使用Prometheus+Grafana进行Apache Hadoop集群监控
简介
Prometheus——从指标到洞察
开源监控解决方案

-
维度模型
- 一个指标,可以通过多种维度来分析。
- Metrics + Multi-dimension,以key-value简洁描述时间序列数据
-
PromQL
- 基于维度模型的查询语言
-
可视化支撑
- 支持build-in表达式方式浏览
- 支持Grafana集成
- 以及控制台模板语言
-
高效存储
- 在内存和磁盘中,存储时间序列数据
- 支持分片和联邦存储
-
简单易用
- 每个服务器都是独立可靠的,并且运行在本地存储上
- 基于Go语言实现,所有的二进制库都采用静态链接,容易部署
-
精准alert
- 基于PromQL定义,由Alert Manager处理通知、以及抑制通知
-
众多客户端库支持
- 客户端易于嵌入到服务中,自定义库也很容易实现
- 支持数十种语言实现
-
广泛集成
- 现有的exporter允许桥接第三方数据到Promethus,例如:操作系统统计指标、Docker、HAProxy、JMX指标等。
-
100%开源,并且为社区驱动。所有组件均可使用

Prometheus生态圈组件
Prometheus Server
主服务器,负责收集和存储时间序列数据
client libraies
应用程序代码插桩,将监控指标嵌入到被监控应用程序中
推送网关
为支持short-lived作业提供一个推送网关
exporter
专门为一些应用开发的数据摄取组件——exporter,例如:HAProxy、StatsD、Graphite等等。
alertmanager
专门用于处理alert的组件
架构
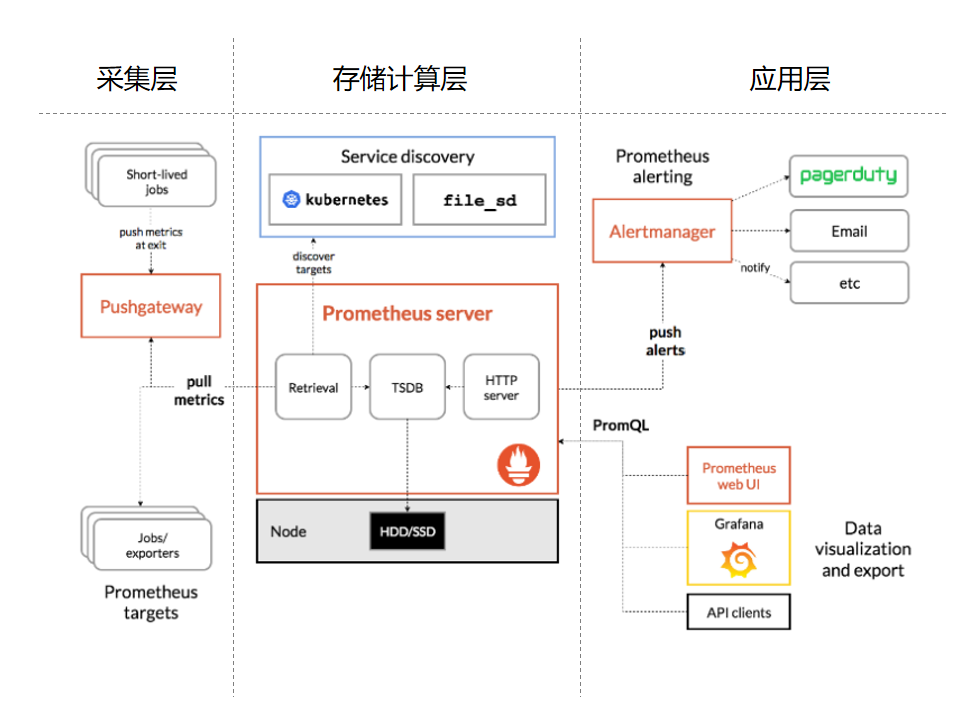
Prometheus既然设计为一个维度存储模型,可以把它理解为一个OLAP系统。
存储计算层
- Prometheus Server,里面包含了存储引擎和计算引擎。
- Retrieval组件为取数组件,它会主动从Pushgateway或者Exporter拉取指标数据。
- Service discovery,可以动态发现要监控的目标。
- TSDB,数据核心存储与查询。
- HTTP server,对外提供HTTP服务。
采集层
采集层分为两类,一类是生命周期较短的作业,还有一类是生命周期较长的作业。
- 短作业:直接通过API,在退出时间指标推送给Pushgateway。
- 长作业:Retrieval组件直接从Job或者Exporter拉取数据。
应用层
应用层主要分为两种,一种是AlertManager,另一种是数据可视化。
- AlertManager
- 可以对接Pagerduty,是一套付费的监控报警系统。可实现短信报警、5分钟无人ack打电话通知、仍然无人ack,通知值班人员Manager...
