C#:字典的工作原理
在C#中,我们可能经常用到使用非常方便的Hashtable,不知大家是否知道它的另外一个名字:散列表.事实上Hashtable使用了某种算法,通过键(key)来确定每个对象的位置,实际上,该算法并不完全是Hashtable类提供的.它有两个部分,其中的一部分的代码是有key类来完成.我们平常在使用Hashtable的时候,key我们一般使用string类(部分算法string已经提供,Microsoft已经替我们做了),所以不会有任何的问题,但是如果key类是用户自己编写的,就必须自己编写这部分算法了.
下面我们用EmployeeID类作为key类,来讲解如何编写自己的算法.
在计算机中.由key类执行的部分算法成为散列,Hashtable在散列算法中有特殊的地位,它提供了对象的GetHashCode()方法,该方法继承于Sysetm.Object.只要字典需要确定数据项的位置,就会条用key对象的GetHashCode()方法.所以我们如果要是我们的key类起作用的话,就必须重写GetHashCode()方法.
GetHashCode()方法的工作方式是:返回一个int型的数据,它使用这个键的值来生成int类型的数据.Hashtable获取这个值,并对它进行其他的一些操作,其中涉及一些非常复杂的计算,最后返回一个索引,表示带有指定散列的数据项在字典中的位置.这部分算法呢据说很复杂,非我辈能力所及,就不介绍了.免得招来拍砖无数.
重载GetHashCode()方法就可以了吗?答案是否顶的!比如:如果再字典中,两个数据项的散列有相同的索引,该怎么办?所以要确保字典的容量大于其中元素的个数.而且,如果两个对象包含相同的数据,他们就必须给出相同的散列值.所以重写System.Object的Equals()和GetHashCode()方法时,必须考虑这个.
下面我们通过具体的例子进行讲解:
比如A公司建立了一个员工字典,该字典用EmployeeID对象做索引,存储的数据都是一个EmployeeData对象(员工的详细数据).我们的实例创建一个字典,添加了两个员工,通过员工的id,获取相应的信息.
首先我们看下我EmployeeID类和EmployeeData类. EmployeeID类是关键,散列的部分算法就在EmployeeID类中实现.
 using System;using System.Collections.Generic;using System.Linq;using System.Web;
using System;using System.Collections.Generic;using System.Linq;using System.Web; /// <summary>
/// <summary>
 /// Summary description for EmployeeID
/// Summary description for EmployeeID /// </summary>public class EmployeeID{
/// </summary>public class EmployeeID{ public EmployeeID()
public EmployeeID() {
{ // // TODO: Add constructor logic here //
// // TODO: Add constructor logic here // } public EmployeeID(string id) { Id = id; } private string Id { get; set; } // public override string ToString() { return base.ToString(); } //必须重写,否则EmployeeID类,不能作为key类, public override int GetHashCode() { return ToString().GetHashCode(); } //重载Equals方法,确保两个相同的对象,返回相同的散列值 public override bool Equals(object obj) { EmployeeID employeeID = obj as EmployeeID; if (employeeID == null) return false; if (this.Id == employeeID.Id) return true; return false; }}
} public EmployeeID(string id) { Id = id; } private string Id { get; set; } // public override string ToString() { return base.ToString(); } //必须重写,否则EmployeeID类,不能作为key类, public override int GetHashCode() { return ToString().GetHashCode(); } //重载Equals方法,确保两个相同的对象,返回相同的散列值 public override bool Equals(object obj) { EmployeeID employeeID = obj as EmployeeID; if (employeeID == null) return false; if (this.Id == employeeID.Id) return true; return false; }}上面的代码 ,我们重点看下GetHashCode()方法,我们前面讲了,如果要实现散列算法,必须满足很多苛刻的要求.但是我们知道string类可以直接作为Hashtable的key类,说明Microsoft已经为string类提供了很有效的散列算法.所以我们直接应用string.GetHashCode()去重写我们的EmployeeID类的GetHashCode()方法.当然性能可能会有损失,因为EmployeeID类转换为string的时候会损失性能.
EmployeeData类就没有什么特别的啦,就一些数据
Main 测试代码
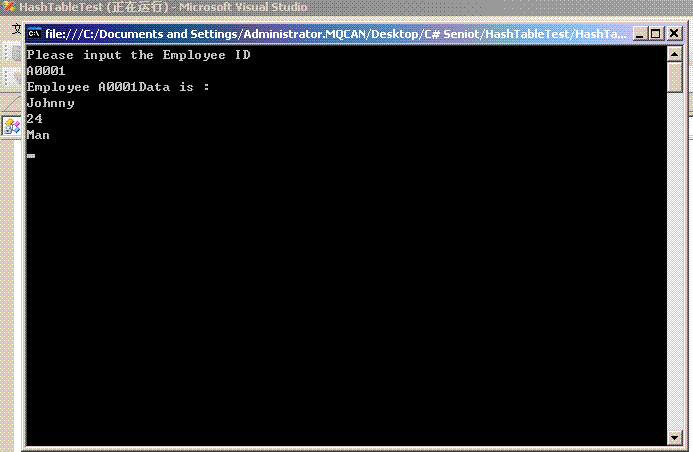
using System;using System.Collections.Generic;using System.Text;using System.Collections;namespace HashTableTest{ class Program { static void Main(string[] args) { Hashtable ht = new Hashtable(); ht.Add(new EmployeeID("A0001"), new EmployeeData("Johnny", "24", "Man")); ht.Add(new EmployeeID("A0002"), new EmployeeData("Vicky", "20", "female")); ht.Add(new EmployeeID("A0003"), new EmployeeData("Allen", "30", "male")); Console.WriteLine("Please input the Employee ID"); string userId = Console.ReadLine(); //当输入ID的是否,返回员工的详细数据 EmployeeData E1 = (EmployeeData)ht[new EmployeeID(userId)]; if (E1 != null) { Console.WriteLine("Employee " + userId+"Data is :"); Console.WriteLine(E1.Name); Console.WriteLine(E1.Age); Console.WriteLine(E1.Gender); } Console.ReadLine(); } }}结果如图所示