Celery概述
-1.前言
Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必须工具。
它是一个专注于实时处理的任务队列,同时也支持任务调度。
想要在Django中使用Celery,看完这篇文章,可跳转至Celery与Django。
参考文献
0.目录
1.什么是任务队列?
Task queues are used as a mechanism to distribute work across threads or machines. 任务队列用作在线程或计算机之间分配工作的机制。A task queue’s input is a unit of work called a task. Dedicated worker processes constantly monitor task queues for new work to perform.
任务队列的输入是称为任务的工作单元。专用的工作进程会不断监视任务队列已执行新工作。
Celery communicates via messages, usually using a broker to mediate between clients and workers. To initiate a task the client adds a message to the queue, the broker then delivers that message to a worker.
Celery通过消息进行通信,通常使用代理在客户端和worker之间进行调节。为了启动任务,客户端将消息添加到队列中, 然后代理将消息传递给worker。
A Celery system can consist of multiple workers and brokers, giving way to high availability and horizontal scaling.
一个Celery系统可以有多个worker和代理组成,让位于高可用性和水平扩展。
Celery is written in Python, but the protocol can be implemented in any language. In addition to Python there’s node-celery for Node.js, and a PHP client.
Celery是Python编写,但是该协议可以用任何语言实现。除Python之外,还有Node.js的node-celery和PHP Client。
Language interoperability can also be achieved exposing an HTTP endpoint and having a task that requests it (webhooks).
语言互操作性也可以通过公开HTTP终结点并具有请求该终结点的任务来实现(Webhooks).
2.Celery简介
- **简单:** Celery易于使用和维护,不需要配置文件。 - **高度可用:** 如果连接丢失或出现故障,工作线程和客户端将自动重试,并且某些代理以主/主或主/副本复制方式支持HA 。 - **快速:** 一个Celery进程每分钟可以处理数百万个任务,往返延迟时间不到毫秒(使用RabbitMQ,librabbitmq和优化的设置)。 - **灵活:** Celery的几乎每个部分都可以自己扩展,使用,自定义池实现,序列化程序,压缩方案,日志记录,调度程序,consumers,producers,代理传输等等。Celery支持
- Brokers
- RabbitMQ, Redis,
- Amazon SQS, and more…
- 结果存储
- AMQP,Redis
- Memcached
- SQLAlchemy, Django ORM
- Apache Cassandra, Elasticsearch
- 并发
- prefork (multiprocessing),
- Eventlet, gevent
- solo (single threaded)
- 序列化
- pickle, json, yaml, msgpack.
- zlib, bzip2 compression.
- Cryptographic message signing.
功能
- 监控: worker会发出一连串的监视事件,并由内置和外部工具用来实时告诉集群在做什么。阅读更多...
- 工作流程: 可以使用一组我们称为“canvas”的强大原语来构成简单和复杂的工作流程,包括分组,链接,组块等。阅读更多...
- 事件和速率限制: 可以控制每秒/分钟/小时可以执行多少个任务,或者可以允许任务运行多长时间,并且可以将其设置为默认值(针对特定工作人员),也可以针对每种任务类型分别设置。阅读更多...
- Scheduling:可以以秒或来指定运行任务的时间 datetime,也可以基于简单的间隔或支持分钟,小时,星期几,月日和年月的Crontab表达式将周期性任务用于周期性事件。阅读更多...
- 资源泄漏防护: 该--max-tasks-per-child 选项用于泄漏资源(如内存或文件描述符)的用户任务,而这些任务根本就无法控制。阅读更多...
- 用户组件: 可以自定义每个工作程序组件,并且用户可以定义其他组件。使用“引导步骤”构建工作程序-依赖关系图可对worker的内部进行精细控制。
框架集成
Celery易于与Web框架集成,其中一些甚至具有集成包:
| 框架 | 模块 |
|---|---|
| Pyramid | pyramid_celery |
| Pylons | celery-pylons |
| Flask | not needed |
| web2py | web2py-celery |
| Tornado | tornado-celery |
| Tryton | celery_tryton |
| Django | Celery with Django |
3.Celery需要什么?
Celery requires a message transport to send and receive messages. The RabbitMQ and Redis broker transports are feature complete, but there’s also support for a myriad of other experimental solutions, including using SQLite for local development. Celery需要消息传输才能发送和接受消息。RabbitMQ和Redis代理传输功能齐全,但也支持许多其他实验性解决方案,包括使用SQLite进行本地开发。Celery can run on a single machine, on multiple machines, or even across data centers.