- Emial,发送邮件
- 等等
- 数据可视化
- Prometheus build-in WebUI
- Grafana
- 其他基于API开发的客户端
安装Prometheus
下载地址
https://prometheus.io/download/
本次安装的版本为:2.25.0。
创建prometheus用户
useradd prometheus
passwd prometheus
# 授予sudo权限
visudo
prometheus ALL=(ALL) NOPASSWD:ALL
上传解压server包
# 上传
[prometheus@ha-node1 ~]$ ll -h
总用量 64M
-rw-r--r-- 1 root root 64M 3月 8 14:07 prometheus-2.25.0.linux-amd64.tar.gz
# 解压
[prometheus@ha-node1 ~]$ tar -xvzf prometheus-2.25.0.linux-amd64.tar.gz -C /opt/
# 创建超链接
[prometheus@ha-node1 ~]$ cd /opt/
[prometheus@ha-node1 opt]$ ln -s /opt/prometheus-2.25.0.linux-amd64/ /opt/prometheus
# 进入到安装目录
[prometheus@ha-node1 opt]$ cd prometheus
[prometheus@ha-node1 prometheus]$ ll
总用量 167984
drwxr-xr-x 2 prometheus prometheus 38 2月 18 00:11 console_libraries
drwxr-xr-x 2 prometheus prometheus 173 2月 18 00:11 consoles
-rw-r--r-- 1 prometheus prometheus 11357 2月 18 00:11 LICENSE
-rw-r--r-- 1 prometheus prometheus 3420 2月 18 00:11 NOTICE
-rwxr-xr-x 1 prometheus prometheus 91044140 2月 17 22:19 prometheus
-rw-r--r-- 1 prometheus prometheus 926 2月 18 00:11 prometheus.yml
-rwxr-xr-x 1 prometheus prometheus 80948693 2月 17 22:21 promtool
# 查看版本号
[prometheus@ha-node1 prometheus]$ ./prometheus --version
prometheus, version 2.25.0 (branch: HEAD, revision: a6be548dbc17780d562a39c0e4bd0bd4c00ad6e2)
build user: root@615f028225c9
build date: 20210217-14:17:24
go version: go1.15.8
platform: linux/amd64
可以看到,Promethues是基于go语言开发的。
配置
Prometheus Server启动需要指定一个重要配置文件:prometheus.yml。
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
该配置文件主要包含三大块:
- global
- rule_files
- scrape_configs
global配置块
global配置块控制Prometheus服务器的全局配置。可以看到,global下有两个配置:
- scrape_interval:配置拉取数据的时间间隔,默认为1分钟。
- evaluation_interval:规则验证(生成alert)的时间间隔,默认为1分钟。
rule_files配置块
- 规则配置文件
scrape_configs配置块
配置采集目标相关,表示prometheus要监视哪些目标。Prometheus自身的运行信息可以通过HTTP访问,所以Prometheus可以监控自己的运行数据。
- job_name:监控作业的名称
- static_configs:表示静态目标配置,就是固定从某个target拉取数据
- targets:指定监控的目标,其实就是从哪儿拉取数据。Prometheus会从http://localhost:9090/metrics上拉取数据。
Prometheus是可以在运行时自动加载配置的。启动时需要添加:--web.enable-lifecycle
启动
./prometheus --config.file=prometheus.yml
| http://ha-node1:9090/metrics |
|---|
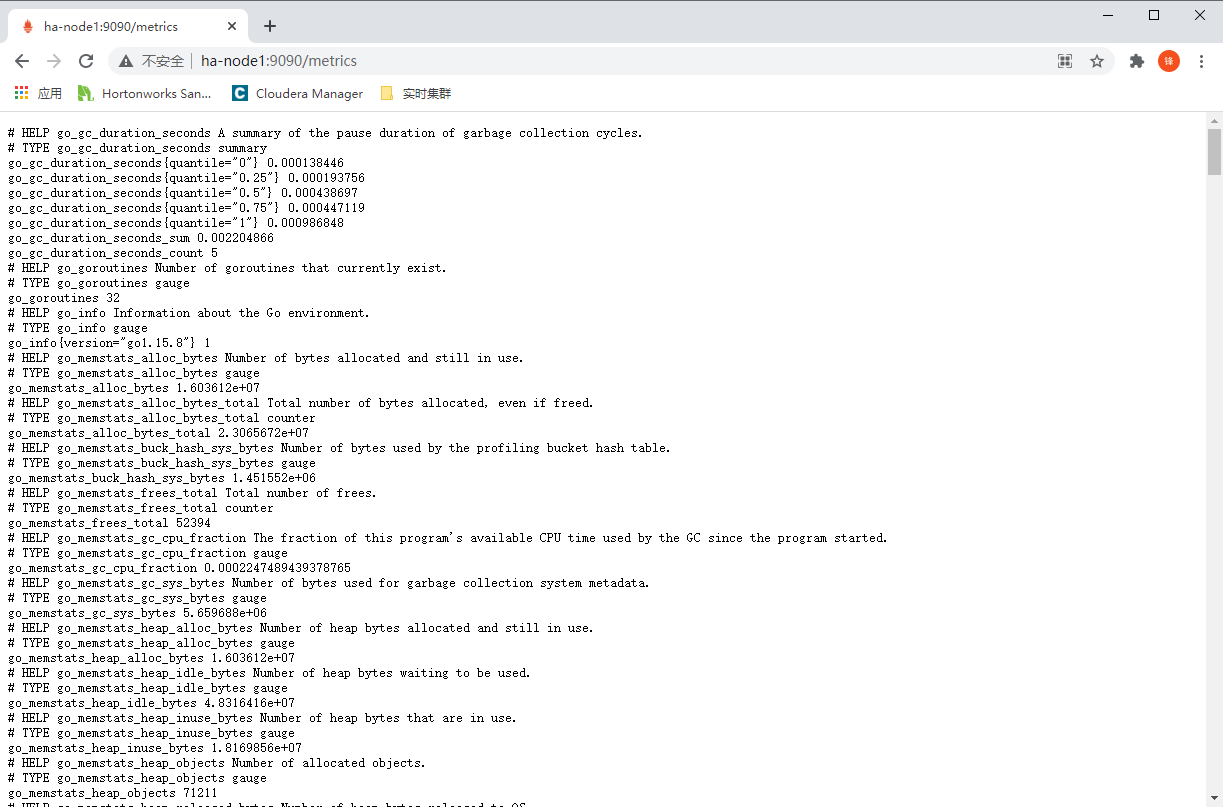 |
| 可以通过/metrics可以查看到Prometheus的一些指标 |
表达式浏览器
