
动手学深度学习第二版——Day1(章节1——2.2)
动手学深度学习第二版——Day1(章节1——2.2)
1、简单介绍
1)、整体内容
- 深度学习基础——线性神经网络,多层感知机
- 卷积神经网络——LeNet,AlexNet,VGG,Inception,ResNet
- 循环神经网络——RNN。GRU,LSTM,seq2seq
- 注意力机制——Attention, Transformer
- 优化算法——SGD, Momentum, Adam
- 高性能计算——并行,多GPU,分布式
- 计算机视觉——目标检测,语义分割
- 自然语言处理——词嵌入,BERT
2)、深度学习介绍
应用:
- 图片分类
- 物体检测和分割
- 样式迁移(滤镜)
- 人脸合成
- 文字生成图片
- 文字生成
- 无人驾驶
- 案例研究——广告点击
2、预备知识(2.1-2.2)
1)数据操作
- N维数组样例
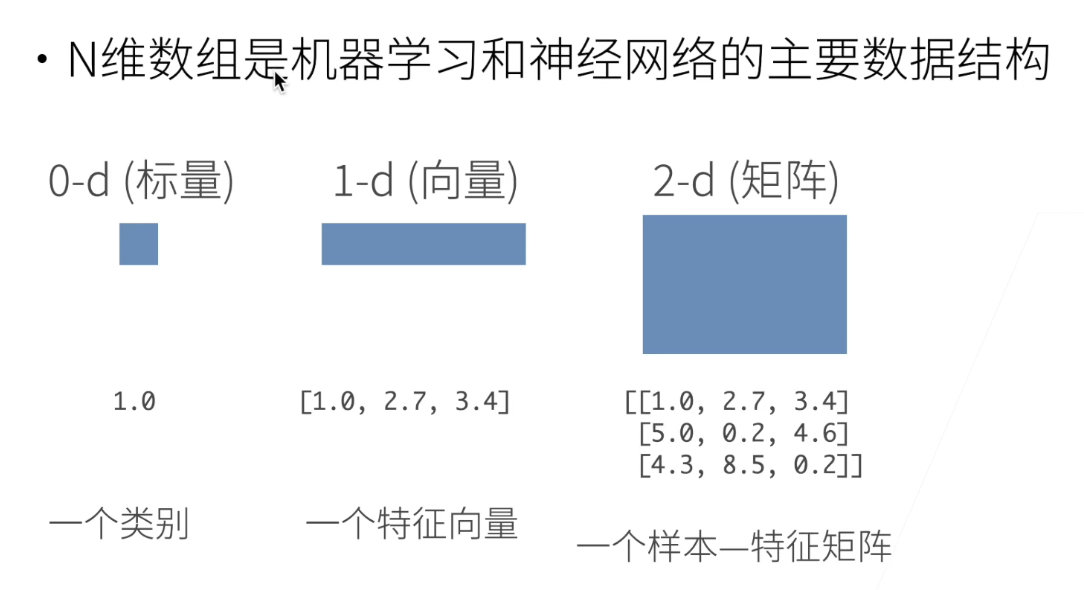
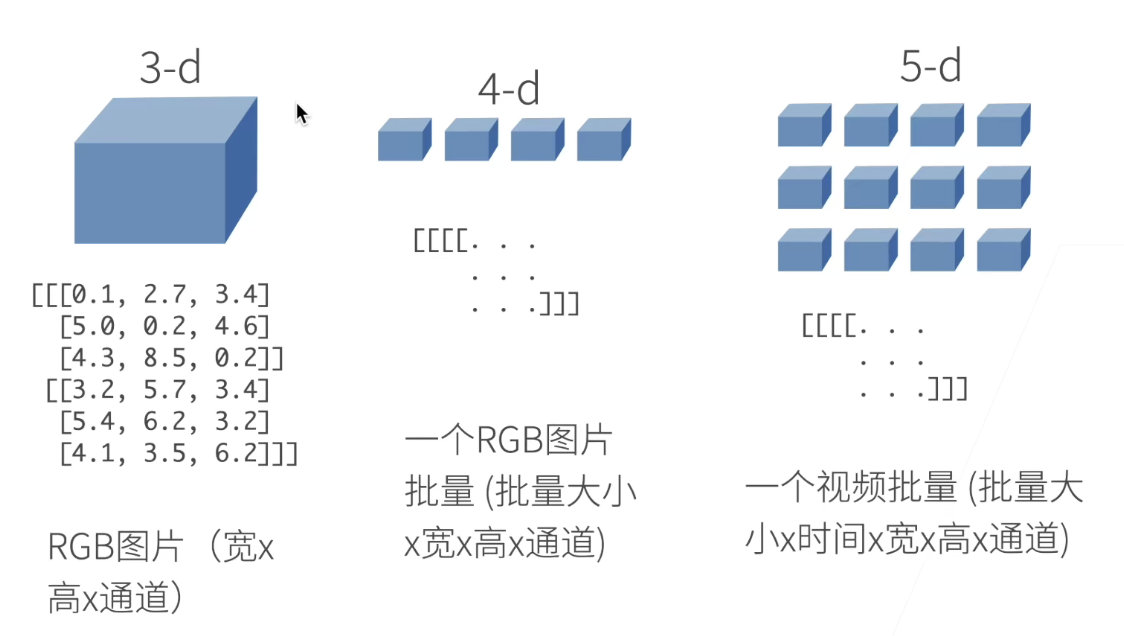
-
创建数组
- 形状:比如:3*4
- 每个元素的数据类型
- 每个元素的值
-
访问元素
下图第三个erro,应该是[:,1]
[1:3, 1:] 第一行到第三行,左开右闭
[::3, ::2] 全部元素,但是行每隔三个访问,列每隔俩个元素访问,比如首先访问了[1,1]->[1,2]->[3,1]->[3,2]
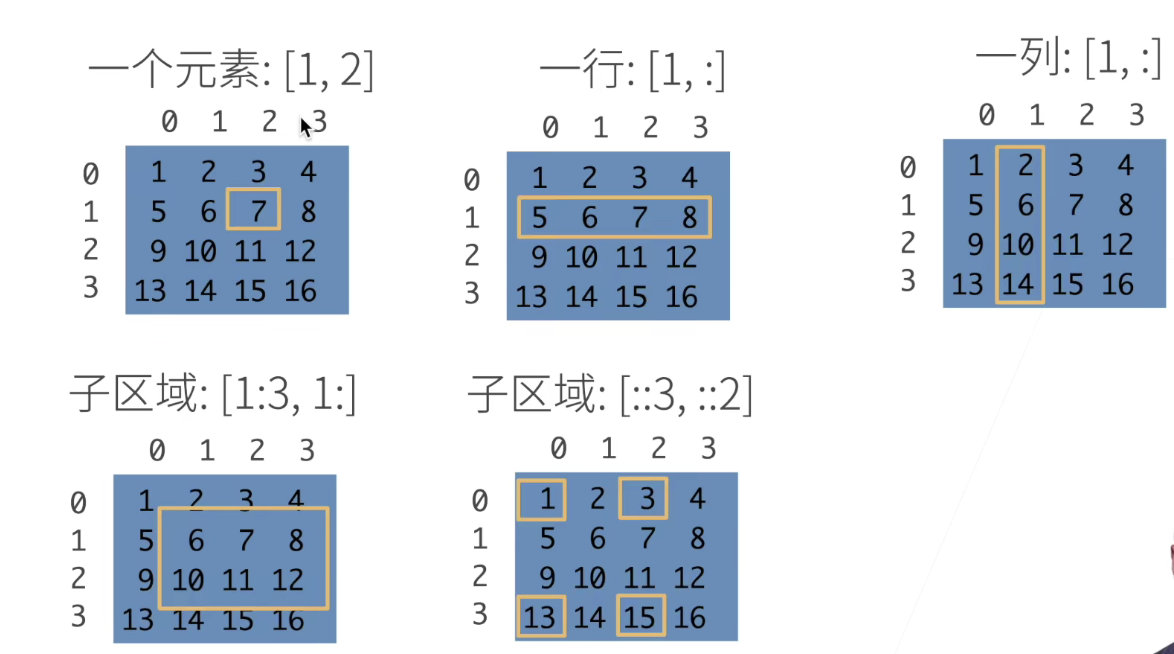
2)动手实践
1⃣️数据操作
import torch
# 张量(创建张量,也就用到了下面代码中的torch.tensor()):表示由一个数值组成的数组,一个轴的张量叫向量,二个轴的叫矩阵
x = torch.arange(12) # torch.arange()创建一个行向量
print(x)
print(x.shape) # 可以使用shape属性来访问张量的形状和元素总数
x.numel() # 里面元素的种数,标量
X = x.reshape(3, 4) # 改变张量的形状,而不改变元素数量和元素值
print(X.shape)
print(torch.zeros((2, 3, 4))) # 使用全0
print(torch.ones((2, 3, 4))) # 使用全1
