如何用Python调试 debug
什么是调试,为什么我们需要调试
这里借用南京大学 蒋炎岩 老师的ppt

在计算机中 ,我们将机器看作状态机,同时我们遵循计算机不会犯错的原则,因此,当你设计的程序产生了与你意料相悖的结果,那就可以认为你的程序产生了bug。
调试理论中的状态机
我们将程序可以看成一个状态机,程序的不断执行就是状态机状态的不断变化,出现bug的程序一定在某个环节后发生了异常,也就是error,从而引发了最终程序的failure。
在现在软件中,bug可以分为如下的两类
- 理解需求的不同产生的bug:我们在设计程序时偏离了最初规划的功能,导致最后设计出的程序没有办法完好的满足用户需求,这就属于第一类bug。
- 具体实现中的bug:因为技术原因,在实现过程中,我们实现的程序不能很好地完成为其设定的任务,究其根本是我们为这个任务设定的数学模型存在纰漏,这就属于第二类bug。
这里以我们的OJ举例,完成OJ上任务的基本步骤就是读懂题面,了解你要实现什么样的程序,接着写出相对应的程序,也就是在数学上实现这个问题的解,第一步对于我们而言都比较简单,而第二步,也是我们最容易犯,最需要注意,最需要debug的部分。
程序具体实现中的bug
在一个程序的实现中,我们会经历编写程序,程序编译,程序运行这几个过程,在现代化的ide中,很多编辑器已经能够为我们自动指出编写程序时的基本错误
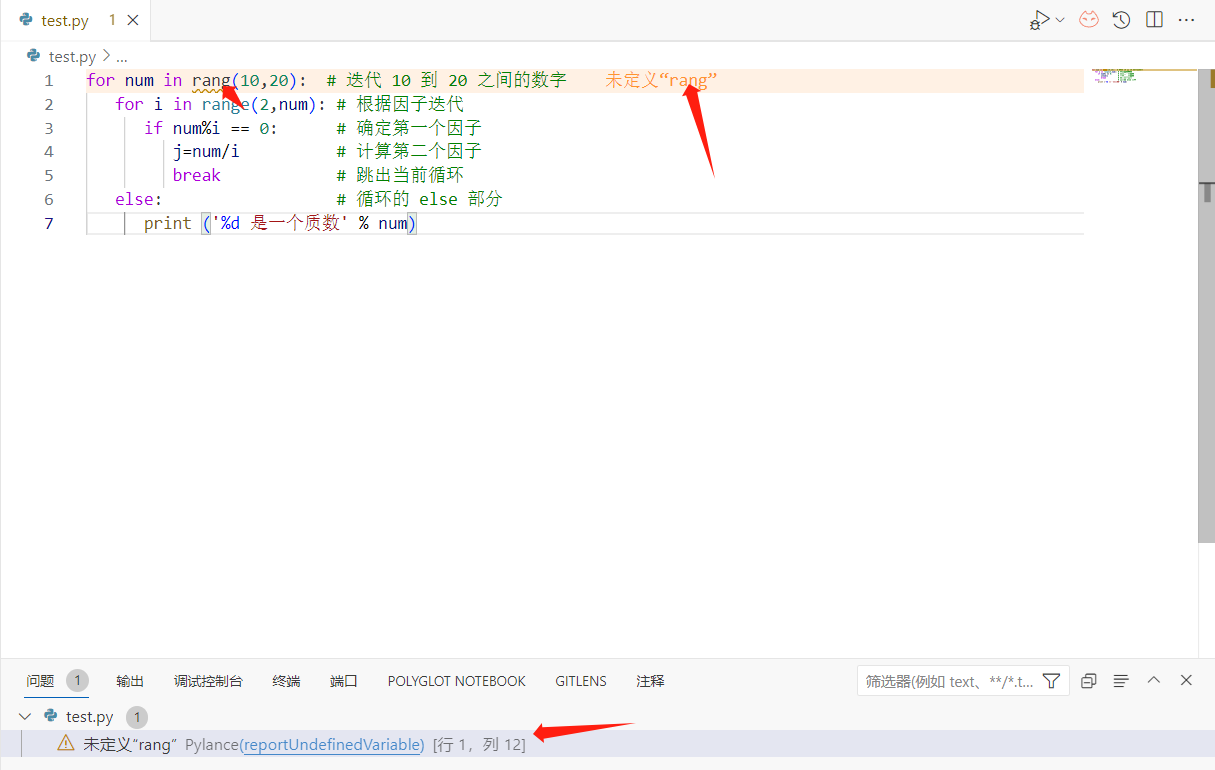
笔者使用的vscode已经为我自动标注出了错误的语法部分,这类问题的检测正是通过我们本地的python解释器完成的,所以即使没有编辑器的标注,我们在运行这个程序时,解释器应该也能返回给我们同样的信息
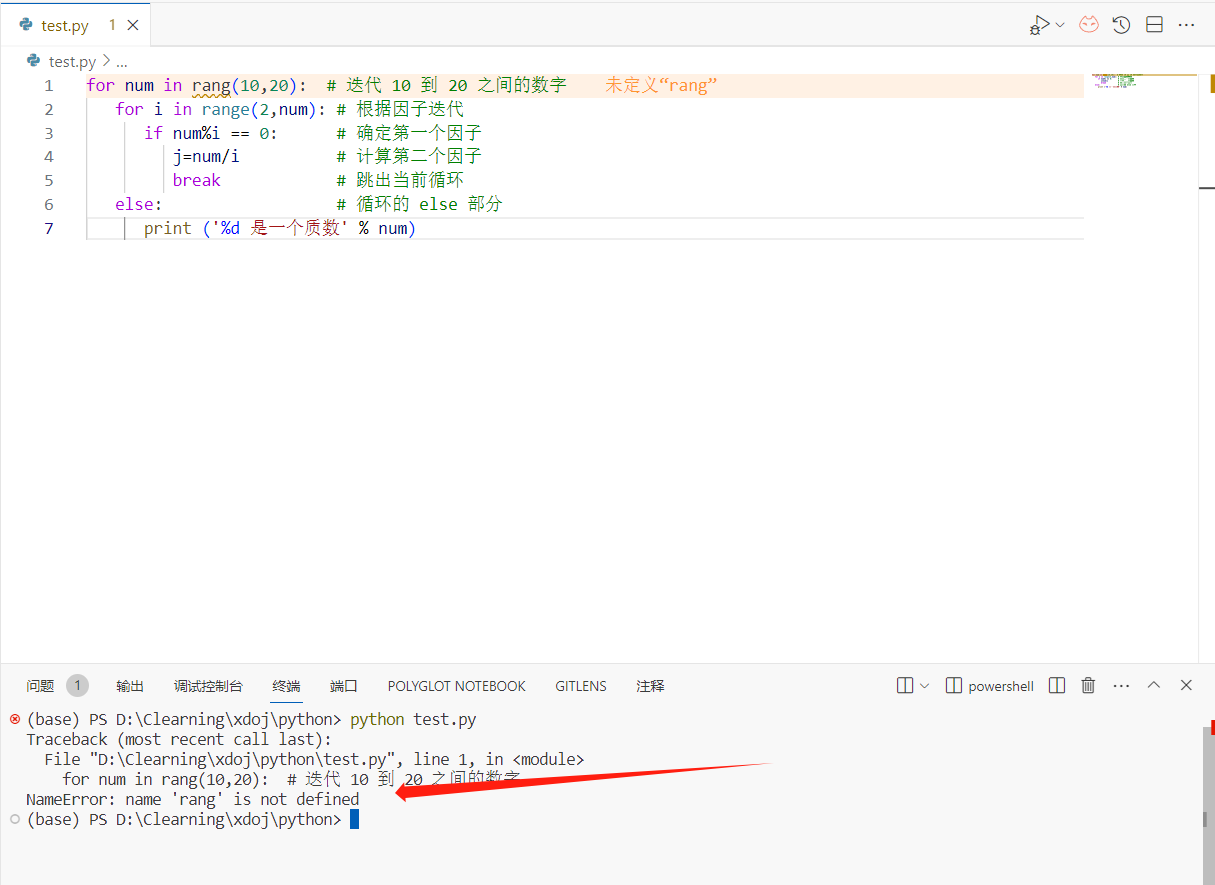
需要注意的是,编辑器仅仅只能够帮助我们指出程序的最基础的问题,例如函数的书写方式,api的调用方式,它并不能为我们指出一些隐性的逻辑问题,而这类错误的反馈往往只能从最终的结果获得,有时候我们甚至需要大量的测试数据才能找出这些隐藏较深的问题出来
同样以oj为例
我们在这里提出一个需求,我需要程序找出[10,20)之间的所有质数
for num in range(10,20): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)如下的代码也能输出相同的结果
for num in range(10,21): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)虽然上面的代码都能解决oj中的这个问题,但是当测试范围改变时,结果也会发生错误,而逻辑上的错误,解释器不会对其做出提醒和警告,这时候我们只能从错误的输出上判断出程序内部出现了问题,也就是bug。
事实上,调试的范围不仅仅局限于代码本身,当你的代码运行出现任何形式的问题,本着计算机不会犯错的原则,我们都需要对代码运行的环境,运行时的设置等进行调试。
在如上的调试理论指导下,我们可以确认调试的基本思想,尽可能的将bug在设计时变得更容易暴露出来,将某些关键的步骤进行可能的可视化。
python中的调试方法
看懂报错信息
如何正确的理解报错信息是完成调试任务的第一步,以前面举过的例子为例
printf('hello')
当我试图运行这行代码时,终端向我返回了这样的信息:
Traceback (most recent call last):
