SQL Server非聚集索引--包含列(翻译官方介绍)
SQL Server indexes are created to speed up the retrieval of data from the database table or view. The index contains one or more columns from your table. The structure of these keys are in the shape of B-tree distribution, enabling SQL Server to find the data quickly.
创建SQL Server索引可加快从数据库表或视图中检索数据的速度。 索引包含表中的一列或多列。 这些键的结构采用B树形分布,从而使SQL Server能够快速查找数据。
You need to balance between the data retrieval and the data update when trying to create the suitable index. Indexes with fewer number of columns in the index key, will require less disk space and also less maintenance overhead. Covering index, on the other hand, serve more queries. It is better to test many scenarios and workloads before choosing the efficient index.
尝试创建合适的索引时,需要在数据检索和数据更新之间取得平衡。 索引键中的列数较少的索引将需要较少的磁盘空间,也需要较少的维护开销。 另一方面,覆盖索引可提供更多查询。 在选择有效索引之前,最好先测试许多方案和工作负载。
There are two main types of indexes in SQL server; Clustered and non-clustered indexes. The clustered index controls the sort of the data pages in the disk, including all the columns in the table, although the index is created by one column only. The non-clustered index does not specify the real data order.
SQL Server中有两种主要的索引类型: 集群索引和非集群索引。 聚集索引控制磁盘中数据页的排序,包括表中的所有列,尽管索引仅由一列创建。 非聚集索引未指定实际数据顺序。
SQL Server Indexes can be categorized also to other types, such as the composite index; which is an index that contains more than one column. Unique index; which ensures the uniqueness of each value in the indexed column or columns as a whole. The last type is the covering index which contains all columns needed for a specific query.
SQL Server索引也可以归类为其他类型,例如复合索引; 这是一个包含多个列的索引。 唯一索引; 这样可以确保一个或多个索引列整体中每个值的唯一性。 最后一种类型是覆盖索引,其中包含特定查询所需的所有列。
我们如何克服非聚集索引设计的局限性? ( How could we overcome the non-clustered index design limitations? )
Non-Clustered index is created by adding key columns that are restricted in the number, type and size of these columns. To overcome these restrictions in the index keys, you could add a non-key columns when creating a non-clustered index, which are the Included Columns. The Included columns option is only available to the non-clustered index and not available to the clustered indexes.
通过添加在这些列的数量,类型和大小上受限制的关键列来创建非聚集索引。 为了克服索引键中的这些限制,您可以在创建非聚集索引时添加一个非键列,即包含列。 “包括的列”选项仅对非聚集索引可用,而对聚集索引不可用。
A column cannot be involved as key and non-key in the same index. It is either a key column or a non-key, included column. The main difference between the key and non-key columns is in the way it is stored in the index. The key column stored in all the levels of the index B-tree structure, where the non-key column stored in the leaf level of the B-tree structure only.
在同一索引中,列不能作为键和非键参与。 它可以是键列,也可以是非键包含列。 键和非键列之间的主要区别在于它在索引中的存储方式。 键列存储在索引B树结构的所有级别中,其中非键列仅存储在B树结构的叶级别中。
数据类型 ( Data Type )
Included columns can be varchar (max), nvarchar(max) , varbinary(max) or XML data types, that you cannot add it as index keys. Computed columns can also be used as included columns.
包含的列可以是varchar(max),nvarchar(max),varbinary(max)或XML数据类型,您不能将其添加为索引键。 计算列也可以用作包含列。
You should take into consideration that adding these large data types as non-key columns will increase the disk space requirements, as the column values will be copied into the index leaf level in addition to the table or clustered index.
您应考虑将这些大数据类型添加为非关键列会增加磁盘空间需求,因为除了表索引或聚集索引外,列值还将复制到索引叶级别。
On the other hand, you still can’t use TEXT, NTEXT and IMAGE as included columns.
另一方面,您仍然不能使用TEXT,NTEXT和IMAGE作为包含的列。
索引大小 ( Index Size )
Included columns can’t exceed its size limit, which is 900 byte only for index keys. So, when designing your index with large index key size, only columns used for searching and lookups are key columns, and all other columns that cover the query are non-key columns. As a result, you have all columns needed to cover the query, at the same time, the index size is small.
