通过深度强化学习自动化后利用
Title:Automating post-exploitation with deep reinforcement learning
一、摘要
为了评估信息系统的安全,我们需要了解攻击者在成功利用后的行为,然而审计需要专家,目前还没有解决方案能够自动化这个过程,本文提出了一种结合DRL和PowerShell Empire框架来实现后利用自动化的方法。我们的强化学习代理选择其中一个PowerShell Empire模块作为动作,代理的状态由10个参数定义,例如被代理破坏的账户类型。在学习阶段,我们比较了3种强化学习模型:A2C,Q-learning和SARSA,结果表明A2C可以最有效的获得奖励。此外对训练后的代理在测试网络中进行评估,使用A2C训练的代理可以获得域控制器的管理权限。
二、介绍
后利用包括以下操作:横向移动,提权,收集信息和构建后门等。有许多支持自动化渗透测试的解决方案和漏洞管理程序,如OpenVAS,sqlmap,DeepExploit,但目前没有方案可以自动化红队测试的后利用。机器学习是解决自动化的常用方法之一,目前的机器学习分为三种类型:监督学习,无监督学习和强化学习。监督学习和无监督学习用于入侵检测、恶意软件检测和隐私保护系统;但对于后利用环境来说,数据的收集是困难的,强化学习是随着环境的探索和经验的积累而学习,代理可以用于复杂的实时环境。
虽然已经有许多研究证明了强化学习智能体可以应用于网络安全模拟场景,但是目前还没有研究将强化学习应用于实际的网络安全场景。本文中运用了数据增强的概念,以应对数据和环境的缺乏,来增加学习环境的多样性,此外还可以避免强化学习的过拟合。
本文重点关注后利用动作之间横向移动的自动化,一旦APT攻击者进入目标网络,他们会谨慎使用受感染的主机作为跳板,一遍到达深埋在网络内部的关键系统。横向移动需要很高的技能要求,本研究的目的是通过DRL是横向移动实现真正的自动化。
已有研究:
Ghanem and Chen (2018) 实现POMDP建模,并使用外部POMDP求解器求解;但研究仅局限于规划阶段,而非具体实施阶段
DeepExploit (Isao) 是与 Metasploit链接的全自动渗透测试框架;但框架的目标仅是自动化和改进漏洞诊断及初始利用,不支持后期利用
Elderman et al. (2017) 专注于网络安全模拟游戏,攻击和防御是实时的
Sharma et al. (2011) 62% 的网络攻击是在攻击者实现目标后检测到的,这意味着攻击者和防御者很少进行实时竞争
因此,在本文中,我们在没有明确设置防御代理的环境中训练攻击代理。
Bland et al., 2020 在使用Petri网形式的扩展建模的网络攻击模型实施了强化学习算法,结果证明了强化学习改善网络安全的潜力
本文使用A2C作为强化学习算法,A2C类似于A3C,但是缺少了异步部分。根据OpenAI,虽然A2C缺少异步部分,但是A2C的性能优于A3C(Wu et al.)