File "demo.py", line 1, in <module>
printf('hello')
NameError: name 'printf' is not defined当代码并没有按照我预想的输出 hello 时,程序内部可能发生了bug,这时解释器也向我返回了程序发生错误的信息,它告诉我在"demo.py"文件的第一行中,名为'printf'的函数并没有被定义,也就是这个函数并不存在。
由此,我修改了我的代码。
print('hello')
现在,这行代码可以正确的输出'hello'了,是不是很简单?
只要理解终端打印的基本错误信息,绝大多数的bug都可以像这样快速找到问题发生的位置然后调整。
以我们在介绍调试理论中举的例子为例
for num in range(10,21): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
我们希望它能够找出[10,20)内的所有质数,但上述的例子明显判断了[10,21)内的所有素数,两者虽然结果一致,python解释器也不会向我们返回任何的错误信息,但这段代码确实存在着逻辑上的bug。
这是,我们可以借用python中的print函数来帮助我们找出这个bug
for num in range(10,21): # 迭代 10 到 20 之间的数字
print(num)
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
我们可以利用print函数 来打印出num变量每个循环的状态
10
11
11 是一个质数
12
13
13 是一个质数
14
15
16
17
17 是一个质数
18
19
19 是一个质数
20通过观察,我们发现遍历过程中num变量值出现了20,所以原代码存在范围上的错误。
assert
这里再介绍一种调试方法,我们选择利用Python中的assert函数来完成
先简单介绍一下assert
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况。
同样用上面的例子,我会为你展示assert的使用方法
assert语法格式如下:
assert expression
# 上下两种表达式相互等价
if not expression:
raise AssertionError同样可以在assert语句后增加参数
assert expression [, arguments]
# 上下两种表达式相互等价
if not expression:
raise AssertionError(arguments)
也许还是有点不明白?我们接着往下看
我们试着利用assert函数来帮助我们解决之前举的例子
for num in range(10,21): # 迭代 10 到 20 之间的数字
assert num<20, "n超出了范围!"
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
(pytorch) PS D:\Datawhale> python demo.py
11 是一个质数
13 是一个质数
17 是一个质数
19 是一个质数
Traceback (most recent call last):
File "demo.py", line 2, in <module>
assert num<20, "n超出了范围!"
