数据结构与算法-链表
概念
链表(linked list)是一种在物理上非连续、非顺序的数据结构,由若干节点(node)所组成。
链表中数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:
- 一个是存储数据元素的数据域,
- 另一个是存储下一个结点地址的指针域。
常见的链表包括:单链表、双向链表、循环链表
单链表
单向链表的每一个节点又包含两部分,一部分是存放数据的变量data,另一部分是指向下一个节点的指针next

Node{
int data;
Node next;
}
双向链表
双向链表的每一个节点除了拥有data和next指针,还拥有指向前置节点的prev指针。

Node{
int data;
Node next;
Node prev;
}
循环链表
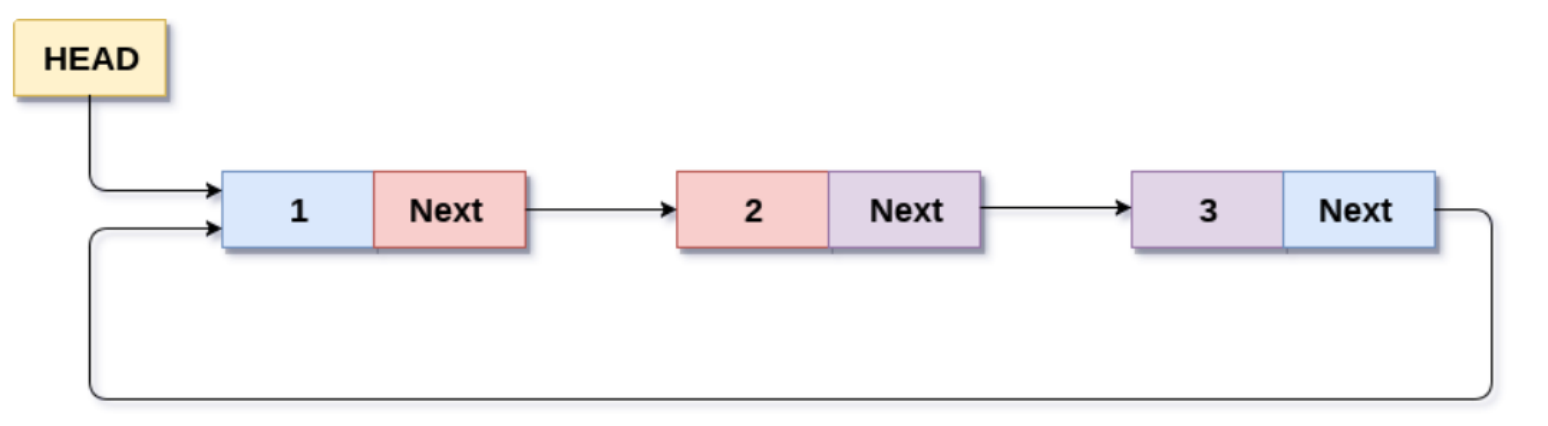
链表的尾节点指向头节点形成一个环,称为循环链表
存储原理
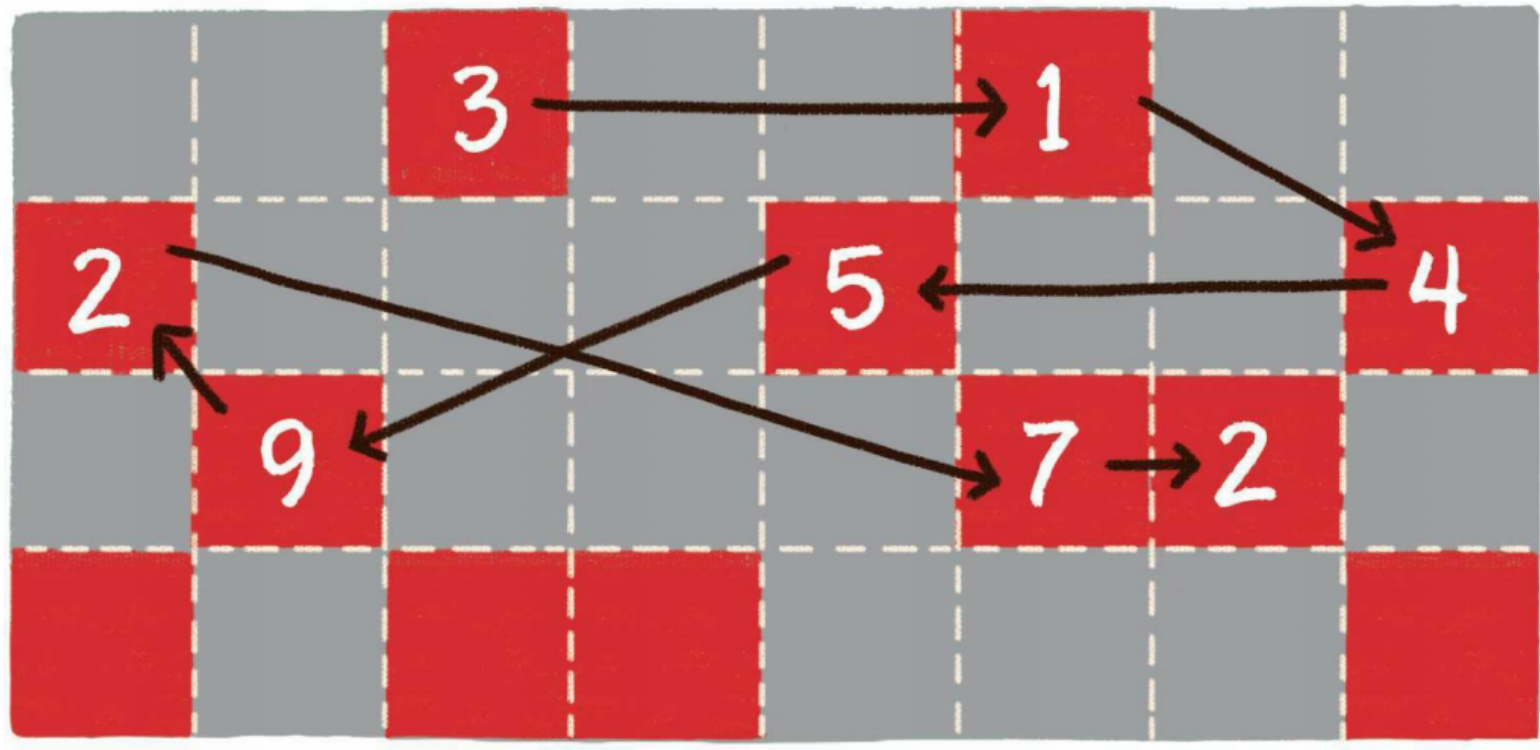
数组在内存中的存储方式是顺序存储(连续存储),链表在内存中的存储方式则是随机存储(链式存储)。
链表的每一个节点分布在内存的不同位置,依靠next指针关联起来。这样可以灵活有效地利用零散的碎片空间。