Celery可以在一台计算机上运行,也可以在多台计算机上运行,甚至可以跨数据中心运行。
版本要求
Celery 4.0支持:
- Python(2.7、3.4、3.5...)
- PyPy❨5.4,5.5❩
这是最后一个支持Python2.7的版本,从下一个版本(Celery5.x)开始,需要Python3.5或更高版本。
Celery是一个资金很少的项目,因此对Microsoft Windows兼容性很差(官方表示不支持Windows,但亲测可用,就是有天坑)。
4.架构&工作原理
Celery由以下三部分构成:消息中间件(Broker)、任务执行单元(Worker)、结果存储(Backend),如下图: 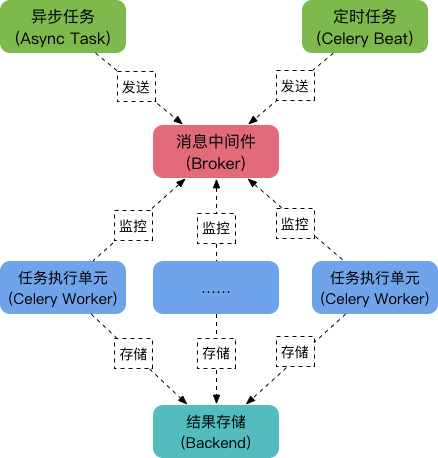 ##### 工作原理: - 任务模块Task包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往消息队列,而定时任务由Celery Beat进程周期地将任务发往消息队列; - 任务执行单元Worker实时监视消息队列获取队列中的任务执行; - Worker执行完任务后将结果保存在Backend中;消息中间件Broker:
消息中间件Broker官方提供了很多备选方案,支持RabbitMQ、Redis、Amazon SQS、MongoDB、Memcached 等,官方推荐RabbitMQ。
任务执行单元Worker
Worker是任务执行单元, 负责从消息队列中取出任务执行,它可以启动一个或者多个,也可以启动在不同的机器节点,这就是其实现分布式的核心。
结果存储Backend
Backend结果存储官方也提供了诸多的存储方式支持:RabbitMQ、Redis、Memcached、SQLAlchemy、Django ORM、Apache Cassandra、Elasticsearch。
5.安装
可以通过Python软件包索引(PyPi)或从源代码安装Celery。 使用pip安装: ``` $ pip install -U Celery ``` #### Bundles Celery还定义了一组捆绑软件,可用于安装Celery及其给功能的依赖项。 可以在要求中或在pip命令行中使用方括号指定这些内容。可以通过用逗号分隔多个包来指定他们。 ``` $ pip install "celery[librabbitmq]" $ pip install "celery[librabbitmq, redis, auth, msgpack]" ``` 提供以下捆绑包: ##### Serializers - **celery[auth]**:使用auth安全序列化程序 - **celery[msgpack]**:使用msgpack序列化程序。 - **celery[yaml]**:使用yaml序列化程序。 ##### Concurrency - **celery[eventlet]** - **celery[gevent]** ##### Transports and Backends - **celery[librabbitmq]** - **celery[redis]** :使用Redis作为消息传输或结果后端。 - **celery[sqs]** 用于将Amazon SQS用做消息传输 - **celery[tblib]** - **celery[memcache]** - **celery[pymemcache]**:纯Python实现 - **celery[cassandra]**:使用Apache Cassandra作为DataStax驱动程序的结果后端。 - **celery[couchbase]** - **celery[arangodb]** - **celery[elasticsearch]** - **celery[riak]** - **celery[dynamodb]** - **[zookeeper]** - **celery[sqlalchemy]** - **celery[pyro]** - **celery[slmq]** - **celery[consul]** - **celery[django]**从源代码下载和安装
从PyPI下载最新版本的Celery:https://pypi.org/project/celery/
可以通过执行以下操作来安装它:
$ tar xvfz celery-x.x.x.tar.gz
$ cd celery-x.x.x
$ python setup.py build
$ python setup.py install
如果当前未使用virtualenv,则必须以root身份执行最后一个命令。
使用开发版本
Celery开发版还需要开发版本的kombu,amqp,billiard和vine.
使用以下pip命令安装这些文件的最新快照:
$ pip install https://github.com/celery/celery/zipball/master#egg=celery
$ pip install https://github.com/celery/billiard/zipball/master#egg=billiard
$ pip install https://github.com/celery/py-amqp/zipball/master#egg=amqp
$ pip install https://github.com/celery/kombu/zipball/master#egg=kombu
$ pip install https://github.com/celery/vine/zipball/master#egg=vine

 浙公网安备 33010602011771号
浙公网安备 33010602011771号