
CLH lock queue的原理解释及Java实现
@
背景
相信大部分人在看AQS的时候都能看到注释上有这么一段话:
The wait queue is a variant of a "CLH" (Craig, Landin, and Hagersten) lock queue.
为了更好的理解AQS中使用锁的思想,所以决定先好好理解CLH锁。
在网上能查到很多关于CLH的博客,但不如我想象中的那么全面,于是自己来整理一篇清晰点的。
原理解释
论文地址
CLH的作者:Craig, Landin, and Hagersten。
CLH lock is Craig, Landin, and Hagersten (CLH) locks,
CLH lock is a spin lock, can ensure no hunger, provide fairness first come first service.
The CLH lock is a scalable, high performance, fairness and spin lock based on the list,
the application thread spin only on a local variable, it constantly polling the precursor state,
if it is found that the pre release lock end spin.
我们能看到它是一个自旋锁,能确保无饥饿性,提供先来先服务的公平性。同时它也是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
这个算法很妙的点在于,在一个CAS操作帮助下,所有等待获取锁的线程之下的节点轻松且正确地构建成了全局队列。等待中的线程正如队列中的节点依次获取锁。
接下来就说一下这个算法的Java实现。
Java代码实现
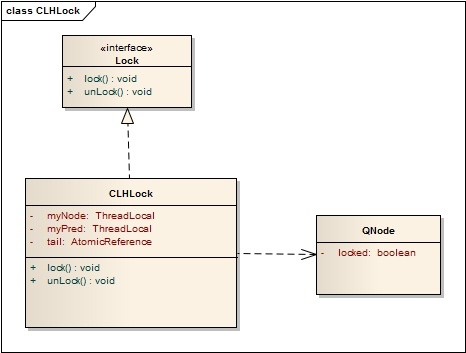
这里面贴出的代码是主要流程代码,详细代码在GitHub中。
定义QNode
CLH队列中的节点QNode中含有一个locked字段,该字段若为true表示该线程需要获取锁,且不释放锁,为false表示线程释放了锁。
public class QNode {
volatile boolean locked;
}
定义Lock接口
public interface Lock {
void lock();
void unlock();
}
定义CLHLock
节点之间是通过隐形的链表相连,之所以叫隐形的链表是因为这些节点之间没有明显的next指针,而是通过myPred所指向的节点的变化情况来影响myNode的行为。CLHLock上还有一个尾指针,始终指向队列的最后一个节点。
public class CLHLock implements Lock {
// 尾巴,是所有线程共有的一个。所有线程进来后,把自己设置为tail
private final AtomicReference<QNode> tail;
// 前驱节点,每个线程独有一个。
private final ThreadLocal<QNode> myPred;
// 当前节点,表示自己,每个线程独有一个。
private final ThreadLocal<QNode> myNode;
public CLHLock() {
this.tail = new AtomicReference<>(new QNode());
this.myNode = ThreadLocal.withInitial(QNode::new);
this.myPred = new ThreadLocal<>();
}
@Override
public void lock() {
// 获取当前线程的代表节点
QNode node = myNode.get();
// 将自己的状态设置为true表示获取锁。
node.locked = true;
// 将自己放在队列的尾巴,并且返回以前的值。第一次进将获取构造函数中的那个new QNode
QNode pred = tail.getAndSet(node);
// 把旧的节点放入前驱节点。
myPred.set(pred);
// 在等待前驱节点的locked域变为false,这是一个自旋等待的过程
while (pred.locked) {
}
// 打印myNode、myPred的信息
peekNodeInfo();
}
@Override
public void unlock() {
// unlock. 获取自己的node。把自己的locked设置为false。
QNode node = myNode.get();
node.locked = false;
myNode.set(myPred.get());
}
}
使用场景
public class KFC {
private final Lock lock = new CLHLock();
private int i = 0;
public void takeout() {
try {
lock.lock();
System.out.println(Thread.currentThread().getName() + ": 拿了第" + ++i + "份外卖");
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
运行代码
public static void main(String[] args) {
final KFC kfc = new KFC();
Executor executor = Executors.newFixedThreadPool(5);