# 也可以提供包含数值的Python列表(or嵌套链接)来为所需张量中的每个元素赋予确定值
print(torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]))
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
print(x + y)
print(x - y)
print(x * y)
print(x / y)
print(x ** y)
print(torch.exp(x)) # 为x的每个元素做e^x
# 张量连结在一起 torch.cat
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0) # 第0维合并,行合并
torch.cat((X, Y), dim=1) # 第1维合并,列合并
print(X == Y) # 通过逻辑运算符构建二元张量
print(X.sum()) # 求和
# 即使形状不同,我们仍然可以通过调用 广播机制 来执行按元素操作(但维度必须是一样的)
a = torch.arange(3).reshape((3, 1)) # 就是把低的变高,eg:(3, 1) -> (3, 2)
b = torch.arange(2).reshape((1, 2)) # 这里就是把, eg:(1, 2) -> (3, 2),随后再相加
print(a, b)
print(a + b)
# 元素访问,可用用[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素
print(X[-1], X[1:3])
X[1, 2] = 9 # 行和列都是从0开始
print(X)
X[0:2, :] = 12 # 为多个元素赋值
print(X)
# 运行一些操作可能会导致为新结果分配内存
before = id(Y) # Y的id是在python中的一个标识号
Y = Y + X # 新的Y的id不等于以前的
print(id(Y) == before)
# 执行原地操作
Z = torch.zeros_like(Y) # Z和Y的shape和数据类型一样,但所有元素是0
print("id(Z):", id(Z))
Z[:] = X + Y
print("id(Z):", id(Z)) # 俩次Z的id相同
before = id(X)
X += Y
print(id(X) == before) # True