AssertionError: n超出了范围!这里在执行过程中,assert帮我捕捉到了num已经超过20的信息然后成功告诉了我此时的n已经超出了范围,我们利用assert完成了一次成功的调试。
利用vscode来完成调试
调试的前期准备
在安装python运行环境时,很多同学可能会选择安装更加现代的编辑器来帮助我们完成编程的目的,这里笔者用自己常用的vscode 来介绍我们如何利用vscode来进行调试
首先,在使用vscode调试时,我们必须配置好vscode来让它正确的调试,告诉vscode,我需要用什么工具来对我的代码进行调试,我的工具在哪里,我要怎样启动他们。
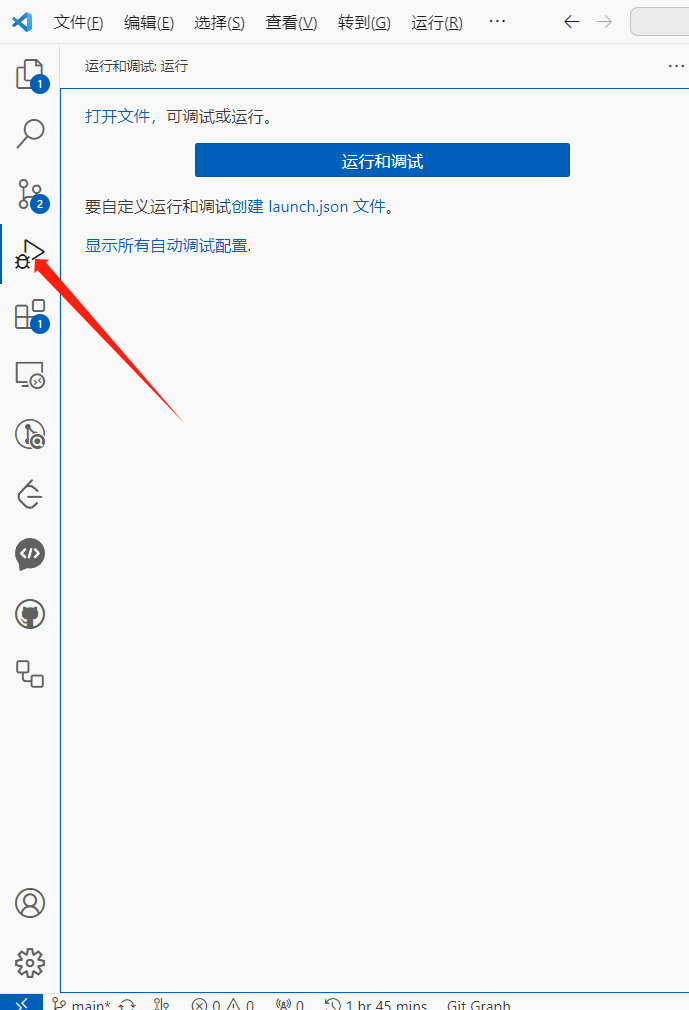
选择vscode侧边栏中的调试选项,也就是那只小虫子(或者按Crtl+shift+D)打开运行与调试选项
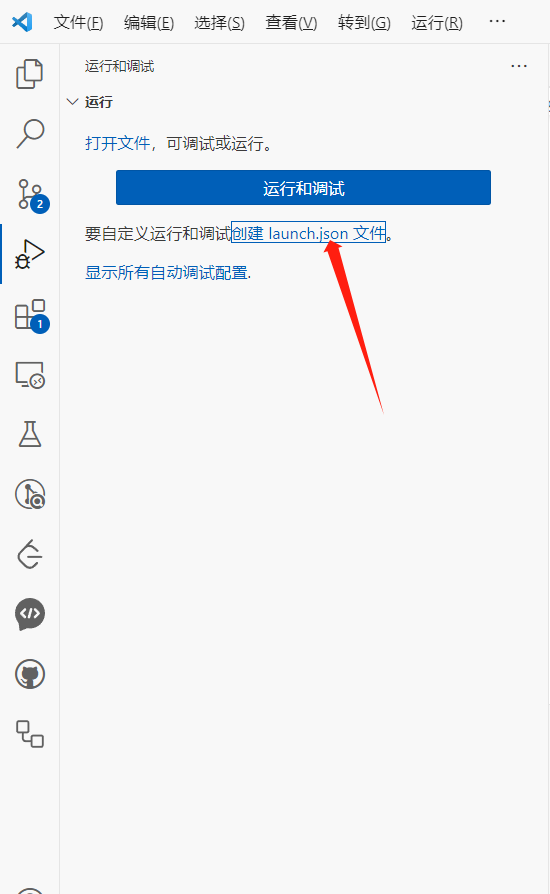
打开运行与调试选项后,我们需要创建配置文件,也就是这里的创建launch.json文件
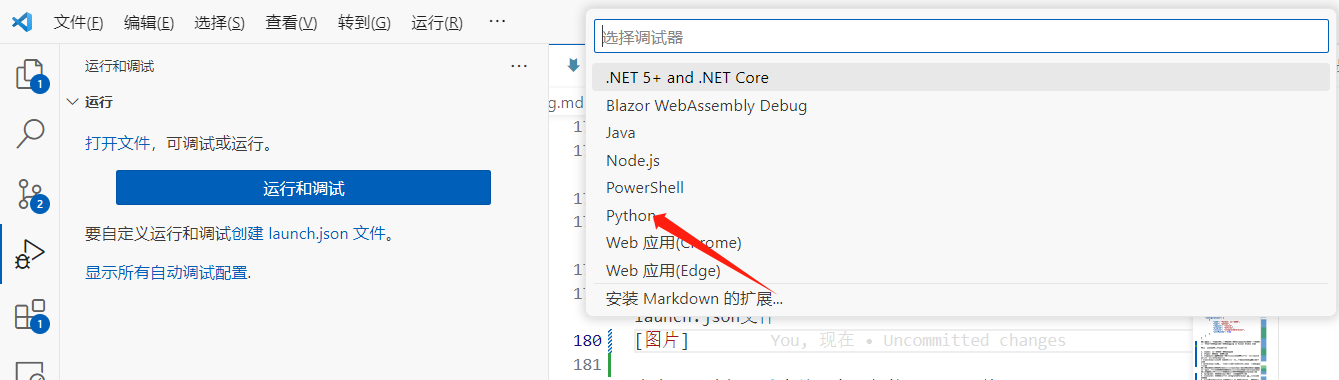
点击后,选择调试当前正在运行的python文件
接下来,你得到了写着如下内容的json文件
这里简单介绍一下
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: 当前文件",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": true
}
]
}
