面向高效网络渗透测试的强化学习
一、本文的贡献
本文提出并且评估了一个基于人工智能的PT系统————IAPTS,系统利用RL技术来学习和再现PT活动。该模块集成了工业框架,能够在未来类似的测试用例中捕获信息、能够从经验中学习和重现测试。
IAPTS将PT环境和任务建模为POMDP问题,并通过POMDP-slover求解。本文仅限于网络基础的PT规划,而不是整个PT过程。此外,IAPTS的学习模块可以存储和重用PT策略来解决专业知识的获取和重用等复杂问题。
二、相关研究
早期的研究集中在将PT建模为攻击图和决策树,反映了PT实践作为序贯决策的观点,由于所提出的方法静态性以及对规划阶段的限制性,大多数与脆弱性评估的相关性更高。使用PDDL语言对PT建模,首次考虑了PT的攻击和攻击后阶段,使其能够提供灵活的解决方案,优化攻击系统,但是缺点是可扩展性,只限于中小网络。目前对于PT中的不确定性,特别是缺少关于评估系统的准确和完整的知识。将PT规划阶段建模为POMDP过程,使用POMDP-solver求解。
关键算法:
GIP (广义增量剪枝)是基于增量剪枝的POMDP精确求解算法家族的变种。GIP算法取代了在几种精确POMDP求解方法中使用的LP来检查支配向量。在本工作中,我们对当前GIP的实现引入了一些非功能性的变化,特别是在信念采样中,使得在求解过程开始时能够使用外部信念而不是从POMDP环境中采样信念,因此代理信念将直接上传到RL环境中,以便高效地使用。
三、当前研究的旨在解决的问题
- 减少由于人力成本导致的系统测试和定期重复测试的成本
- 减少对被评估网络的影响,特别是测试期间的安全暴露、性能和停机时间
- 将人类专家从枯燥的重复性任务中解放出来,分配到更具挑战性的任务
- 通过允许更加灵活性和适应性,更有效地应对不断变化的网络威胁