| http://ha-node1:9090/graph |
|---|
 |
查询监控指标(可以切换Table或者Graph视图)
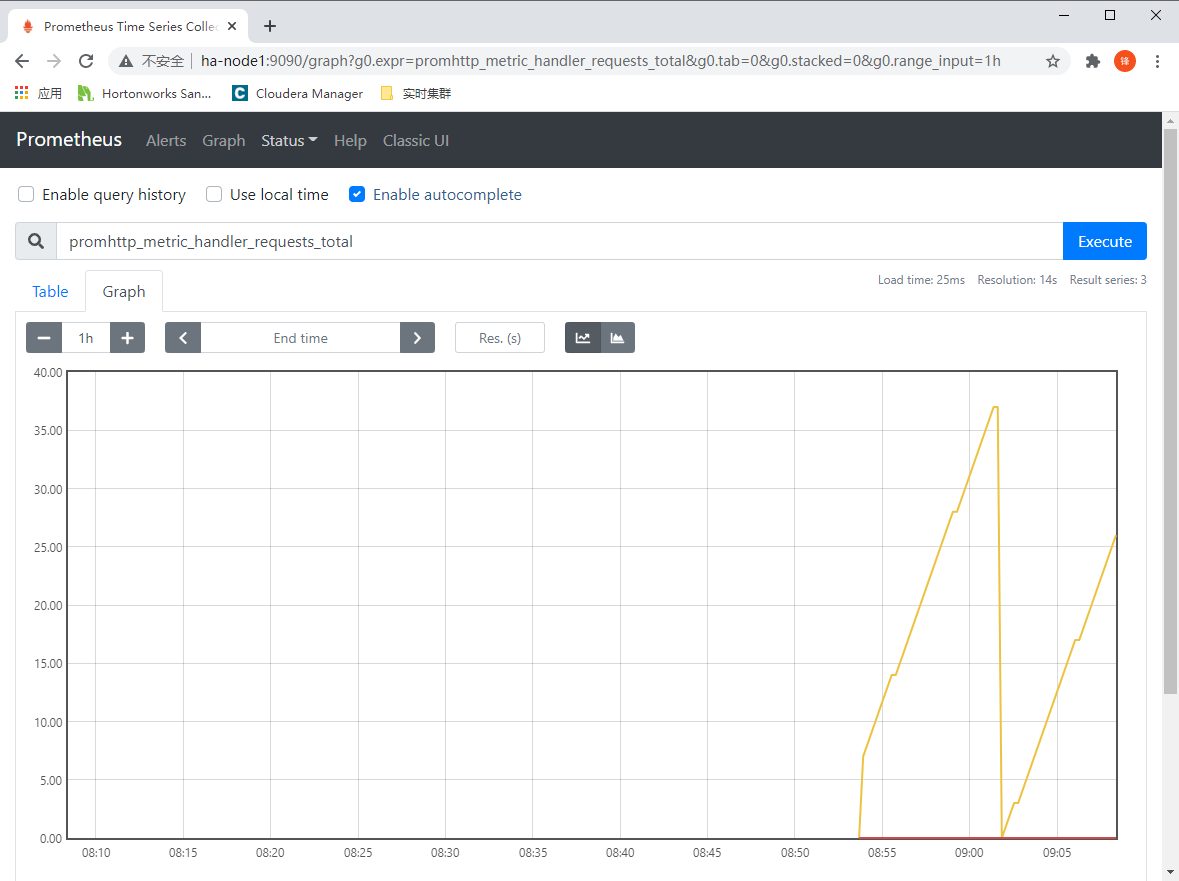
使用PromQL查询每分钟的请求成功率:
rate(promhttp_metric_handler_requests_total{code="200"}[1m])
概念
数据模型
Prometheus将所有的数据存储为时间序列。一组时间戳对应的流数据,属于同样的指标、同样的一组维度。也就是说,例如:监控的时间为5s。那么5秒内流中的所有监控指标,都将放在一组维度中进行计算。而存储下来的就是5s的指标。除了存储的时间序列之外,Prometheus还可以生成临时派生的时间序列作为查询结果。例如:基于5s上卷,计算1小时、半天的维度指标。
时间序列
针对任意时间戳中发生的流数据的一条数据称为时间序列。例如:
net_conntrack_dialer_conn_failed_total{dialer_name="alertmanager",reason="timeout"} 0
指标名和标签
每个时间序列都由指标的名称(Metrics Name)、以及可选的key-value组成的标签(Labels)组成。例如:
net_conntrack_dialer_conn_failed_total{dialer_name="alertmanager",reason="timeout"} 0
go_gc_duration_seconds{quantile="0"} 2.9347e-05
go_gc_duration_seconds{quantile="0.25"} 5.3684e-05
go_gc_duration_seconds{quantile="0.5"} 9.8082e-05
# go_gc_duration_seconds为指标名称
# quantile="0"、dialer_name="alertmanager"、reason="timeout"为标签
# 0、2.9347e-05为指标值
标签其实组成了Prometheus的维度模型。可以按照相同的指标名称可以任意组合(很类似于数仓的维度建模)。使用PromQL可以按照这些组合的维度进行聚合和过滤。
但标签的值、添加标签、删除标签都会生成一个新的时间序列。
语法
<metric name>{<label name>=<label value>, ...}
指标类型
指标是来源于客户端的,Prometheus提供给客户端4类的指标类型。除此之外的类型的指标类型,Prometheus会将它们划分为未启用的类型信息。这4类指标类型分别为:
- Counter(计数器)
- Gauge(精确度量值)
- Histogram(矩形图)
- Summary(总结)
指标类型会影响时间序列聚合计算的方式。就像SQL的count和sum采用的是不同的计算方式一样。
Counter
是一个累计度量指标类型,这种类型的指标计算的方式是单调递增的计数器。它的值要么是增加,要么被重置为零。例如:使用Counter来统计服务请求的数量、已完成的任务、错误的数量等等。
不要使用Counter来处理会发生减少的值,例如:当前正在运行的进程。应该使用Gauge。
Java API
导入Maven依赖
<!-- The client -->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient</artifactId>
<version>0.10.0</version>
</dependency>
<!-- Hotspot JVM metrics-->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_hotspot</artifactId>
<version>0.10.0</version>
</dependency>
<!-- Exposition HTTPServer-->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_httpserver</artifactId>
<version>0.10.0</version>
</dependency>
<!-- Pushgateway exposition-->
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>simpleclient_pushgateway</artifactId>
<version>0.10.0</version>
</dependency>
客户端代码
import io.prometheus.client.Counter;
class YourClass {
static final Counter requests = Counter.build()
.name("requests_total").help("Total requests.").register();
void processRequest() {
requests.inc();
// Your code here.
