一个基于强化学习的攻击路径分析方法
Title: A Reinforcement Learning Approach for Attack Graph Analysis
一、摘要
本文提出了一个Q-learning的攻击图近似分析方法,首先利用MulVAL基于给定的网络拓扑生成攻击图,然后提炼攻击图生成一个简单的转移图。我们使用Q-learning模型去发现可能的攻击路径使得攻击者能够威胁到安全网络,我们的方法评估是将其运用在一个具有特定服务、网络配置和漏洞的典型IT网络场景。
使用CVSS为攻击者可能的行为建模奖励系统,并应用Q-learning找寻攻击者的可能动作。
二、系统介绍
- 侦察网络(收集当前网络的状态信息),使用MuVAL生成攻击图
- 简化攻击图,生成转移图
- 使用转移图为环境和攻击者的奖励系统建模,应用Q-learning获取攻击者到达目标可能的攻击路线
Q-learning是基于单一目标的算法,我们改变了Q-learning算法使其能够运用到攻击图场景,被称作Q-learning-Attack-Graph。我们使用R的子矩阵来为每一个目标生成一个Q矩阵,为了达到这点每次一个目标被选择,其余的目标联通他们对应的行列将会被移除从R矩阵,然后得到的结果是子矩阵r被作为Q-learning的奖励矩阵。
原始的单一目标Q-learning算法
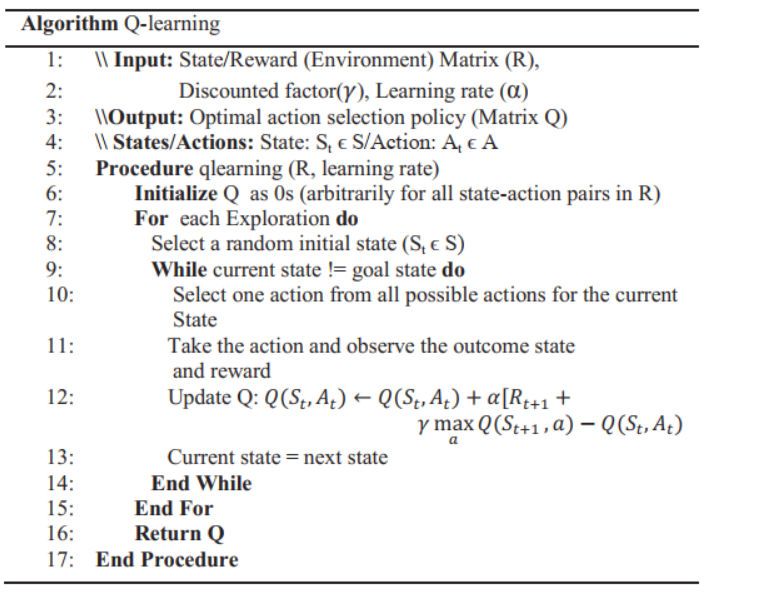
经过改进后的Q-learning-Attack-Graph算法

三、实验评估
(1)网络拓扑配置
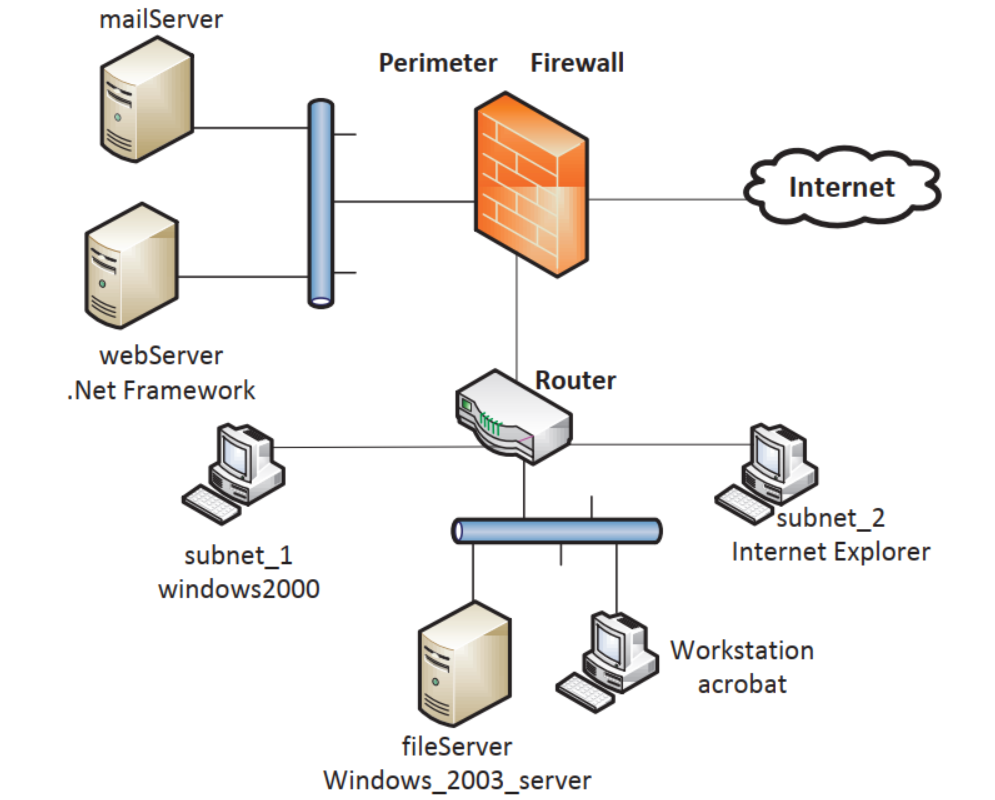
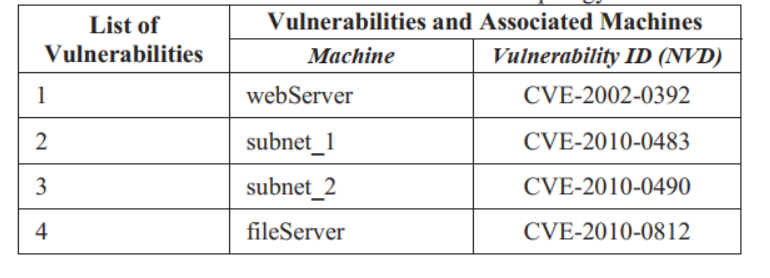
(2)漏洞配置
(3)MulVAL生成攻击图和转移图
正方形代表系统配置,如防火墙规则或者有问题的软件;菱形代表潜在的特权和利用,如代码执行;椭圆表示前置条件到后置条件,如漏洞—>攻击者获取特权
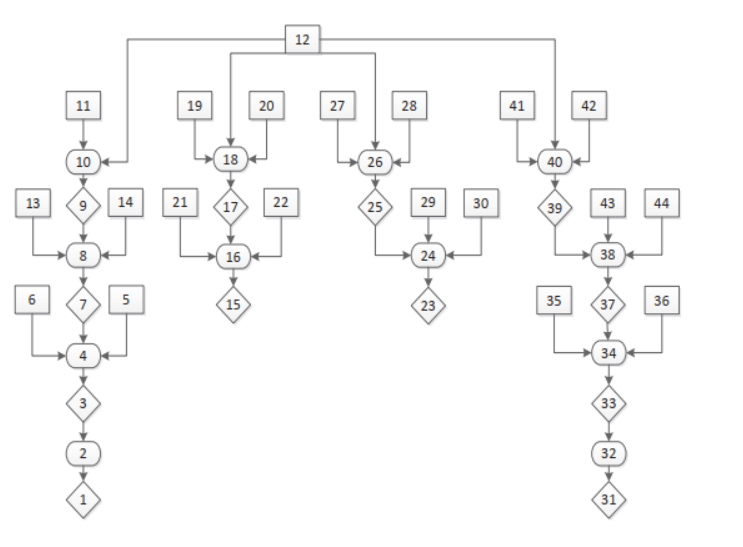