包含的列不能超过其大小限制,该大小限制仅对于索引键为900字节。 因此,在设计具有大索引键大小的索引时,只有用于搜索和查找的列才是键列,而覆盖查询的所有其他列都是非键列。 结果,您具有覆盖查询所需的所有列,同时,索引大小很小。
列数 ( Number of Columns )
Non-clustered index can contain up to 16 index keys; where you are not restricted with this number in the included columns. But you should take into consideration that creating indexes using large number of keys is not commonly used or recommended. In SQL Server, you can include up-to 1023 columns per each non-clustered index. But you have to add minimum one key column to your non-clustered index in order to create it.
非聚集索引最多可以包含16个索引键; 在包含的列中,您不受此数字的限制。 但是,您应该考虑到不建议使用大量键来创建索引。 在SQL Server中,每个非聚集索引最多可以包含1023列。 但是您必须在非聚集索引中至少添加一个键列才能创建它。
覆盖指数 ( Covering Index )
Indexes with included columns provide the greatest benefit when covering the query. This means that the index includes all columns referenced by your query, as you can add columns with data types, number or size not allowed as index key columns.
包含查询的索引具有最大的优势。 这意味着索引包括查询所引用的所有列,因为您可以添加数据类型,数字或大小不允许的列作为索引键列。
Performance gains are achieved as the query optimizer can locate all the column values within the index in fewer disk I/O operations; as the table or clustered index data is not accessed. However, having too many included columns may increase the time required to perform insert, update, or delete operations to your table.
由于查询优化器可以用更少的磁盘I / O操作定位索引中的所有列值,因此可以提高性能。 因为不访问表或聚集索引数据。 但是,包含的列过多可能会增加对表执行插入,更新或删除操作所需的时间。
Let’s have an example of creating a covering index with key and non-key columns and how this will enhance the query performance.
让我们举一个使用键列和非键列创建覆盖索引的示例,以及如何提高查询性能。
If we run the query below on the SQLShackDemo database, the execution plan generated using APEXSQL PLAN application will be like:
如果我们在SQLShackDemo数据库上运行以下查询,则使用APEXSQL PLAN应用程序生成的执行计划将类似于:
-
USE SQLShackDemo
-
GO
-
SELECT CountyCode, FirstName,Lastname,Age
-
FROM CountryInfo2
-
WHERE Age >25;
-
GO
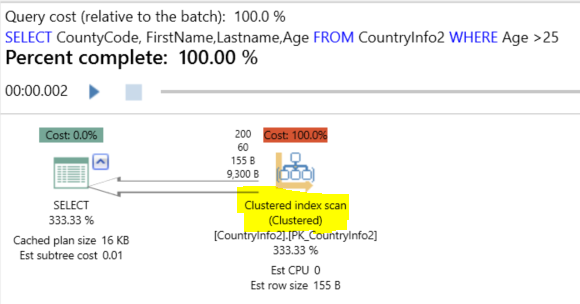
Index Scan means that the search will touch all rows in your table if needed or not, with cost proportional to the number of rows in your table. It is not a bad issue if you have a small table with few number of records.
On the other hand, the Index Seek indicates that the search will touch only the rows that meet a specific criteria, with the cost proportional to the number of rows in the table that meet that criteria, not the whole table rows.
