深入理解RocketMQ延迟消息
延迟消息是实际开发中一个非常有用的功能,本文第一部分从整体上介绍秒级精度延迟消息的实现思路,在第二部分结合RocketMQ的延迟消息实现,进行细致的讲解,点出关键部分的源码。第三步介绍延迟消息与消息重试的关系。
延迟消息介绍
基本概念:延迟消息是指生产者发送消息发送消息后,不能立刻被消费者消费,需要等待指定的时间后才可以被消费。
场景案例:用户下了一个订单之后,需要在指定时间内(例如30分钟)进行支付,在到期之前可以发送一个消息提醒用户进行支付。
一些消息中间件的Broker端内置了延迟消息支持的能力,如:
- NSQ:这是一个go语言的消息中间件,其通过内存中的优先级队列来保存延迟消息,支持秒级精度,最多2个小时延迟。Java中也有对应的实现,如ScheduledThreadPoolExecutor内部实际上也是使用了优先级队列。
- QMQ:采用双重时间轮实现。可参考:任意时间延时消息原理讲解:设计与实现
- RabbitMQ:需要安装一个rabbitmq_delayed_message_exchange插件。
- RocketMQ:RocketMQ 开源版本延迟消息临时存储在一个内部主题中,不支持任意时间精度,支持特定的 level,例如定时 5s,10s,1m 等。
Broker端内置延迟消息处理能力,核心实现思路都是一样:将延迟消息通过一个临时存储进行暂存,到期后才投递到目标Topic中。如下图所示:

步骤说明如下:
- producer要将一个延迟消息发送到某个Topic中
- Broker判断这是一个延迟消息后,将其通过临时存储进行暂存。
- Broker内部通过一个延迟服务(delay service)检查消息是否到期,将到期的消息投递到目标Topic中。这个的延迟服务名字为delay service,不同消息中间件的延迟服务模块名称可能不同。
- 消费者消费目标topic中的延迟投递的消息
显然,临时存储模块和延迟服务模块,是延迟消息实现的关键。上图中,临时存储和延迟服务都是在Broker内部实现,对业务透明。
此外, 还有一些消息中间件原生并不支持延迟消息,如Kafka。在这种情况下,可以选择对Kafka进行改造,但是成本较大。另外一种方式是使用第三方临时存储,并加一层代理。
第三方存储选型要求:
对于第三方临时存储,其需要满足以下几个特点:
高性能:写入延迟要低,MQ的一个重要作用是削峰填谷,在选择临时存储时,写入性能必须要高,关系型数据库(如Mysql)通常不满足需求。高可靠:延迟消息写入后,不能丢失,需要进行持久化,并进行备份支持排序:支持按照某个字段对消息进行排序,对于延迟消息需要按照时间进行排序。普通消息通常先发送的会被先消费,延迟消息与普通消息不同,需要进行排序。例如先发一条延迟10s的消息,再发一条延迟5s的消息,那么后发送的消息需要被先消费。支持长时间保存:一些业务的延迟消息,需要延迟几个月,甚至更长,所以延迟消息必须能长时间保留。不过通常不建议延迟太长时间,存储成本比较大,且业务逻辑可能已经发生变化,已经不需要消费这些消息。
例如,滴滴开源的消息中间件DDMQ,底层消息中间件的基础上加了一层代理,独立部署延迟服务模块,使用rocksdb进行临时存储。rocksdb是一个高性能的KV存储,并支持排序。
此时对于延迟消息的流转如下图所示:

说明如下:
- 生产者将发送给producer proxy,proxy判断是延迟消息,将其投递到一个缓冲Topic中;
- delay service启动消费者,用于从缓冲topic中消费延迟消息,以时间为key,存储到rocksdb中;
- delay service判断消息到期后,将其投递到目标Topic中。
- 消费者消费目标topic中的数据
这种方式的好处是,因为delay service的延迟投递能力是独立于broker实现的,不需要对broker做任何改造,对于任意MQ类型都可以提供支持延迟消息的能力。例如DDMQ对RocketMQ、Kafka都提供了秒级精度的延迟消息投递能力,但是Kafka本身并不支持延迟消息,而开源版本的 RocketMQ 只支持几个指定的延迟级别,并不支持秒级精度的定时消息。
事实上,DDMQ还提供了很多其他功能,仅仅从延迟消息的角度,完全没有必要使用这个proxy,直接将消息投递到缓冲Topic中,之后通过delay service完成延迟投递逻辑即可。
具体到delay service模块的实现上,也有一些重要的细节:
- 为了保证服务的高可用,delay service也是需要部署多个节点。
- 为了保证数据不丢失,每个delay service节点都需要消费缓冲Topic中的全量数据,保存到各自的持久化存储中,这样就有了多个备份,并需要以时间为key。不过因为是各自拉取,并不能保证强一致。如果一定要强一致,那么delay service就不需要内置存储实现,可以借助于其他支持强一致的存储。
- 为了避免重复投递,delay service需要进行选主,可以借助于zookeeper、etcd等实现。只有master可以通过生产者投递到目标Topic中,其他节点处于备用状态。否则,如果每个节点进行都投递,那么延迟消息就会被投递多次,造成消费重复。
- master要记录自己当前投递到的时间到一个共享存储中,如果master挂了,从slave节点中选出一个新的master节点,从之前记录时间继续开始投递。
- 延迟消息的取消:一些延迟消息在未到期之前,可能希望进行取消。通常取消逻辑实现较为复杂,且不够精确。对于那些已经快要到期的消息,可能还未取消之前,已经发送出去了,因此需要在消费者端做检查,才能万无一失。
RocketMQ中的延迟消息
开源RocketMQ支持延迟消息,但是不支持秒级精度。默认支持18个level的延迟消息,这是通过broker端的messageDelayLevel配置项确定的,如下:
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
