网络流入门
【模板】网络最大流
什么是网络流?
对于一张有向图\(G(V,E)\)(网络),包含\(N\)个点,\(M\)条边和源点\(S\),汇点\(T\)。
其中的每条边\((u,v)\)都有一个容量\(c(u,v)\)。这些容量\(c\)构建了一张容量网络,边在网络中也称作弧。
如何理解这些概念?
可以把它具体化为一个城市的水网,每根水管就是边,水管的容量就是容量,当然,它不能传输大于容量的水,也就是流量不可能大于容量,自来水厂就是源点,你家就是汇点。源点的水可以理解为无限,但是运到你家的水是有限的。网络最大流就是让自来水厂,即源点用最大的功率往外运水,求此时你家也就是汇点收到的水。
为什么会出现不同的情况呢?因为每条边的容量是有限的,对应的,源点之外的点如果有多条出路,需要考虑把自己所能接收到的水以最优的方案分配到各条出路,使得最终汇点收到的水最多。
对于这样一个水网,即网络流模型,有三个性质:
1.容量限制。每条边的流量(实际流过的水)不大于该边的容量。设流量为\(f(x,y)\),那么则有\(f(x,y)\leq c(x,y)\)
2.反对称性。正向边的流量等于反向边的流量。即\(f(x,y)=-f(y,x)\)。后面再细说。
3.流守恒。对于\(G\)中任意一个节点\(u\),如果它不是源点或汇点,那么它到相邻节点的流量和为0。也就是流入多少水就会流出多少水。即\(\forall u\in V-\{s,t\},\sum_{w\in V}f(u,w)=0\)
这里的\(f\)函数即为流函数。如果我们能够构造合法的\(f\)函数使其满足以上三个性质,那这就是一个可行流。其中最大的可行流就是我们要求的最大流。
残量网络:即容量网络减去流函数,\(c_f(u,v)=c(u,v)-f(u,v)\)。其实就是在\((u,v)\)这条容量为\(c(u,v)\)的边上,流过了\(f(u,v)\)的水,还剩的残量*\(c_f(u,v)\)就是用容量减去流量。
接下来就是算法部分咯
\(Edmonds-Karp\)增广路算法
即\(EK\)算法。
所谓增广路,就是从\(S\)到\(T\)找到的一条路径上残量都大于0的一条路径。
暴力的\(EK\)算法选择了用\(BFS\)来寻找增广路。也就是让一股流从\(S\)出发,一路寻找残量大于0的弧前进,直到到达\(T\)。这样网络的流量就会增大。直到找不到一条增广路为止。
我们在搜索的时候,可以记录路径上最小的残量,这就是我们可以让网络的流量增大的值\(dis\)。路径上所有的正向边都要减去\(dis\),反向边都要加上\(dis\)。正向边要减比较容易理解,但是反向边加,就是因为上面的反对称性。
为什么这么做?
一条边可能在多条增广路上,为了找到所有增广路使得全局最优,我们需要允许反悔。也就是如果当前正向边已经被包含在了某条已经找到的增广路中,但是如果把它包含在另一条增广路中,会使得网络流量增加的更多,那就肯定要选择更优的。
反向边的初始权值为0。方向与原弧(边)相反。
什么是反悔?假设\(u\)到\(v\)原本的正边权是\(dis\),被增广之后正边权就更改为\(0\),反边权变为\(dis\)。如果还要反过来回去的话便可以通过反边权回去。或者说是通过反向加压把一部分水可以压回去(?)
如果成功反悔,部分流量又会从反边权回到正边权,达到分流取得最优的目的。所以在\(EK\)算法中,我们要遍历所有正向边和反向边,增广最短的一条。
如何方便的在正向和反向之间跳转?我们可以把一对边存储在\((i,i+1)\)的位置,\(i\)从1开始。比如\((1,2),(3,4)\)等。这样对于任意一条边的编号\(p\),它的另一条边就是\(p\ xor \ 1\)。
对于在路程中经过的点\(v\),为了便于更新正反边的值,我们记录一个\(pre[v]=\)当前遍历边的编号。每次增广之后,我们就可以对边权进行更新。
inline void ud()
{
int u=t;//从汇点出发,走反向边向源点出发
while(u!=s)
{
int i=pre[u];//被增广的边
val[i]-=dis[t];
val[i^1]+=dis[t];//正减反加
u=to[i^1];//走反向边
}
ans+=dis[t];//汇点被增大的流量累加到答案中
}
但是\(EK\)算法是比较慢的(\(O(VE^2)\),能处理\(1e3-1e4\)的数据),我们需要判重边来过掉这道板子题...
