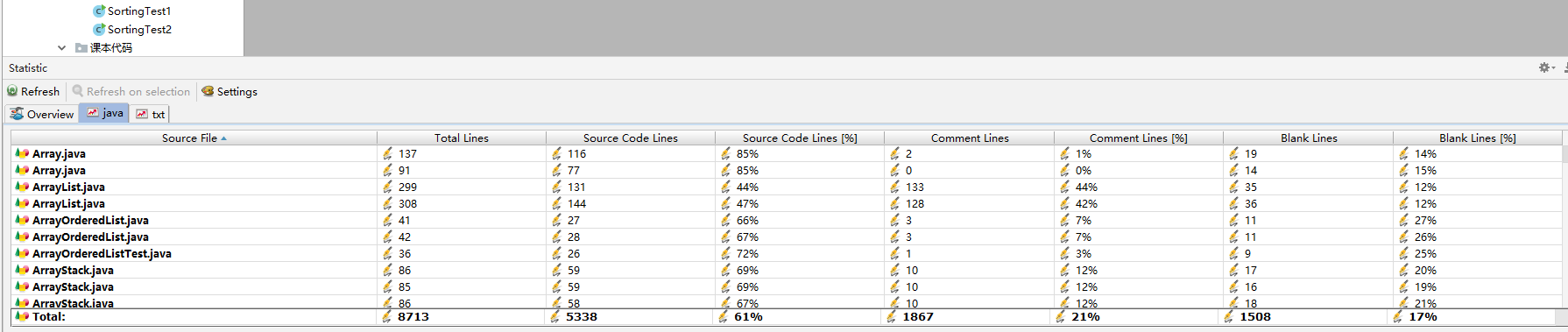
代码托管
结对及互评
正确使用Markdown语法(加1分)
模板中的要素齐全(加1分)
教材学习中的问题和解决过程, (加3分)
代码调试中的问题和解决过程, 无问题
感想,体会真切的(加1分)
点评认真,能指出博客和代码中的问题的(加1分)
-
20172317
基于评分标准,我给以上博客打分:2分。得分情况如下: -
20172320
基于评分标准,我给以上博客打分:8分。得分情况如下:- 结对学习内容
- 教材第9章,运行教材上的代码
- 完成课后自测题,并参考答案学习
- 完成课后自测题,并参考答案学习
- 完成程序设计项目:至少完成PP9.2、PP9.3
- 结对学习内容
其他(感悟、思考等,可选)
这周将排序全学了一遍,感觉有些理解起来还好,写起来也还算好些,但是有些知道它运行的流程但代码实现做不到,这就让人很着急。我还会再看看代码,将二分法实现的归并排序,快速排序以及基数排序再多研究一下,把不懂的搞懂。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 8/8 | |
| 第二周 | 1306/1306 | 1/2 | 20/28 | |
| 第三周 | 1291/2597 | 1/3 | 18/46 | |
| 第四周 | 4361/6958 | 2/5 | 20/66 | |
| 第五周 | 1755/8713 | 1/6 | 20/86 |
-
计划学习时间:10小时
-
实际学习时间:8小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号