三、系统介绍
我们构建多个环境来构建分布式环境。通过分布式的经验收集提高了学习效率。
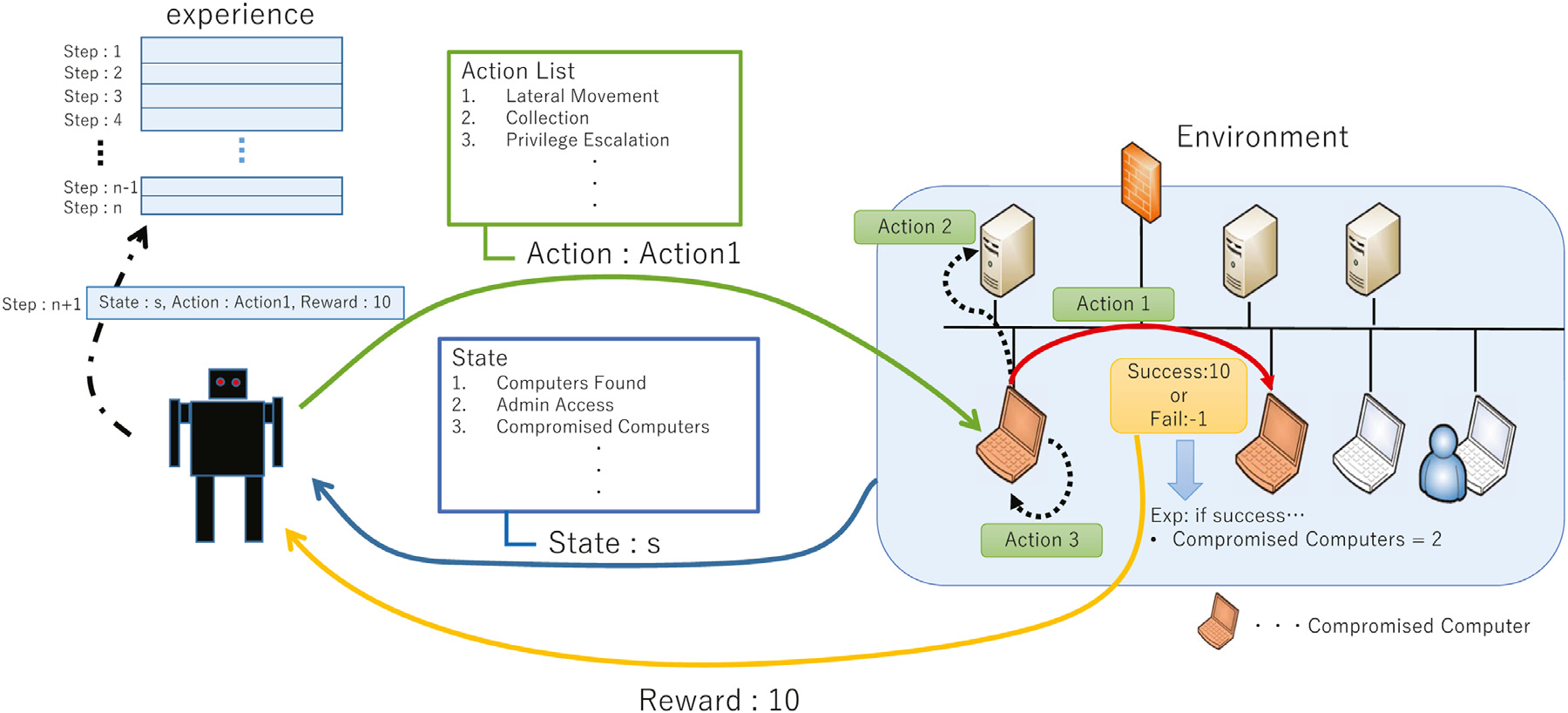
(1)状态定义:状态由10个条目来定义,下表显示了条目的信息和摘要
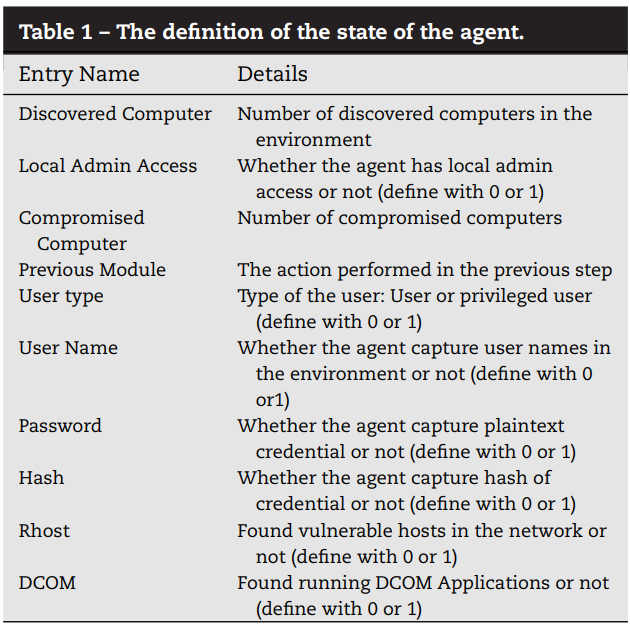
Discovered Computer表示网络中已发现计算机的数量。Compromised Computer表示网络中受感染的计算机的数量。每个模块都有一个唯一的编号。 Previous Module 条目的值是在上一步中执行的模块的编号。 Admin Access 值指示是否可以使用受损的用户权限访问任何其他计算机。如果发现这样的计算机,代理可以在计算机上执行横向移动和代码执行。因此,应该积极使用这些信息。用户名、密码、哈希表项代表凭证信息的获取状态。
这些凭据对于代理破坏网络中的新计算机和其他资产很有用。 Rhost 的条目表明是否在网络中发现了易受攻击的主机。 DCOM(分布式组件对象模型)是一种 Windows 功能,用于在不同远程计算机上的软件组件之间进行通信。代理可以通过使用 DCOM 来利用一些横向移动方法。如果正在监视横向移动的其他方法,代理可以利用 DCOM。总之,DCOM 应用程序的存在会影响代理的确定。因此,我们将 DCOM 条目添加为代理状态的元素之一。
