使用深度强化学习改进POMDP
论文提出一种ADRQN架构来增强在部分可观测领域的学习表现,架构的特点在于同时考虑动作和观测作为模型的输入。

如下图中的模型所示,我们的动作和观测在经过相关的维度变换之后,共同作为LSTM的历史经验输入。这种循环结构能够集成任意长度的历史经验来更好地估计当前的状态。
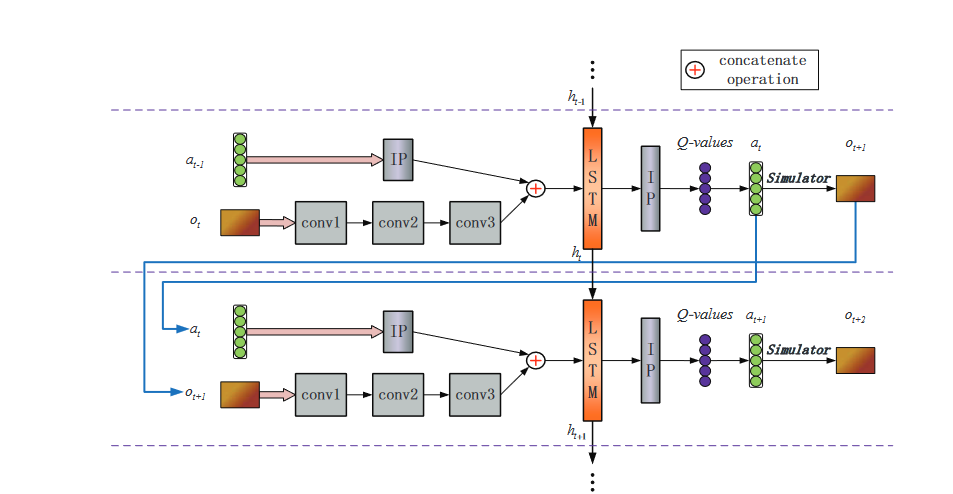
整个过程如算法1所示:

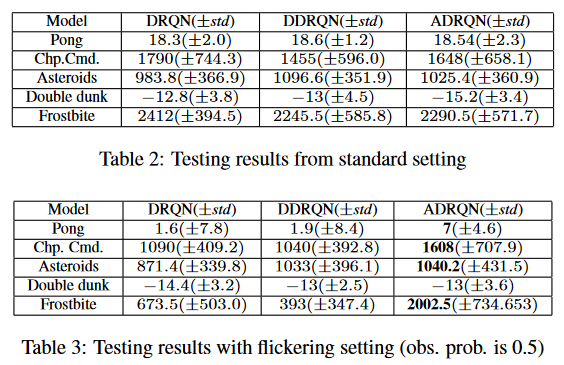
实验基于Atari 2600 games,性能对比(DRQN,DDRQN,QDRQN):
训练效果展示:

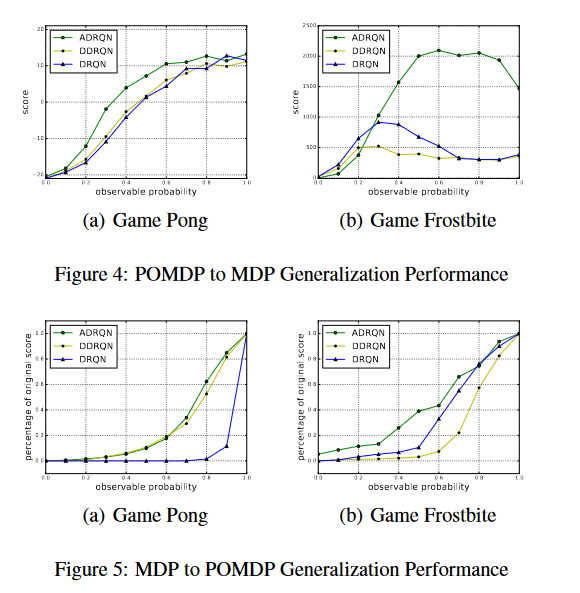
对比从POMDP to MDP 和 MDP to POMDP,模型的鲁棒性:
文章信息
原文:On Improving Deep Reinforcement Learning for POMDPs
源码:https://github.com/bit1029public/ADRQN
申明:版权归原文作者及出版单位所有,如有侵权请联系删除