for (int i = 1; i <= 35; i++) {
executor.execute(kfc::takeout);
}
}
代码输出
为什么输出这么多日志后面有解释。
thread-1 acquire lock success. myNode(QNode_2_locked:true), myPred(QNode_1_locked:false)
thread-1: 拿了第1份外卖
thread-2 acquire lock success. myNode(QNode_3_locked:true), myPred(QNode_2_locked:false)
thread-2: 拿了第2份外卖
thread-3 acquire lock success. myNode(QNode_4_locked:true), myPred(QNode_3_locked:false)
thread-3: 拿了第3份外卖
thread-4 acquire lock success. myNode(QNode_5_locked:true), myPred(QNode_4_locked:false)
thread-4: 拿了第4份外卖
thread-5 acquire lock success. myNode(QNode_6_locked:true), myPred(QNode_5_locked:false)
thread-5: 拿了第5份外卖
----------------------------------------------------------------------------------------
thread-1 acquire lock success. myNode(QNode_1_locked:true), myPred(QNode_6_locked:false)
thread-1: 拿了第6份外卖
thread-2 acquire lock success. myNode(QNode_2_locked:true), myPred(QNode_1_locked:false)
thread-2: 拿了第7份外卖
thread-3 acquire lock success. myNode(QNode_3_locked:true), myPred(QNode_2_locked:false)
thread-3: 拿了第8份外卖
thread-4 acquire lock success. myNode(QNode_4_locked:true), myPred(QNode_3_locked:false)
thread-4: 拿了第9份外卖
thread-5 acquire lock success. myNode(QNode_5_locked:true), myPred(QNode_4_locked:false)
thread-5: 拿了第10份外卖
----------------------------------------------------------------------------------------
thread-1 acquire lock success. myNode(QNode_6_locked:true), myPred(QNode_5_locked:false)
thread-1: 拿了第11份外卖
thread-2 acquire lock success. myNode(QNode_1_locked:true), myPred(QNode_6_locked:false)
thread-2: 拿了第12份外卖
thread-3 acquire lock success. myNode(QNode_2_locked:true), myPred(QNode_1_locked:false)
thread-3: 拿了第13份外卖
thread-4 acquire lock success. myNode(QNode_3_locked:true), myPred(QNode_2_locked:false)
thread-4: 拿了第14份外卖
thread-5 acquire lock success. myNode(QNode_4_locked:true), myPred(QNode_3_locked:false)
thread-5: 拿了第15份外卖
----------------------------------------------------------------------------------------
thread-1 acquire lock success. myNode(QNode_5_locked:true), myPred(QNode_4_locked:false)
thread-1: 拿了第16份外卖
thread-2 acquire lock success. myNode(QNode_6_locked:true), myPred(QNode_5_locked:false)
thread-2: 拿了第17份外卖
thread-3 acquire lock success. myNode(QNode_1_locked:true), myPred(QNode_6_locked:false)
thread-3: 拿了第18份外卖
thread-4 acquire lock success. myNode(QNode_2_locked:true), myPred(QNode_1_locked:false)
thread-4: 拿了第19份外卖
thread-5 acquire lock success. myNode(QNode_3_locked:true), myPred(QNode_2_locked:false)