(2)动作定义:动作按特征分为12组,下表显示了分组名称和数量,共204个
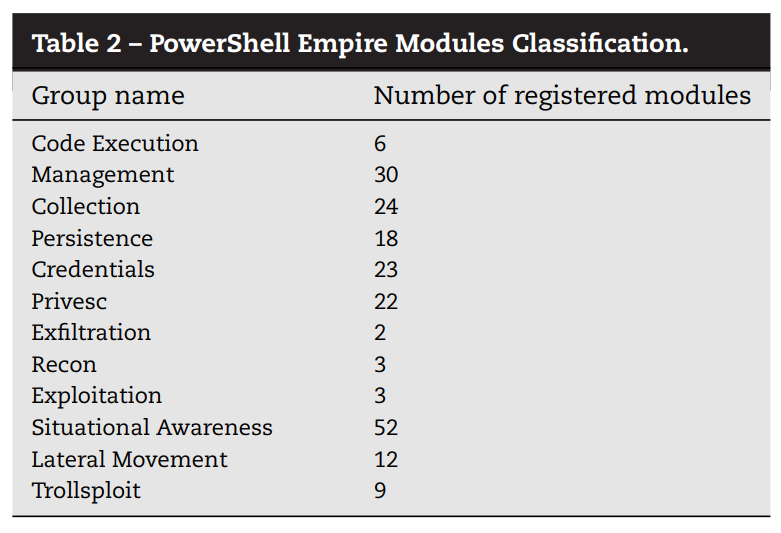
PowerShell Empire是一个著名的工具,使用 PowerShell 实现为后利用框架。属于同组的模块具有不同的手段和机制,但他们基本上用于实现相同的目的,更多信息可参照https://www.powershellempire.com/
(3)奖励定义:对代理的奖励设置为横向移动的成功。
奖励的大小取决于横向移动时是否获得了新的账户控制。如果代理获得了对更高权限的账户的控制,则获得高价值资产的概率增加。
∗ r=50,如果有价值的横向移动成功。
∗ r=10,如果低值横向移动成功。
∗ r=-1 如果横向移动失败。
∗ 对于其他动作,无论成功或失败,r=-1
(4)实现
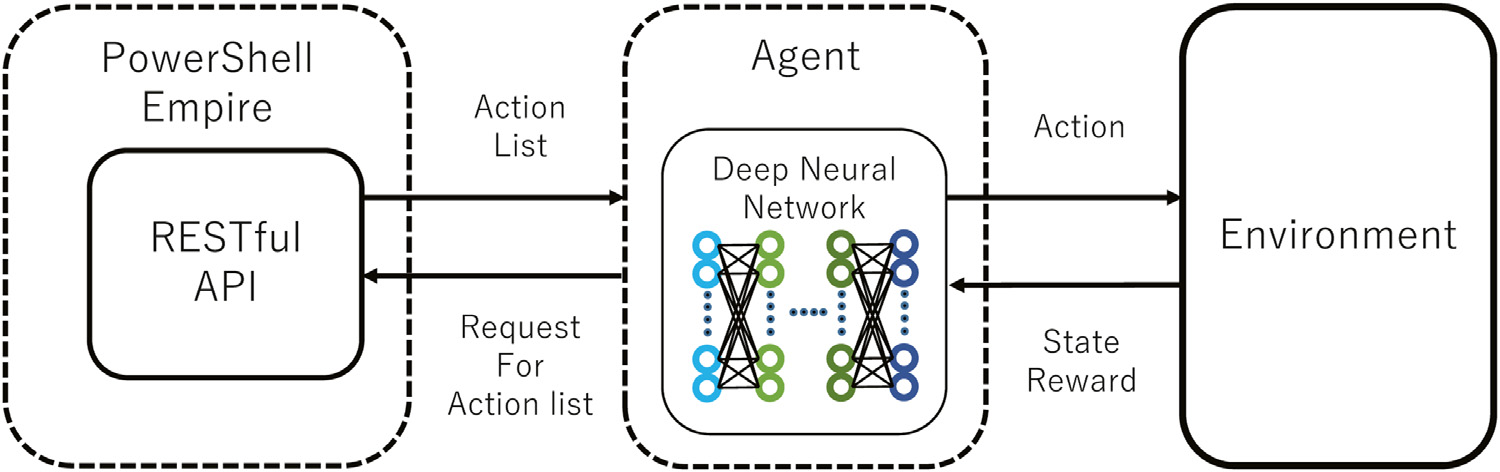