攻击图简化后的转移图
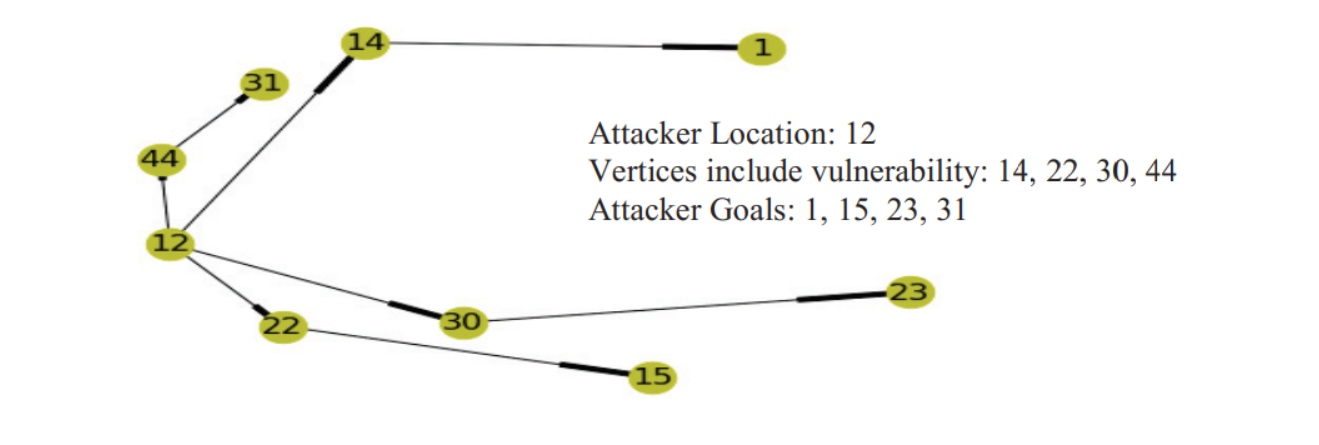
使用CVSS评分获得的奖励系统
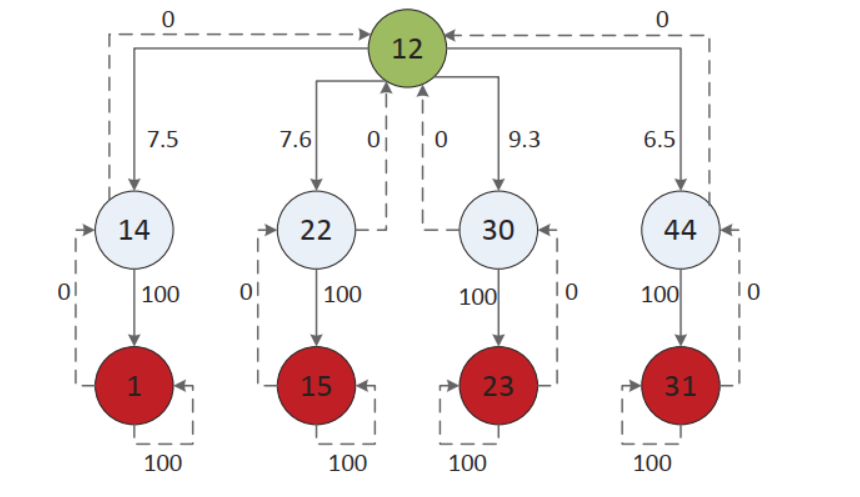
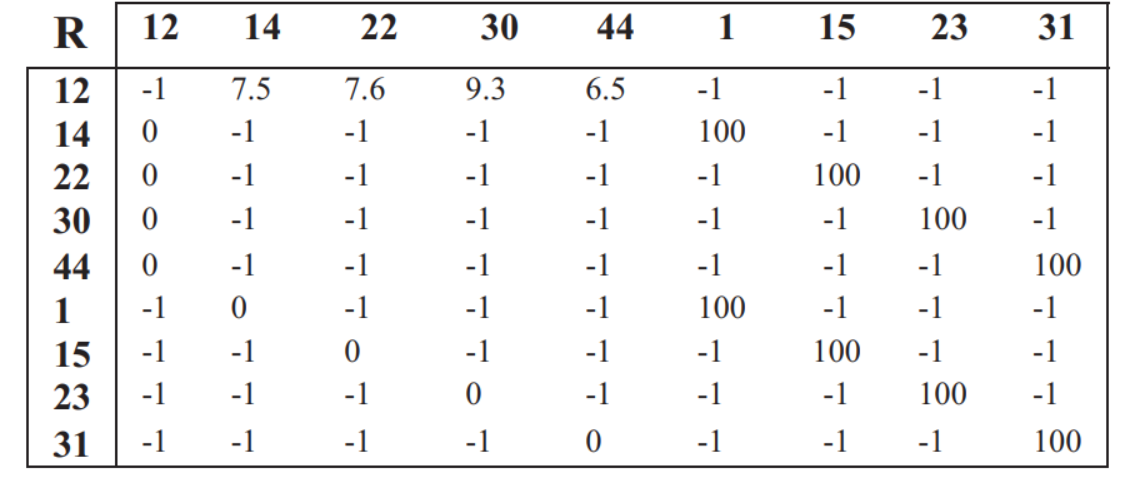
对应上图的奖励矩阵R
(4)结果评估
我们使用转移图为我们的环境建模,然后使用奖励矩阵R训练我们的算法。我们每次从矩阵R中提取子矩阵r,然后为子矩阵r生成矩阵Q。我们展示了保留目标(节点1),然后移除其他的目标(节点15,23,31)和相应的边,展示了子矩阵r。
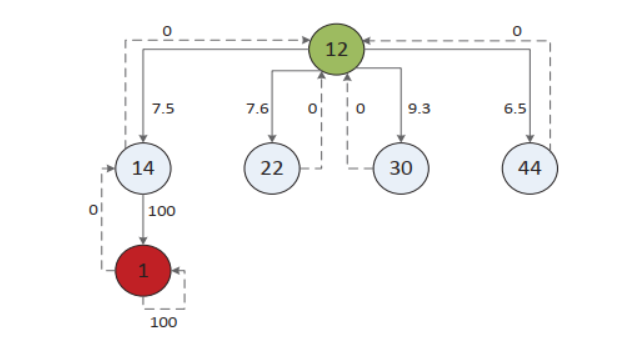
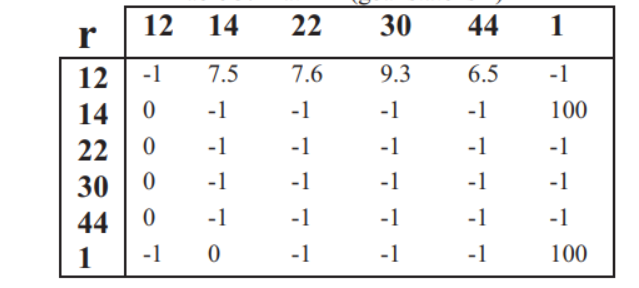
下图展示了收敛后的矩阵Q,这里边的权重代表了攻击者在不同节点之间移动的奖励,使用矩阵Q,攻击者能够从每一个单独的状态到达目标节点。