}
}
Python API
导入包
pip install prometheus-client
from prometheus_client import Counter
c = Counter('my_failures', 'Description of counter')
c.inc() # Increment by 1
c.inc(1.6) # Increment by given value
Gauge
使用Gauge指标类型可以任意增加或者减少单个数字。例如:统计温度、内存使用量等。或者是上升、下降的计数。例如:并发请求数。
Java API
class YourClass {
static final Gauge inprogressRequests = Gauge.build()
.name("inprogress_requests").help("Inprogress requests.").register();
void processRequest() {
inprogressRequests.inc();
// Your code here.
inprogressRequests.dec();
}
}
Python API
from prometheus_client import Gauge
g = Gauge('my_inprogress_requests', 'Description of gauge')
g.inc() # Increment by 1
g.dec(10) # Decrement by given value
g.set(4.2) # Set to a given value
Histogram
直方图是对监控指标值(通常是请求的持续时间或者响应大小之类)进行采样,并存储在可配置的桶中。还可以计算所监控的值的总和。
名为<basename>的指标在拉取数据期间会显示多个序列:
- 桶的累积计数,显示为:<basename>_bucket
- 观察值的综合,显示为:<basename>_sum
- 观察到的事件计数,显示为:<basename>_count
使用histogram_quantile()可根据直方图来计算分位数。
Summary
类似于Histogram,也是对监控指标进行采样。也包含了监控指标的总数、值的总和,还可以计算滑动时间窗口类的分位数。
作业和实例
Prometheus将被监控的目标的端称为实例(Instance),通常是单个进程。而具备有相同目的的实例集合称为作业(Job)。例如:Hadoop中有大量的NodeManager,我们可以用一个Job包含很多的NodeManager实例。
例如:有4个NodeManager节点的YARN集群Job。
job: NodeManager
instance_1: ha-node1:8042
instance_2: ha-node2:8042
instance_3: ha-node3:8042
instance_4: ha-node4:8042
自动生成Label和时间序列
Prometheus从目标拉取数据时,会自动在时间序列上添加一些标签,以用来识别具体的目标。包含以下Label:
- job:目标对应配置的job名称
- instance:目标对应配置的host:port
每个instance,Prometheus都会存储以下时间序列:
# 采集运行良好为1,采集运行失败为0
up{job="<job-name>", instance="<instance-id>"}
# 采集运行持续时间
scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}
# 应用度量标准重新标记后剩余的样本数
scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}
# 从目标采集的样本数
scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}
# 新的序列数量
scrape_series_added{job="<job-name>", instance="<instance-id>"}
Prometheus配置说明
prometheus.yaml说明
| 配置项 | 说明 |
|---|---|
| global_config | 全局配置指定在整个Prometheus上下文有效的参数,还有一些作用于其他配置的默认配置。 |
| scrape_config | 指定被采集监控指标的目标参数。一般针对一个作业都会有一个scrape_config |
| tls_config | 基于TLS连接的相关配置。(安全传输层协议) |
| azure_sd_config | 从Microsoft Azure虚拟机相关配置。 |
| consul_sd_config | Consul相关配置(Google开源服务发现微服务框架) |
| digitalocean_sd_config | Digitalocean相关配置(也是一家云主机厂商) |
| dockerswarm_sd_config | dockerswarm相关配置(Docker集群管理中间件) |
| dns_sd_config | 基于DNS的服务发现配置。 |
| ec2_sd_config | AWS EC2配置。 |
| openstack_sd_config | OpenStack配置。 |
| file_sd_config | 基于文件的服务发现,也是静态目标的一种更通用的配置方法,通过它可以实现自定义实现机制。 |
| gce_sd_config | 基于GCP、GCE实例的配置(Google Cloud Platform)。 |
| hetzner_sd_config | 基于Hetzner Clouder的配置。 |
| kubernetes_sd_config | 基于K8s的配置。 |
| marathon_sd_config | 基于Marathon的配置。 |
| nerve_sd_config | 基于AirBnB的Nerve的配置。 |
| serverset_sd_config | 存储在ZooKeeper中的Serverset配置。 |