thread-5: 拿了第20份外卖
----------------------------------------------------------------------------------------
thread-1 acquire lock success. myNode(QNode_4_locked:true), myPred(QNode_3_locked:false)
thread-1: 拿了第21份外卖
thread-2 acquire lock success. myNode(QNode_5_locked:true), myPred(QNode_4_locked:false)
thread-2: 拿了第22份外卖
thread-3 acquire lock success. myNode(QNode_6_locked:true), myPred(QNode_5_locked:false)
thread-3: 拿了第23份外卖
thread-4 acquire lock success. myNode(QNode_1_locked:true), myPred(QNode_6_locked:false)
thread-4: 拿了第24份外卖
thread-5 acquire lock success. myNode(QNode_2_locked:true), myPred(QNode_1_locked:false)
thread-5: 拿了第25份外卖
----------------------------------------------------------------------------------------
thread-1 acquire lock success. myNode(QNode_3_locked:true), myPred(QNode_2_locked:false)
thread-1: 拿了第26份外卖
thread-2 acquire lock success. myNode(QNode_4_locked:true), myPred(QNode_3_locked:false)
thread-2: 拿了第27份外卖
thread-3 acquire lock success. myNode(QNode_5_locked:true), myPred(QNode_4_locked:false)
thread-3: 拿了第28份外卖
thread-4 acquire lock success. myNode(QNode_6_locked:true), myPred(QNode_5_locked:false)
thread-4: 拿了第29份外卖
thread-5 acquire lock success. myNode(QNode_1_locked:true), myPred(QNode_6_locked:false)
thread-5: 拿了第30份外卖
----------------------------------------------------------------------------------------
thread-1 acquire lock success. myNode(QNode_2_locked:true), myPred(QNode_1_locked:false)
thread-1: 拿了第31份外卖
thread-2 acquire lock success. myNode(QNode_3_locked:true), myPred(QNode_2_locked:false)
thread-2: 拿了第32份外卖
thread-3 acquire lock success. myNode(QNode_4_locked:true), myPred(QNode_3_locked:false)
thread-3: 拿了第33份外卖
thread-4 acquire lock success. myNode(QNode_5_locked:true), myPred(QNode_4_locked:false)
thread-4: 拿了第34份外卖
thread-5 acquire lock success. myNode(QNode_6_locked:true), myPred(QNode_5_locked:false)
thread-5: 拿了第35份外卖
代码解释
CLHLock的加锁、释放锁过程
-
当一个线程需要获取锁时,会创建一个新的QNode,将其中的locked设置为true表示需要获取锁,然后线程对tail域调用getAndSet方法,使自己成为队列的尾部,同时返回旧的尾部节点作为其前驱引用myPred,然后该线程就在前驱节点的locked字段上自旋,直到前驱节点释放锁。
-
当一个线程需要释放锁时,将当前节点的locked域设置为false,同时回收前驱节点。如下图所示,线程A需要获取锁,其myNode域为true,此时tail指向线程A的节点,然后线程B也加入到线程A后面,tail指向线程B的节点。然后线程A和B都在它的myPred域上旋转,一旦它的myPred节点的locked字段变为false,它就可以获取到锁。明显线程A的myPred locked值为false,此时线程A获取到了锁。
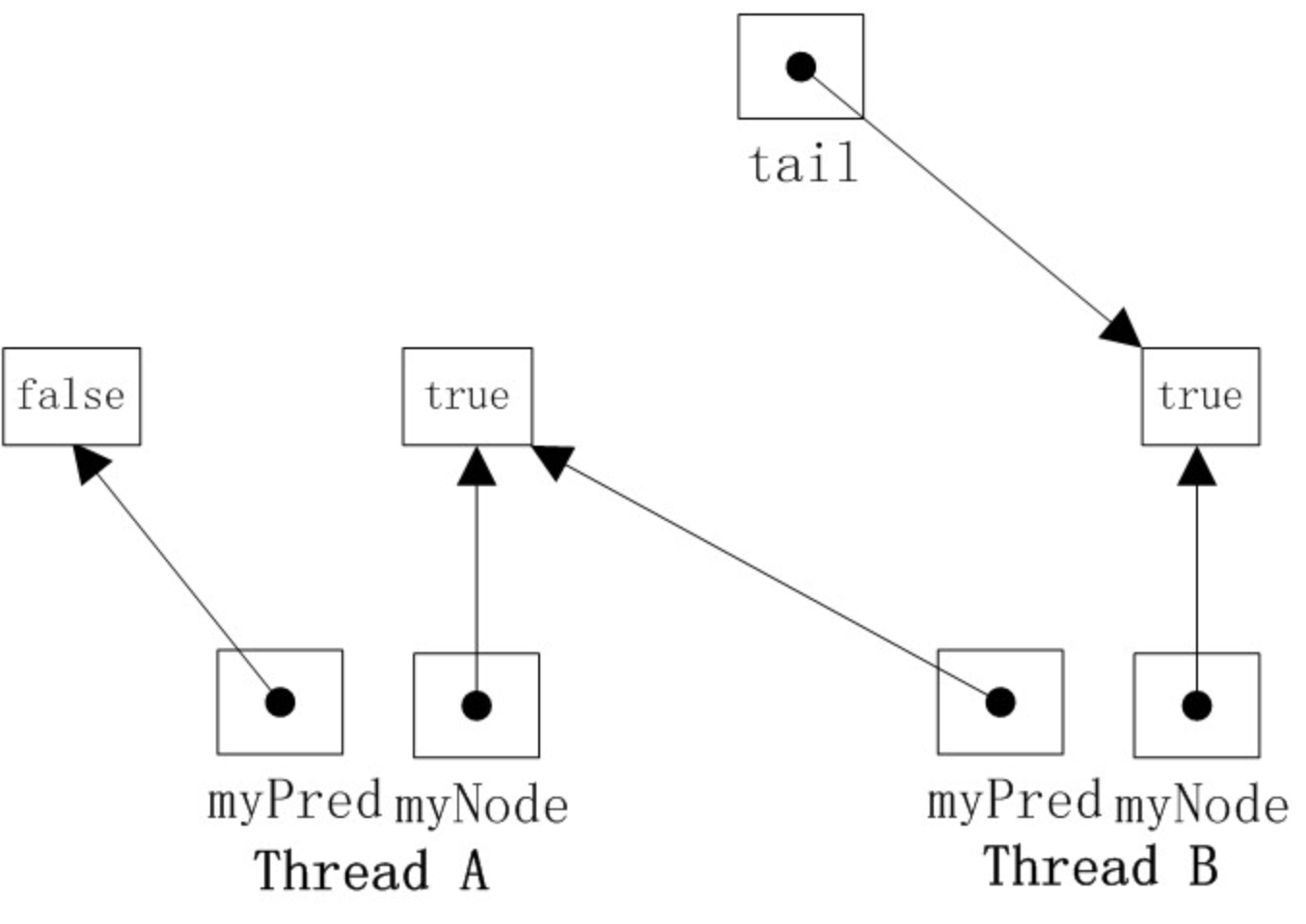
第一个使用CLHLock的线程自动获取到锁
初始状态的tail的值是一个新的QNode,locked的值是默认的false。后面新加入的QNode在获取锁的时候都把locked置为true后放入尾节点并成为前驱节点。
为什么使用ThreadLocal保存myNode和myPred?
