scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
前言
经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo。这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程。
工具和环境
- 语言:python 2.7
- IDE: Pycharm
- 浏览器:Chrome
- 爬虫框架:Scrapy 1.2.1
教程正文
观察页面结构
首先我们打开豆瓣电影TOP250的页面
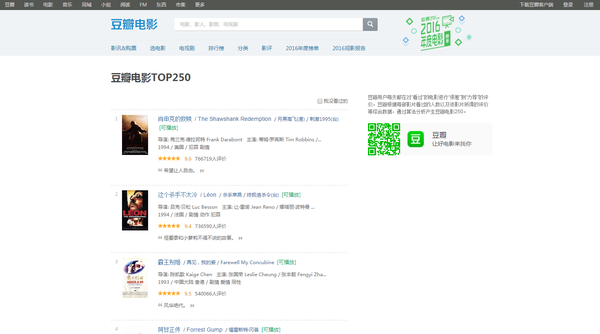
通过观察页面决定让我们的爬虫获取每一部电影的排名、电影名称、评分和评分的人数。
声明Item
什么是Items呢?官方文档Items定义如下:
Items
爬取的主要目标就是从非结构性的数据源提取结构性数据,例如网页。 Scrapy spider可以以python的dict来返回提取的数据.虽然dict很方便,并且用起来也熟悉,但是其缺少结构性,容易打错字段的名字或者返回不一致的数据,尤其在具有多个spider的大项目中。
为了定义常用的输出数据,Scrapy提供了 Item 类。 Item 对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like) 的API以及用于声明可用字段的简单语法。
许多Scrapy组件使用了Item提供的额外信息: exporter根据Item声明的字段来导出数据、 序列化可以通过Item字段的元数据(metadata)来定义、 trackref 追踪Item实例来帮助寻找内存泄露 (see 使用 trackref 调试内存泄露) 等等。
Item使用简单的class定义语法以及Field对象来声明。我们打开scrapyspider目录下的items.py文件写入下列代码声明Item:
import scrapy
class DoubanMovieItem(scrapy.Item):
# 排名
ranking = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 评分
score = scrapy.Field()
# 评论人数
score_num = scrapy.Field()
爬虫程序
在scrapyspider/spiders目录下创建douban_spider.py文件,并写入初步的代码:
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item = DoubanMovieItem()
这个一个基本的scrapy的spider的model,首先我们要导入Scrapy.spiders中的Spider类,以及scrapyspider.items中我们刚刚定义好的DoubanMovieItem。
接着创建我们自己的爬虫类DoubanMovieTop250Spider并继承Spider类,scrapy.spiders中有很多不同的爬虫类可供我们继承,一般情况下使用Spider类就可以满足要求。(其他爬虫类的使用可以去参考官方文档)。
Spider
class scrapy.spider.Spider
Spider是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。 Spider并没有提供什么特殊的功能。 其仅仅请求给定的 start_urls/start_requests ,并根据返回的结果(resulting responses)调用spider的 parse 方法。
name 定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。 不过您可以生成多个相同的spider实例(instance),这没有任何限制。 name是spider最重要的属性,而且是必须的。
如果该spider爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加 后缀 )来命名spider。 例如,如果spider爬取 mywebsite.com ,该spider通常会被命名为 mywebsite 。
allowed_domains 可选。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
start_urls URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
start_requests() 该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。
当spider启动爬取并且未制定URL时,该方法被调用。 当指定了URL时,make_requests_from_url() 将被调用来创建Request对象。 该方法仅仅会被Scrapy调用一次,因此您可以将其实现为生成器。
该方法的默认实现是使用 start_urls 的url生成Request。
如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。 例如,如果您需要在启动时以POST登录某个网站,你可以这么写:
def start_requests(self):
return [scrapy.FormRequest("http://www.example.com/login",
formdata={'user': 'john', 'pass': 'secret'},
callback=self.logged_in)]
def logged_in(self, response):
# here you would extract links to follow and return Requests for
# each of them, with another callback
pass
make_requests_from_url(url) 该方法接受一个URL并返回用于爬取的 Request 对象。 该方法在初始化request时被 start_requests() 调用,也被用于转化url为request。
默认未被复写(overridden)的情况下,该方法返回的Request对象中, parse() 作为回调函数,dont_filter参数也被设置为开启。 (详情参见 Request).