链表的第1个节点被称为头节点(3),没有任何节点的next指针指向它,或者说它的前置节点为空头结点用来记录链表的基地址。有了它,我们就可以遍历得到整条链表。链表的最后1个节点被称为尾节点(2),它指向的next为空
操作
查找节点
在查找元素时,链表只能从头节点开始向后一个一个节点逐一查找

更新节点

插入节点
尾部插入
把最后一个节点的next指针指向新插入的节点即可
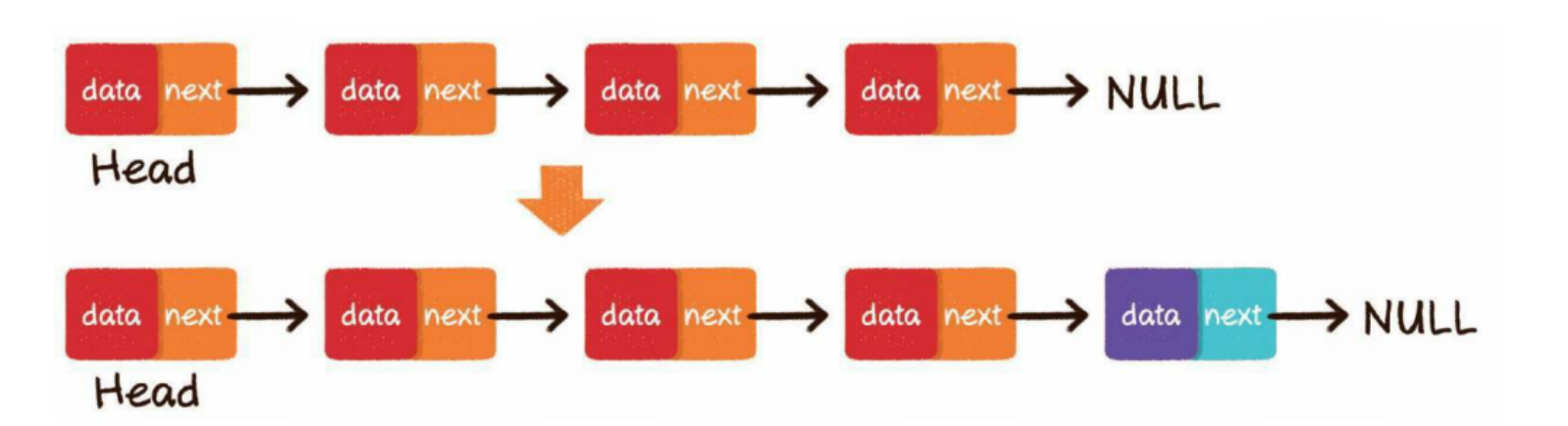
头部插入
第1步,把新节点的next指针指向原先的头节点
第2步,把新节点变为链表的头节点
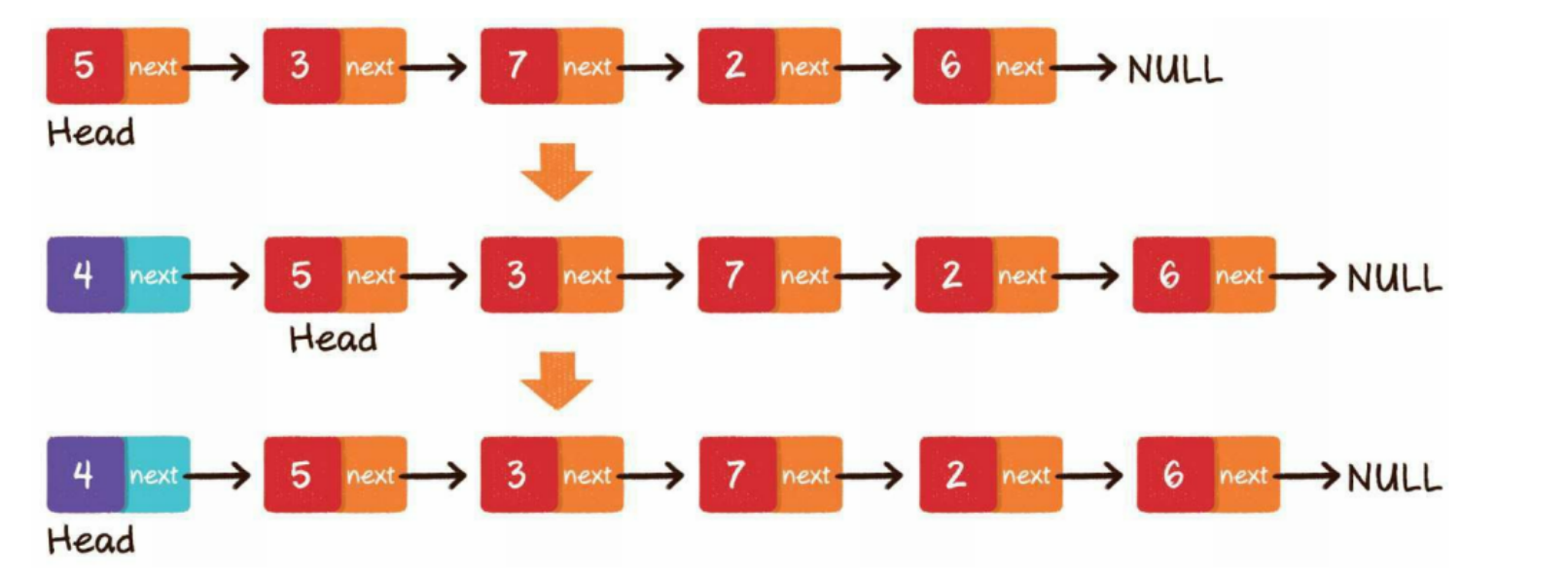
中间插入