- 通过覆盖广泛的攻击向量来执行更广泛的测试,同时考虑人类测试人员难以识别的复杂和模糊的攻击路径
四、系统功能介绍
IAPTS系统允许RL代理在PT环境中进行交互和操作,从而自我学习,获得和概括PT专业知识。将提取的知识进行存储和不断完善,以达到在类似情况下未来使用的最优决策策略。PT专家通过决定是否接受或拒绝IAPTS提供的专业知识来完全控制专业知识的提取、评估和存储。
开发Python脚本对原始数据进行预处理,并将预处理结果以POMDP的形式用于优化PT域的表示。IAPTS Memory将由人工进行初步处理,专家决定所获得的结果的存储以及相关专业知识的提取和存储相关的任务的管理。提取专家知识被手动执行,直到IAPTS达到伪成熟的状态,它将负责捕获、评估、和存储专家知识,并且将其嵌入到IAPTS专家知识内存中。IAPTS作为一个独立的模块,可以被嵌入到工业的PT框架之中。当前的IAPTS与MSF相关联,作为外部模块通过定制的Python脚本与API通信。
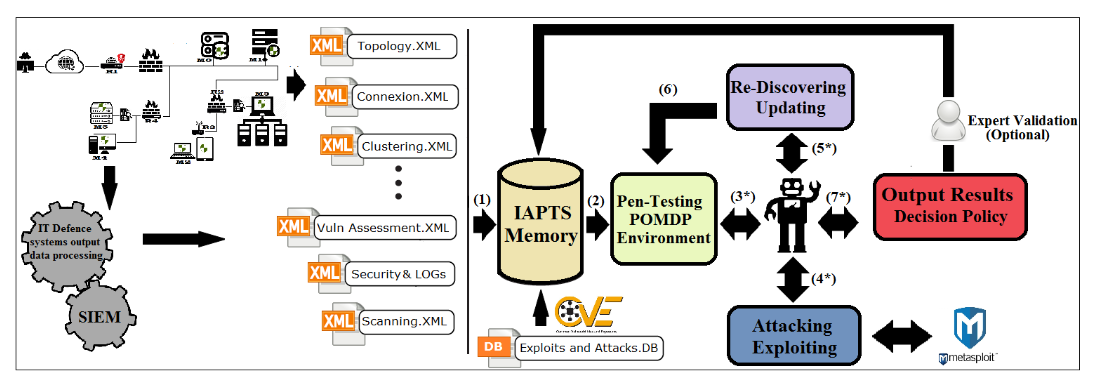
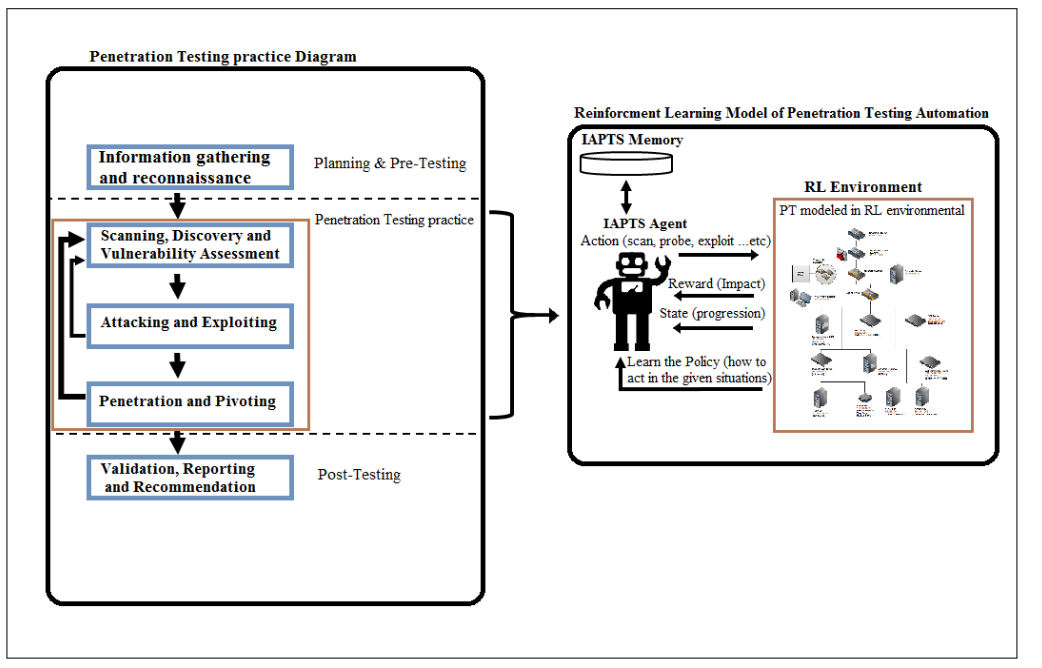
总的来说,IAPTS可以在四个不同的层次上运行,这取决于系统知识库的开发,包括捕获和泛化的专业知识:
- 完全自主;IAPTS在成熟后完全控制测试,因此它可以像人类专家一样执行PT任务,处理一些小问题,并报告给专家评审。
- 部分自治;IAPTS最常见的模式和反映专业使用的第一个星期或几个月时,IAPTS将在一个高水准的PT专家的不断和持续的监督下进行测试。
- 决策助手;IAPTS将跟踪人类专家,并通过提供与那些保存到专家库中的场景相同的精确决策来帮助他/她,从而使测试人员从重复的任务中解脱出来。
- 专长建设;IAPTS运行在后台,而人类测试人员执行测试和捕获以专家形式做出的决策,并进行泛化和提取经验,并构建专家知识库以供将来使用。