Broker在启动时,内部会创建一个内部主题:SCHEDULE_TOPIC_XXXX,根据延迟level的个数,创建对应数量的队列,也就是说18个level对应了18个队列。注意,这并不是说这个内部主题只会有18个队列,因为Broker通常是集群模式部署的,因此每个节点都有18个队列。
延迟级别的值可以进行修改,以满足自己的业务需求,可以修改/添加新的level。例如:你想支持2天的延迟,修改最后一个level的值为2d,这个时候依然是18个level;也可以增加一个2d,这个时候总共就有19个level。
生产者发送延迟消息
生产者在发送延迟消息非常简单,只需要设置一个延迟级别即可,注意不是具体的延迟时间,如:
Message msg=new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
如果设置的延迟level超过最大值,那么将会重置最最大值。
Broker端存储延迟消息
延迟消息在RocketMQ Broker端的流转如下图所示:

可以看到,总共有6个步骤,下面会对这6个步骤进行详细的讲解:
- 修改消息Topic名称和队列信息
- 转发消息到延迟主题的CosumeQueue中
- 延迟服务消费SCHEDULE_TOPIC_XXXX消息
- 将信息重新存储到CommitLog中
- 将消息投递到目标Topic中
- 消费者消费目标topic中的数据
第一步:修改消息Topic名称和队列信息
RocketMQ Broker端在存储生产者写入的消息时,首先都会将其写入到CommitLog中。之后根据消息中的Topic信息和队列信息,将其转发到目标Topic的指定队列(ConsumeQueue)中。
由于消息一旦存储到ConsumeQueue中,消费者就能消费到,而延迟消息不能被立即消费,所以这里将Topic的名称修改为SCHEDULE_TOPIC_XXXX,并根据延迟级别确定要投递到哪个队列下。
同时,还会将消息原来要发送到的目标Topic和队列信息存储到消息的属性中。相关源码如下所示:
org.apache.rocketmq.store.CommitLog#asyncPutMessage
public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) {
//如果是延迟消息
if (msg.getDelayTimeLevel() > 0) {
//如果设置的级别超过了最大级别 重置延迟级别
if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel());
}
//修改TOPIC的投递目标为内部主题SCHEDULE_TOPIC_XXX
topic = TopicValidator.RMQ_SYS_SCHEDULE_TOPIC;
//根据delayLevel 确定消息投递到SCHEDULE_TOPIC_XXX内部的哪个队列中
queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel());
// Backup real topic, queueId
//记录原始topic、queueId
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
//更新消息的topic、queueId
msg.setTopic(topic);
msg.setQueueId(queueId);
}
}
第二步:转发消息到延迟主题的CosumeQueue中
CommitLog中的消息转发到CosumeQueue中是异步进行的。在转发过程中,会对延迟消息进行特殊处理,主要是计算这条延迟消息需要在什么时候进行投递。
投递时间=消息存储时间(storeTimestamp) + 延迟级别对应的时间
需要注意的是,会将计算出的投递时间当做消息Tag的哈希值存储到CosumeQueue中,CosumeQueue单个存储单元组成结构如下图所示:

其中:
Commit Log Offset:记录在CommitLog中的位置。Size:记录消息的大小Message Tag HashCode:记录消息Tag的哈希值,用于消息过滤。特别的,对于延迟消息,这个字段记录的是消息的投递时间戳。这也是为什么java中hashCode方法返回一个int型,只占用4个字节,而这里Message Tag HashCode字段却设计成8个字节的原因。
相关源码参见:CommitLog#checkMessageAndReturnSize
public DispatchRequest checkMessageAndReturnSize(java.nio.ByteBuffer byteBuffer, final boolean checkCRC,
final boolean readBody) {
// Timing message processing
{
//如果消息需要投递到延迟主题SCHEDULE_TOPIC_XXX中
String t = propertiesMap.get(MessageConst.PROPERTY_DELAY_TIME_LEVEL);
if (TopicValidator.RMQ_SYS_SCHEDULE_TOPIC.equals(topic) && t != null) {
int delayLevel = Integer.parseInt(t);
if (delayLevel > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) {
delayLevel = this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel();
}
//如果延迟级别大于0 计算目标投递时间 并将其当作tag哈希值
if (delayLevel > 0) {