DNN的隐藏层是三个全连接层,因此深度神经网络由包括输入层和输出层在内的共五层组成,输入值是代理状态s,输出值为动作选择的概率分布p(a)和状态值v(s)。动作选择由RESTful API实现,DNN累积的经验由一组“选择的动作,动作前后的状态以及奖励”组成。使用经验计算节点之间的梯度,并基于\(\epsilon\)贪心策略,根据\(\epsilon\)的值执行p(a)最大或者随机选择确定动作a,\(\epsilon\)的初始值为0.5,并随着训练的进度趋于0
四、状态评估
由于缺乏公共资源用于训练代理,我们设计了训练环境,使得网络配置和漏洞不是唯一确定的。具体来说,我们应用了数据增强的概念,并且在网络中添加了噪声,从而赋予了环境多样性。我们设置了关键动作的成功概率,横向移动,使得网络设置和漏洞不是唯一确定的,这是防止代理过拟合的噪音。代理尝试对概率设置的每个模式进行后期利用,收集训练样本并进行学习。
我们尝试了5种概率设置模式,以设置能够进行适当学习的成功概率:A(所有成功概率设置为 20%)、B(50% 的模式)、C(80% 的模式) ,D(成功概率随机设置),E(成功概率根据模块特性设置在一定范围内)。
表 3 显示了 E 的概率设置。图 3 显示了每种方法获得的奖励的转换。

