数据结构与算法-散列表
定义
散列表也叫作哈希表(hash table),这种数据结构提供了键(Key)和值(Value)的映射关系。只要给出一个Key,就可以高效查找到它所匹配的Value,时间复杂度接近于O(1)。
哈希表(Hash Table)是一种特殊的数据结构,它最大的特点就是可以快速实现查找、插入和删除。
| 数据结构 | 特点 |
|---|---|
| 数组 | 寻址容易,插入和删除困难 |
| 链表 | 寻址困难,而插入和删除操作容易 |
| 哈希表 | 快速实现查找、插入和删除 |
存储原理
散列表在本质上也是一个数组。散列表的Key则是以字符串类型为主的,通过hash函数把Key和数组下标进行转换。作用是把任意长度的输入通过散列算法转换成固定类型、固定长度的散列值
哈希冲突
由于数组的长度是有限的,当插入的Entry越来越多时,不同的Key通过哈希函数获得的下标有可能是相同的,这种情况,就叫作哈希冲突。
开放寻址法
冲突可能会导致哈希化方案无法实施,前面我们说指定的数组范围大小是实际存储数据的两倍,因此可能有一半的空间是空着的,所以,当冲突产生时,一个方法是通过系统的方法找到数组的一个空位,并把这个单词填入,而不再用哈希函数得到数组的下标,这种方法称为开放地址法。
开发地址法中,若数据项不能直接存放在由哈希函数所计算出来的数组下标时,就要寻找其他的位置。分别有三种方法:线性探测、二次探测以及再哈希法。这里不详细展开
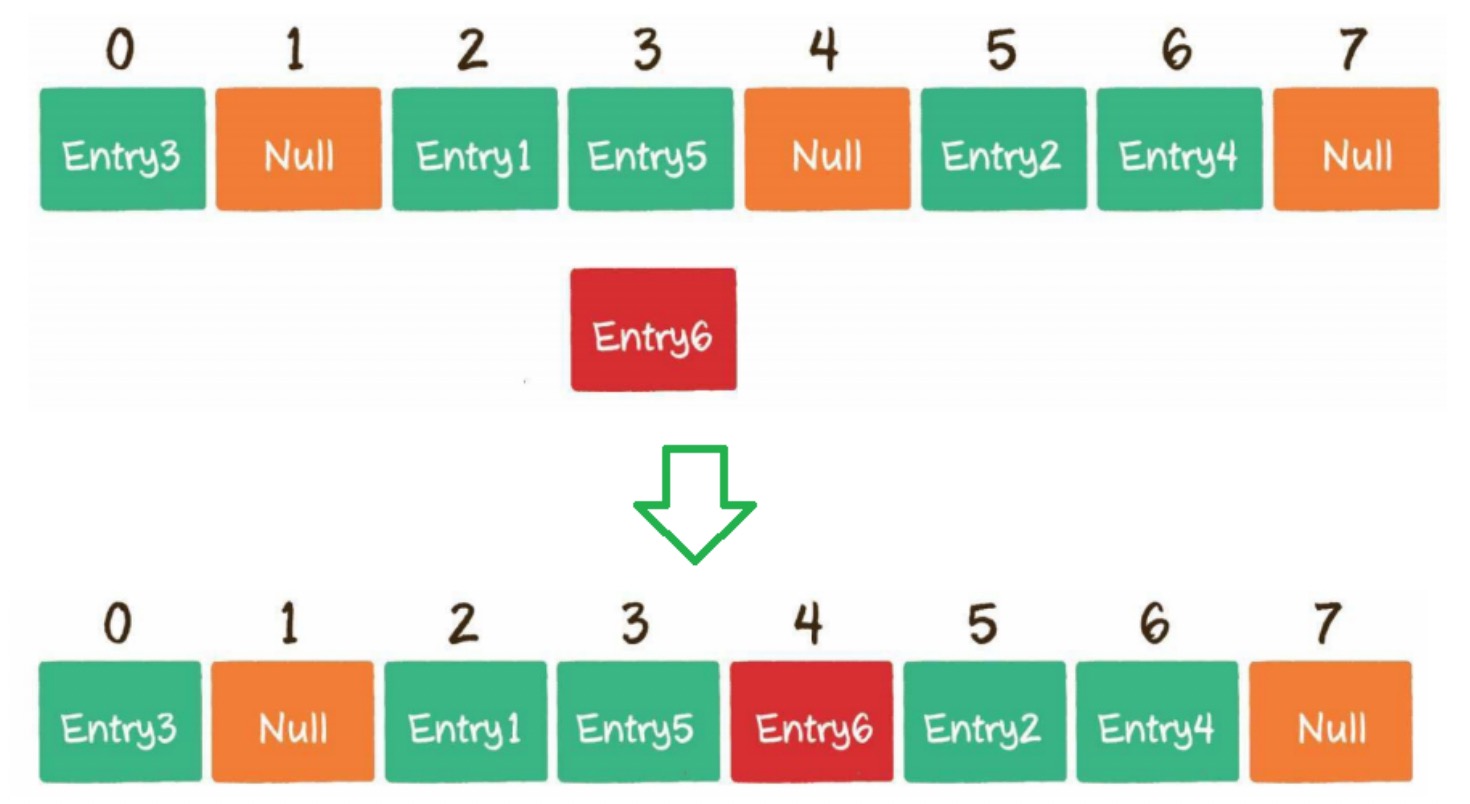
在Java中,ThreadLocal所使用的就是开放寻址法
链地址法
数组的每个数据项都创建一个子链表或子数组,那么数组内不直接存放单词,当产生冲突时,新的数据项直接存放到这个数组下标表示的链表中,这种方法称为链地址法

操作
写操作
写操作就是在散列表中插入新的键值对(在JDK中叫作Entry或Node)
- 通过哈希函数,把Key转化成数组下标
- 如果数组下标对应的位置没有元素,就把这个Entry填充到数组下标的位置。
- 如果里面有数据了 则发送hash冲突,需要转化为链表