因为每个线程使用lock方法的时候,将QNode绑定到当前线程上,等unlock操作的时候还可以获取到本线程之前调用lock方法里创建的QNode对象。
为什么tail要用AtomicReference修饰?
因为我们在把尾节点更新成当前节点并返回旧的尾节点作为前驱节点的时候,我们希望这个操作是原子性的,AtomicReference的getAndSet()方法正好能满足我们的需求。
unlock中的set操作怎么理解?
也就是这一段代码:
myNode.set(myPred.get());
它有以下几点影响:
- 将当前node指向前驱node,lock方法中再也拿不到当前node的引用了。这样操作等于把当前node从链表头部删除(并不是被JVM回收,第二个线程的myPred还引用它)
- 当前线程若要在unlock之后再次拿锁需重新排队(每个线程自己都维护了两个QNode,一个在释放锁的时候把当前node置为前驱node,另一个在lock方法的时候重新获取尾node作为前驱node)
- 如果所有的任务都是由固定数量的线程池执行的话,你会看到所有的QNode的使用会形成一个环形链表(实际不是),在打印日志中可看到,日志“拿了第31份”和日志“拿了第1份”的myNode和myPred一样。
为什么要有myPred,不用行不行?
也就是代码改成这样:
public void lock() {
QNode node = myNode.get();
node.locked = true;
// spin on pre-node
QNode pred = tail.getAndSet(node);
while (pred.locked) {
}
}
public void unlock() {
QNode node = myNode.get();
node.locked = false;
}
答案肯定是不行啦。
假设有两个线程:T1 & T2,T1持有锁,T2等待T1释放锁。
这时候T1.node.locked为true,T2.node.locked也为true,tail变量指向T2.node,却T2正在pred.locked自旋。这里的pred也是T1.node。
现在T1开始释放锁(设置T1.node.locked为false)并且在T2抢占到锁之前再次获取锁,此时T1.node.locked再次变成true,但是此时的尾节点是T2.node,所以T1只好等待T2释放锁。而T2也在等待T1释放锁,死锁发生了。
再结合上面myNode.set(myPred.get())代码的解释,myPred变量提供了两点好处:
- 防止死锁发生,释放锁的时候也就释放了当前节点的引用。
- 等待队列中节点具有顺序性(看日志打印)可保证锁竞争公平,每个等待锁的线程都持有前驱节点的引用(getAndSet返回),n个线程最后有n+1的节点(有一个是初始tail的node),所有的节点按照顺序循环使用。借助于myPred在释放锁后若要再次拿锁需排队且排在最后。
CLH优缺点
CLH队列锁的优点是空间复杂度低(如果有n个线程,L个锁,每个线程每次只获取一个锁,那么需要的存储空间是O(L+n),n个线程有n个QNode,L个锁有L个tail)。
CLH的一种变体被应用在了JAVA并发框架中。唯一的缺点是在NUMA系统结构下性能很差,在这种系统结构下,每个线程有自己的内存,如果前趋结点的内存位置比较远,自旋判断前趋结点的locked域,性能将大打折扣,但是在SMP系统结构下该法还是非常有效的。一种解决NUMA系统结构的思路是MCS队列锁。
NUMA与SMP
SMP(Symmetric Multi-Processor),即对称多处理器结构,指服务器中多个CPU对称工作,每个CPU访问内存地址所需时间相同。其主要特征是共享,包含对CPU,内存,I/O等进行共享。SMP的优点是能够保证内存一致性,缺点是这些共享的资源很可能成为性能瓶颈,随着CPU数量的增加,每个CPU都要访问相同的内存资源,可能导致内存访问冲突,可能会导致CPU资源的浪费。常用的PC机就属于这种。
NUMA(Non-Uniform Memory Access)非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。NUMA优点是可以较好地解决原来SMP系统的扩展问题,缺点是由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。
最后
我的疑惑点都在上文叙述了,如果还有不清晰的地方,希望可以在评论区指出,谢谢🙏
参考
A Hierarchical CLH Queue Lock
JAVA并发编程学习笔记之CLH队列锁
CLH lock 原理及JAVA实现
Why CLH Lock need prev-Node in java