| triton_sd_config | 基于从Container Monitor的配置。 |
| eureka_sd_config | 基于Eureka的配置。 |
| static_config | 配置指定目标列表、和目标的通用标签级。配置静态目标。 |
| relabel_config | 顾名思义,它可以对目标的标签进行重写。 |
| metric_relabel_configs | 它不适用于自动生成的时间序列,是对摄取的最后一次重写标记。 |
| alert_relabel_configs | 顾名思义,对alert的标签进行重写。 |
| alertmanager_config | 指定Prometheus服务器警报发送到的AlertManager实例。 |
| remote_write | 根据write_relabel_configs配置进行重新Label,然后将重新标记后的Label发送到远端。 |
| remote_read | 从源端读取标签 |
定义Record Rule
在Prometheus中有两种类型的规则:
- Record Rule
- Alert Rule
在Prometheus中可以通过rule_files来加载规则,rule_files是可以运行时重载的。
Record Rule
Record Rule配置预计算,一些计算量比较大的表达式,可以放在Record Rule进行预计算,并将计算结果存储为一组新的时间序列。这样,基于预计算后的结果要比每次都执行计算表达式要快得多。这种方式,对于一些Dashboard的展示很有效。
以下为配置示例:
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
# PromQL表达式
expr: sum by (job) (http_inprogress_requests)
# 在保存结果前的添加或重写的标签
labels:
- [ <labelname>: <labelvalue>]
Record Rule和Alert都定义在一个规则组中(Group),组中的规则以固定的时间间隔顺序执行。Record Rule的名称必须是有效的度量标准名称。而Alert Rule的名称必须是有效的Label值。
Alert Rule
Alert Rule可以基于Prometheus表达式语言定义警报条件,并将通知发送到外部服务。只要表达式在给定的时间点产生一个或者多个元素,就认为这些元素的标签集处于活动状态。
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
# 表示附加到警报的标签
labels:
severity: page
# 附加更长的描述信息。
annotations:
summary: High request latency
for表示第一次表达式输出元素能够持续一定的时间。上述的Alert Rule表示10分钟内是否还处于活动状态,如果处于活动状态但尚未触发的元素会处于挂起状态。
被测程序埋点
INSTRUMENTING这个词翻译过来是检测仪表装置的意思,而针对Prometheus上下文表示的是将采集数据的代码植入到被监控程序。我把它简称为客户端埋点。
客户端库
在监控之前,需要通过Prometheus客户端库,在被测程序中埋点。这些客户端实现了之前我们提到过的4种指标类型。官方支持4种客户端:
- Go
- Java / Scala
- Python
- Ruby
第三方客户端:
- Bash
- C
- C++
- Common Lisp
- Dart
- Elixir
- Erlang
- Haskell
- Lua for Nginx
- Lua for Tarantool
- .NET / C#
- Node.js
- Perl
- PHP
- R
- Rust
当Prometheus服务器从HTTP采集实例中拉取数据时,客户端库会将所有监控的指标发送到服务器。
Exporter与集成
一些库和服务器可以将第三方系统中的现有指标导出为Prometheus指标。这种会极大降低使用Prometheus的成本。例如:使用JMXExporter可以将基于JVM的应用程序中导出为Prometheus的指标。例如:Kafka、Cassandra之类的。
Prometheus官方以及Github上开源的Exporter非常丰富。
参考:https://prometheus.io/docs/instrumenting/exporters/
推送指标
一些短作业是不利于监控的,因为它们总是在短时间内快速变化。此时,可以使用Prometheus提供的Pushgateway将指标推送到Prometheus Server的拉取中间作业。所以,即便没有客户端库,也可以实现监控。
具体请参考:https://prometheus.io/docs/instrumenting/pushing/
监控Hadoop集群
监控ZooKeeper指标
修改zkServer.sh
vim /opt/apache-zookeeper-3.6.1-bin/conf/zoo.cfg
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
将ZK分发到每个节点
scp /opt/apache-zookeeper-3.6.1-bin/conf/zoo.cfg ha-node2:/opt/apache-zookeeper-3.6.1-bin/conf; \
scp /opt/apache-zookeeper-3.6.1-bin/conf/zoo.cfg ha-node3:/opt/apache-zookeeper-3.6.1-bin/conf; \
scp /opt/apache-zookeeper-3.6.1-bin/conf/zoo.cfg ha-node4:/opt/apache-zookeeper-3.6.1-bin/conf; \
scp /opt/apache-zookeeper-3.6.1-bin/conf/zoo.cfg ha-node5:/opt/apache-zookeeper-3.6.1-bin/conf
