
---恢复内容开始---
很多人在找工作时,对薪资要求不知道怎么说,今天我们爬取一下招聘网站上的一个岗位,看看平均薪资是多少.
这里举例:地区:上海;岗位:数据分析师;工作年限:1-3年;爬取网站:前程无忧.
1.首先导入需要的包.
1 from bs4 import BeautifulSoup 2 import requests 3 import time 4 import pandas as pd
2.设置一下hearders和cookie
这两个的作用是模拟浏览器访问.很多网站是有反爬机制的,如果不设置,就爬取不到内容.
1 user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36' 2 cookie = 'lastCity=101020100; _uab_collina=156721816571945766335399; _bl_uid=nvjqLzabyLRxaX9hy6vmj3qyaORh; __c=1567341011; __g=-; __zp_stoken__=613fLW1944DKo8okH8iDIBam5fmeR38LsVQqpi6F0FDhJOfSlLtTunuH262safSf14b8VChVheFTHWfBE%2BCbPq%2FxGA%3D%3D; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1567218166,1567341011,1567342165; __l=l=%2Fwww.zhipin.com%2F&r=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DXOm3PDn-siBcPplVvyeigrHY63A2pN3_BADmd-juw4EnT6BpkUEeDSc7XoWKUhaf%26wd%3D%26eqid%3Df9bf3433001fa534000000045d6bb9cc&friend_source=0&friend_source=0; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1567344123; __a=93439332.1567218166.1567218166.1567341011.18.2.12.18' 3 headers={"User-Agent":user_agent,"Cookie":cookie}
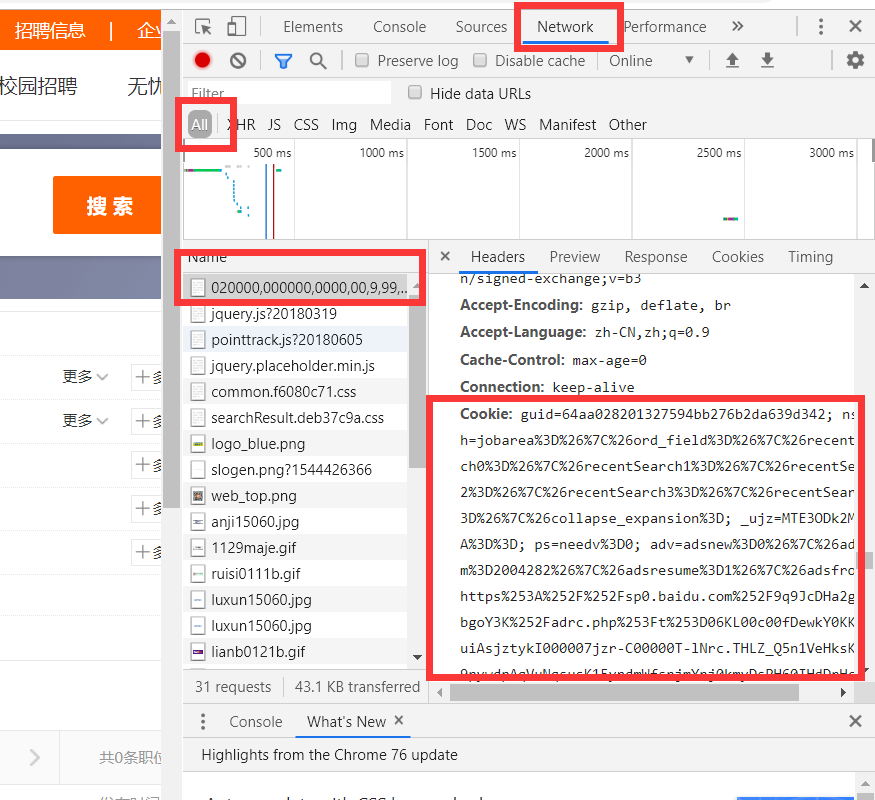
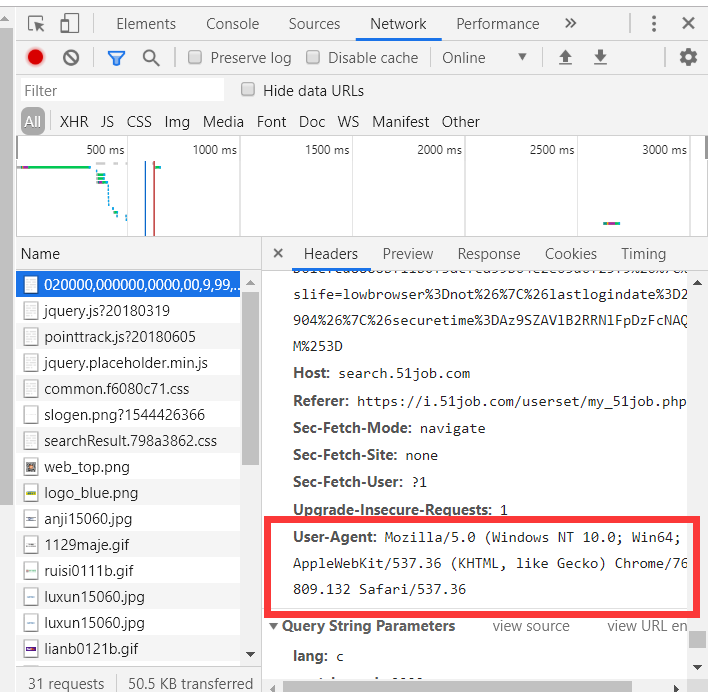
hearders和cookie的获取方法: 谷歌浏览器→F12→F5→看图中红框标出的部分,分别将Cookie和User-Agent复制粘贴.
3.网站内容爬取和解析
主要思想:现将html页面内容怕取下来,再根据页面标签提取想要的信息,最后转化为DataFrame格式
