20172327-哈夫曼编码测试
20172327-哈夫曼编码测试
哈夫曼编码与哈夫曼树
- 哈夫曼编码:又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
- 哈夫曼树:给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
哈夫曼编码步骤
下面我们以【5、8、4、11、9、13】为例来画出哈夫曼树(数字大小代表权重大小,越大的权重越大)
- 第一步:按从小到大排序。
【5、8、4、11、9、13】→【4、5、8、9、11、13】
- 第二步:选最小两个数画出一个树,最小数为4和5。
给定的4、5、8、9、11、13为白色, 红色的9为4+5,与给定的白9无关,新序列为:【红9(含子节点4、5)、8、9、11、13】

- 之后一直重复第一、第二步:排序然后取两个最小值。实际就是一个递归过程
排序:

-
取两个最小数8和9:

-
排序:
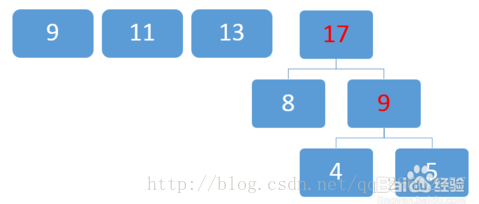
-
取两个最小数9和11:
-
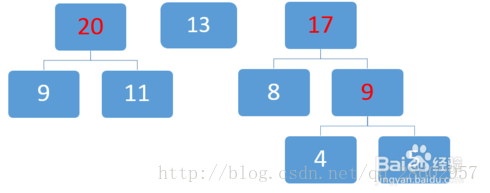
排序,然后取两个最小数13和17:
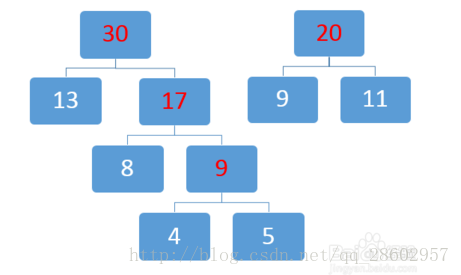
取两个最小数20和30:

哈夫曼编码主要用途
哈夫曼研究这种最优树的目的是为了解决当年远距离通信(主要是电报)的数据传输的最优化问题。
比如我们有一段文字“BADCADFEED”,显然用二进制数字(0和1)表示是很自然的想法。

这样真正传输的数据就是“001000011010000011101100100011”,对方接收时同样按照3位一组解码。如果一篇文章很长,这样的二进制串也非常的可怕。而且事实上,每个字母或者汉子的出现频率是不同的。
假设六个字母的频率为A 27,B 8, C 15, D 15 , E 30, F 5,合起来正好是100%,那就意味着我们完全可以用哈夫曼树来规划它们。
左图为构造哈夫曼树的过程的权值显示。右图为将权值左分支改为0,右分支改为1后的哈夫曼树。
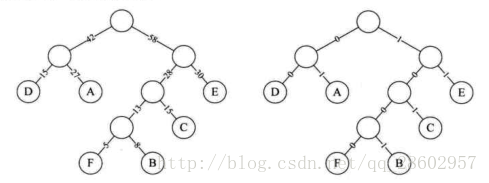
我们对这六个字母用其从树根到叶子所经过的路径的0或1来编码,可以得到下表:


也就是说我们的数据被压缩了,节约了大概17%的存储或传输成本。随着字符的增加和多字符权重的不同,这种压缩会更显出优势来。
实验内容
哈夫曼编码测试
设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
(1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