强化学习模型在任何模式中都是 A2C,横轴表示代理执行模块(动作)的次数。我们在每种方法中尝试了 50,000 步。
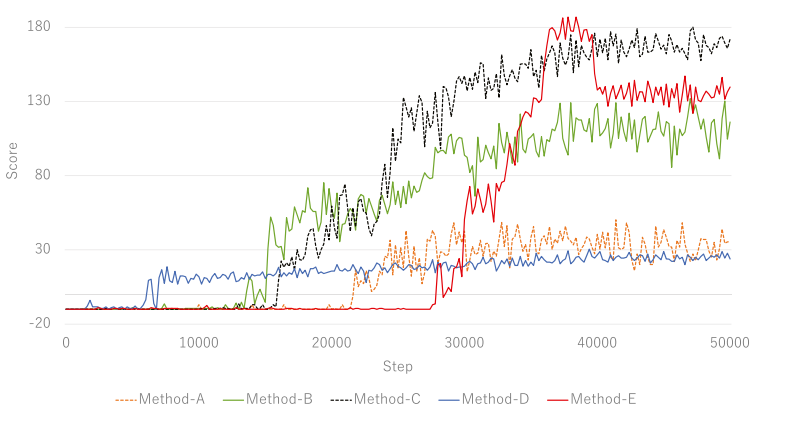
B、C 和 D 的训练过程中损失值波动很大,甚至在学习结束之前也不会收敛到 0。另一方面,当获得的奖励增加时,A 和 E 的损失值迅速增长。此外,随着获得的奖励趋于平稳,A 和 E 的损失值趋于收敛到 0。这些结果表明,就损失值而言,Method-A 和 Method-E 比 Method-B、C 和 D 更适合训练。
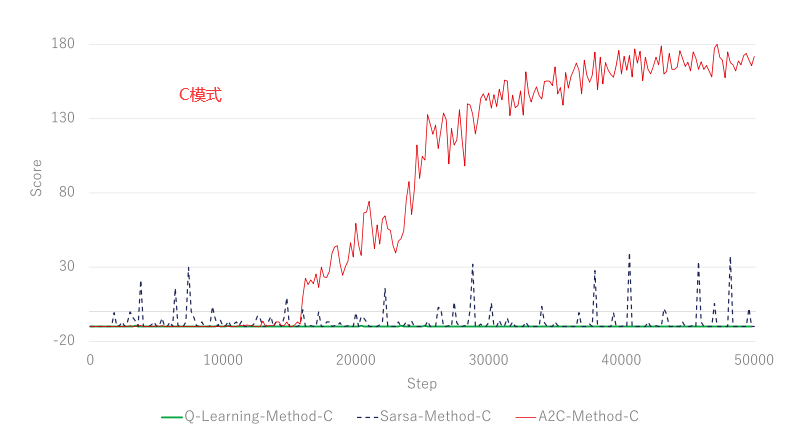
接下来,我们评估了 3 种强化学习模型的训练进度。除了 A2C,还实施了 Q-Learning 和 SARSA。我们尝试在与 A2C 相同的条件下训练 Q-Learning 代理和 SARSA 代理。我们将在 A2C 学习阶段表现良好的 C 和 E 应用于 Q-Learning 和 SARSA 代理学习。结果表明,A2C 模型的最终奖励高于其他模型,A2C 比其他模型具有更好的学习效率。 SARSA 的奖励部分高于 Q-Learning 的奖励,但不稳定。此外,Qlearning 代理获得的奖励没有显着变化。
