在强化学习中使用网络地形进行渗透测试
Title: Using Cyber Terrain in Reinforcement Learning for Penetration Testing
Code: None
一、介绍
RL应用于渗透测试的攻击图之中,但是训练有素的代理并不能反映现实情况,因为攻击图缺乏对于网络地形的描述。目前通常使用CVSS及其组件构建攻击图,但是通过完全依赖抽象化,网络表示可能偏向于漏洞,而不是攻击者如何计划或执行攻击活动的实际操作,这会导致RL方法收敛于不切实际的攻击活动。
在本文中我们提出基于网络地形的概念构建攻击图的方法,将OAKOC地形分析框架构建到攻击图的MDP模型中,以使RL代理在渗透测试期间构建更为真实的攻击活动。
我们在实验中展示了我们的方法,其中防火墙被视为障碍物,并且表示在(1)奖励空间和(2)动态状态中,通过实验,我们展示了网络地形分析可以为RL的攻击图增加真实感。
二、RL渗透测试
(1)将网络结构提取到攻击图中 ————通过使用MulVal提取
(2)在提取的攻击图上指定MDP(或POMDP)
(3)在MDP上部署RL
我们通过在状态和奖励中添加地形信息,以接近实际情况。通过状态添加地形信息,就是修改状态S和P(s,a,s')来实现,通过使用状态,我们将地形表示为MDP动态的影响。通过奖励添加地形信息,就是修改奖励R来实现,通过使用奖励,我们使用激励代理的方式来实现。
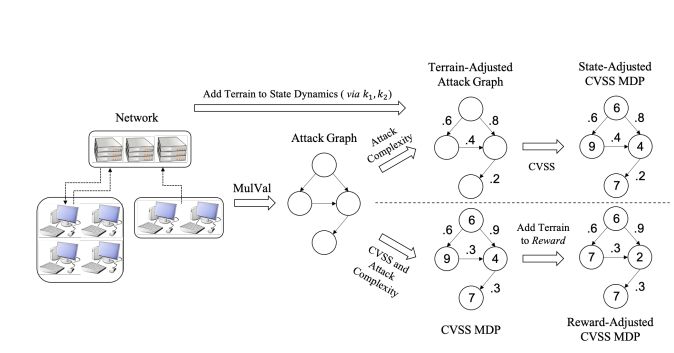
我们现在将防火墙视为网络地形障碍,并使用提出的方法将网络地形整合到基于CVSS的攻击图之中。
(1)通过奖励添加
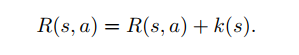

其中 w ≤ 0 是调整激励强度的参数。我们根据通信协议的安全性来改变奖励的变化。当存在多个协议时,它们的k值是平均的。
(2)通过状态添加
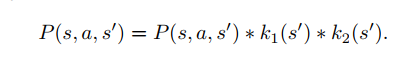
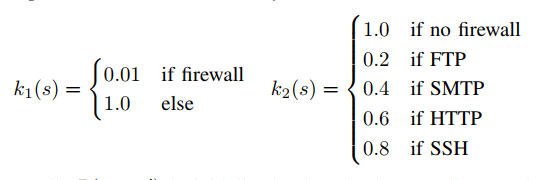
k1对应与防火墙是否存在,k2对应于防火墙的重要性。k1引入是为了避免防火墙,k2则是抵消了对高价值目标的强调,如果存在多个协议时,它们的k2值是平均的。
三、实验结果