parse(response) 当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
parse 负责处理response并返回处理的数据以及(/或)跟进的URL。 Spider 对其他的Request的回调函数也有相同的要求。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
参数: response (Response) – 用于分析的response
log(message[, level, component]) 使用 scrapy.log.msg() 方法记录(log)message。 log中自动带上该spider的 name 属性。 更多数据请参见 Logging 。
closed(reason) 当spider关闭时,该函数被调用。 该方法提供了一个替代调用signals.connect()来监听 spider_closed 信号的快捷方式。
提取网页信息
我们使用xpath语法来提取我们所需的信息。 不熟悉xpath语法的可以在W3School网站学习一下,很快就能上手。
首先我们在chrome浏览器里进入豆瓣电影TOP250页面并按F12打开开发者工具。
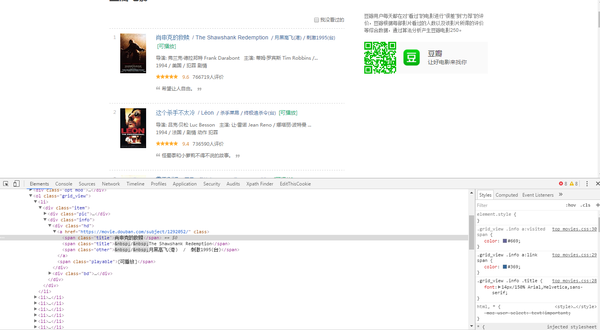
点击工具栏左上角的类鼠标符号图标或者Ctrl + Shift + c在页面中点击我们想要的元素即可在工具栏中看到它在网页HTML源码中所处的位置。
一般抓取时会以先抓大再抓小的原则来抓取。通过观察我们看到该页面所有影片的信息都位于一个class属性为grid_view的ol标签内的li标签内。
<ol class="grid_view">
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" src="https://img3.doubanio.com/view/movie_poster_cover/ipst/public/p480747492.jpg" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.6</span>
<span property="v:best" content="10.0"></span>
<span>766719人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>
...
...
...
</ol>
因此我们根据以上原则对所需信息进行抓取
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
对于Scrapy提取页面信息的内容详情可以参照官方文档的相应章节。
运行爬虫
在项目文件夹内打开cmd运行下列命令:
scrapy crawl douban_movie_top250 -o douban.csv
注意此处的douban_movie_top250即为我们刚刚写的爬虫的name, 而-o douban.csv是scrapy提供的将item输出为csv格式的快捷方式
试着运行一下爬虫怎么什么也没输出呢?!!!
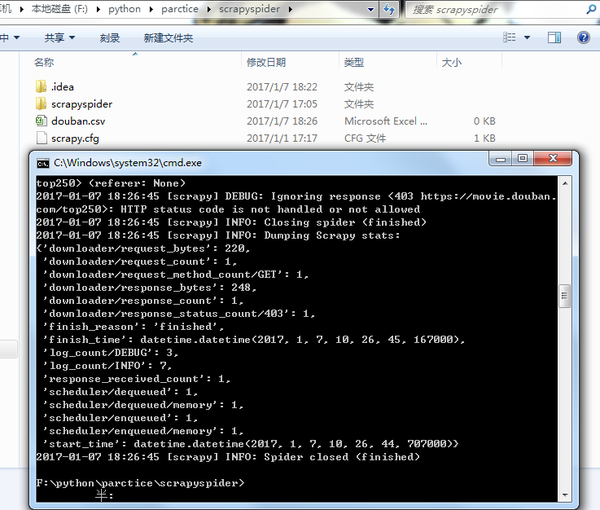
辛辛苦苦到了这里难道要失败了吗?!!!