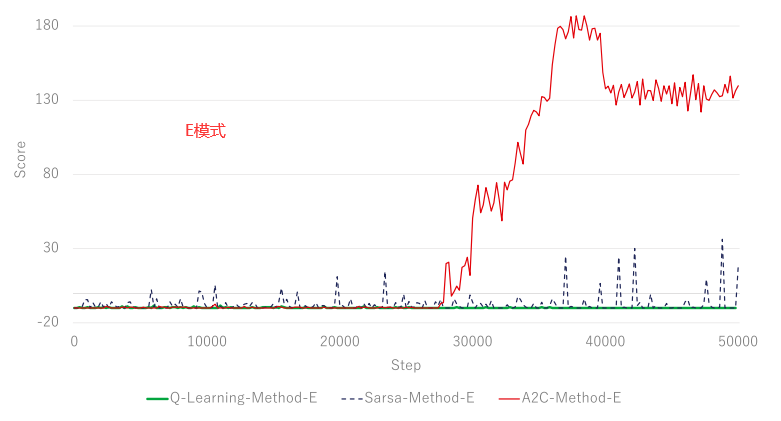
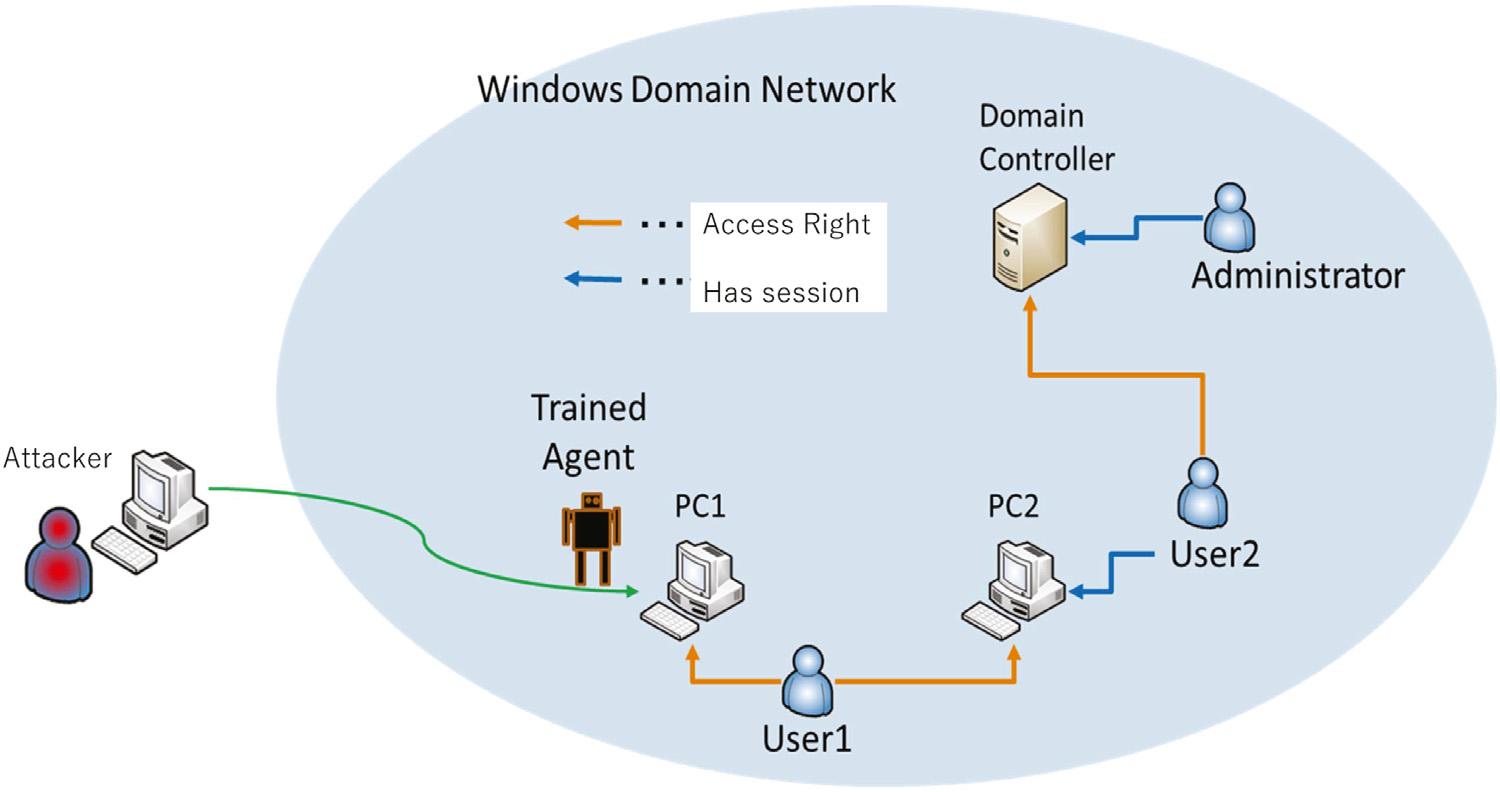
在真实环境中运行训练好的代理进行比较,经过训练的代理在测试Windows域网络中执行。下图显示了一个典型的域网络配置示例。如图所示,域网络配置通常由计算机、用户和服务器等许多组件组成。
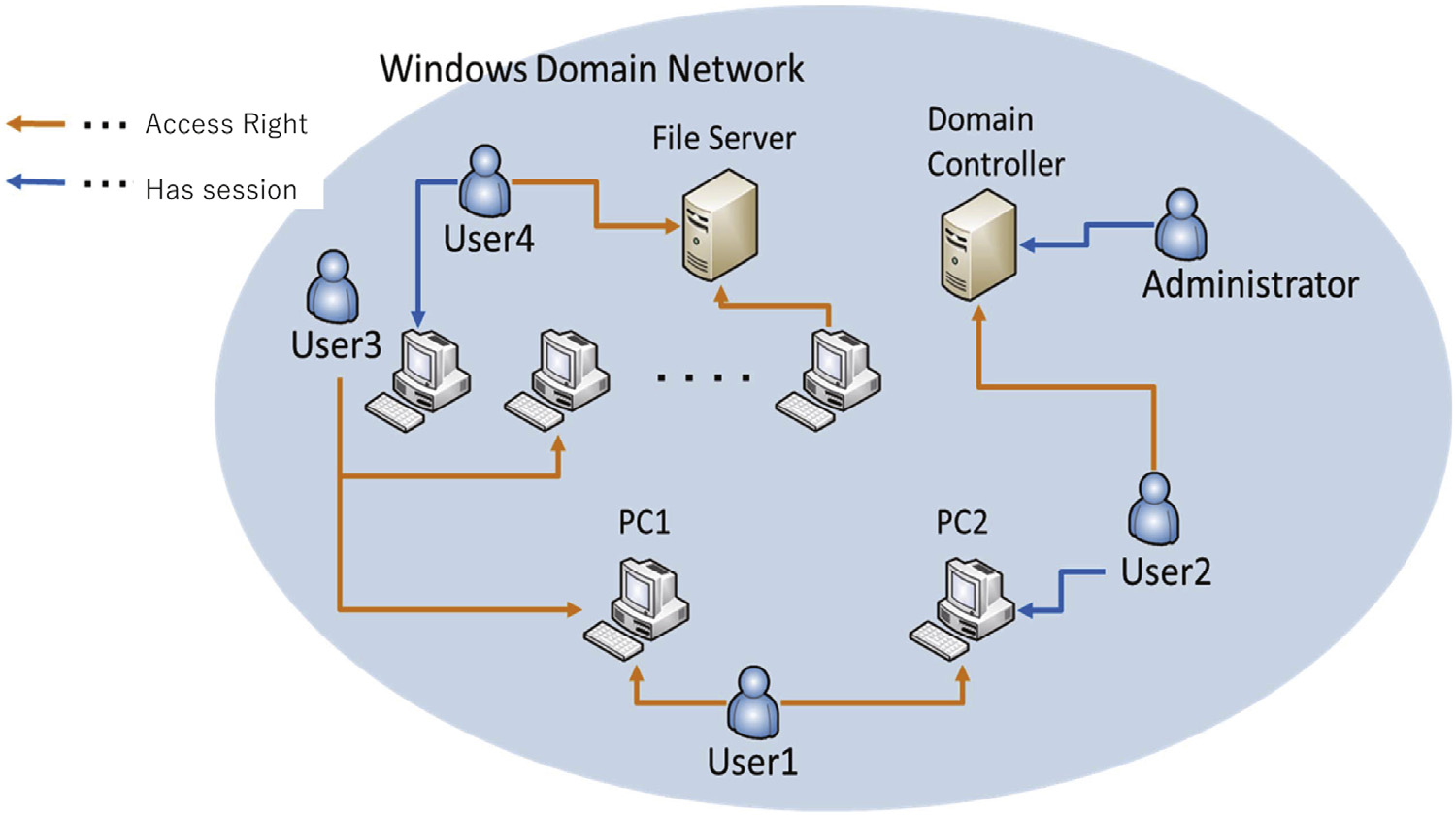
我们在测试过程中使用了简化后的配置,为了获得域控的管理权限,攻击者要在计算机之间移动两次,在用户之间移动两次。
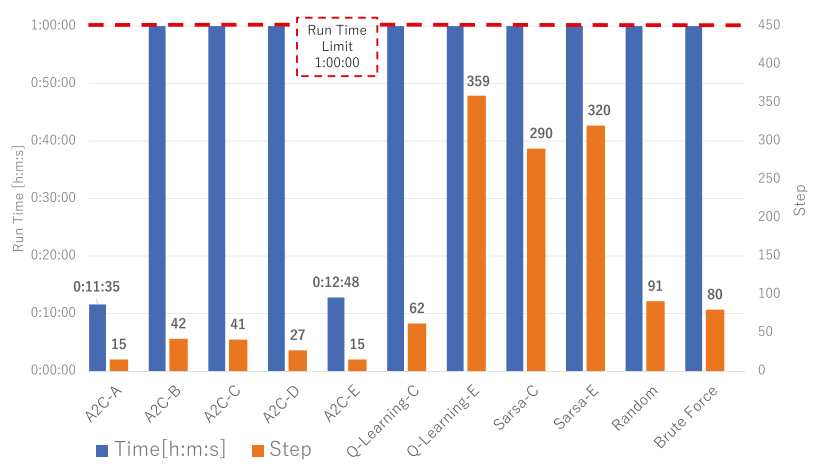
下图展示了每个代理的执行步骤和运行时间,Random和Brute不使用强化学习算法。
五、总结
(1)有效性
本研究的目的是 1)自动化后期开发,2)将深度强化学习作为自动化方法应用于后期开发,以及 3)验证其有效性。
我们需要讨论的第一点是学习阶段实验的结果。实验结果表明,C和E可以学习行为以实现显着的横向运动,A2C的学习效率优于Q-learning和SARSA,A2C适合于学习后开发的任务。表格方法不适合这种情况,因为状态和动作的组合太多。