索引扫描意味着如果需要,搜索将触及表中的所有行,而成本与表中的行数成正比。 如果您有一个带有少量记录的小表,这不是一个坏问题。
另一方面,“索引搜索”指示搜索将仅触摸满足特定条件的行,而成本与表中满足该条件的行数成正比,而不是整个表行。
To resolve the scan performance issue, we will creating non-clustered index on CountryInfo2 table to cover our query, by adding the predicate column in the WHERE clause as key column and the rest of columns that will be retrieved in the SELECT statement as non-key columns as below:
为解决扫描性能问题,我们将在WHERE子句中将谓词列添加为键列,并将在SELECT语句中检索为非列的其余列添加到CountryInfo2表上以创建非簇索引以覆盖查询关键列如下:
-
USE [SQLShackDemo]
-
GO
-
CREATE NONCLUSTERED INDEX [IX_CountryInfo2_Age] ON [dbo].[CountryInfo2]
-
(
-
[Age] ASC
-
)
-
INCLUDE ( [CountyCode],
-
[FirstName],
-
[Lastname]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
-
GO
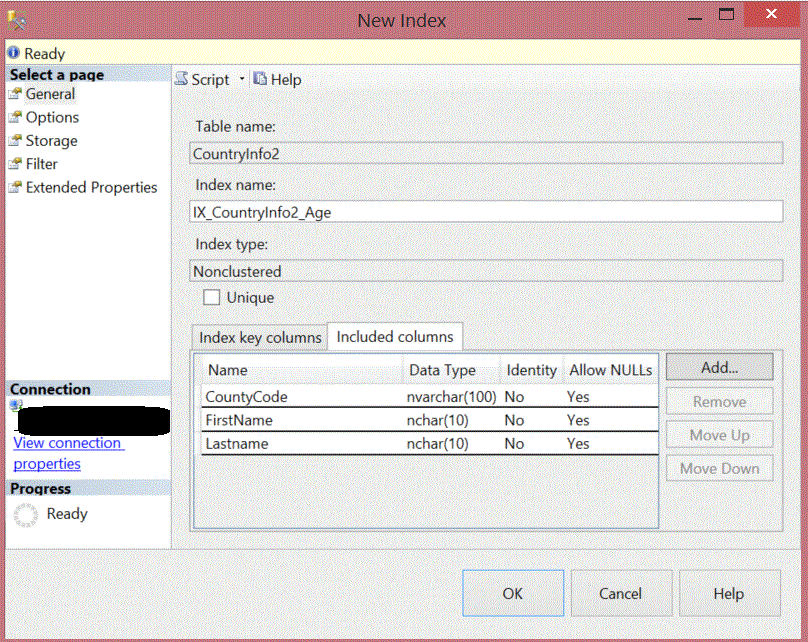
Adding included columns can also be done using the Management Studio from the New Index window. From this window, you can choose the key and non-key columns, also you can sort or remove it as below:
也可以使用“新建索引”窗口中的Management Studio添加包含的列。 在此窗口中,您可以选择键和非键列,也可以按以下方式对其进行排序或删除:
Try to run the same SELECT statement above, Index seek will be performed as all the data retrieved included in that index without touching the table or the clustered index as below:
尝试运行与上面相同的SELECT语句,索引查找将作为该索引中包含的所有检索到的数据执行,而不用触摸表或聚集索引,如下所示:
Once the non-clustered index created, you can’t drop any index non-key column unless you drop the index first. Also these non-key columns can’t be changed except changing it from NOT NULL to NULL or increasing the length of varchar, nvarchar, or varbinary columns.
一旦创建了非聚集索引,您将无法删除任何索引非键列,除非您先删除索引。 这些非关键列也不能更改,除非将其从NOT NULL更改为NULL或增加varchar , nvarchar或varbinary列的长度。
Badly designed SQL Server indexes or missing ones are the main cause of the slowness in most environments. Plan and study deeply, test many scenarios and finally decide which one is suitable for your situation. Review the index usage regularly in order to remove unused indexes and plan to add the missing ones
在大多数环境中,设计不良SQL Server索引或缺少索引是导致速度缓慢的主要原因。 进行深入计划和研究,测试许多方案,最后决定哪种方案适合您的情况。 定期检查索引使用情况,以删除未使用的索引并计划添加缺失的索引
翻译自: https://www.sqlshack.com/sql-server-non-clustered-indexes-with-included-columns/
2024-04-10 11:00:53【出处】:https://blog.csdn.net/culuo4781/article/details/107626103
=======================================================================================


如果,您希望更容易地发现我的新博客,不妨点击一下绿色通道的【关注我】。(●'◡'●)
因为,我的写作热情也离不开您的肯定与支持,感谢您的阅读,我是【Jack_孟】!
本文来自博客园,作者:jack_Meng,转载请注明原文链接:https://www.cnblogs.com/mq0036/p/18125611
【免责声明】本文来自源于网络,如涉及版权或侵权问题,请及时联系我们,我们将第一时间删除或更改!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号