A Simple Framework for Contrastive Learning of Visual Representations 阅读笔记
Motivation
作者们构建了一种用于视觉表示的对比学习简单框架 SimCLR,它不仅优于此前的所有工作,也优于最新的对比自监督学习算法,
而且结构更加简单:这个结构既不需要专门的架构,也不需要特殊的存储库。
· 由于采用了对比学习,这个框架可以作为很多视觉相关的任务的预训练模型,可以在少量标注样本的情况下,拿到比较好的结果。
Discovery
在这篇论文中,研究者发现:
· 多个数据增强方法组合对于对比预测任务产生有效表示非常重要。
· 与监督学习相比,数据增强对于无监督学习更加有用;
· 在表示和对比损失之间引入一个可学习的非线性变换可以大幅提高模型学到的表示的质量;
· 与监督学习相比,对比学习得益于更大的批量和更多的训练步骤。
基于这些发现,他们在 ImageNet数据集上实现了一种新的自监督学习方法—SimCLR。
Model
SimCLR 通过隐空间中的对比损失来最大化同一数据示例的不同增强视图之间的一致性,从而学习表示形式。具体说来,这一框架包含四个主要部分:
· 随机数据增强模块,可随机转换任何给定的数据示例,从而产生同一示例的两个相关视图,分别表示为 x˜i 和 x˜j,我们将其视为正对;
· 一个基本的神经网络编码器 f(·),从增强数据中提取表示向量;
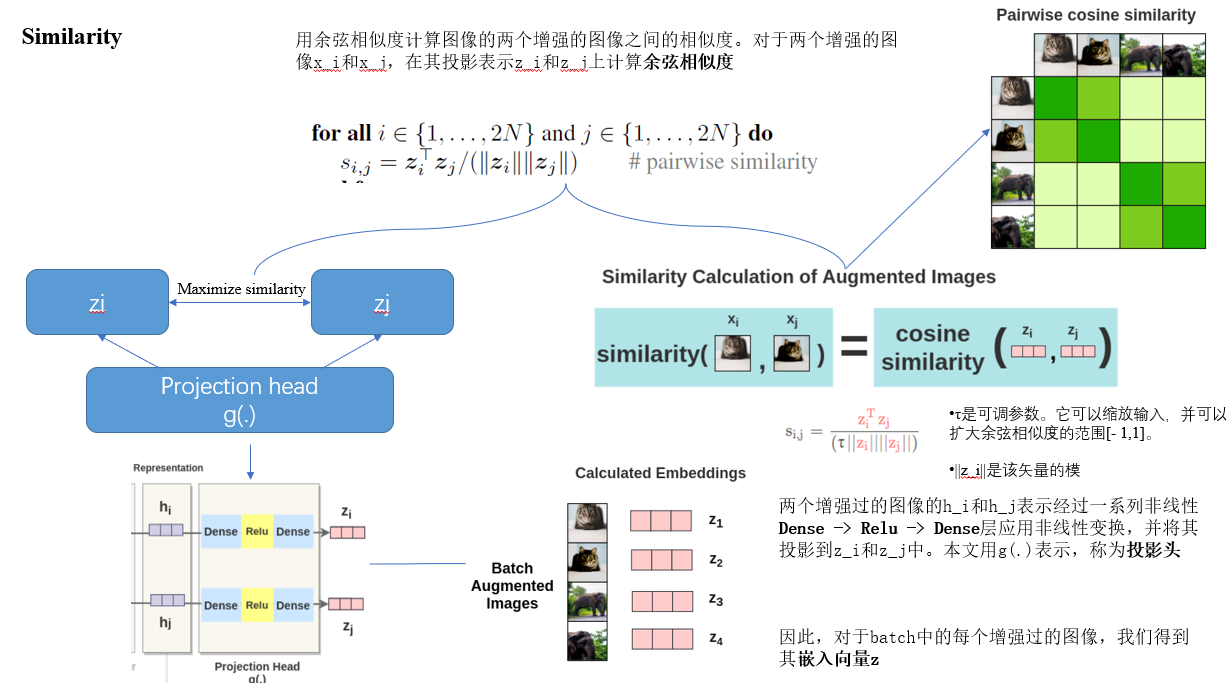
· 一个小的神经网络投射头(projection head)g(·),将表示映射到对比损失的空间;
· 为对比预测任务定义的对比损失函数。
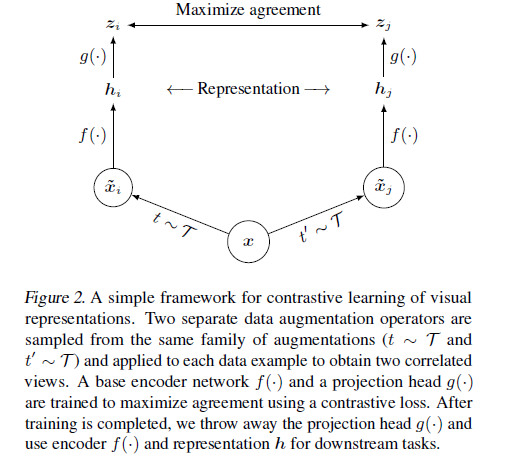
下面让我们详细的理解一下simCLR算法的核心思想
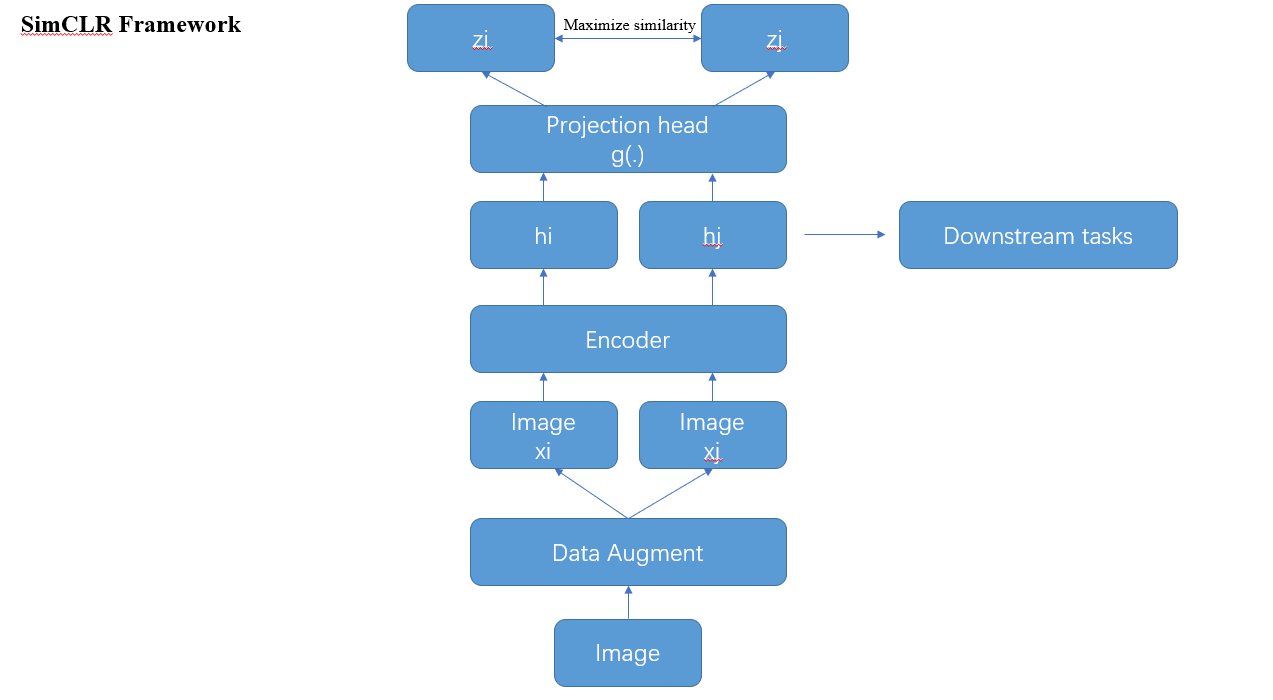
首先是对比学习的基本概念,其实很简单,这是一种试图教会机器区分相似和不同的东西

可以简单总结为:
· 随机抽取一个小批量
· 给每个例子绘制两个独立的增强函数
· 使用两种增强机制,为每个示例生成两个互相关联的视图