启动ZooKeeper集群
测试获取ZooKeeper metrics
curl ha-node1:7000/metrics
马上就能看到大量的指标了。
[zookeeper@ha-node1 bin]$ curl ha-node1:9505/metrics
# HELP jmx_exporter_build_info A metric with a constant '1' value labeled with the version of the JMX exporter.
# TYPE jmx_exporter_build_info gauge
jmx_exporter_build_info{version="0.15.0",name="jmx_prometheus_javaagent",} 1.0
# HELP jmx_config_reload_failure_total Number of times configuration have failed to be reloaded.
# TYPE jmx_config_reload_failure_total counter
jmx_config_reload_failure_total 0.0
# HELP jvm_threads_current Current thread count of a JVM
# TYPE jvm_threads_current gauge
jvm_threads_current 41.0
# HELP jvm_threads_daemon Daemon thread count of a JVM
# TYPE jvm_threads_daemon gauge
jvm_threads_daemon 15.0
# HELP jvm_threads_peak Peak thread count of a JVM
# TYPE jvm_threads_peak gauge
jvm_threads_peak 41.0
# HELP jvm_threads_started_total Started thread count of a JVM
# TYPE jvm_threads_started_total counter
jvm_threads_started_total 43.0
# HELP jvm_threads_deadlocked Cycles of JVM-threads that are in deadlock waiting to acquire object monitors or ownable synchronizers
# TYPE jvm_threads_deadlocked gauge
jvm_threads_deadlocked 0.0
# HELP jvm_threads_deadlocked_monitor Cycles of JVM-threads that are in deadlock waiting to acquire object monitors
# TYPE jvm_threads_deadlocked_monitor gauge
jvm_threads_deadlocked_monitor 0.0
Prometheus开启监控
编辑prometheus.yaml文件:
- job_name: 'zk_cluster'
static_configs:
- targets: ['ha-node1:9505','ha-node2:9505','ha-node3:9505','ha-node4:9505','ha-node5:9505']
启动prometheus:
./prometheus --config.file=prometheus.yml
监控Hadoop运行指标
创建prometheus_client用户
在所有节点创建prometheus_client用户。
useradd prometheus_client
passwd prometheus_client
上传并解压Hadoop exporter
[prometheus_client@ha-node1 ~]$ ll
总用量 17228
-rw-r--r-- 1 root root 17639070 3月 9 15:58 hadoop_jmx_exporter.tar.gz
解压到指定目录
tar -xvzf hadoop_jmx_exporter.tar.gz -C /opt
修改集群节点文件
