基于改进深度Q网络的自动化渗透测试系统
Title: Autonomous Penetration Testing Based on Improved Deep Q-Network
Code: https://networkattacksimulator.readthedocs.io/en/latest/
摘要
本文提出了一种改进的DQN被命名为NDSPI-DQN,算法中我们整合了DQN的五个扩展方向,包括噪声网络、软Q学习、斗争结构、优先经验重放和内在好奇心模型来提高探索效率,同时为了减小动作空间,我们对攻击向量进行解耦,并将DQN的估计器分割开来,分别计算动作的两个元素,以减少动作空间。
与传统的Q-learning算法相比,基于DQN的方法在使用深度神经网络进行函数逼近来处理大状态速度问题时具有天然优势。但是目前基于DQN的方法仍然收到稀疏回报问题和网络规模增加导致的大行动空间的困扰。目前基于强化学习的自主测试研究仅应用于简单的网络场景,在收敛和扩展性能方面还有很大的提升空间。
本文使用了Nasim进行实验,Nasim是一个抽象的模拟实验研究平台,可以作为测试RL的基准。
Q-learning算法和DQN算法
Q-learning算法是一种被广泛使用的无模型的基于值的算法,无模型意味着它试图通过反复实验来学习最优策略,而不需要对环境建模。Q-函数将随着对环境的探索和利用而收敛,然后代理可以使用它来为状态选择贪婪的行为,Q函数的更新公式为:

传统的表格式Q学习算法在训练过程中使用一个表来存储状态-动作值,但由于表的大小有限,不能用于解决大状态空间的问题,DRL是深度学习和强化学习的结合,它使得应对维数灾难成为可能。DQN算法使用深度神经网络作为函数逼近器来生成状态-动作值,为了保证算法的收敛性,DQN采用了经验重放机制,通过从内存中随机抽样来提高以往经验的使用效率,并且去除数据之间的相关性,为了提高算法的稳定性,DQN维护了两个独立的网络(权重为\(\theta\)的Q网络和权重为\(\theta ^-\)的目标Q网络) 来生成预测Q值和目标Q值。