第1步,新节点的next指针,指向插入位置的节点
第2步,插入位置前置节点的next指针,指向新节点
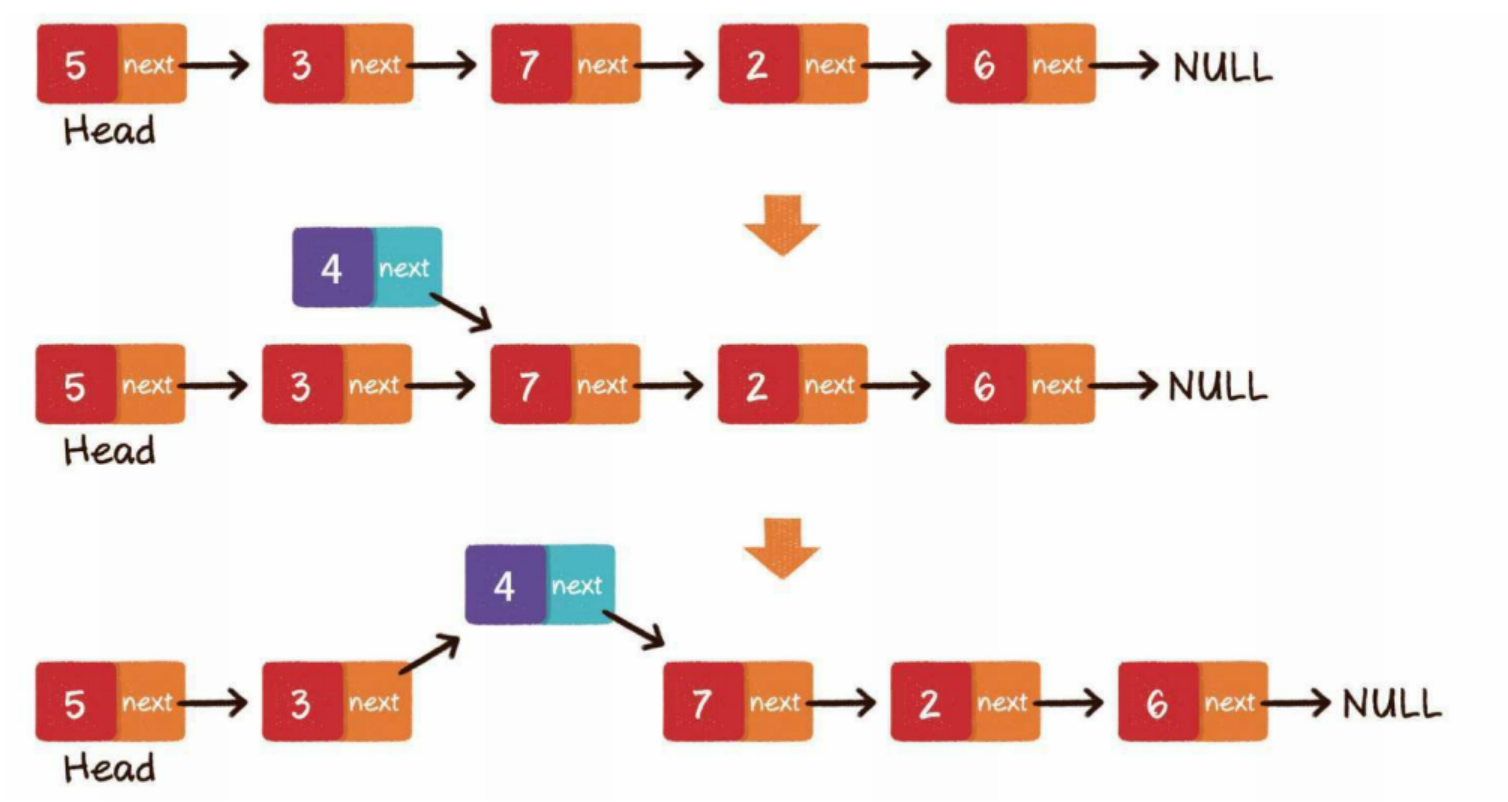
只要内存空间允许,能够插入链表的元素是无限的,不需要像数组那样考虑扩容的问题
删除节点
尾部删除
把倒数第2个节点的next指针指向空即可

头部删除
把链表的头节点设为原先头节点的next指针即可
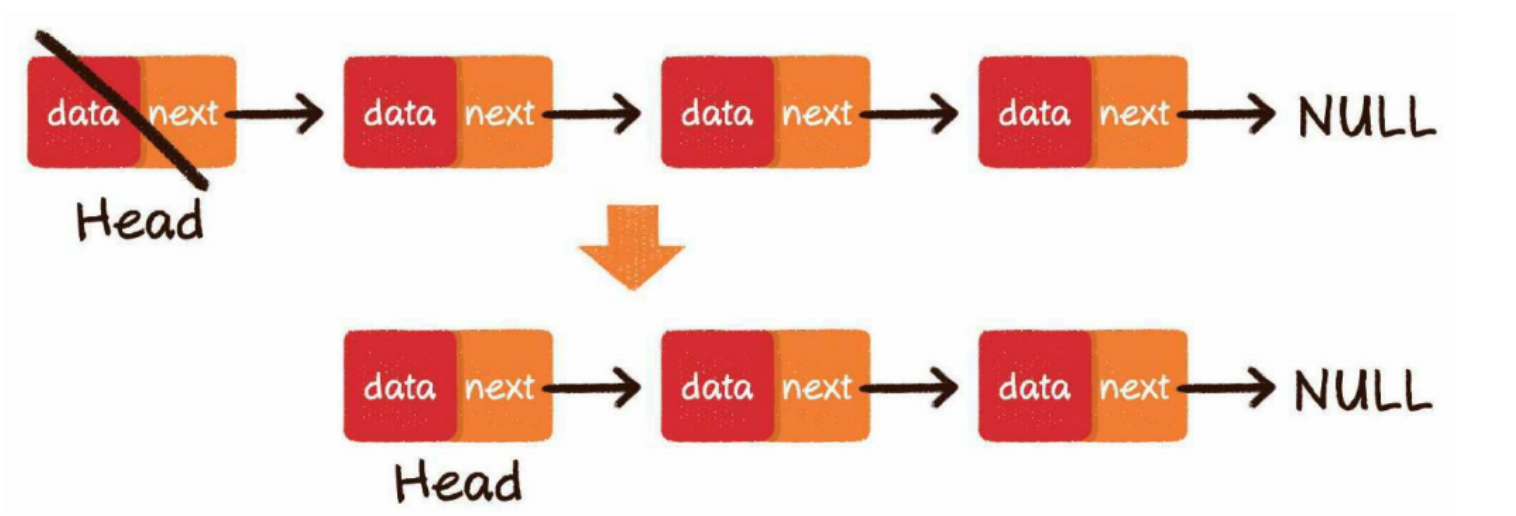
中间删除
把要删除节点的前置节点的next指针,指向要删除元素的下一个节点即可

优缺点
优势: 插入、删除、更新效率高。省空间