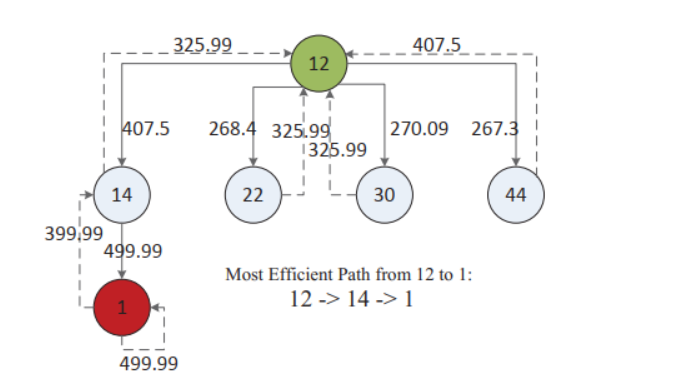
然后依次保留对应的目标之后,我们可以得到如下的路径顺序。
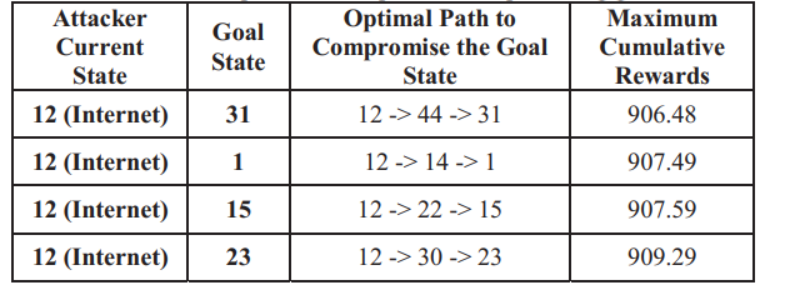
通过使用这些信息,我们能够观察到攻击者能够导致的最大危害,能够为系统中的漏洞排序,根据优先级处理他们。
四、总结
本文中,我们提出了一种新颖的方式评估计算机网络的安全性基于Q-learning应用到经过提炼的攻击图。主要的贡献在于通过强化学习为网络地形建模,改变Q-learning算法,使其能够应用于计算机网络的漏洞分析。首先,我们使用转移图为环境建模;然后我们应用Q-learning算法去寻找可能的攻击路径(系统管理员能够使用是定最佳的策略为系统打补丁)。这是一种有效的方式分析网络安全,我们了解了攻击者可能采取的攻击路径威胁我们的系统安全,然后系统管理员能够采取有效的措施来缓解攻击者的进攻。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号