

【正则】分组/捕获-总
分组/捕获
魔芋:
01,小括号(又称为圆括号)会产生子表达式(又称为分组,子串)。可以在正则中\1,\2来引用子表达式匹配的文本值。
这些子表达式会被临时缓冲区缓存起来。所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。
缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 '\n' 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。如\1,\2。
n又称为分组号。
好处,可以不用重复查找某个匹配项。
这种方式,又称为反向引用。
这种又称为捕获分组。
02,用(?:n)可以消除小括号产生子表达式的效果。
03,可以使用非捕获元字符 '?:'、'?=' 或 '?!' 来重写捕获,忽略对相关匹配的保存。
叫做:预测先行的匹配。
又叫做:非捕获组(non-capturing)
|
选择,匹配的是该符号左边的子表达式或右边的子表达式。
捕获
(exp)
用小圆括号进行分组,如日期中年月日的分组:/(\d{5})-(\d{1,2})-(\d{1,2})/
每个分组将产生分组号,从第一个括号开始,可以使用\n的形式在正则中使用分组号。
如匹配成对出现的HTML标签,可以写成:/<(\w+)><\/\1>/。
可以记住和这个组合相匹配的字符串以供此后的引用使用。
(?:exp)
匹配exp正则,但不产生分组号,不记忆与该组匹配的字符
(?<name>exp)
匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp)
零宽断言:
exp1(?=exp2)
前瞻断言,匹配exp1,但后面必须是exp2。又称为先行断言。零宽度正预测先行断言
如匹配名字叫xianlie,但不姓zhao的人:/zhao(?=xianlie)/
exp1(?!=exp2)
后瞻断言,匹配exp1,但后面不能是exp2。又称为负向先行断言。先行否定断言。
如匹配姓zhao,但名字不叫xianlie的人:/zhao(?!xianlie)/
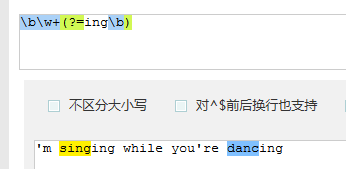
比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<exp)
来自ES7。
后行断言:与”先行断言”相反, x只有在y后面才匹配,必须写成/(?<=y)x/。解释:找一个x,那个x的前面要有y。
又叫做:零宽度正回顾后发断言
比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
(?<!exp)
来自ES7。
后行否定断言: 与”先行否定断言“相反,x只有不在y后面才匹配,必须写成/(?<!y)x/。 解释:找一个x,那个x的前面没有y。
可以看出,后行断言先匹配/(?<=y)x/的x,然后再回到左边,匹配y的部分,即先右后左”的执行顺序。
又叫做:零宽度负预测先行断言
例如:\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b匹配不包含连续字符串abc的单词。
(?<![a-z])\d{7}匹配前面不是小写字母的七位数字。
\n
和第n个分组第一次匹配的字符相匹配,组是圆括号的子表达式(也有可能是嵌套的),组索引是从左到右的左括号数,“(?:形式的分组不编码
?=n
匹配任何其后紧接指定字符串 n 的字符串。
?!n
匹配任何其后没有紧接指定字符串 n 的字符串。
(魔芋:就是一个附加条件,匹配带有什么字符串的才能匹配)
?!就是不能带有什么字符串的。
什么是断言?
断言用来声明一个应该为真的事实。
名词解释:
前瞻 = 先行断言
(?=) 正向前瞻 = 正向零宽先行断言
(?!) 反向前瞻 = 负向前瞻 = 负向零宽先行断言
后顾 = 后发断言
(?<=) 正向后顾 = 正向零宽后发断言
(?<!) 反向后顾 = 负向后顾 = 负向零宽后发断言
**


 浙公网安备 33010602011771号
浙公网安备 33010602011771号