vim /opt/hadoop_jmx_exporter/apache-tomcat-8.5.63/webapps/ROOT/cluster_config.json
在第一个节点启动tomcat
cd /opt/hadoop_jmx_exporter/apache-tomcat-8.5.63
bin/startup.sh
分发到每个节点
scp -r /opt/hadoop_jmx_exporter ha-node2:/opt; \
scp -r /opt/hadoop_jmx_exporter ha-node3:/opt; \
scp -r /opt/hadoop_jmx_exporter ha-node4:/opt; \
scp -r /opt/hadoop_jmx_exporter ha-node5:/opt
所有节点启动Exporter
export PYTHONPATH=${PYTHONPATH}:/opt/hadoop_jmx_exporter/hadoop_exporter/modules
python /opt/hadoop_jmx_exporter/hadoop_exporter/hadoop_exporter.py -host "0.0.0.0" -P 9131 -s "ha-node1:9035"
配置Prometheus
- job_name: 'hadoop'
static_configs:
- targets: ['ha-node1:9131','ha-node2:9131','ha-node3:9131','ha-node4:9131','ha-node5:9131']
启动Prometheus
./prometheus --config.file=prometheus.yml
PromQL语法
用户可以通过PromQL进行实时查询、以及汇总时间序列数据。结果可以以图形化展示,也可以以Table方式展示,还可以通过Http API方式提供给外部。
快速入门
查询指定指标列
http_requests_total
指定条件查询
http_requests_total{job="apiserver", handler="/api/comments"}
指定时间范围查询
http_requests_total{job="apiserver", handler="/api/comments"}[5m]
正则匹配查询
# 以~开头
http_requests_total{job=~".*server"}
取反查询
http_requests_total{status!~"4.."}
子查询
查询过去30m,http_request_total指标5分钟的速度,分辨率为1分钟。
rate(http_requests_total[5m])[30m:1m]
嵌套子查询
max_over_time(deriv(rate(distance_covered_total[5s])[30s:5s])[10m:])
使用函数、运算符
返回过去5分钟类使用http_request_total指标的所有时间序列,每秒的速率。
rate(http_requests_total[5m])
按照作业统计的比率的和。
sum by (job) (
rate(http_requests_total[5m])
)
运算符(对于不同的指标,相同的维度标签)
(instance_memory_limit_bytes - instance_memory_usage_bytes) / 1024 / 1024
相同的表达式,但按照不同的应用汇总。
sum by (app, proc) (
instance_memory_limit_bytes - instance_memory_usage_bytes
) / 1024 / 1024
更多的函数、运算符请参考:https://prometheus.io/docs/prometheus/latest/querying/basics/
语法检查
为了方便排错,可以在不启动Prometheus进行语法检查。
promtool check rules /path/to/example.rules.yml
返回1表示存在语法错误,返回0表示无语法错误。
Prometheus整合Grafana
下载地址:https://grafana.com/grafana/download
安装Grafana
创建Grafana用户
useradd grafana
passwd grafana
上传解压grafana