劣势:查询效率较低,不能随机访问
应用
链表的应用也非常广泛,比如树、图、Redis的列表、LRU算法实现、消息队列等
数组与链表的对比
数据结构没有绝对的好与坏,数组和链表各有千秋。
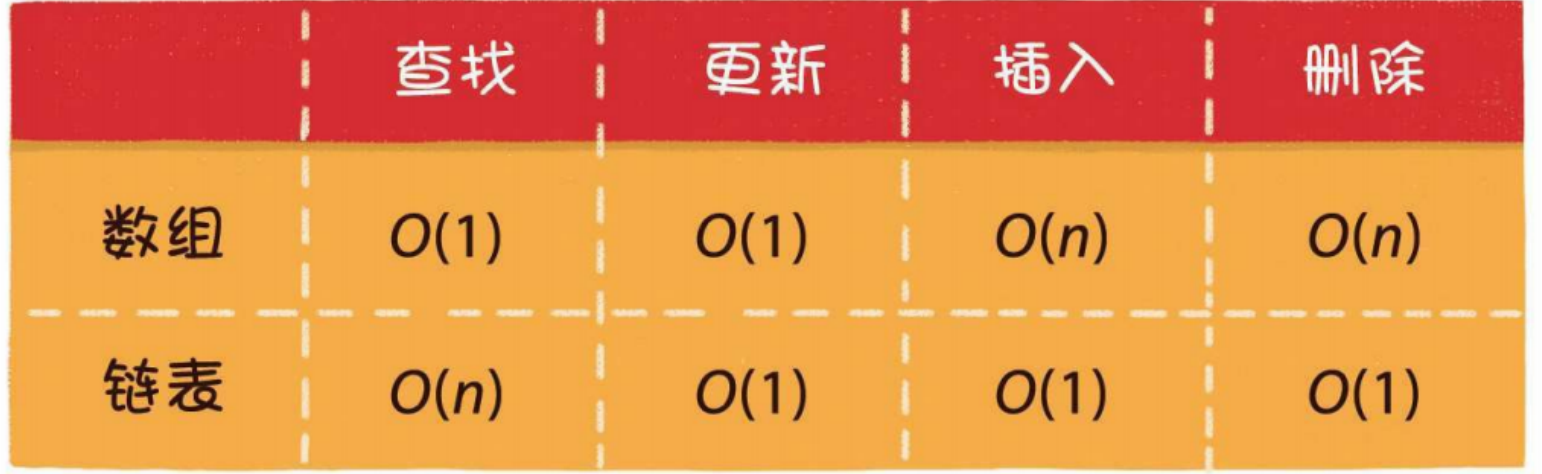
数组的优势在于能够快速定位元素,对于读操作多、写操作少的场景来说,用数组更合适一些
链表的优势在于能够灵活地进行插入和删除操作,如果需要在尾部频繁插入、删除元素,用链表更合适一些
数组和链表是线性数据存储的物理存储结构:即顺序存储和链式存储。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号