目标Q网络的Q值计算和DQN损失函数定义如下:
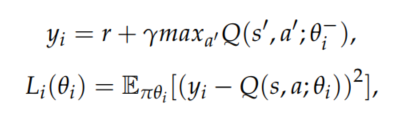
在MDP过程中,一个行动a可以看作是<h,o>定义的攻击向量,这意味着代理对主机h采取了操作o。在任何的训练步骤中,代理的行动空间大小为O(M*N),其中M是网络中主机的数量,N是攻击目标的可执行操作数量。
奖励是代理的驱动力,我们将奖励函数定义为所有被攻击主机的价值减去所有行动的成本:
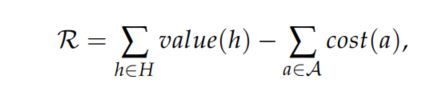
当网络规模增大时,代理的学习效率主要收到两个挑战的限制:
- 稀疏奖励问题,通常网络中只有少数具有正值的敏感主机,所以随着网络规模的增加,奖励变得稀疏,因此算法变得难以收敛。
- 大动作空间问题,代理通过反复实验来学习最优策略,动作空间随着网络规模的增加而增加,这会降低探索效率并增加试错成本。
DQN扩展
软Q学习:一种用于学习最大熵策略的方法,它允许学习不同的策略和更好的探索,并且被证明在连续动作任务中表现更好。将其与DQN结合处理离散动作任务时,目标Q值被计算为如下,其中\(\sigma\)是用于衡量熵和奖励的相对重要性的参数
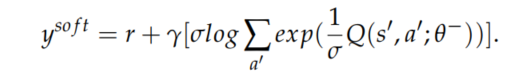
动作选择策略,软Q学习没有使用贪心策略,而是使用softmax策略,通过为每个动作分配被选中的概率来进行探索。
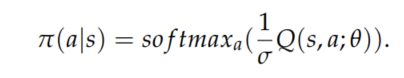
决斗网络通过改变DQN的神经网络架构来提高策略评估的性能,它将Q值函数分解为值函数和优势函数之和
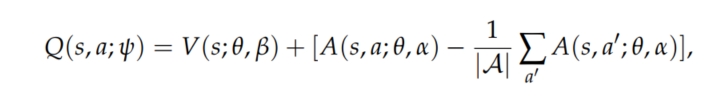
\(\theta , \alpha , \beta\)分别表示共享网络参数,价值流参数和优势流参数,\(\psi\)是它们之间的关联。