1 def get_info(url): 2 web_data = requests.get(url,headers = headers) 3 web_data.encoding = web_data.apparent_encoding 4 soup = BeautifulSoup(web_data.text,'html.parser') 5 info = soup.find('div',attrs={'id':'resultList'}) 6 info1 = info.find_all('div',attrs={'class':'el'}) 7 info1.pop(0) 8 9 result_all = [] 10 for i in info1: 11 result = [] 12 job_title = i.find('span').find('a').text.strip() 13 company = i.find('span',attrs = {'class':'t2'}).text 14 location = i.find('span',attrs = {'class':'t3'}).text 15 salary = i.find('span',attrs = {'class':'t4'}).text 16 date = i.find('span',attrs = {'class':'t5'}).text 17 18 result.append(job_title) 19 result.append(company) 20 result.append(location) 21 result.append(salary) 22 result.append(date) 23 24 result_all.append(result) 25 26 df = pd.DataFrame(result_all,columns = ['job_title','company','location','salary','date']) 27 return df
4.循环爬取所有页面
因为职位信息有好多页,要都怕下来,观察一下URL,看下第二页和第一页的变化.这里的变化就是我下面用{}替代的部分,第几页这里就会显示几.
1 #字符串过长 用(),每一行字符串都用''' '''引起。 2 df_all = pd.DataFrame() 3 urls = [('''https://search.51job.com/list/020000,000000,0000,00,9,06%252C07,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259''' 4 '''E%2590,2,{}.html?lang=c&postchannel=0000&workyear=02&cotype=99°reefrom=99&jobterm=99&companysize=0''' 5 '''2&ord_field=0&dibiaoid=0&line=&welfare=''').format(str(i)) for i in range(1,21)]#1-3年, 6 for url in urls: 7 df = get_info(url) 8 df_all = pd.concat([df_all,df]).reset_index(drop=True)
5.结果
看下爬取结果的前五行

6.数据处理
1)将salary列规整一下,因为里面有空值,将空值标记为''无效'';有0.8-1.2万/月,10-15千/月,10-15万/年这些不统一的单位,将他们同意变为10-15千/月这种形式,便于统计.
