博客园自己的备份功能,备份文章
为什么要备份博客?
首先希望你是一个认真对待博客的人,其次,如果你又是一个爱惜自己物品的人,或者你有强迫症(完美主义倾向),你一定不希望哪天登录博客园翻看自己的某篇博客时突然发现这种情况——自己之前写的博客怎么缺失了一半!!!另外一半呢??? @_@
于是找到博客园团队,发了一封求救信,可结果却是这样:

然后呢?小编想说然后就没有然后了(没有备份自己只能默默重写了 Orz)。虽然发生这种情况的几率很小,但也要防患于未然,于是我们就可以选择一种保险的做法——备份(博客)。因此,从专业一点的角度上讲,备份工具 可以保护数据免受意外的损失,而 备份博客 就是为了应付博客中数据丢失等可能出现的意外情况。至于为什么会发生数据丢失,小编觉得仅就博客园丢失博客的数据而言,可能是当时的网络环境比较差,并且你在博客园加载某篇博客的 TextView 时(还未加载完毕)就点了保存,服务器正在缓存,还没有将你之前博客的数据加载完全,这就导致了一部分数据的丢失。
在你下次翻看自己之前的博客时,就会不经意地发现:自己有一篇博客的 XXX内容 竟然奇迹般地消失了!?点了一下刷新,没用,再点刷新,还是没用,慌乱的你想进去看个究竟于是直接点击了编辑,结果这部分内容真的就这样消失了!
(丢失博客的截图.pnp)
小编已有1年多的园龄了,在这段时光里,小编不幸地遇到了两次博客数据丢失的“灾难”,第一次遇到的时候不知所措,完全傻了眼,现在多了些经验教训,遂借此篇博客进行总结和分享,并提醒更多博主定期做好“保养”博客的工作。如果有备份,就能“以防万一”了:

如何在博客园备份博客?
我们一般使用一些大容量存储设备定期备份系统、使用U盘等中小容量存储设备来备份一些重要数据和文件,备份博客也是如此,我们可以使用博客园自带的备份功能将自己的所有博客(包括草稿)保存为一个xml文件下载下来,然后把它保存好即可(占用空间很小)。具体步骤如下:
-
首先,进入个人界面,点击你最常用的“写博”,或者访问:https://i.cnblogs.com/posts

其次,在写博界面中有两种备份方式,你可以点击左侧操作栏中的“博客备份”,也可以点击右上角的“备份”:
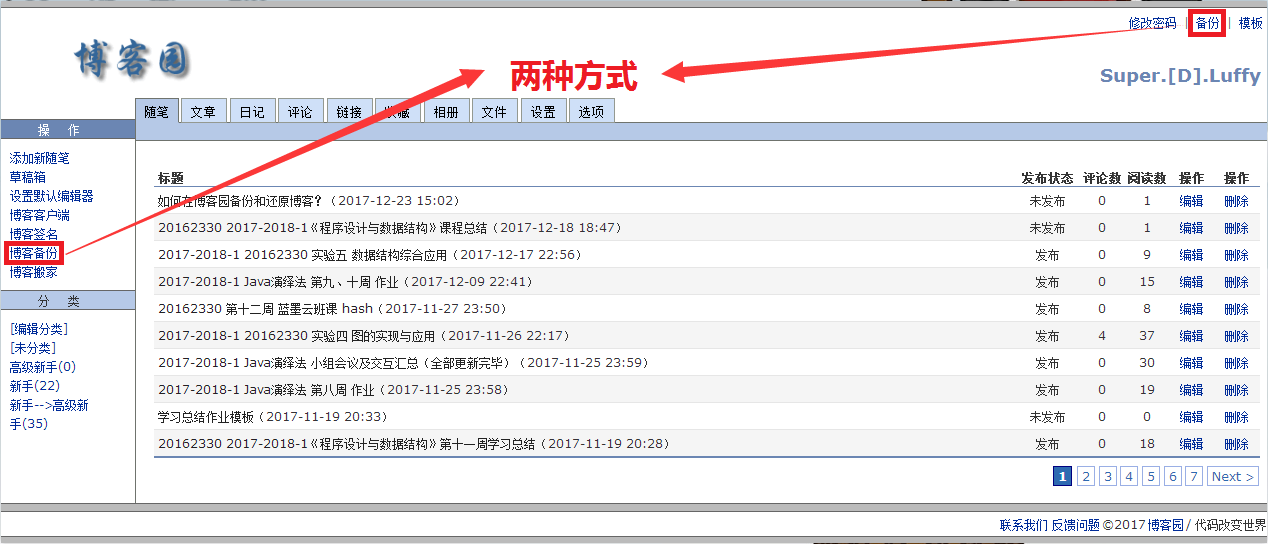
进入备份界面之后,根据所选择的时间进行备份,如果不进行修改,那么开始日期就默认为你发表(或保存)第一篇博客的时间,结束日期也默认为你最近发表(或保存)的一篇博客的时间:


之后点击下载即可进行博客备份。
也可以直接在备份界面的地址:https://i.cnblogs.com/BlogBackup.aspx
或试试直接在备份界面的地址:https://i1.cnblogs.com/BlogBackup.aspx

【注意】备份是有时间规定的,为了减少对网站性能的影响,一般在工作日的8:00之前或者18:00之后,或者周六周日才不会被限制下载,建议学生党一周定期备份一次,其他博主可根据自己的写博频率进行调整。
并且文章备份最多999个文章,多余的则无法导出,至少我今天测试了一次备份都是999个文章
如何还原备份的博客?
在备份了自己珍贵的博客之后,要怎么在博客内容丢失后迅速还原呢?办法很简单,之前我们保存的是一个xml文件,首先我们不用去下载一些xml文件的查看工具,除非有其他需要,我们只需要使用记事本打开即可:


由于是xml文件,所以打开后会有一些类似html的标记语言,不用管它们,直接去寻找我们需要的。之后我们便可以看到,第一篇博客(最近发表的博客或保存的草稿)的标题和正文,正文中的markdown格式内容完好无损:

找到第一篇博客的末尾之后,紧接着就是下一篇博客的标题,以此类推:

我们将需要的markdown格式正文复制下来,粘贴到对应的缺失数据的博客中去重新保存即可,这样一来,我们就放心了,是不是也同时满足了强迫症的需求呢?博主们现在就可以去备份博客了(今天周六)!这次就写到这里吧,小编学识浅薄,见闻不广,如果博主们在阅读时发现了一些错误、遗漏点或者对此篇博客有其他建议,欢迎在评论区指出。( ^∀^)
参考资料
【附】原创作品,如需转载,请注明出处,谢谢。
出处:https://www.cnblogs.com/super925/p/8093453.html
=======================================================================================
博客园备份档案浏览的小工具
最近才发现博客园提供了一个功能,就是可以根据时间对博客进行备份。
备份操作会得到一个XML文件,其实就是标准的RSS格式的。我们可以大致看一下内容

但这样看总是有些不方便的,为此我简单地写了一个小工具,它可以查看这些文件,就如在网上看到的一样

其实这个工具,谁都能写出来的。我就是用了一个xslt文件将那个xml文件转换为了Html文件,然后显示出来而已。
xslt文件的内容大致如下
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:msxsl="urn:schemas-microsoft-com:xslt" exclude-result-prefixes="msxsl"
>
<xsl:output method="html" indent="yes"/>
<xsl:template match="rss">
<html>
<head>
<title>
<xsl:value-of select="channel/title"/>
</title>
</head>
<body>
<h1>
<xsl:value-of select="channel/title"/>
</h1>
<xsl:for-each select="channel/item">
<h2>
<a>
<xsl:attribute name="href">
<xsl:value-of select="link"/>
</xsl:attribute>
<xsl:value-of select="title"/>
</a>
</h2>
<font size="2">
<xsl:value-of disable-output-escaping="yes" select="description"/>
</font>
</xsl:for-each>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
窗体代码如下
using System;
using System.Windows.Forms;
using System.Xml;
using System.Xml.Xsl;
namespace BlogViewer
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void 打开ToolStripMenuItem_Click(object sender, EventArgs e)
{
OpenFileDialog dialog = new OpenFileDialog();
dialog.Filter = "XML 文件(*.XML)|*.Xml";
dialog.InitialDirectory = Application.StartupPath;
if (dialog.ShowDialog() == DialogResult.OK)
{
string inputFile = dialog.FileName;
string outputFile = System.IO.Path.GetFileNameWithoutExtension(inputFile) + ".html";
XslTransform tran = new XslTransform();
string resourceName = "BlogViewer.BlogRss.xslt";
System.IO.Stream stream = System.Reflection.Assembly.GetExecutingAssembly().GetManifestResourceStream(resourceName);
XmlReader reader = XmlReader.Create(stream);
tran.Load(reader);
reader.Close();
tran.Transform(inputFile, outputFile);
this.webBrowser1.Url = new Uri(Application.StartupPath+"\\"+outputFile);
}
}
private void 退出ToolStripMenuItem_Click(object sender, EventArgs e)
{
Application.Exit();
}
}
}
该工具很简单,有兴趣的朋友可以继续添加一些功能。例如编写更加合适的xslt文件,或者实现其他的管理功能。
当前博客园仅提供了备份功能,不知道以后会不会提供还原的功能。
该小工具我打包放在下面,如果有需要的朋友可以直接下载
出处:https://www.cnblogs.com/chenxizhang/archive/2008/08/17/1269804.html
=======================================================================================
Python 博客园备份迁移脚本
鉴于有些小伙伴在寻找博客园迁移到个人博客的方案,本人针对博客园实现了一个自动备份脚本,可以快速将博客园中自己的文章备份成Markdown格式的独立文件,备份后的md文件可以直接放入到hexo博客中,快速生成自己的站点,而不需要自己逐篇文章迁移,提高了备份文章的效率。
首先第一步将博客园主题替换为codinglife默认主题,第二步登录到自己的博客园后台,然后选择博客备份,备份所有的随笔文章,如下所示:

备份出来以后将其命名为backup.xml,然后新建一个main.py脚本,以及一个blog目录,代码实现的原理是,解析xml格式并依次提取出文档内容,然后分别保存为markdown文件。

转存文章到MarkDown格式: 写入备份脚本,代码如下所示,运行后即可自动转存文件到blog目录下,当运行结束后备份也就结束了。
# powerby: LyShark
# blog: www.cnblogs.com/lyshark
from bs4 import BeautifulSoup
import requests, os,re
header = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) By LyShark CnblogsBlog Backup Script"}
# 获取文章,并转成markdown
# blog: www.lyshark.com
def GetMarkDown(xml_file):
con = open(xml_file, 'r', encoding='utf8').read()
# 每篇文章都在 <item> 标签里
items = re.findall("<item>.*?</item>", con, re.I | re.M | re.S)
ele2 = ['<title>(.+?)</title>', '<link>(.+?)</link>', '<description>(.+?)</description>']
# md_name = xml_file.split('.xml')[0] + '.md'
for item in items:
try:
title = re.findall(ele2[0], item, re.I | re.S | re.M)[0]
link = re.findall(ele2[1], item, re.I | re.S | re.M)[0]
des = re.findall(ele2[2], item, re.I | re.S | re.M)[0]
des = re.findall('<!\[CDATA\[(.+?)\]\]>', des, re.I | re.S | re.M)[0] # CDATA 里面放的是文章的内容
des = des.replace('~~~', "```")
lines = des.split('\n')
with open("./blog/" + title.replace("/","") + ".md", mode='w+', encoding='utf8') as f:
f.write("---\n")
f.write("title: '{}'\n".format(title.replace("##","").replace("###","").replace("-","").replace("*","").replace("<br>","").replace(":","").replace(":","").replace(" ","").replace(" ","").replace("`","")))
f.write("copyright: true\n")
setdate = "2018-12-27 00:00:00"
try:
# 读取时间
response = requests.get(url=link, headers=header)
print("读取状态: {}".format(response.status_code))
if response.status_code == 200:
bs = BeautifulSoup(response.text, "html.parser")
ret = bs.select('span[id="post-date"]')[0]
setdate = str(ret.text)
pass
else:
f.write("date: '2018-12-27 00:00:00'\n")
except Exception:
f.write("date: '2018-12-27 00:00:00'\n")
pass
f.write("date: '{}'\n".format(setdate))
# description检测
description_check = lines[0].replace("##","").replace("###","").replace("-","").replace("*","").replace("<br>","").replace(":","").replace(":","").replace(" ","").replace(" ","")
if description_check == "":
f.write("description: '{}'\n".format("该文章暂无概述"))
elif description_check == "```C":
f.write("description: '{}'\n".format("该文章暂无概述"))
elif description_check == "```Python":
f.write("description: '{}'\n".format("该文章暂无概述"))
else:
f.write("description: '{}'\n".format(description_check))
print("[*] 时间: {} --> 标题: {}".format(setdate, title))
f.write("tags: '{}'\n".format("tags10245"))
f.write("categories: '{}'\n".format("categories10245"))
f.write("---\n\n")
f.write('%s' %des)
f.close()
except Exception:
pass
if __name__ == "__main__":
GetMarkDown("backup.xml")
备份后的效果如下所示:

打开Markdown格式看一下,此处的标签和分类使用了一个别名,在备份下来以后,你可以逐个区域进行替换,将其替换成自己需要的分类类型即可。

转存图片到本地: 接着就是继续循环将博客中所有图片备份下来,同样新建一个image文件夹,并运行如下代码实现备份。
# powerby: LyShark
# blog: www.cnblogs.com/lyshark
from bs4 import BeautifulSoup
import requests, os,re
header = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) By LyShark CnblogsBlog Backup Script"}
# 从备份XML中找到URL
def GetURL(xml_file):
blog_url = []
con = open(xml_file, 'r', encoding='utf8').read()
items = re.findall("<item>.*?</item>", con, re.I | re.M | re.S)
ele2 = ['<title>(.+?)</title>', '<link>(.+?)</link>', '<description>(.+?)</description>']
for item in items:
try:
title = re.findall(ele2[0], item, re.I | re.S | re.M)[0]
link = re.findall(ele2[1], item, re.I | re.S | re.M)[0]
print("标题: {} --> URL: {} ".format(title,link))
blog_url.append(link)
except Exception:
pass
return blog_url
# 下载所有图片
# blog: www.lyshark.com
def DownloadURLPicture(url):
params = {"encode": "utf-8"}
response = requests.get(url=url, params=params, headers=header)
# print("网页编码方式: {} -> {}".format(response.encoding,response.apparent_encoding))
context = response.text.encode(response.encoding).decode(response.apparent_encoding, "ignore")
try:
bs = BeautifulSoup(context, "html.parser")
ret = bs.select('div[id="cnblogs_post_body"] p img')
for item in ret:
try:
img_src_path = item.get("src")
img_src_name = img_src_path.split("/")[-1]
print("[+] 下载图片: {} ".format(img_src_name))
img_download = requests.get(url=img_src_path, headers=header, stream=True)
with open("./image/" + img_src_name, "wb") as fp:
for chunk in img_download.iter_content(chunk_size=1024):
fp.write(chunk)
except Exception:
print("下载图片失败: {}".format(img_src_name))
pass
except Exception:
pass
if __name__ == "__main__":
url = GetURL("backup.xml")
for u in url:
DownloadURLPicture(u)
备份后的效果如下:

替换文章内的图片链接地址,可以使用编辑器,启用正则https://img2020.cnblogs.com/blog/(.*?)/(.*?)/批量替换。

当把博客备份下来以后你就可以把这些文章拷贝到hexo博客_post目录下面,然后hexo命令快速渲染生成博客园的镜像站点,这样也算是增加双保险了。
对过滤器的进一步优化,使之可以直接过滤出特定的标题,只需要稍微修改一下代码即可,如下代码可实现过滤特定关键词的文章。
# powerby: LyShark
# blog: www.cnblogs.com/lyshark
from bs4 import BeautifulSoup
import requests, os,re
header = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) By LyShark CnblogsBlog Backup Script"}
# 获取文章,并转成markdown
# blog: www.lyshark.com
def GetMarkDown(xml_file,grep_title,tags):
con = open(xml_file, 'r', encoding='utf8').read()
# 每篇文章都在 <item> 标签里
items = re.findall("<item>.*?</item>", con, re.I | re.M | re.S)
ele2 = ['<title>(.+?)</title>', '<link>(.+?)</link>', '<description>(.+?)</description>']
# md_name = xml_file.split('.xml')[0] + '.md'
for item in items:
try:
title = re.findall(ele2[0], item, re.I | re.S | re.M)[0]
link = re.findall(ele2[1], item, re.I | re.S | re.M)[0]
des = re.findall(ele2[2], item, re.I | re.S | re.M)[0]
des = re.findall('<!\[CDATA\[(.+?)\]\]>', des, re.I | re.S | re.M)[0] # CDATA 里面放的是文章的内容
des = des.replace('~~~', "```")
lines = des.split('\n')
# 判断是否存在:或者是空格
if title.find(":") != -1 or title.find(":") != -1 or title.find(" ") != -1:
# 过滤特定关键字
if title.find(grep_title) != -1:
local_tags = ""
if local_tags == "":
local_tags = title.split(":")[0]
if local_tags == "":
local_tags = title.split(":")[0]
if local_tags == "":
local_tags = title.split(" ")[0]
if local_tags == "":
local_tags = title.split(" ")[0]
# print("[只过滤] 标签: {}".format(local_tags))
# 开始转存
with open("./blog/" + title.replace("/", "") + ".md", mode='w+', encoding='utf8') as f:
f.write("---\n")
f.write("title: '{}'\n".format(title.replace("##", "").replace("###", "").replace("-", "").replace("*", "").replace("<br>","").replace(":", ":").replace(":", ":").replace(" ", "").replace(" ", "").replace("`", "")))
f.write("copyright: true\n")
setdate = "2000-01-01 00:00:00"
try:
# 读取时间
response = requests.get(url=link, headers=header)
if response.status_code == 200:
bs = BeautifulSoup(response.text, "html.parser")
ret = bs.select('span[id="post-date"]')[0]
setdate = str(ret.text)
pass
else:
f.write("date: '2000-01-01 00:00:00'\n")
except Exception:
f.write("date: '2000-01-01 00:00:00'\n")
pass
f.write("date: '{}'\n".format(setdate))
# description 检测描述信息的输出
description_check = lines[0].replace("##", "").replace("###", "").replace("-", "").replace("*","").replace("<br>", "").replace(":", "").replace(":", "").replace(" ", "").replace(" ", "")
if description_check == "":
f.write("description: '{}'\n".format("该文章暂无概述,自动增加注释"))
elif description_check == "```C":
f.write("description: '{}'\n".format("该文章暂无概述,自动增加注释"))
elif description_check == "```Python":
f.write("description: '{}'\n".format("该文章暂无概述,自动增加注释"))
elif description_check == "```BASH":
f.write("description: '{}'\n".format("该文章暂无概述,自动增加注释"))
elif description_check == "```PHP":
f.write("description: '{}'\n".format("该文章暂无概述,自动增加注释"))
else:
f.write("description: '{}'\n".format(description_check))
print("[*] 状态: {} --> 时间: {} --> 标题: {}".format(response.status_code, setdate, title))
# 开始打标签
f.write("tags: '{}'\n".format(tags))
f.write("categories: '{}'\n".format(tags))
# print("[*] 打标签")
f.write("---\n\n")
f.write('%s' % des)
f.close()
except Exception:
pass
# 从备份XML中找到URL
def GetURL(xml_file,grep_title):
blog_url = []
con = open(xml_file, 'r', encoding='utf8').read()
items = re.findall("<item>.*?</item>", con, re.I | re.M | re.S)
ele2 = ['<title>(.+?)</title>', '<link>(.+?)</link>', '<description>(.+?)</description>']
for item in items:
try:
title = re.findall(ele2[0], item, re.I | re.S | re.M)[0]
link = re.findall(ele2[1], item, re.I | re.S | re.M)[0]
# print("标题: {} --> URL: {} ".format(title,link))
# 判断是否存在:或者是空格
if title.find(":") != -1 or title.find(":") != -1 or title.find(" ") != -1:
# 过滤特定关键字
if title.find(grep_title) != -1:
# print("[只过滤] 标签: {}".format(grep_title))
blog_url.append([title,link])
except Exception:
pass
return blog_url
# 下载所有图片
# blog: www.lyshark.com
def DownloadURLPicture(title,url):
params = {"encode": "utf-8"}
response = requests.get(url=url, params=params, headers=header)
# print("网页编码方式: {} -> {}".format(response.encoding,response.apparent_encoding))
context = response.text.encode(response.encoding).decode(response.apparent_encoding, "ignore")
try:
print("当前文章: {} | URL: {}".format(title,url))
bs = BeautifulSoup(context, "html.parser")
ret = bs.select('div[id="cnblogs_post_body"] p img')
for item in ret:
try:
img_src_path = item.get("src")
img_src_name = img_src_path.split("/")[-1]
print("[+] Down --> {} ".format(img_src_name))
img_download = requests.get(url=img_src_path, headers=header, stream=True)
with open("./image/" + img_src_name, "wb") as fp:
for chunk in img_download.iter_content(chunk_size=1024):
fp.write(chunk)
except Exception:
print("[-] DownError: {}".format(img_src_name))
pass
except Exception:
pass
if __name__ == "__main__":
backup_title = "驱动开发:"
tags = "Windows 内核安全编程技术实践"
backup_file = "./backup.xml"
GetMarkDown(backup_file,backup_title, tags)
for u in GetURL(backup_file,backup_title):
DownloadURLPicture(u[0],u[1])
出处:https://www.cnblogs.com/LyShark/p/16652464.html


如果,您希望更容易地发现我的新博客,不妨点击一下绿色通道的【关注我】。(●'◡'●)
因为,我的写作热情也离不开您的肯定与支持,感谢您的阅读,我是【Jack_孟】!
本文来自博客园,作者:jack_Meng,转载请注明原文链接:https://www.cnblogs.com/mq0036/p/11569359.html
【免责声明】本文来自源于网络,如涉及版权或侵权问题,请及时联系我们,我们将第一时间删除或更改!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号