DQN使用经验重放机制来保证样本是独立同分布的,但是传统的随机抽样方法忽略了不同样本的显著性,为了使经验重放更有效,优先经验重放使用时间差异误差(TD error,\(\delta\))来衡量转换的重要性,它以概率对转换进行采样:
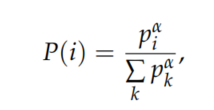
其中\(\alpha\)表示使用了多少优先级,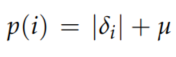 是表示具有常数\(\mu\)的转换的优先级。
是表示具有常数\(\mu\)的转换的优先级。
噪声网络通过向DQN的线性层添加参数高斯噪声来提高探索效率。DQN使用\(\epsilon\)-greedy策略基于Q函数贪婪地选择动作或者基于概率\(\epsilon\)随机地选择动作,相比之下。噪声网络对大动作空间的问题有着更加丰富的探索。噪声网络的噪声线性层定义为:
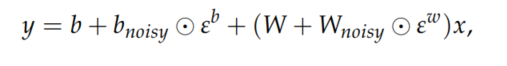
$\varepsilon^b , \varepsilon^w $表示噪声随机变量, 表示元素乘积,此变换用于替换标准线性方程y = b + Wx
表示元素乘积,此变换用于替换标准线性方程y = b + Wx
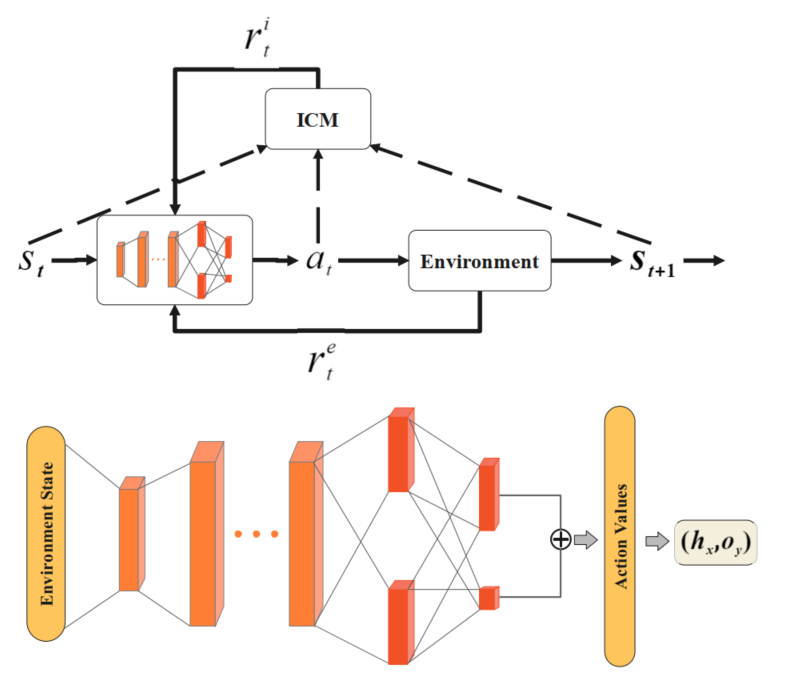
好奇心作为内部奖励信号驱动代理在外部的稀疏环境中进行探索,外部奖励由环境提供,内部奖励由自我监督的内在好奇心模块(ICM)产生,因此好奇心驱动代理的目标是最大化内部奖励\(r^i\)和外部奖励\(r^e\)的总和。ICM由两个子模块组成:
给定由状态\(s_t,s_{t+1}\)编码的特征向量\(\phi(s_t),\phi(s_{t+1})\),训练逆模型以预测动作\(\widehat{a}_t\);前向模型将\(\phi(s_t),a_t\)作为输入,并预测下一个状态\(\widehat{\phi}(s_{t+1})\)。好奇心被定义为环境状态的预测误差,因此内部奖励被计算为
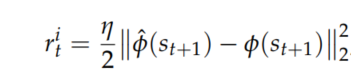