# 上传...
[grafana@ha-node1 ~]$ ll
总用量 50068
-rw-r--r-- 1 root root 51268825 3月 9 16:29 grafana-7.4.3.linux-amd64.tar.gz
# 解压
[grafana@ha-node1 ~]$ tar -xvzf grafana-7.4.3.linux-amd64.tar.gz -C /opt/
# 创建超链接
[grafana@ha-node1 ~]$ ln -s /opt/grafana-7.4.3/ /opt/grafana
启动grafana
[grafana@ha-node1 grafana]$ pwd
/opt/grafana
[grafana@ha-node1 grafana]$ ./bin/grafana-server web
访问grafana
http://ha-node1:3000/login
# 默认用户名密码为:admin/admin
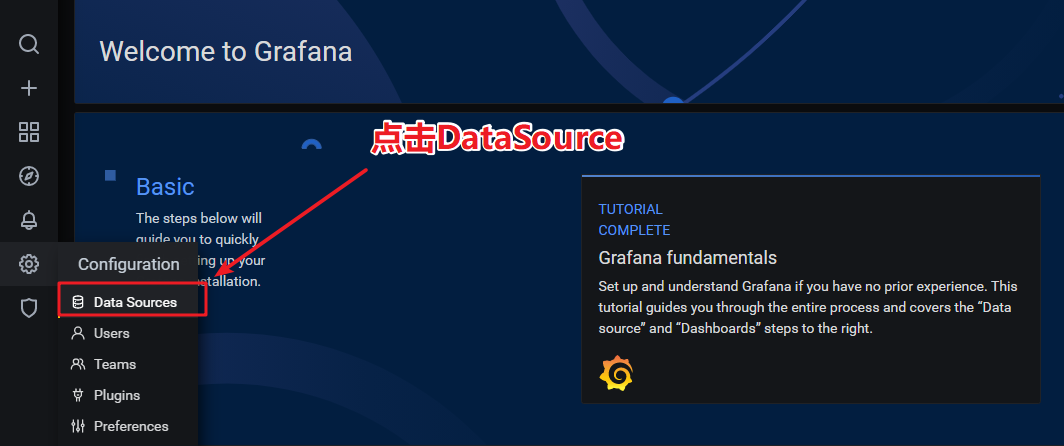
添加指标数据源
Grafana可以以图表化的方式展示Prometheus中的数据。要展示数据,首先要告诉Grafana从哪儿查询数据,也就是prometheus server(TSDB)的位置。
点击小齿轮 > DataSource
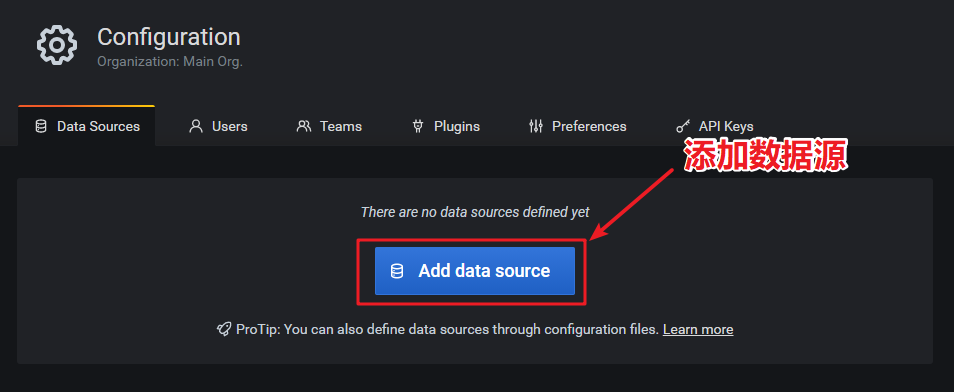
添加数据源
选择Prometheus

配置Prometheus地址,此处为:http://ha-node1:9090
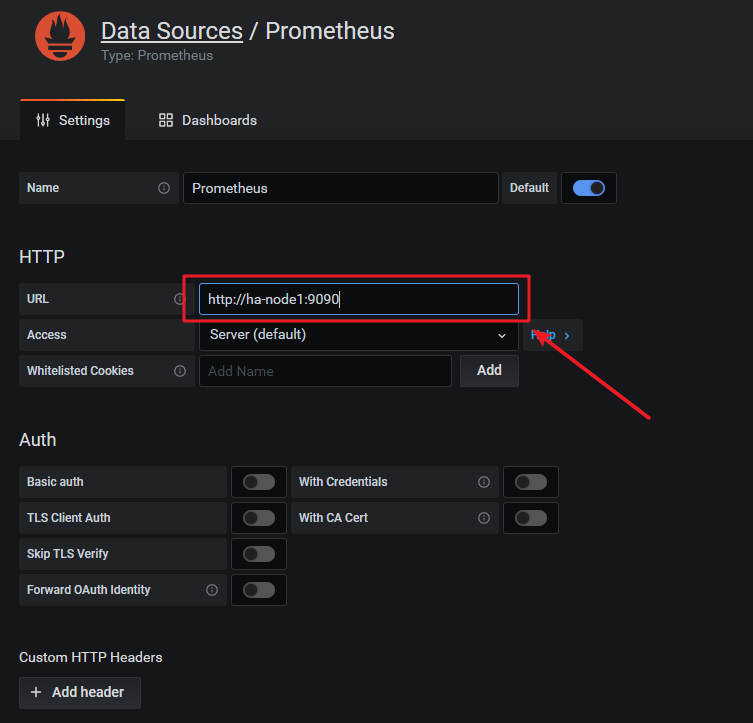
点击Save & test

使用Grafana查询指标
点击 Explore图标,再选择Prometheus数据源。
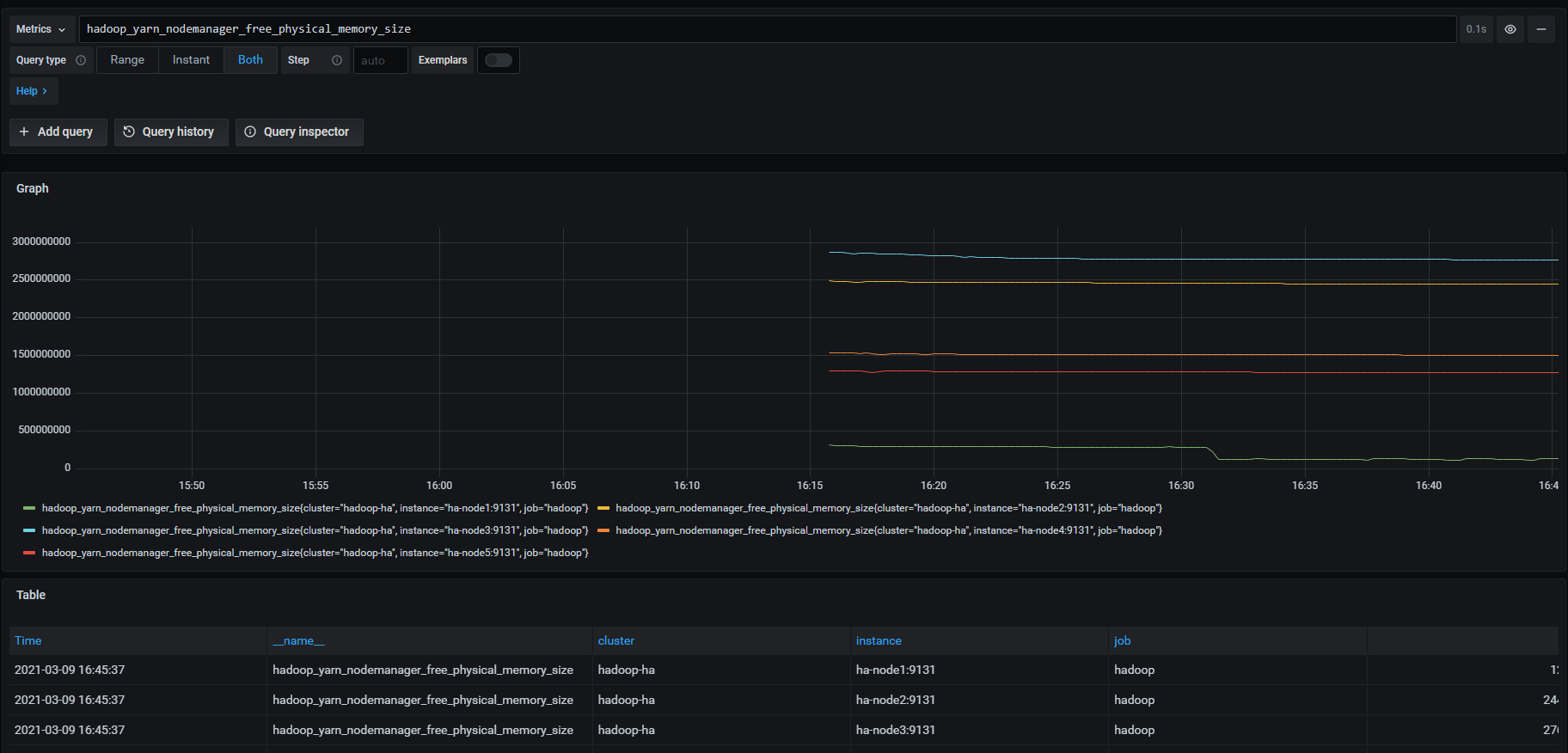
然后就可以用PromQL查询指标数据了。
创建Dashboard
1、创建Dashboard
2、点击右上角添加Panel
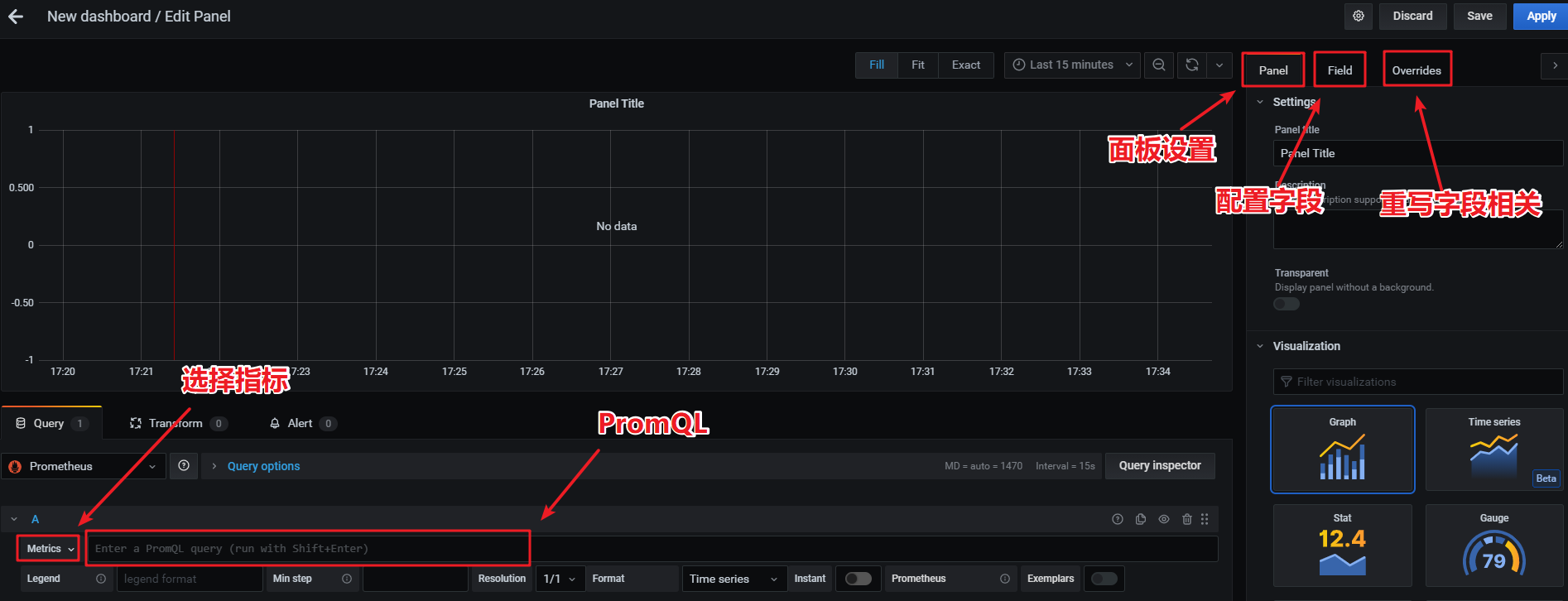
3、配置Panel
Grafana 表达式语言
| Expression syntax | Example | Renders to | Explanation |
|---|---|---|---|
${__field.displayName} |
Same as syntax | Temp {Loc="PBI", Sensor="3"} |
Displays the field name, and labels in {} if they are present. If there is only one label key in the response, then for the label portion, Grafana displays the value of the label without the enclosing braces. |
${__field.name} |
Same as syntax | Temp |
Displays the name of the field (without labels). |
${__field.labels} |
Same as syntax | Loc="PBI", Sensor="3" |
Displays the labels without the name. |
${__field.labels.X} |
${__field.labels.Loc} |
PBI |
Displays the value of the specified label key. |
${__field.labels.__values} |
Same as Syntax | PBI, 3 |
Displays the values of the labels separated by a comma (without label keys). |
参考文献:
[1] https://prometheus.io/docs/introduction/overview/
[2] https://grafana.com/docs/grafana/latest/panels/field-options/standard-field-options/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号