不要急我们看下一控制台输出的信息,原来是403错误了。这是因为豆瓣对爬虫设了一个小小的门槛,我们只需要更改一下发送请求时的请求头user-agent即可。
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
更改后的代码是不是觉得有些地方不太一样了?start_urls怎么不见了?start_requests函数又是干什么的?还记得刚才对Spider类的介绍吗?先回过头复习一下上面关于start_urls和start_requests函数的介绍。简单的说就是使用start_requests函数我们对初始URL的处理就有了更多的权利,比如这次给初始URL增加请求头user_agent。
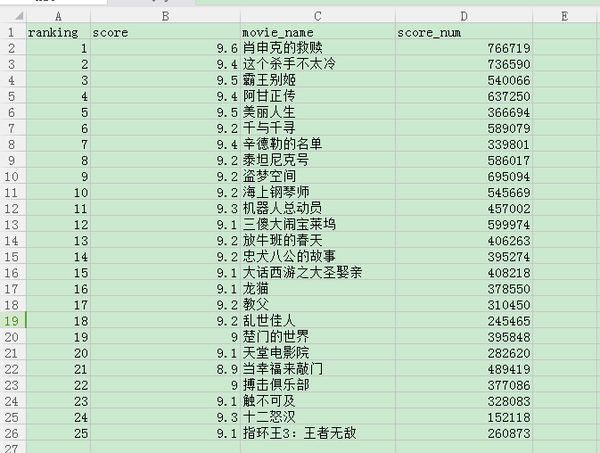
再次运行爬虫,我们想要的信息都被下载到douban.scv文件夹里了。直接用WPS打开即可查看信息。
自动翻页
先别急着高兴,你难道没有发现一个问题吗?这样的话我们还是只能爬到当前页的25个电影的内容。怎么样才能把剩下的也一起爬下来呢?
实现自动翻页一般有两种方法:
- 在页面中找到下一页的地址;
- 自己根据URL的变化规律构造所有页面地址。
一般情况下我们使用第一种方法,第二种方法适用于页面的下一页地址为JS加载的情况。今天我们只说第一种方法。
首先利用Chrome浏览器的开发者工具找到下一页的地址
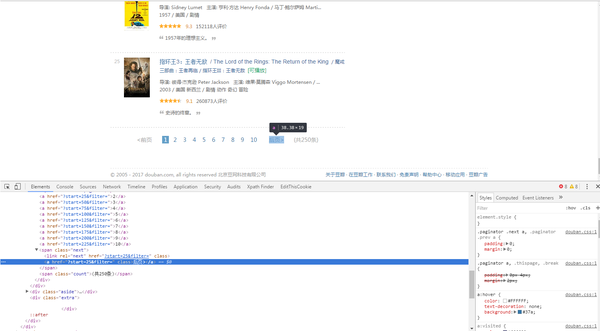
然后在解析该页面时获取下一页的地址并将地址交给调度器(Scheduler)
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)
最后再运行一下爬虫,打开douban.csv。是不是发现所有的影片信息都获取到了,250个一个不多一个不少。
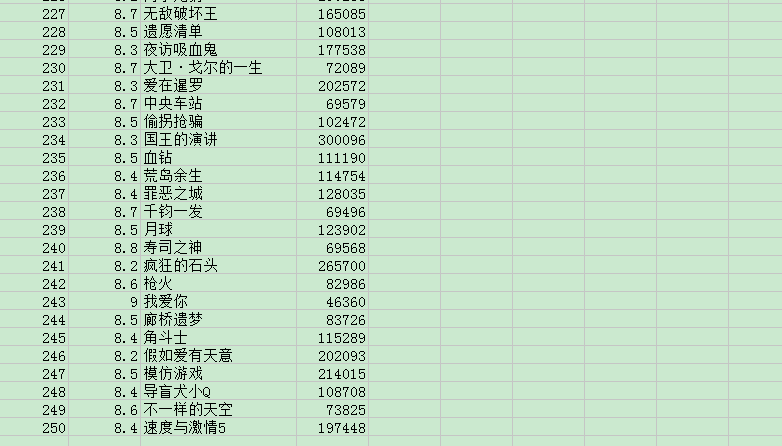
最后,利用WPS的筛选功能你可以筛选任意符合你要求的影片。(Ps:外来的和尚有时候不一定好念经。记得要用WPS打开这个CVS文件,用EXCEL打开会因为有中文而显示不正常。)
结尾
从写这个Scrapy爬虫框架教程以来,我越来越觉得自己学会的东西再输出出去没有想象的那么简单,往往写了几个小时的教程最后发现还是没有想表达的东西表达完美。如果有什么说的不好的地方欢迎大家指正。闻道有先后,术业有专攻。大家互相学习: )


 浙公网安备 33010602011771号
浙公网安备 33010602011771号