对比DQN在(1)CVSS-MDP(2)奖励调整MDP,通过R(3)状态调整MDP,通过状态转移概率P中的表现。我们使用了拥有122个主机的网络,攻击图有955个顶点和2350条边,其中所有的结果中w = -2,网络地形的引入使得跳数增加,因为我们的代理需要绕过防火墙。
普通 MDP 和经过状态调整的 MDP 之间的奖励函数是相同的,但在普通 MDP 和奖励调整后的 MDP 之间是不同的。用于调整 R 的 w 参数会降低奖励,因此我们预计会看到更低的奖励。
普通 MDP 和 状态调整 MDP 之间的类似比较,我们看到了更大的奖励,正如预期的那样,由于跳数更多。在普通 MDP 上,代理平均每跳 3.6 个单位的奖励,而在状态调整的 MDP 上,代理平均每跳 2.8 个单位的奖励。
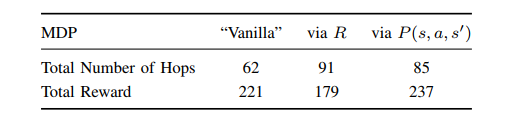
下图显示了 DQN 代理获得的平均奖励与训练集数的关系。每 4 集评估一次总奖励,每集的最大长度为 2500 步。在 80 集之后获得的高平均奖励值意味着代理将大部分时间都花在接近终端状态。普通MDP 与协议无关。虽然上表显示了代理可以在协议之间进行选择时的状态调整和奖励调整的总奖励,但在下图中,状态调整和奖励调整的图显示了代理被限制为单一选择协议时的平均奖励。图表显示我们的方法能够表示 FTP 是比 SSH 更重要的网络障碍。
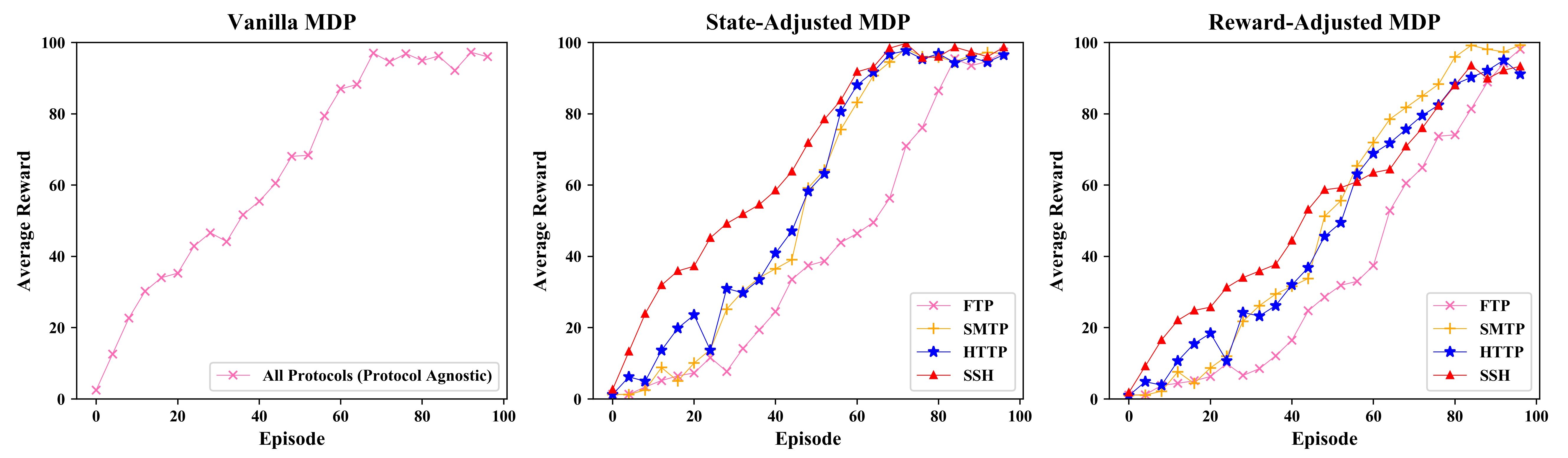
上图显示了原版路径,中图显示了状态调整路径,下图显示了奖励调整路径。通过关注路径上的关键节点,路径已大大减少。红色边缘突出显示从初始状态到最终状态的路径差异。在节点 681,存在防火墙,导致代理使用状态调整和奖励调整的 MDP 来寻找替代路径。它们的路径在节点 136 之后有所不同。
四、结论
通过修改状态转移概率P和奖励函数R来引入网络地形来增强基于CVSS的攻击图方法,我们使用DQN进行了评估,发现总奖励、跳数、平均奖励和攻击活动存在明显差异。
从手动构建的MDP到基于CVSS的MDP转变标志着对扩展基于攻击图的MDP的构建的重视,本文提出的方法保持了一种自动化的、面向规模的方法来构建MDP,同时引入了网络地形的概念来将RL的代理行为变为现实。
未来的方向应该考虑如何将更多的网络地形元素融入到MDP的构建之中,扩展攻击图的大小,开发使用多个初始状态和终止状态的攻击图制图方法。