\(\eta\)是比例因子,逆模型和正模型分别通过最小化损失函数\(L_I(a_t,\widehat{a}_t)\)和\(L_F(\phi(s_{t+1},\widehat{\phi}(s_{t+1})))\)进行优化,那么ICM的整体损失函数就是它们的加权和。
集成和解耦
我们将扩展结合在一起,并提出了NDSPI-DQN算法来训练渗透代理,如下图所示,我们为Q网络和目标网络应用添加噪声的决斗网络结构。神经网络的输入为环境状态向量,隐藏层与输入层和输出层全连接,输出为所有动作的预测值,不再使用\(\epsilon\)-greedy策略,而是由softmax策略直接选择动作
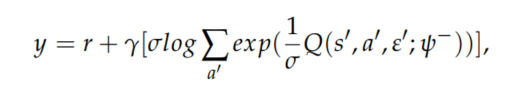
目标是最大化ICM产生的外部奖励和内部奖励,优先经验重放以更加频繁存储和采样重要的转换,结合这些扩展,动作值函数可以写成\(Q(s,a,\varepsilon;\psi)\),其中\(\varepsilon,\psi\)分别表示噪声变量和连接网络参数,因此目标Q值计算为
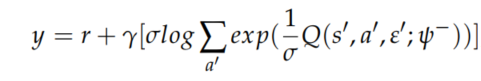
其中\(r = r_i + r_e\),整体损失函数定义为
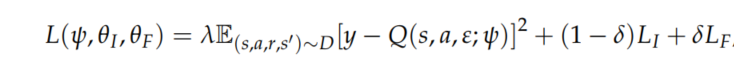
其中\(\lambda,\delta\)是衡量策略网络和ICM模型损失的重要性的标量。
仅仅改善智能体的探索是不够的,为了减少代理在探索过程中的试错成本,我们可以通过解耦可以被看做是攻击向量a=<h,o>的动作来减少动作空间。我们的方法的关键是将NDSPI-DQN网络分成两个独立的流:一个用来估计主机的值,另一个用来估计动作的值,这意味着代理可以独立选择受害者主机和根据当前状态环境向量对目标采取的操作。对于具有M个目标主机和N个可执行操作的环境中的代理,神经网络的输出分为两个部分:M个主机的Q值和N个操作的Q值,因此动作空间从原来的O(M*N)减少为O(M + N)