(2)构造哈夫曼树
(3)对英文文件进行编码,输出一个编码后的文件
(4)对编码文件进行解码,输出一个解码后的文件
(5)撰写博客记录实验的设计和实现过程,并将源代码传到码云
(6)把实验结果截图上传到云班课
满分:6分。
酌情打分。
重点代码
构造哈夫曼树:
public static HuffmanNode createTree(List<HuffmanNode> nodes) {
// 只要nodes数组中还有2个以上的节点
while (nodes.size() > 1)
{
quickSort(nodes);
//获取权值最小的两个节点
HuffmanNode left = nodes.get(nodes.size()-1);
left.setCodeNumber(0+"");
HuffmanNode right = nodes.get(nodes.size()-2);
right.setCodeNumber(1+"");
//生成新节点,新节点的权值为两个子节点的权值之和
HuffmanNode parent = new HuffmanNode(null, left.weight + right.weight);
//让新节点作为两个权值最小节点的父节点
parent.leftChild = left;
parent.rightChild = right;
//删除权值最小的两个节点
nodes.remove(nodes.size()-1);
nodes.remove(nodes.size()-1);
//将新节点加入到集合中
nodes.add(parent);
}
return nodes.get(0);
}
/**
* 将指定集合中的i和j索引处的元素交换
*
* @param nodes
* @param i
* @param j
*/
private static void swap(List<HuffmanNode> nodes, int i, int j) {
HuffmanNode tmp;
tmp = nodes.get(i);
nodes.set(i, nodes.get(j));
nodes.set(j, tmp);
}
/**
* 实现快速排序算法,用于对节点进行排序
* @param nodes
* @param start
* @param end
*/
private static void subSort(List<HuffmanNode> nodes, int start, int end)
{
if (start < end)
{
// 以第一个元素作为分界值
HuffmanNode base = nodes.get(start);
// i从左边搜索,搜索大于分界值的元素的索引
int i = start;