tagsCode = this.defaultMessageStore.getScheduleMessageService().computeDeliverTimestamp(delayLevel,
storeTimestamp);
}
}
}
}
第三步:延迟服务消费SCHEDULE_TOPIC_XXXX消息
Broker内部有一个ScheduleMessageService类,其充当延迟服务,消费SCHEDULE_TOPIC_XXXX中的消息,并投递到目标Topic中。
ScheduleMessageService在启动时,其会创建一个定时器Timer,并根据延迟级别的个数,启动对应数量的TimerTask,每个TimerTask负责一个延迟级别的消费与投递。
相关源码如下所示:ScheduleMessageService#start
public void start() {
if (started.compareAndSet(false, true)) {
super.load();
//1.创建定时器Timer
this.timer = new Timer("ScheduleMessageTimerThread", true);
//2.针对每个延迟级别 创建一个 TimerTask
//2.1: 迭代每个延迟级别,delayLevelTable是一个Map 记录了每个延迟级别对应的延迟时间
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
Integer level = entry.getKey();
Long timeDelay = entry.getValue();
Long offset = this.offsetTable.get(level);
if (null == offset) {
offset = 0L;
}
//2.2 针对每个延迟级别 创建一个 TimerTask
if (timeDelay != null) {
this.timer.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME);
}
}
}
需要注意的是,每个TimeTask在检查消息是否到期时,首先检查对应队列中尚未投递第一条消息,如果这条消息没到期,那么之后的消息都不会检查。如果到期了,则进行投递,并检查之后的消息是否到期。
第四步:将信息重新存储到CommitLog中
在将消息到期后,需要投递到目标Topic。由于在第一步已经记录了原来的Topic和队列信息,因此这里重新设置,再存储到CommitLog即可。此外,由于之前Message Tag HashCode字段存储的是消息的投递时间,这里需要重新计算tag的哈希值后再存储。
源码参见:DeliverDelayedMessageTimerTask的messageTimeup方法。
第五步:将消息投递到目标Topic中
这一步与第二步类似,不过由于消息的Topic名称已经改为了目标Topic。因此消息会直接投递到目标Topic的ConsumeQueue中,之后消费者即消费到这条消息。
延迟消息与消费重试的关系
RocketMQ提供了消息重试的能力,在并发模式消费消费失败的情况下,可以返回一个枚举值RECONSUME_LATER,那么消息之后将会进行重试。如:
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
//处理消息,失败,返回RECONSUME_LATER,进行重试
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
});
重试默认会进行重试16次。使用过RocketMQ消息重试功能的用户,可能看到过以下这张图:
| 第几次重试 | 与上次重试的间隔时间 | 第几次重试 | 与上次重试的间隔时间 |
|---|---|---|---|
| 1 | 10 秒 | 9 | 7 分钟 |
| 2 | 30 秒 | 10 | 8 分钟 |
| 3 | 1 分钟 | 11 | 9 分钟 |
| 4 | 2 分钟 | 12 | 10 分钟 |
| 5 | 3 分钟 | 13 | 20 分钟 |
| 6 | 4 分钟 | 14 | 30 分钟 |
| 7 | 5 分钟 | 15 | 1 小时 |
| 8 | 6 分钟 | 16 | 2 小时 |
细心地的读者发现了,消息重试的16个级别,实际上是把延迟消息18个级别的前两个level去掉了。事实上,RocketMQ的消息重试也是基于延迟消息来完成的。在消息消费失败的情况下,将其重新当做延迟消息投递回Broker。
在投递回去时,会跳过前两个level,因此只重试16次。当然,消息重试还有一些其他的设计逻辑,在之后的文章将会进行分析。
自定义延迟时间
开源版本延迟消息缺点:固定了Level,不够灵活,最多只能支持18个Level
Java中的延迟任务
Timer
public static void main(String[] args) {
Timer timer = new Timer();
//在3秒后执行run方法,之后每隔1秒执行一次run方法
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("执行任务");
}
}, 3000);
}
ScheduledThreadPoolExecutor
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService
= Executors.newSingleThreadScheduledExecutor();
scheduledExecutorService.schedule(
() -> System.out.println("执行任务"), 3000,
TimeUnit.MILLISECONDS);
}
其原理都是基于最小堆实现的延迟队列DelayQueue
插入任务的时间复杂度为Olog(n),消息TPS较高时性能仍不够快,有没O(1)复杂度的方案呢?