将PT建模和表示为POMDP环境尤为复杂,会产生一个庞大的POMDP环境,从而在时间和计算能力(内存)的限制下无法求解。因此,需要对资源进行智慧化利用。如图所示的系统内存用于动态存储环境属性(状态、动作、观察、过渡、奖励)和代理内存(代理人在环境中行动所获得的政策和知识经验的数据)等系统处理的数据。
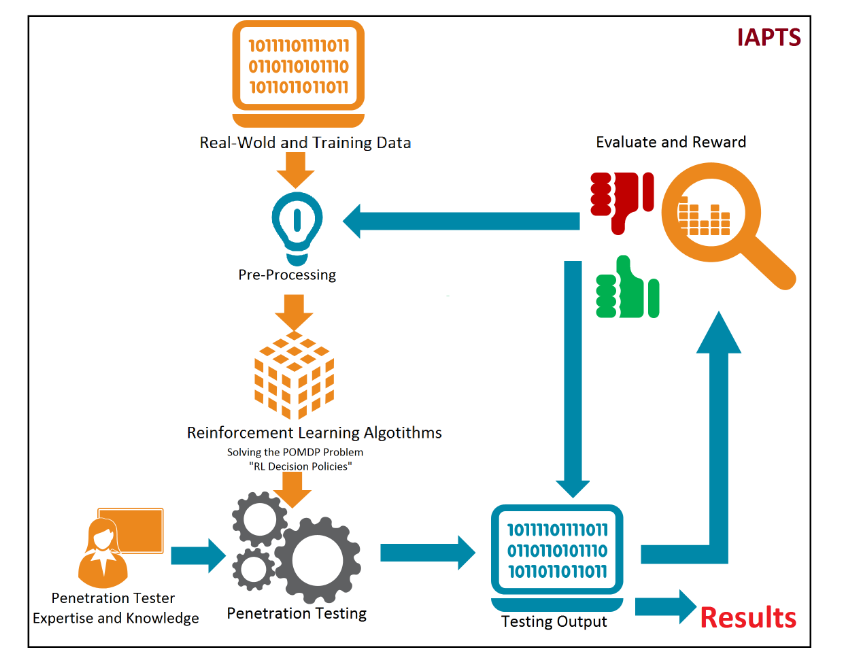
五、实验结果
最后,在整体性能提升方面,值得注意的是,当使用GIP LPSolve结合初始置信度算法时,所产生的决策策略的质量超出了人类的专业知识,特别是在10台机器网络的情况下,IAPTS突出了一个平均人类PT专家容易忽略的两个额外攻击向量,如图所示。
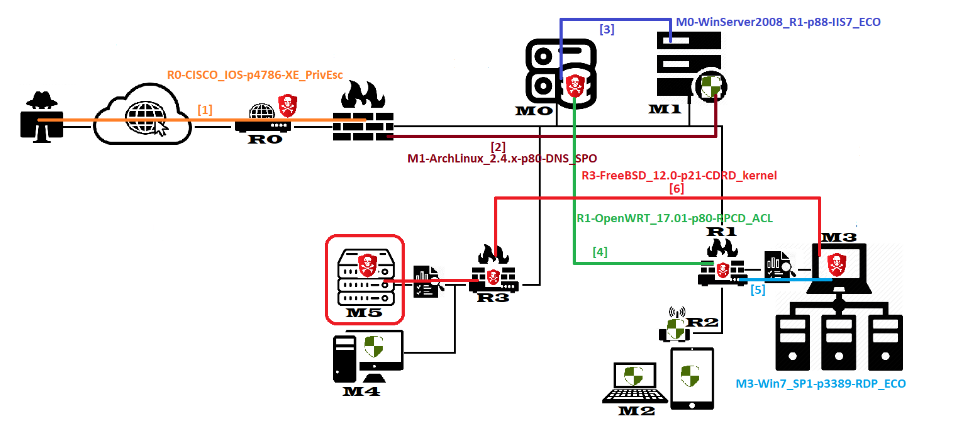
IAPTS在相对较大的网络上的性能仍然优于通常分配给PT专家的可接受时间,因此我们计划通过采用PT实践的分层POMDP模型来改进当前版本。在该模型中,大网络按照面向安全的方法被初始划分为段(簇),并且整个POMDP环境将包含簇的表示而不是网络中的所有机器。这种方法有望解决IAPTS测试过程中面临的两大问题:性能的提升,因为系统将解决几个小的POMDP问题,而不是处理一个大而复杂的环境。另一方面,层次模型将简化和优化专业知识捕获和处理的过程,将其作为攻击向量在两个层次的集群和机器上使用,这将取决于评估网络中引入的变化。
文章信息
原文:Reinforcement Learning for Efficient Network Penetration Testing
源码:无
申明:版权归原文作者及出版单位所有,如有侵权请联系删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号