// j从右边开始搜索,搜索小于分界值的元素的索引
int j = end + 1;
while (true)
{
// 找到大于分界值的元素的索引,或者i已经到了end处
while (i < end && nodes.get(++i).weight >= base.weight);
// 找到小于分界值的元素的索引,或者j已经到了start处
while (j > start && nodes.get(--j).weight <= base.weight);
if (i < j)
{
swap(nodes, i, j);
}
else
break;
}
swap(nodes, start, j);
//递归左边子序列
subSort(nodes, start, j - 1);
//递归右边子序列
subSort(nodes, j + 1, end);
}
}
public static void quickSort(List<HuffmanNode> nodes)
{
subSort(nodes, 0, nodes.size()-1);
}
//层序遍历
public static List<HuffmanNode> levelTraversal(HuffmanNode root)
{
Queue<HuffmanNode> queue = new ArrayDeque<HuffmanNode>();
List<HuffmanNode> list = new ArrayList<HuffmanNode>();
if(root!=null)
{
//将根元素加入“队列”
queue.offer(root);
root.leftChild.setCodeNumber(root.getCodeNumber()+"0");
root.rightChild.setCodeNumber(root.getCodeNumber()+"1");
}
while(!queue.isEmpty())
{
//将该队列的“队尾”元素加入到list中
list.add(queue.peek());
HuffmanNode tree = queue.poll();
//如果左子节点不为null,将它加入到队列
if(tree.leftChild != null)
{
queue.offer(tree.leftChild);
tree.leftChild.setCodeNumber(tree.getCodeNumber()+"0");
}
//如果右子节点不为null,将它加入到队列
if(tree.rightChild != null)
{
queue.offer(tree.rightChild);
tree.rightChild.setCodeNumber(tree.getCodeNumber()+"1");
}
}