TimeWheel时间轮
Netty、Kafka中使用TimeWheel来优化I/O超时的操作
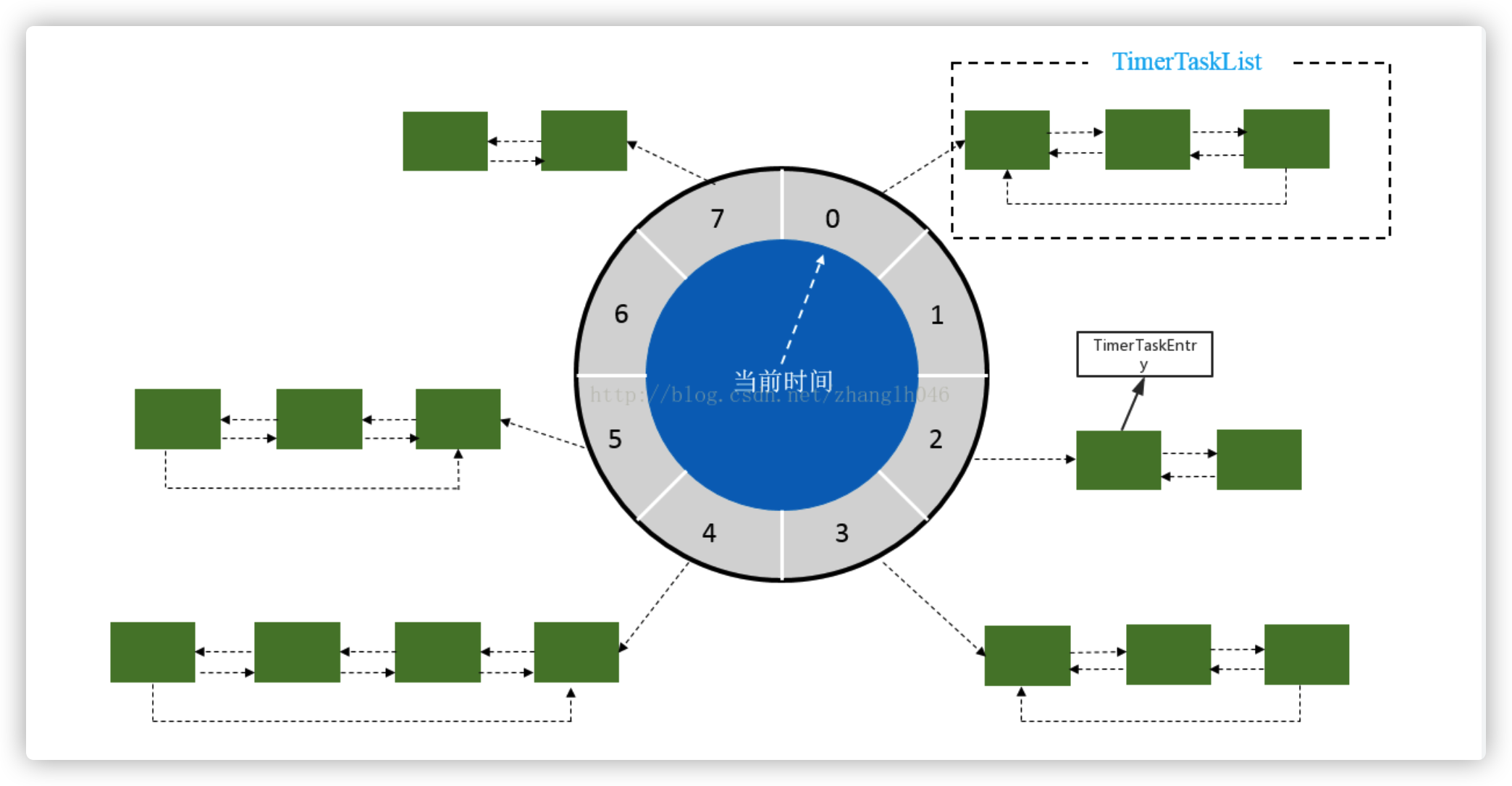
ticksPerWheel:槽位数
tick:每个槽位的时间间隔
假设这个延迟时间为X秒,那么X%(ticksPerWheel * tick)可以计算出X所属的TimeWheel中位置
TimeWheel的size为8,那么延迟1秒和9秒的消息都处在一个链表中。如果用户先发了延迟9秒的消息再发了延迟1秒的消息,他们在一个链表中所以延迟1秒的消息会需要等待延迟9秒的消息先投递。显然这是不能接受的,那么如何解决这个问题?