# 转换为NumPy张量
A = X.numpy()
B = torch.tensor(A)
print(type(A), type(B))
# 将大小唯一的张量转换为Python的标量
a = torch.tensor([3.5])
print(a, a.item(), float(a), int(a))
2⃣️数据处理
# 创建一个人工数据集, 并存储在csv(逗号分隔值)文件
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n')
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
# 注意:在向文件里写入NA的时候要注意字符之间不可以使用空格,否则写入的是NA这个字符而不是NaNI类型的missing value
3⃣️读取文件
import pandas as pd
import torch
data = pd.read_csv('../data/house_tiny.csv')
print(data)
# 为了处理缺失的数据,典型的方法包括插值、删除
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean()) # 将na(不是值)的地方填为均值
print(inputs)
# 对于inputs中的类别值和离散值,我们将"NA"视为一个类别
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
# 现在我们将inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(X, y)
3、Qustion/Answer
reshape和view的区别
view只能作用在连续的张量上(张量中元素的内存地址是连续的)。而reshape连续或者非连续都可以。调用x.reshape时,如果x在内存中是连续的,那么x.reshape会返回一个view(原地修改,此时内存地址不变),否则就会返回一个新的张量(这时候内存地址就变了)。
所以推荐,如果想要原地修改就直接view,否则就先clone()再修改

这里的b,感觉就像是指针一样。
快速区分维度
a.shape
tensor和array的区别
tensor是一个张量,数学上确定的,多元数组
array是计算机的概念,是一个数组,没有数学的定义
参考:沐神B站视频