如果你想进一步了解这些配置文件是如何影响python调试过程的可以进一步查看文件提供的链接Debugging in Visual Studio Code
这里简单介绍这些字段的含义
- name: 当前DEBUG配置的名称。
- Type: 调试语言的种类。
- request是最重要的参数,它能选择两种类型,一个是launch模式,一个是attach模式:
- launch模式:由VS Code来启动一个独立的具有debug功能的程序。
- attach模式:监听一个已启动的程序(其必须已经开启debug模式)。
大多数情况下,调试Python都是用launch模式。少数情况下,你无法通过新建独立程序来调试(如要与浏览器相结合的程序,launch模式会导致你大部分浏览器插件失效),这时候就需要attach模式。
- program: 文件的绝对路径,一般不需要改动。
- console: 终端的类型, integratedTerminal 指使用vscode终端。
- justMyCode:
true只调试当前 py 文件,false也调试引用的模块,当你需要调试模块时请确保将它修改为false
如果你只是希望能够快速学会如何完成调试的基本准备,那么做到这里,你就完成了利用vscode调试python文件的前置准备,接下来就是调试的步骤。
调试的步骤
断点调试,断点调试是指在程序自动运行的过程中,在代码某一处打上断点,当程序运行至设置的断点位置处,程序将暂停下来,此时可以检查运行时的所有变量数据来检查程序内部是否出现问题。