-
排序
显然,如果对TimeWheel一个tick中的元素进行排序显然就解决了上面的问题。但是显而易见的是排序是不可能的。 -
扩大时间轮
最直观的方式,我们能不能通过扩大时间轮的方式避免延迟9和延迟1落到一个tick位置上?
假设支持30天,精度为1秒,那么ticksPerWheel=30 * 24 * 60 * 60,这样每一个tick上的延迟都是一致的,不存在上述的问题(类似于将RocketMQ的Level提升到了30 * 24 * 60 * 60个)。但是TimeWheel需要被加载到内存操作,这显然是无法接受的。 -
多级时间轮
单个TimeWheel无法支持,那么能否显示中的时针、分针的形式,构建多级时间轮来解决呢?

多级时间轮解决了上述的问题,但是又引入了新的问题:
在整点(tick指向0的位置)需要加载大量的数据会导致延迟,比如第二个时间轮到整点需要加载未来一天的数据时间轮需要载入到内存,这个开销是不可接受的
- 延迟加载
多级定时轮的问题在于需要加载大量数据到内存,那么能否优化一下将这里的数据延迟加载到内存来解决内存开销的问题呢?
在多级定时轮的方案中,显然对于未来一小时或者未来一天的数据可以不加载到内存,而可以只加载延迟时间临近的消息。
进一步优化,可以将数据按照固定延迟间隔划分,那么每次加载的数据量是大致相同的,不会出tick约大的定时轮需要加载越多的数据,那么方案如下:

基于上述的方案,那么TimeWheel中存储未来30分钟需要投递的消息的索引,索引为一个long型,那么数据量为:30 * 60 * 8 * TPS,相对来说内存开销是可以接受的,比如TPS为1w那么大概开销为200M+。
之后的数据按照每30分钟一个块的形式写入文件,那么每个整点时的操作就是计算一下将30分钟的消息Hash到对应的TimeWheel上,那么排序问题就解决了。
到此为止就只剩下一个问题,如何保存30天的数据?
CommitLog保存超长延迟的数据
CommitLog是有时效性的,比如在我们只保存最近7天的消息,过期数据将被删除。对于延迟消息,可能需要30天之后投递,显然是不能被删除的。
那么我们怎么保存延迟消息呢?
直观的方法就是将延迟消息从CommitLog中剥离出来,独立存储以保存更长的时间。

通过DispatchService将WAL中的延迟消息写入到独立的文件中。这些文件按照延迟时间组成一个链表。
链表长度为最大延迟时间/每个文件保存的时间长度。
那么WAL可以按照正常的策略进行过期删除,Delay Msg File则在一个文件投递完之后进行删除。
唯一的问题是这里会有Delay Msg File带来的随机写问题,但是这个对系统整体性能不会有很大影响,在可接受范围内。
BOUNS
结合TimeWheel和CommitLog保存超长延迟数据的方案,加上一些优化手段,基本就完成了支持任意延迟时间的

方案:
- 消息写入WAL
- Dispatcher处理延迟消息
- 延迟消息一定时间的直接写入TimeWheel
- 延迟超过一定时间写入DelayMessageStorage
- DelayMessageStorage对DelayMsgFile构建一层索引,这样在映射到TimeWheel时只需要做一次Hash操作
- 通过TimeWheel将消息投递到ConsumeQueue中完成对Consumer的可见
本文转载:
https://cloud.tencent.com/developer/article/1581368
https://www.cnblogs.com/hzmark/p/mq-delay-msg.html