1 def Convert_unit_thousand_yuan(salary): 2 if '年' in salary : 3 salary_new_1 = round(float(salary.split('万')[0].split('-')[0])/12*10,1) 4 salary_new_2 = round(float(salary.split('万')[0].split('-')[1])/12*10,1) 5 salary_new = str(salary_new_1) +'-'+str(salary_new_2) 6 elif(('千'in salary) or('万'in salary) ==True) : 7 result1 = '千' in salary 8 result2 = '万' in salary 9 if result1==True: 10 salary_new = salary.split('千')[0] 11 if result2==True: 12 salary_new_1 = float(salary.split('万')[0].split('-')[0])*10 13 salary_new_2 = float(salary.split('万')[0].split('-')[1])*10 14 salary_new = str(salary_new_1) +'-'+str(salary_new_2) 15 else: 16 salary_new = '无效' 17 return salary_new
1 #新增一列salary_new 2 df_all['salary_new']=df_all.apply(lambda x:Convert_unit_thousand_yuan(x['salary']),axis=1)
1 #剔除无效的行 2 df_all_1 = df_all[df_all['salary_new'] !='无效']
2)对薪水的范围重新归类:先求出每家给出薪水的中位数,在对中位数归类范围.
1 def salary_mean(salary_new): 2 salary_new_1 = float(salary_new.split('-')[0]) 3 salary_new_2 = float(salary_new.split('-')[1]) 4 salary_new_3 = int((salary_new_1+salary_new_2)/2) 5 return salary_new_3
1 df_all_1['salary_new_mean']=df_all_1.apply(lambda x:salary_mean(x['salary_new']),axis=1)
1 def salary_dis(salary_new_mean): 2 if 0<salary_new_mean<=6: 3 salary_dis_1 = '0-6k' 4 elif 7<=salary_new_mean<=9: 5 salary_dis_1 = '7-9k' 6 elif 10<=salary_new_mean<=14: 7 salary_dis_1 = '10-14k' 8 elif 15<=salary_new_mean<=19: 9 salary_dis_1 = '15-19k' 10 elif 20<=salary_new_mean<=24: 11 salary_dis_1 = '20-24k' 12 else: 13 salary_dis_1 = '25k以上' 14 return salary_dis_1
1 df_all_1['salary_dis']=df_all_1.apply(lambda x:salary_dis(x['salary_new_mean']),axis=1) 2 df_all_1.head()
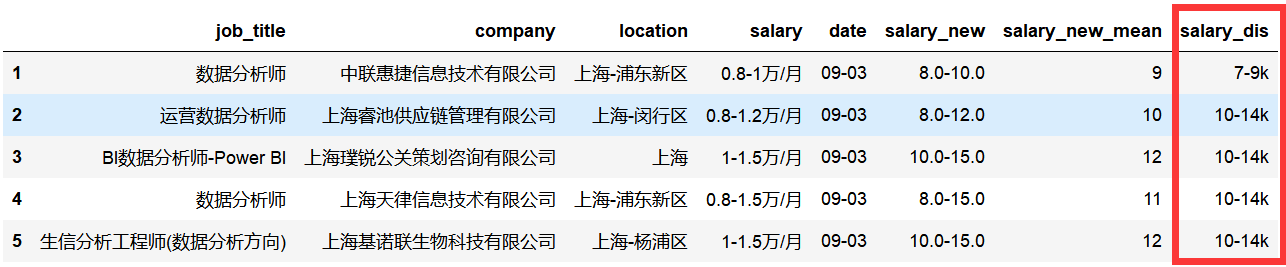
3)结果:salary_dis列就是重新添加的列
4)统计
看下薪水的分布:大部分薪水都是在10-14k之间的.
1 df_all_1.groupby('salary_dis')['job_title'].count()

对各家公司的中位值薪水做一个统计:平均薪水11k左右.
1 df_all_1['salary_new_mean'].describe()

结论:
工作1-3年想在上海找数据分析师工作的小伙伴,平均薪资是可以达到11k的.
---恢复内容结束---