当完成调试配置后,点击运行与调试选项,在代码的右边可以看到调试过程中的变量,以及调用堆栈的情况,单击代码行的左边(就是代码行数字的左边)可以创建一个断点,或者可以在同样的地方使用右键来添加条件断点记录点等
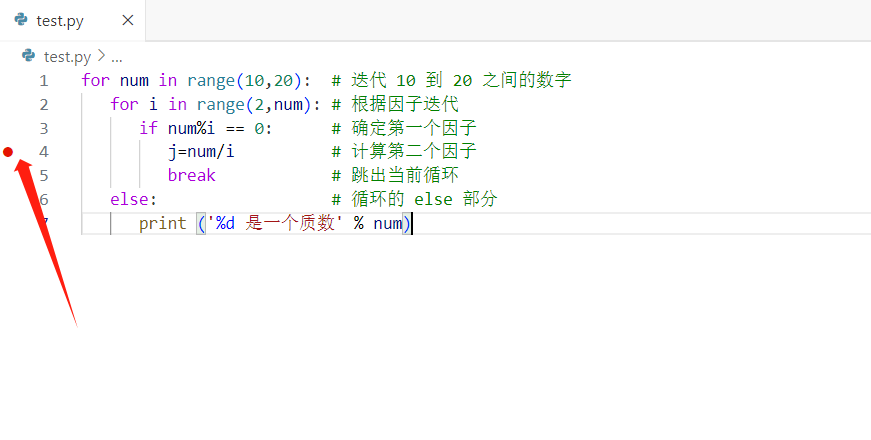
程序将在运行至断点位置时暂停。
完成断点设置后,我们在代码界面按下F5,或者在界面的右上角
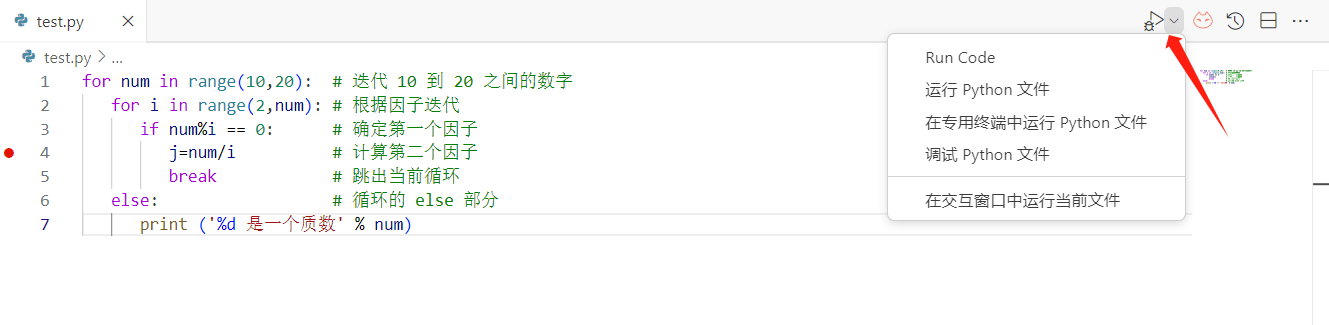
在如上位置选择调试python文件,点击后将启动调试过程。
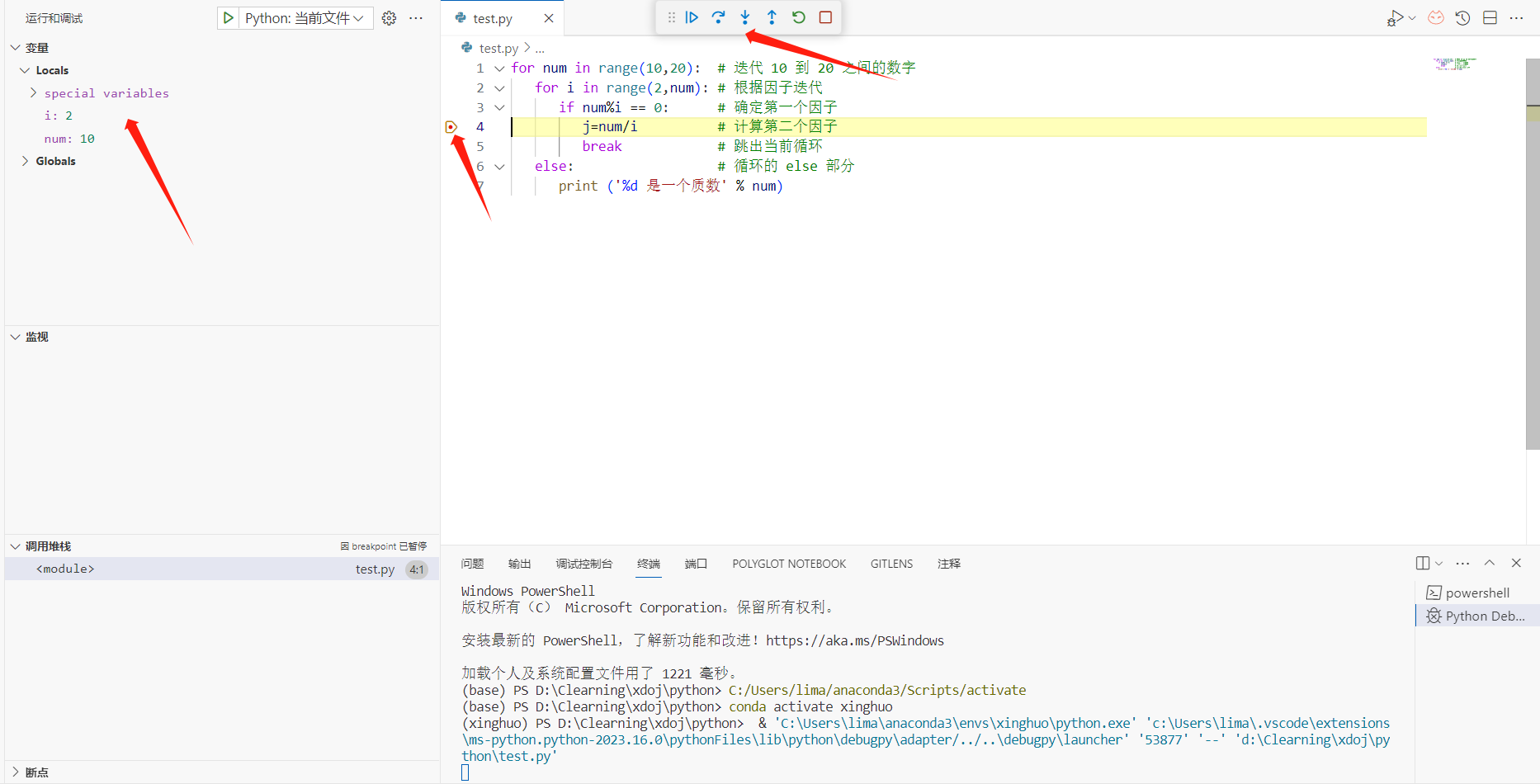
在代码行数字的左边的红色箭头将为我们指出代码目前暂停在什么位置
在代码上方的按钮 分别对应 继续 单步跳过 单步调试 单步跳出 重启 终止
- 选择继续 程序将继续运行,直到遇见下一个断点
- 选择单步跳过 程序将执行并跳过当前这一步代码
- 选择单步调试 程序将进入这行内的函数,展示函数内的运行步骤(这里没*有函数概念的同学可以在后面的学习结束后再回过头继续看)
- 选择单步跳出 程序将跳出目前所在的函数
- 选择重启 程序将重新启动调试
- 选择终止 程序将立刻终止
当我们在调试时,可以观察运行中变量是如何变化的,通过左侧的变量监控可以轻松获知当前有那些变量被声明,它们的值又是什么。
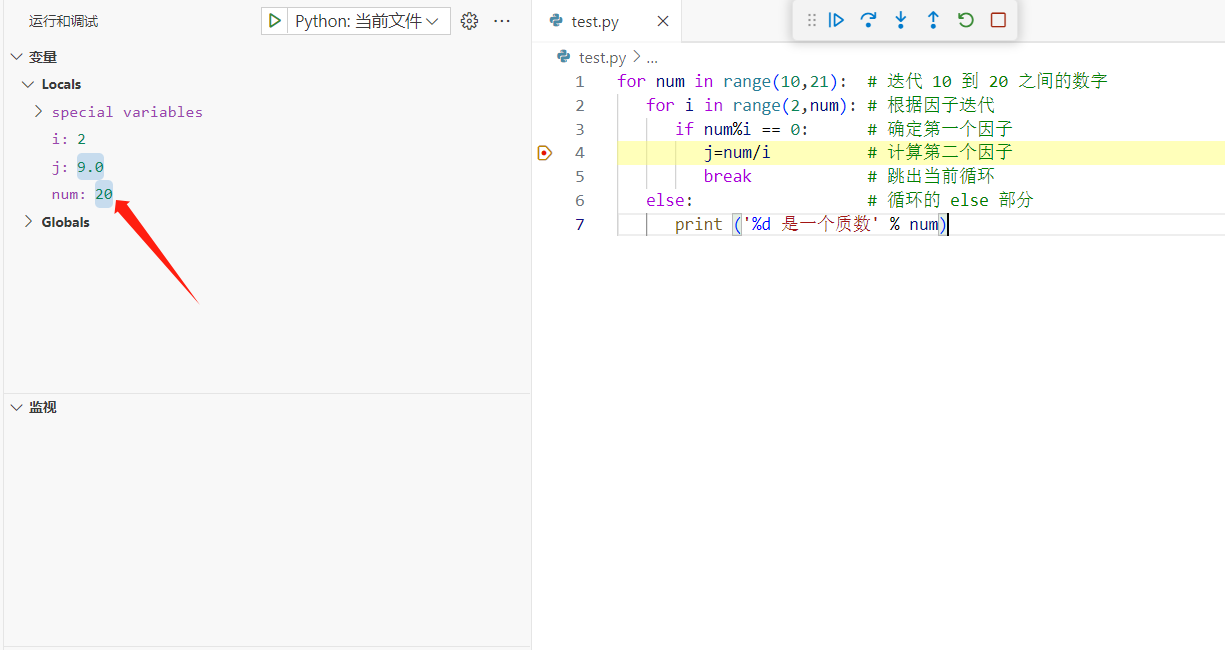
这里在运行中,我们观察到num的值已经超出了我们设定的范围,而程序依然在运行,成功找到了原代码存在的bug。
通过vscode进行调试的操作就是这些。
如何利用ai来帮助debug?