· 让相关视图互相吸引,同时排斥其他示例

其算法可以具体表示为:

非常简单。取一幅图像,对其进行随机变换,得到一对增广图像x_i和x_j。该对中的每个图像都通过编码器以获得图像的表示。然后用一个非线性全连通层来获得图像表示z,其任务是最大化相同图像的z_i和z_j两种表征之间的相似性
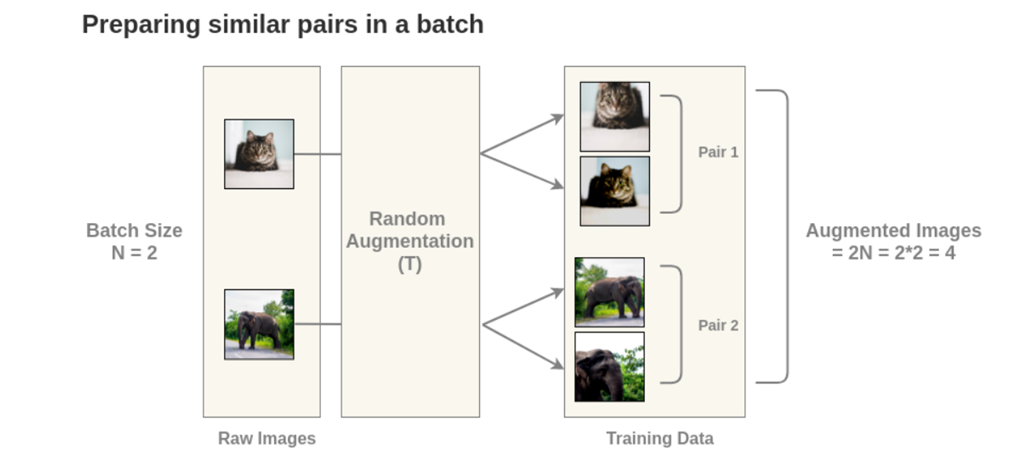
首先是Data Augment这步

这个是效果,以N=2为例,则会产生2N = 4张经过数据增加的图。(文中作者使用N = 8192/batch)
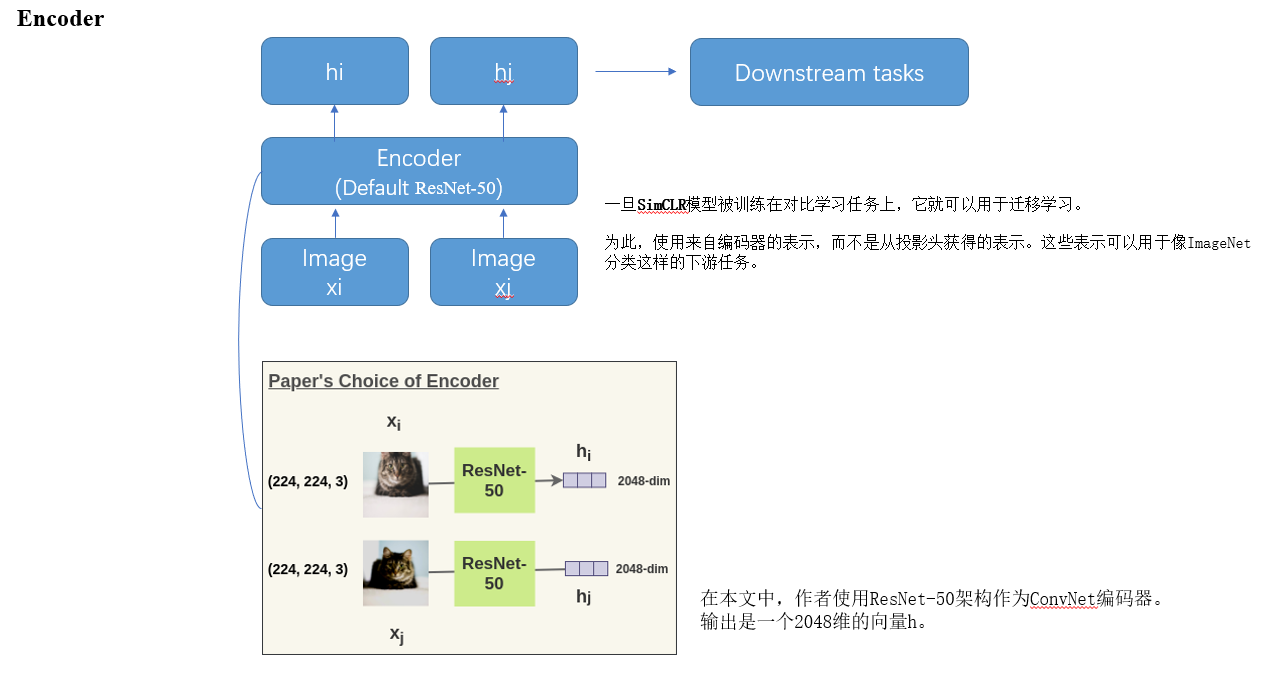
然后是编码部分
下面是关于Similarity部分,也就是计算两个图像特征之间的相似度
下面是SimCLR的对比损失函数
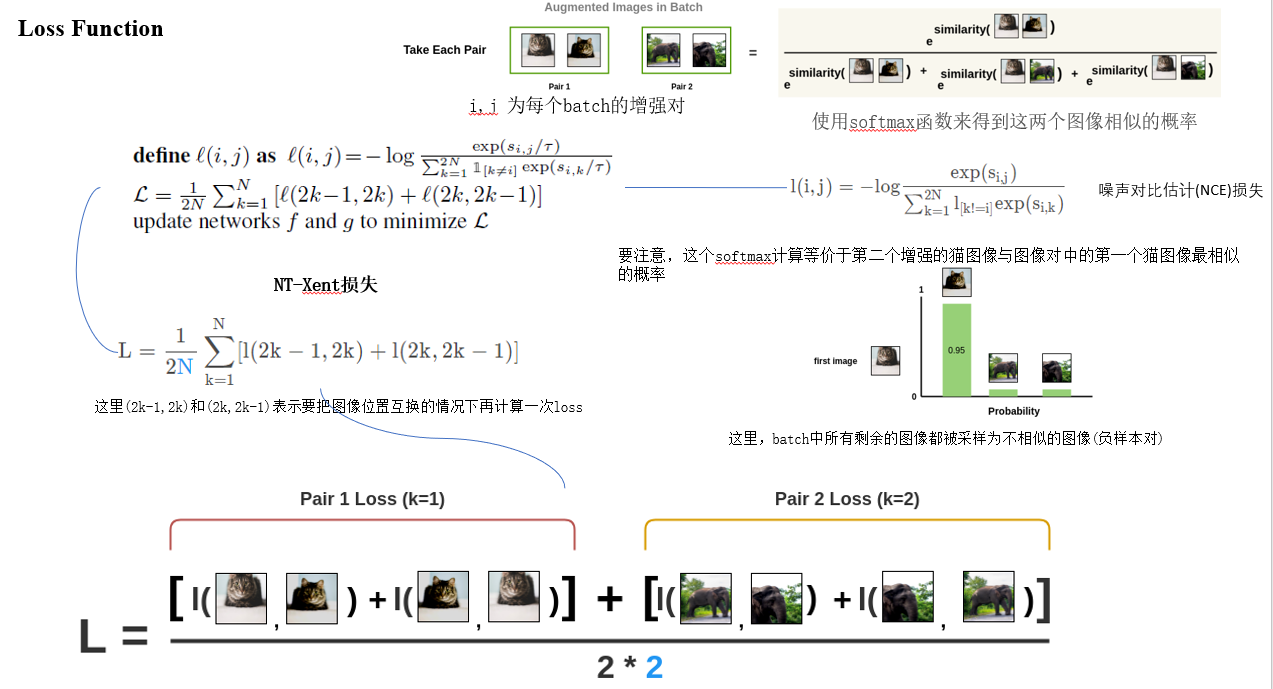
分析结束
最后是与其他方式的比较
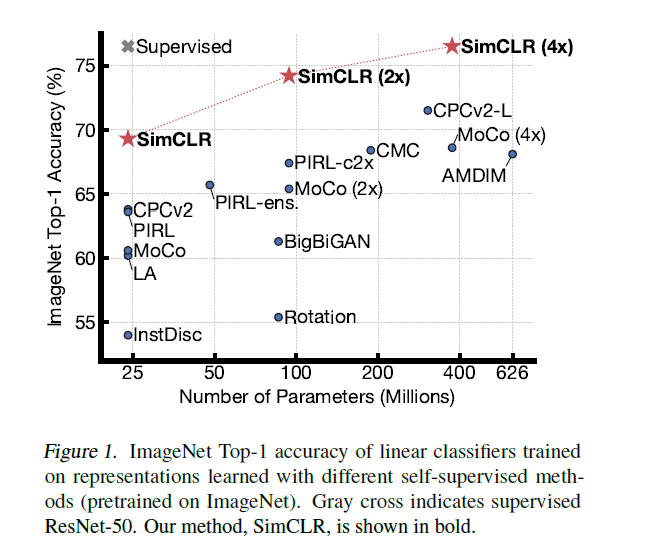
在线性评估方面,SimCLR 实现了 76.5% 的 top-1 准确率,比之前的 SOTA 提升了 7%。在仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 实现了 85.8% 的 top-5 准确率,比之前的 SOTA 方法提升了 10%。在 12 个其他自然图像分类数据集上进行微调时,SimCLR 在 10 个数据集上表现出了与强监督学习基线相当或更好的性能。
Code
Tensorflow实现:https://github.com/googl-research/simclr
Pytorch实现:https://github.com/leftthomas/SimCLR
Reference
https://blog.csdn.net/u011984148/article/details/106233313/
最后,都看到这了,姑且给一个赞,推荐,关注一键三连呗~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号