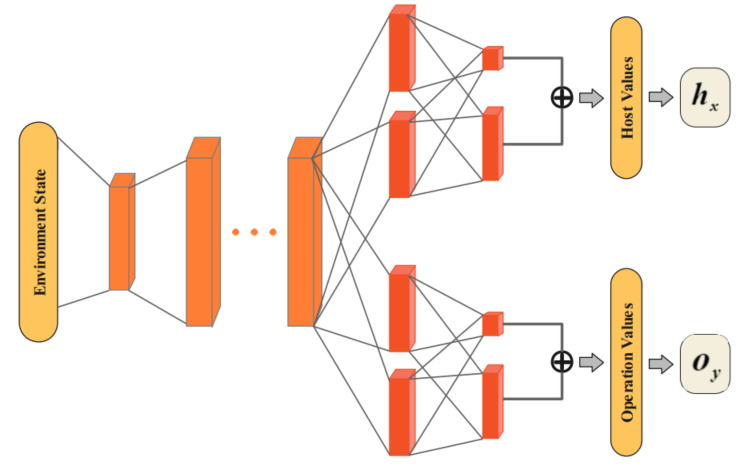
在给定输入状态的情况下,两个流独立地输出动作元素\(\pi(h|s)=softmax_h(\frac{1}{\sigma_h}Q(s,h,\varepsilon;\psi_h))\)和\(\pi(o|s)=softmax_o(\frac{1}{\sigma_o}Q(s,o,\varepsilon;\psi_o))\)。然后选定的主机h和操作o被组合到攻击向量之中,以作用于环境。我们使用主机Q值和操作Q值的平均值来计算总耗损:
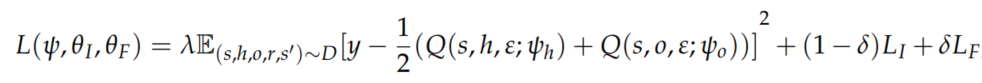
其中\(\psi_h,\psi_o\)是主机流和操作流的参数,\(\psi=\{\psi_h,\psi_o\}\)是公共网络参数
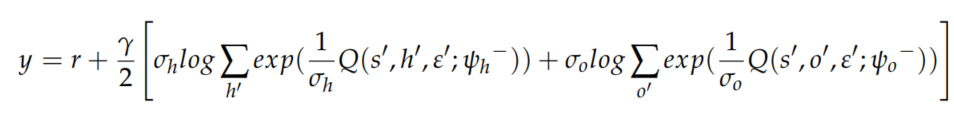
性能比较
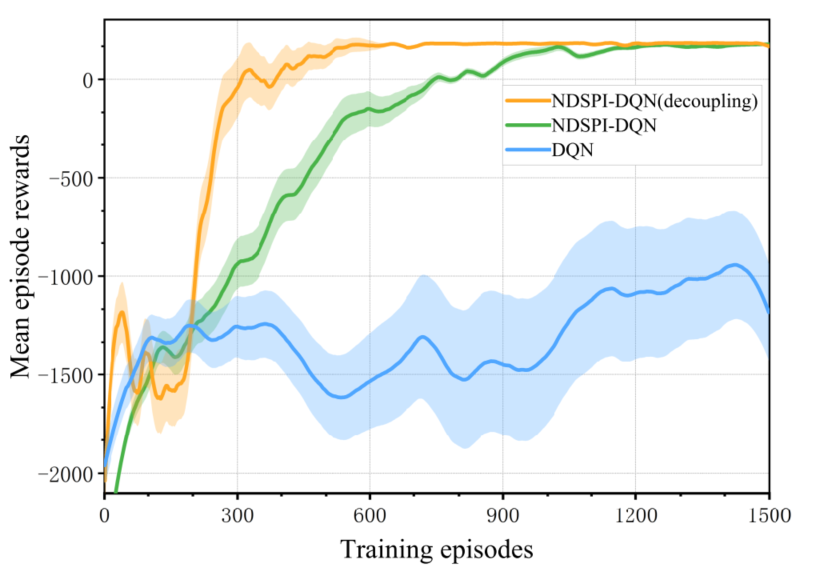
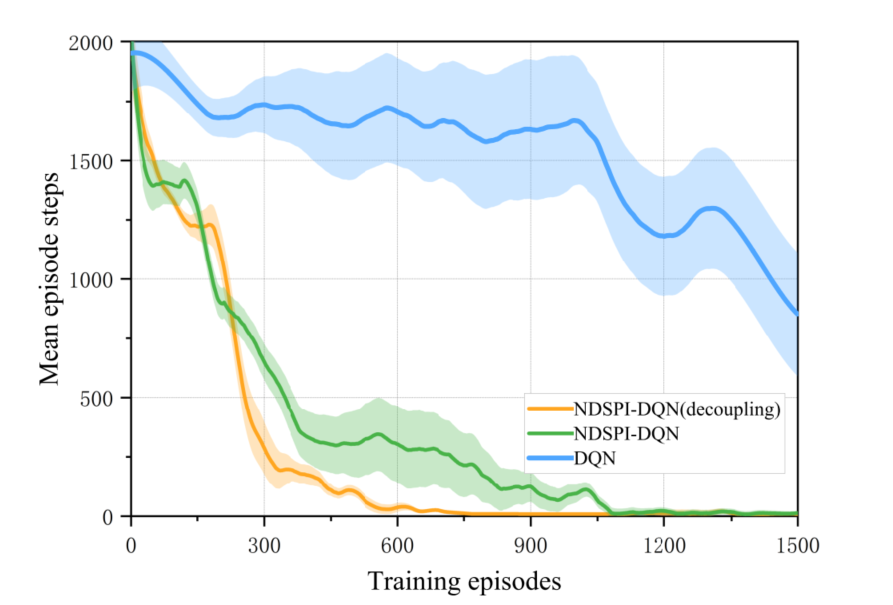
通过如上图所示的收敛速率比较,我们可以看到本文提出的算法相对传统的DQN算法能够更好更快地收敛,传统的DQN算法难以收敛,因此我们下面探究在大规模网络下解耦的NDSPI-DQN算法与没有解耦的进行对比。
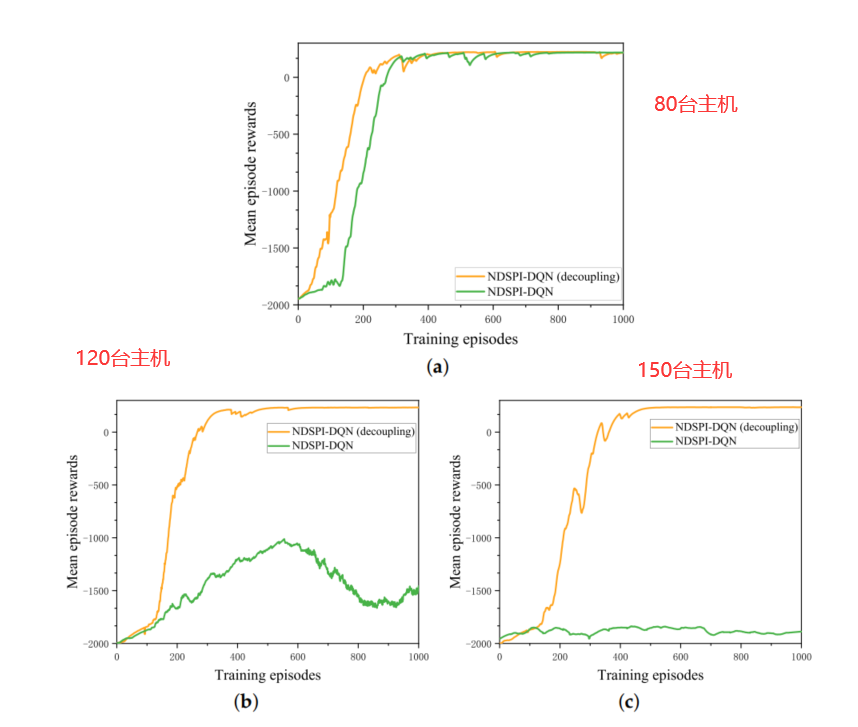
我们可以看到在解耦的NDSPI-DQN算法几乎没有收到网络规模的影响,能够快速收敛,但是没有解耦的NDSPI-DQN算法在网络规模变大后,算法的性能受到影响,变得难以收敛。
总结
- 在集成了多种DQN扩展之后,促进了代理有效的探索,进而缓解了稀疏回报的问题,使得智能体可以在每集有限的训练步骤内高效地学习到最优策略
- 行动空间的缩小降低了试错的成本,大大加快了大规模网络环境下的收敛速度
- 奖励值对于算法的性能有着关键性的影响
- 多代理RL和分层RL这些更为先进的算法