bito ai
在这里我将向你介绍如何使用ai来帮助我们快速debug,我使用的工具是 bito ai
从使用上来说,利用ai解决bug和从百度搜索bug解决方法类似,就是将问题塞给ai,让ai来帮你回答,但今天介绍的bito ai是一个vscode插件,
目前支持的功能有:
- 代码补全助手:使用深度学习模型进行代码补全和提示。可以根据变量、函数定义和调用关系进行准确地补全,最大限度减少打字量。
- 语法检查器:使用自然语言处理技术检查代码注释和变量名,确保其清晰、准确和连贯。可配置性很高,支持多种语言。
- 重构提示器:分析代码结构和逻辑,提出重构建议,使代码更加整洁清晰。采用AST分析,对各种语言都有很好的支持。
- 代码评论生成器:自动生成代码方法、类、文件等的注释。可以自动提取代码逻辑和功能,生成模板规范的注释。简化手动文档工作。
- 代码质量检测:通过静态代码分析,检测出未处理异常、资源泄漏、安全漏洞等代码缺陷。提供修复提示,在开发过程中及早发现和解决问题。
- Todo高亮和提示:通过自然语言理解,检测代码中的Todo项并进行分类和高亮。按优先级和截止时间给出提醒,使Todo不遗漏。
我将在下面为你展示我是如何用它来debug的:
获取bito ai
Bito ai 是vscode 的一个插件,你可以在vscode的插件扩展里找到它
点击获取之后,你就可以在最左侧的活动栏里找到它的图标

使用bito ai
Bito ai 支持像gpt一样的直接询问,你可以把它当成gpt来使用,同时内部内置了很多有用的prompt来帮你快速上手它的使用
像这样直接向bito ai 提问
或者利用它内置的prompt提问,你可以用鼠标右键快速完成提问
总而言之,合理利用手边的工具来帮助你debug吧!
调试进阶
下面的内容需要一定的模块基础,如果你理解困难,不要灰心,可以等后面的学习结束后来回看
logging
参考连接:https://zhuanlan.zhihu.com/p/166671955
模块介绍
在实际的工程项目中,我们需要保存程序运行的日志,以排查程序在某一个时候崩溃的具体原因,以便及时定位Bug进行抢救,而在Python中,logging就可以十分灵活的帮助我们记录程序运行的过程的中的一些信息。
那么日志的作用是什么呢?
归纳起来日志的作用有三点:
- 进行程序(代码)的调试
- 程序运行过程中的问题定位和分析
- 收集程序运行的情况
logging中将日志等级分成如下几个(由低到高):
DEBUG INFO WARNING ERROR CRITICAL
它们代表着不同的日志展示等级,在使用中,我们最常用的方法是logging.basicConfig()
该方法支持以下关键字参数:
filename
指定使用指定的文件名而不是 StreamHandler 创建 FileHandler。
filemode
如果指定 filename,则以此模式打开文件(‘r’、‘w’、‘a’)。默认为“a”。
format
为处理程序使用指定的格式字符串。
datefmt
使用 time.strftime() 所接受的指定日期/时间格式。
style
如果指定了格式,则对格式字符串使用此样式。’%’ 用于 printf 样式、’{’ 用于 str.format()、’$’ 用于 string。默认为“%”。
level
将根记录器级别设置为指定的级别。默认生成的 root logger 的 level 是 logging.WARNING,低于该级别的就不输出了。级别排序:CRITICAL > ERROR > WARNING > INFO > DEBUG。(如果需要显示所有级别的内容,可将 level=logging.NOTSET)
stream
使用指定的流初始化 StreamHandler。注意,此参数与 filename 不兼容——如果两者都存在,则会抛出 ValueError。
handlers
如果指定,这应该是已经创建的处理程序的迭代,以便添加到根日志程序中。任何没有格式化程序集的处理程序都将被分配给在此函数中创建的默认格式化程序。注意,此参数与 filename 或 stream 不兼容——如果两者都存在,则会抛出 ValueError。
这段代码主要是用来配置日志的输出的,代码会将level以上级别日志输出,我们在这里就设置为INFO以上级别信息输出
在下面做一个logging模块的简单使用演示
具体使用
我会在这里展示如何使用logging来完成对例子的调试,需要确保你已经获取了logging模块,如果执行下面的代码失败显示import error,还记得我们之前讲的吗,看看终端告诉你,问题发生在了哪里。
import logging
logging.basicConfig(level=logging.INFO)
for num in range(10,21): # 迭代 10 到 20 之间的数字
logging.info(num)
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
控制台输出如下:
(pytorch) PS D:\Datawhale> python demo.py
INFO:root:10
INFO:root:11
11 是一个质数
INFO:root:12
INFO:root:13
13 是一个质数
INFO:root:14
INFO:root:15
INFO:root:16
INFO:root:17
17 是一个质数
INFO:root:18
INFO:root:19
19 是一个质数
INFO:root:20在上面,我们首先导入了logging这个包,同时我们指定了记录信息的级别为info,此时只有info级别的信息与比info级别更高的信息会被输出到终端,同时,我们还可以将信息记录在文件中,你可以采取下面的写法
import logging
logging.basicConfig(filename='log.txt',
format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s-%(funcName)s',
level=logging.INFO)
for num in range(10,21): # 迭代 10 到 20 之间的数字
logging.info(num)
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
运行上面的代码后,你将能够在同级目录下发现一个名为log.txt的文件,文件内的输出如下
2023-03-26 19:47:47,807 - root - INFO - 10-<module>
2023-03-26 19:47:47,807 - root - INFO - 11-<module>
2023-03-26 19:47:47,807 - root - INFO - 12-<module>
2023-03-26 19:47:47,807 - root - INFO - 13-<module>
2023-03-26 19:47:47,808 - root - INFO - 14-<module>
2023-03-26 19:47:47,808 - root - INFO - 15-<module>
2023-03-26 19:47:47,808 - root - INFO - 16-<module>