接下来是测试阶实验的结果。实验结果表明,DQL可以应用于后期开发并自动化后期开发的任务,我们的方法通过15个动作实现了目标,而无代理自动化模型无法实现目标。无代理自动化模型将无法在像我们的测试环境这样的复杂环境中实现其目标。这是无代理自动化模型的缺点。另一方面,基于代理的自动化模型需要训练,而无代理自动化模型则不需要。这是基于代理的自动化模型的缺点,因为所提出的解决方案在准备训练样本方面存在最大的问题。不需要训练的无代理自动化模型不存在这个问题。这是无代理自动化模型的优点。
最后,让我们考虑一下 A2C-B 和 A2C-C 测试阶段失败的结果。在 A2C-B 和 A2C-C 中,执行的横向移动总是以高概率成功。因此,动作选择可能会偏向于可以首先找到并获得奖励的动作,它们被认为对训练环境过度拟合,在测试网络上失败。
(2)比较
DeepExploit (Isao) 是将强化学习应用于网络安全场景的实用框架。我们应该仔细比较 Deep Exploit 和提出的解决方案,因为它们有一些共同点,但也有很大的不同。
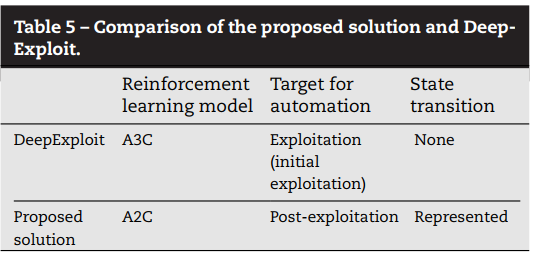
需要状态转换是所提出的解决方案的一个优点。另一个区别是代理的训练样本。DeepExploit 从真实世界的样本中训练代理,而提议的解决方案从合成样本中训练代理。在这方面,DeepExploit 是一个比提出的解决方案更现实的框架。
(3)限制
训练环境几乎没有多样性。我们的方法通过设置智能体动作的成功概率来多样化训练环境:评估了 5 种成功概率设置模式。但是,仅通过成功概率很难表示实际环境的多样性。使学习环境多样化的方法是未来研究的主题。
此外,在本文中,我们只尝试了一种代理状态定义的方法。根据状态定义的方法,智能体的行为和学习进度可能会发生变化。因此,探索和评估其他定义智能体状态的方法也是未来研究的主题。
最后,用于训练代理的样本是合成样本,实际测试是在有限的条件下进行的。理想情况下,代理应该从真实世界的样本而不是合成样本中学习利用。这个问题限制了代理训练和学习的有效性。具体来说,此时代理可能无法适应各种各样的特征环境。
因此,在这方面,我们的贡献在于它展示了通过深度强化学习优化的计划(或建模)网络攻击的潜力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号