GAIL-PT:一个具有生成对抗模仿学习的通用智能渗透测试框架
主要内容:本文结合了GAN 和 IL-IRL构成了GAIL,通过专家知识的指导,使用GAIL对智能体进行训练,使其无限接近专家知识库的动作,使得PT的训练过程更加稳定和高效。
GAIL-PT框架介绍:
- 渗透专家知识库的构建:收集不同渗透场景下的PT专家样本,存储成功利用RL/DRL模型时的状态-动作对,构建专家知识库。
- GAIL训练:将专家样本和不同RL/DRL模型在线生成的状态-动作对同时输入GAIL中的判别器进行训练。
- 基于GAIL的自动化渗透测试:RL/DRL代理应用来自训练有素的判别器的新动作来自动化PT过程并执行更有效的渗透攻击。
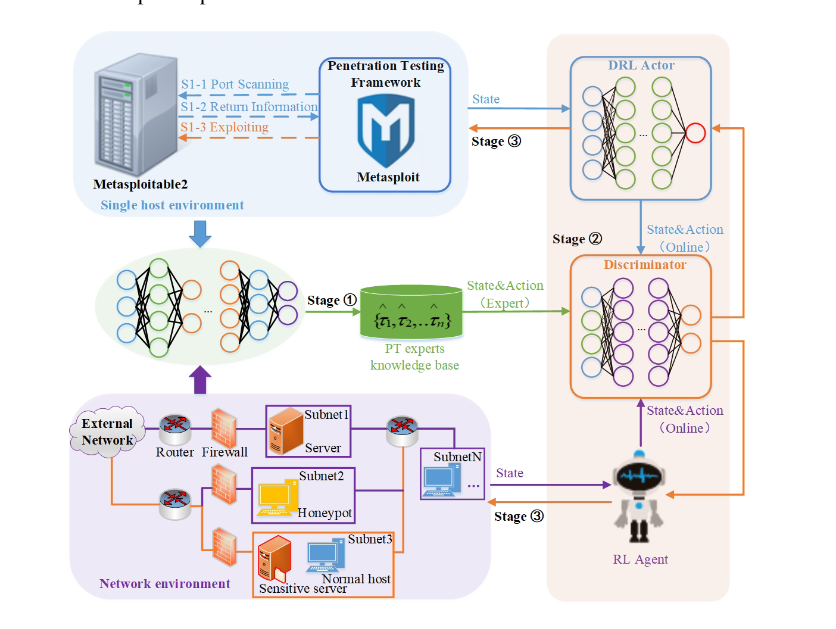
GAIL的训练过程:
- 将PT专家知识库和在线模型生成的状态-动作对分别放入到判别器中共同训练。
- 通过最大化PT专家样本给出的标准动作奖励和最小化智能体输出的动作奖励来训练判别器。
- 通过判别器和不同的DRL模型将折扣奖励和输出的价值相减得到优势函数。(使用判别器的输出代替原模型的奖励函数来指导训练方向。)
- 利用优势函数更新DRL模型,同时以更高的渗透成功概率指导Agent输出动作。(使DRL模型输出预测分布尽可能无限接近PT专家知识库轨迹。)

在本文中,使用Actor网络代替生成器G。将Actor输出的动作和状态配对到判别器中,并且和专家数据进行比较,判别器的输出D在模仿学习中被认为是指导策略学习的奖赏信号。通过将策略和奖励函数的训练转化为GAN中G和D的博弈过程,我们通过交替优化G和D来训练Actor和Discriminator网络。
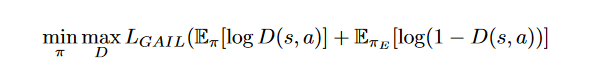
思路梳理:本文首先通过预训练的模型收敛来手工收集状态-动作构建专家知识库,然后根据构建的专家知识库来训练GAN网络,GAN网络的主要构成是生成器和判别器,这里利用训练好的判别器网络,将在线模型的状态-动作对输入到判别器网络中,根据判别器输出的0~1之间的值,判断在线状态动作对与专家经验的相似性,作为折扣奖励,将Q值与折扣奖励做差值,获得我们的优势函数,更新在线模型的网络。
文章在真实目标主机和模拟网络场景上进行的大量实验表明,GAIL-PT在利用实际目标Metasploitable2和Q学习优化渗透路径方面取得了对DeepExploit的SOTA渗透性能,不仅在小规模有/无蜜罐网络环境中,而且在大规模模拟网络环境中也取得了较好的渗透性能。
文章信息
原文:GAIL-PT: A Generic Intelligent Penetration Testing Framework with Generative Adversarial Imitation Learning
源码:https://github.com/Shulong98/GAIL-PT//
申明:版权归原文作者及出版单位所有,如有侵权请联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号