2023-03-26 19:47:47,808 - root - INFO - 17-<module>
2023-03-26 19:47:47,808 - root - INFO - 18-<module>
2023-03-26 19:47:47,808 - root - INFO - 19-<module>
2023-03-26 19:47:47,808 - root - INFO - 20-<module>如上就是一个利用logging来完成这个调试过程的简单步骤,我强烈建议想要深入了解的同学们可以进一步查询logging模块的其他函数以及其参数介绍,充分了解这个日志输出工具。
利用pdb进行调试
模块介绍
强烈建议大家有机会读读pdb文档内容pdb — Python 的调试器
https://blog.csdn.net/qq_43799400/article/details/122582895
具体使用
我会在这里展示如何使用pdb来完成对例子的调试,需要确保你已经获取了pdb模块,如果执行下面的代码失败显示import error,还记得我们之前讲的吗,看看终端告诉你,问题发生在了哪里。
非侵入式调试
首先,我们采用非侵入式的方法调试原代码,运行下面的代码,在终端中启动对示例代码的调试
python -m pdb demp.py
启动后,终端输出如下,它输出了当前代码运行的位置,同时等待你的一下步指令。
> d:\datawhale\demo.py(1)<module>()
-> for num in range(10,21): # 迭代 10 到 20 之间的数字
(Pdb)
常用的指令如下
| 命令 | 解释 |
|---|---|
| break 或 b | 设置断点 |
| continue 或 c | 继续执行程序 |
| list 或 l | 查看当前行的代码段 |
| step 或 s | 进入函数(进入 for 循环用 next 而不是用 step) |
| return 或 r | 执行代码直到从当前函数返回 |
| next 或 n | 执行下一行 |
| up 或 u | 返回到上个调用点(不是上一行) |
| p x | 打印变量x的值 |
| exit 或 q | 中止调试,退出程序 |
| help | 帮助 |
你不需要记住这么多的命令,可以随时在pdb界面中使用help 来查看都有些什么命令
(pytorch) PS D:\Datawhale> python -m pdb demo.py
> d:\datawhale\demo.py(1)<module>()
-> for num in range(10,21): # 迭代 10 到 20 之间的数字
(Pdb) help
Documented commands (type help <topic>):
========================================
EOF c d h list q rv undisplay
a cl debug help ll quit s unt
alias clear disable ignore longlist r source until
args commands display interact n restart step up
b condition down j next return tbreak w
break cont enable jump p retval u whatis
bt continue exit l pp run unalias where
Miscellaneous help topics:
==========================
exec pdb试着看看q指令
(Pdb) help q
q(uit)
exit
Quit from the debugger. The program being executed is aborted.
(Pdb)
侵入式调试
接下来,我们采用侵入式的方法调试原代码
import pdb
pdb.set_trace()
for num in range(10,21): # 迭代 10 到 20 之间的数字
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
导入pdb 并设置断点
此时运行代码
(pytorch) PS D:\Datawhale> python demo.py
> d:\datawhale\demo.py(3)<module>()
-> for num in range(10,21): # 迭代 10 到 20 之间的数字
(Pdb)
我们成功启动了pdb来帮助调试
你也可以设置多个断点
import pdb
pdb.set_trace()
for num in range(10,21): # 迭代 10 到 20 之间的数字
pdb.set_trace()
for i in range(2,num): # 根据因子迭代
if num%i == 0: # 确定第一个因子
j=num/i # 计算第二个因子
break # 跳出当前循环
else: # 循环的 else 部分
print ('%d 是一个质数' % num)
如何利用pdb进行调试的简单介绍就到这里。
利用vscode完成带参调试
这部分的官方文档,请参考:
https://code.visualstudio.com/docs/python/debugging#_set-configuration-options
利用launch.json文件完成带参调试
在前面的内容中,我们已经聊了如何利用vscode来完成调试,但这种方式仅仅适合无参运行python脚本时使用,接下来我们将利用vscode中的launch.json文件来完成带参调试
那么什么场景下我们需要带参调试呢?
下面的代码是一个应用场景的示范:(关于argparse你可以参考:https://zhuanlan.zhihu.com/p/56922793)
import argparse
parser = argparse.ArgumentParser(description='命令行中传入的数字')
#type是要传入的参数的数据类型 help是该参数的提示信息
parser.add_argument('integers', type=str, help='传入的数字')
args = parser.parse_args()#获得传入的参数
print(args)
当我们在运行这段代码时,我们需要在命令行内指定运行参数
(base) PS D:\Clearning\xdoj\python> python demo.py
usage: demo.py [-h] integers
demo.py: error: the following arguments are required: integers上面在运行时 因为没有携带参数而报错
(base) PS D:\Clearning\xdoj\python> python demo.py 6
Namespace(integers='6')
(base) PS D:\Clearning\xdoj\python> 可以看到,我们正确运行了上面的这个文件
那么,如何在vscode中完成调试呢?