return list;
}
计算字母出现次数:
//层序遍历显示构建的哈弗曼树
char[] chars = new char[a];
int[] times = new int[a];
Iterator<Character> pl2 = counter.keySet().iterator();
for (int i=0;i<=a;i++ )
{
if (pl2.hasNext())
{
chars[i] = pl2.next();
times[i] = counter.get(chars[i]);
}
}
List<HuffmanNode> list = new ArrayList<HuffmanNode>();
for(int i = 0;i<a;i++)
{
System.out.print(chars[i]+"出现次数为:"+times[i]+" \n");
list.add(new HuffmanNode(chars[i]+"",times[i]));
}
读取文件:
File file = new File("E:\\IDES_Project\\JSSD\\src\\HaffmanCoding\\test.txt");
if (!file.exists()) {
throw new Exception("文件不存在");
}
BufferedReader fin = new BufferedReader(new FileReader(file));
String line;
Map<Character, Integer> counter = new HashMap<Character, Integer>();
int total=0;
while ((line = fin.readLine()) != null)
{
int len = line.length();
for (int i = 0; i < len; i++)
{
char c = line.charAt(i);
if (( (c >= 'a' && c <= 'z'&& c == ' ')))
{
continue;
}
if (counter.containsKey(c))
{
counter.put(c, counter.get(c) + 1);
}
else
{
counter.put(c, 1);
}
}
}
fin.close();
实验结果截图
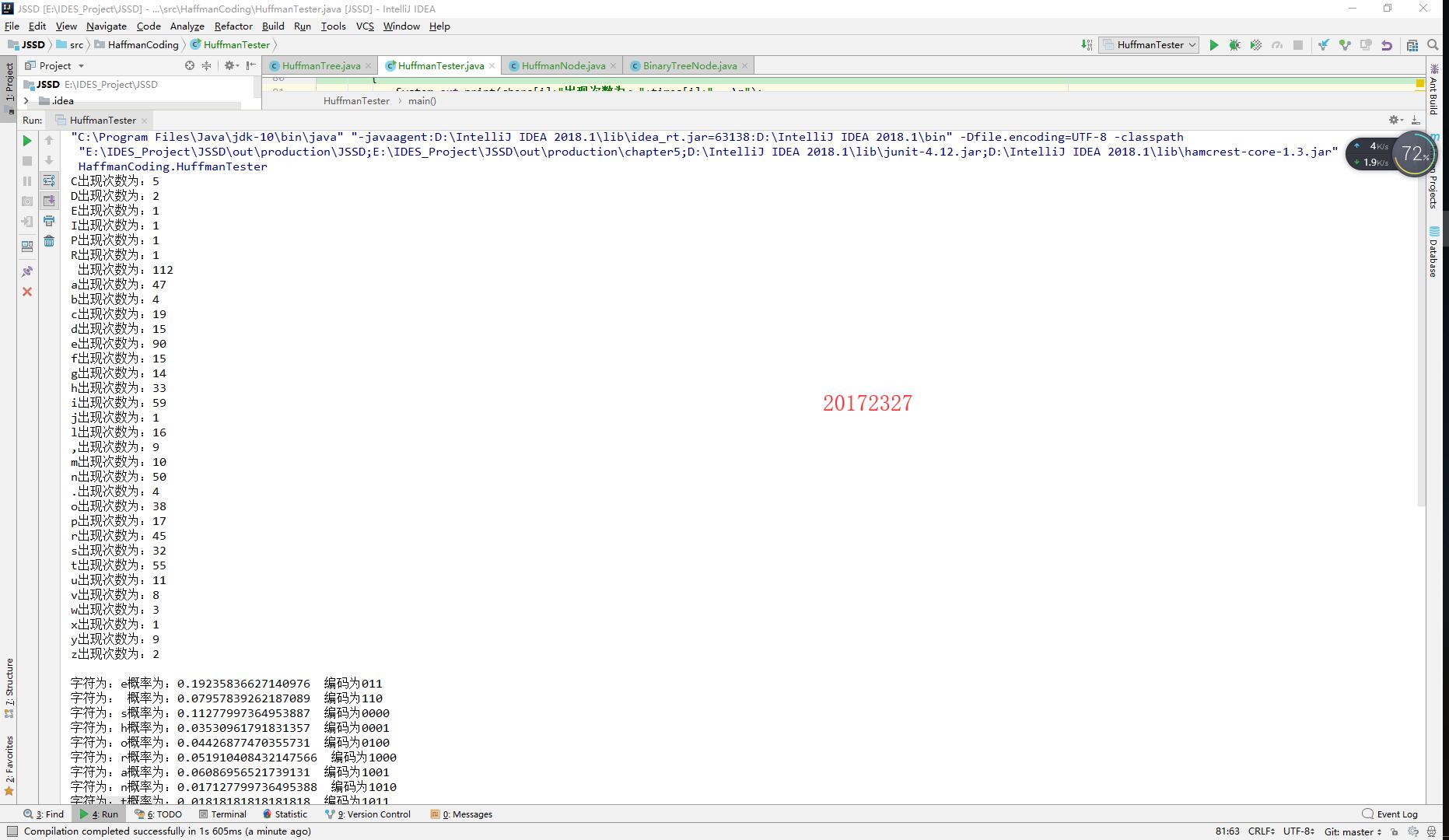
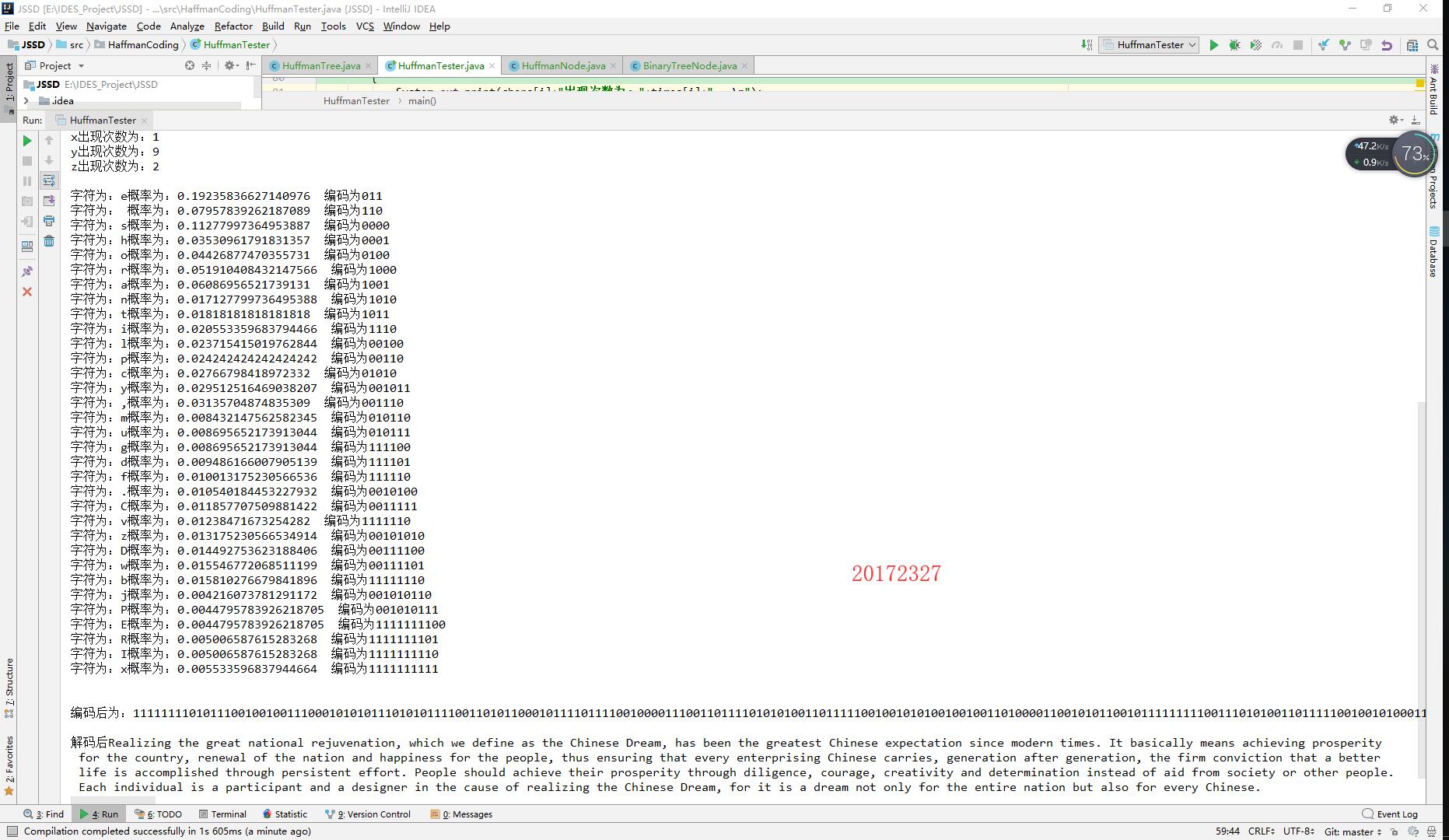
码云链接
感悟
这次实验给人的感觉有点难,不是很懂,所以写起来很迷。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号