用模仿学习来学习POMDP中的信念表示
一、研究对象
本文研究了POMDP的模仿学习问题,具体来说本文在POMDP中引入了一种的信念表示学习方法,用于生成对抗模仿学习,不同于以往单独训练信念模块和策略,我们对信念模块和策略进行联合学习,使用任务感知模仿损失来确保目标表示更加符合策略目标。
为了避免这种潜在的信念退化,我们引入了集中信息性的信念正则化技术,包括预测多步过去/未来观测和动作序列的辅助损失,提高了信念表示的鲁棒性。
本文研究了POMDP中使用生成对抗模仿学习的信念表示学习问题。在POMDP中由于仅仅只有当前观测,不足以选择最优的动作,因此将智能体的历史(过去的观测和动作)编码为信念状态,定义为当前潜在状态上的分布(表示代理的信念)。
二、方法
信念状态将对过去经验的记忆与对世界的不可观测方面的不确定性结合起来,如果我们能够学习到信念状态b,使得它形成状态上的滤波后验统计量,那么b可以作为信念状态的替代(或表示),并用于训练POMDP中的智能体。
利用循环神经网络和概率隐变量模型对POMDP中表征潜在状态分布的信念表示进行建模,并且表明这对于POMDP中的强化学习是有效的。
提供专家论证来指导学习代理模仿专家的动作,而不需要指定奖励函数,之前的研究提供了大量的对于完全可观测的MDP过程的模仿学习工作,其中包括了(GAIL,2016)的开创性工作,但是这些工作对于POMDP的工作还很少。
为了提高鲁棒性,我们引入了几种信念正则化技术,包含动态和动作序列的多步预测。
本文将体系结构分为两个模块:
- 策略模块,该模块学习基于信念b的分布;
- 信念模块,学习信念b的表示,从观测和行动的历史中。
- 策略模块使用模仿学习的方式,而信念模块使用任务无关的方式,或者也可以使用任务感知的方式训练。
三、系统架构
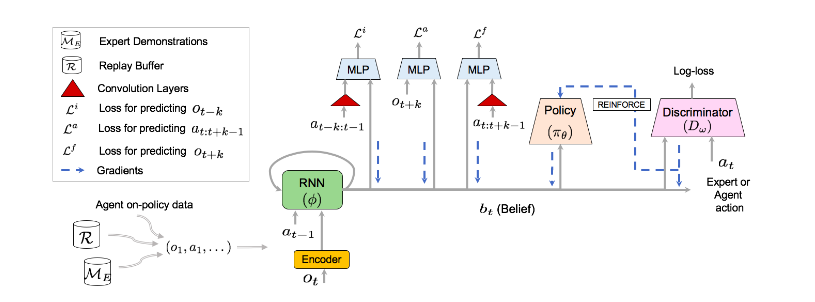
信念模块B是一个带有GRU单元的循环网络,将来自代理的轨迹(在线策略数据)和重放缓冲区的数据(离线策略数据)和专家演示数据编码为信念表示b。B通过从当前策略和判别器网络计算的损失进行更新。利用MLP进行前向、反向和动作正则化。卷积层(红色部分)将过去的动作和未来的动作编码为紧凑的表示,并将其输入到MLP中,策略\(\pi\)以信念为条件,通过模仿学习进行更新。判别器D是在代理和专家演示的元组上训练的二分类器。
四、总结
本文在部分可观测的连续控制运动任务上进行了评估,我们的信念模块模仿学习的方法显著优于几个基线方法,包括原始的GAIL算法和任务不可知的信念学习算法。本文证明了任务感知信念学习和信念正则化的有效性。
在本文中,我们研究了POMDP中的模仿学习,与MDP中的模仿学习和带有预定义奖励函数的POMDP中的学习相比,这方面的研究相对较少。我们介绍了一个由信念模块、以生成的信念为条件的策略和判别器网络组成的框架。
本文提出的框架的一个好处是,在未来的工作中,可以直接用其他学习信念表示的方法来代替本文中得到的方法。类似地,GAN和RL文献的最新进展可以指导POMDP中用于模仿学习的更好的判别器和策略网络的开发。
文章信息
原文:Learning Belief Representations for Imitation Learning in POMDPs
源码:https://github.com/tgangwani/BMIL
申明:版权归原文作者及出版单位所有,如有侵权请联系删除