读操作
读操作就是通过给定的Key,在散列表中查找对应的Value
- 通过哈希函数,把Key转化成数组下标
- 找到数组下标所对应的元素,如果key不正确,说明产生了hash冲突,则顺着头节点遍历该单链表,再根据key即可取值

Hash扩容
散列表是基于数组实现的,所以散列表需要扩容
当经过多次元素插入,散列表达到一定饱和度时,Key映射位置发生冲突的概率会逐渐提高。这样一来,大量元素拥挤在相同的数组下标位置,形成很长的链表,对后续插入操作和查询操作的性能都有很大影响
影响扩容的因素有两个:
| 因素 | 描述 |
|---|---|
| Capacity | HashMap的当前长度 |
| LoadFactor | HashMap的负载因子(阈值),默认值为0.75f |
当HashMap.Size >= Capacity×LoadFactor时,需要进行扩容
扩容的步骤:
- 扩容,创建一个新的Entry空数组,长度是原数组的2倍
- 重新Hash,遍历原Entry数组,把所有的Entry重新Hash到新数组中
关于HashMap的实现,JDK 8和以前的版本有着很大的不同。当多个Entry被Hash到同一个数组下标位置时,为了提升插入和查找的效率,HashMap会把Entry的链表转化为红黑树这种数据结构。
JDK1.8前在HashMap扩容时,会反序单链表,这样在高并发时会有死循环的可能。
时间复杂度
| 操作 | 复杂度 |
|---|---|
| 写操作: | O(1) + O(m) = O(m) m为单链元素个数 |
| 读操作: | O(1) + O(m) m为单链元素个数 |
| Hash冲突写单链表: | O(m) |
| Hash扩容: | O(n) n是数组元素个数 rehash |
| Hash冲突读单链表: | O(m) m为单链元素个数 |
应用
- HashMap
- Redis字典
- 布隆过滤器:不存在一定为真,存在不一定为真。
- 位图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号