首先我们仿照前文中的步骤创建launch.json文件,在其中添加 "args" 参数
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: 当前文件",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": true,
"args": ["6"]
}
]
}
接下来,我们在debug界面选择我们刚才创建好的这个launch.json debug配置文件
接下来试着打上断点运行,可以看到,运行成功了!
杂谈
如何避免程序中因为调试而浪费资源?
在Talk2 介绍的前两种报错方法(利用print assert完成调试)中,虽然这两种方法理解简单,上手容易,但是由于两种方法自身的缺陷,它们或多或少都存在一定的问题
print
- 调试信息与代码混杂在一起,使代码难以阅读和维护。
- 在调试完成后,需要手动删除或注释掉调试信息,否则会影响代码的性能和可读性。
- 在多线程或异步编程中,使用print方法进行调试可能会导致输出信息的混乱和不可控。
assert
- assert方法只能用于检查程序的假设条件,不能用于捕获和处理异常。
- assert方法只能在调试期间使用,不能用于生产环境。
- assert方法不能提供详细的错误信息,只能提供简单的错误提示。
同时对于不同级别的问题,我们应当采用不同的处理方法,下面具体介绍一下如何利用logging模块来完成我们的需求:
当使用logging模块时,可以使用不同的日志级别来记录不同严重程度的日志信息。以下是logging模块中不同的日志级别:
- DEBUG:最详细的日志信息,通常只在调试时使用。
- INFO:确认一切按预期运行。
- WARNING:表示发生了一些意外情况或潜在的问题,但程序仍然可以正常运行。
- ERROR:由于更严重的问题,程序无法执行某些功能。
- CRITICAL:严重错误,程序可能无法继续运行。
以下是如何使用这些日志级别的示例:
import logging
logging.basicConfig(level=logging.DEBUG)
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')
在这个例子中,我们将日志级别设置为DEBUG,这意味着所有级别的日志信息都将被记录。然后,我们添加了五个不同级别的日志信息,从DEBUG到CRITICAL。在运行程序时,只有级别大于或等于设置的级别的日志信息才会被记录。
如果我们将日志级别设置为WARNING,那么只有WARNING、ERROR和CRITICAL级别的日志信息才会被记录。以下是一个示例:
import logging
logging.basicConfig(level=logging.WARNING)
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')
在这个例子中,只有WARNING、ERROR和CRITICAL级别的日志信息被记录,而DEBUG和INFO级别的日志信息被忽略。
通过使用不同级别的日志信息,我们可以更好地了解程序的运行状态并更轻松地调试和排除问题。
内容依然会持续更新,如果您有更好的debug技巧,欢迎您参与该文章内容的贡献!
联系方式:azula_fire@163.com
【出处】:https://blog.csdn.net/limafang/article/details/133146469
=======================================================================================
python如何单步调试?
调试是程序员在编写代码时必不可少的过程,它可以帮助我们找出程序中的错误并解决它们。Python 作为一门流行的语言,也提供了很多方便的调试工具,其中单步调试就是其中之一。本文将介绍 Python 的单步调试工具及其使用方法。
一、单步调试的概念
单步调试是一种逐步执行程序并观察每个步骤的调试方法。它允许程序员在程序中设置断点,然后逐行执行代码,在每个断点处暂停程序并检查变量值、函数返回值等信息。这种方法可以帮助我们快速地发现代码中的错误和问题,提高程序的调试效率。
二、Python 的单步调试工具
Python 提供了多种单步调试工具,其中较为常用的有以下几种:
1. pdb
pdb 是 Python 的内置调试器,它可以让我们逐行执行代码并查看变量值、函数返回值、堆栈信息等。使用 pdb 调试程序的方式非常简单,只需要在代码中添加如下语句:
```
import pdb
pdb.set_trace()
```
执行到这个语句时,程序会进入调试模式并暂停,我们就可以通过命令行交互式界面来逐步执行代码、查看变量值等信息。pdb 提供了很多命令,比如 n(next)表示执行下一行代码,s(step)表示进入当前行的函数中,c(continue)表示继续执行程序直到下一个断点等等。更多详细的命令可以通过在 pdb 中输入 h(help)来查看。
2. ipdb
ipdb 是 pdb 的增强版,它提供了更多的功能和更友好的交互界面。使用方式与 pdb 类似,只需要在代码中添加如下语句:
```
import ipdb
ipdb.set_trace()
```
执行到这个语句时,程序会进入 ipdb 的调试模式,并提供了更多的命令和交互式界面,比如 ll(long list)可以查看当前函数的全部代码、u(up)可以进入调用当前函数的函数等等。更多详细的命令可以通过在 ipdb 中输入 h(help)来查看。
3. PyCharm 调试器
PyCharm 是一款流行的 Python 开发集成环境,它内置了强大的调试器。使用 PyCharm 调试器调试 Python 程序非常方便,只需要在代码中添加断点,然后点击调试按钮即可进入调试模式。在调试模式下,我们可以逐行执行代码、查看变量值、堆栈信息等,还可以通过调试控制台进行交互式调试。PyCharm 调试器的使用方法可以参考官方文档。
三、结语
Python 的单步调试工具为我们提供了很多方便,可以帮助我们快速地发现代码中的问题并解决它们。在实际开发中,我们可以根据自己的习惯和需求选择合适的调试工具来提高开发效率。
出处:https://www.ycpai.cn/python/FfgvDTX6.html


如果,您希望更容易地发现我的新博客,不妨点击一下绿色通道的【关注我】。(●'◡'●)
因为,我的写作热情也离不开您的肯定与支持,感谢您的阅读,我是【Jack_孟】!
本文来自博客园,作者:jack_Meng,转载请注明原文链接:https://www.cnblogs.com/mq0036/p/18002341
【免责声明】本文来自源于网络,如涉及版权或侵权问题,请及时联系我们,我们将第一时间删除或更改!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号