详细看看代码吧,主要是一点点细节的处理。
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int N=2020;
const int M=20000;
const int INF=0x3f3f3f3f;
int head[M],to[M],nxt[M],cnt=1;
ll val[M];
void add(int u,int v,ll w)
{
cnt++;
to[cnt]=v,nxt[cnt]=head[u],val[cnt]=w,head[u]=cnt;
cnt++;
to[cnt]=u,nxt[cnt]=head[v],val[cnt]=0,head[v]=cnt;
}
int n,m,s,t;
int f[N][N],vis[N],pre[N];
ll dis[N];
inline bool bfs()
{
memset(vis,0,sizeof vis);
queue<int> q;
vis[s]=1,dis[s]=INF;
q.push(s);
while(!q.empty())
{
int u=q.front();
q.pop();
for(int i=head[u];i;i=nxt[i])
{
int v=to[i];
if((val[i]==0)||(vis[v]==1))continue;
dis[v]=min(dis[u],val[i]);
pre[v]=i,q.push(v),vis[v]=1;
if(v==t)return 1;
}
}
return 0;
}
ll ans;
inline void ud()
{
int u=t;
while(u!=s)
{
int i=pre[u];
val[i]-=dis[t];
val[i^1]+=dis[t];
u=to[i^1];
}
ans+=dis[t];
}
signed main()
{
scanf("%d%d%d%d",&n,&m,&s,&t);
for(int i=1;i<=m;i++)
{
int u,v;
ll w;
scanf("%d%d%lld",&u,&v,&w);
if(!f[u][v])
{
add(u,v,w);
f[u][v]=cnt;
}
else val[f[u][v]^1]+=w;
}
while(bfs()){ud();}
printf("%lld\n",ans);
return 0;
}
\(EK\)算法时间复杂度上界达到了\(O(VE^2)\),如果在完全图情况下,可以达到\(O(V^5)\)。它为什么这么慢?
让我们来看看\(EK\)的运行:
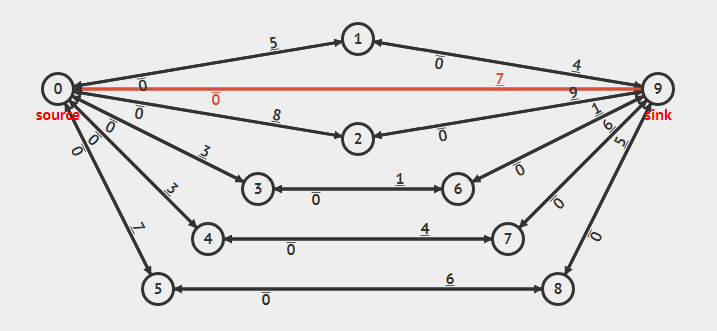
我们找到了一条\(s→t\)的增广路,所以我们去更新...再找到一条\(s→1→t\)的增广路...
不对啊,\(s→2→t\)也是一条增广路,但是要下一次搜索才能再增广到它,这样不是很浪费时间吗?
\(Dinic\)算法应运而生。
\(Dinic\)算法
\(Dinic\)算法是\(EK\)算法的替代品。
首先继承\(EK\)算法的优点:每次增广最短路,保留\(BFS\)。
然后引入分层图的概念。简单来说,一个点的层次\(d[x]\)就是到源点的最短路长度。满足\(d[y]=d[x]+1\)的边\((x,y)\)构成的图就是分层图。
比如在上图中,\(1,2,3,4,5\)都在同一层。
首先在残量网络(残量不为零的弧组成的网络)中用\(BFS\)求出节点的层次,构造分层图。
然后在分层图上用\(DFS\)进行增广。
我们可以发现,增广路之间是不会出现环的。否则一定能找到一种更优的选择。所以,只要在分层图上进行\(DFS\),那么一定不会搜到一个环。
而且,在分层图上的弧都在一条残量网络的最短路上,这也为我们进行\(DFS\)提供了很便利的条件。
而且。。在分层图上找最短路,反向边都去和梁非凡共进晚餐了。
所以,你只管开车,办法由老爹来想,你只管\(DFS\)就完事了。
我们来分析一下时间复杂度吧!
首先寻找最短路的\(BFS\)很好说。每次判断了下一个层次是否有增广路,上界也就\(O(V)\)
而\(DFS\)的复杂度不用说,我这种蒟蒻都知道是\(O(E)\)
所以它的时间复杂度是\(O(VE)\)!比\(EK\)快太多了。
我们\(Dinic\)真的太厉害啦!
然而是假的。
不会真的有人觉得\(O(E)\)就能找到一个层次的所有增广路吧,不会吧不会吧?
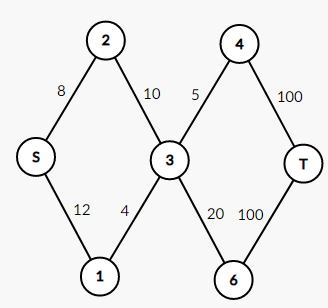
我们增广了\(S→2→3→6→T\)这条路之后,难道就不会经过路径上的点了吗?
当然不是。我们还要增广\(S→1→3→4→T\)。
所以\(vis\)标记是肯定不能打的,这个\(DFS\)是指数级的,\(Dinic\)就是个垃圾算法,大家散了吧。。
然而还是假的。


对于一个节点\(x\),当它在\(DFS\)时如果已经走到了第\(i\)条边,前\(i-1\)条边一定已经被塞满,所以下次再遍历经过\(x\)的边时,就没有必要遍历前\(i-1\)条边了。所以每次\(DFS\)都记录一个\(cur[u]\)初始为\(head[u]\),并且在遍历到边\(i\)的时候吧\(cur[u]\)更新为\(i\)。并且遍历边都从\(cur[u]\)而不是\(head[u]\)开始。
再来一个优化:

如果在同一轮\(DFS\)中,我们发现从\(u\)到\(v\)无法增广,那这个\(v\)就是无用点,我们把它的层数改为极大值或者极小值,目的在于不会再被遍历。
加上了这两个优化,\(Dinic\)就从一个垃圾的指数级搜索算法变成了一个\(O(V^2E)\),比\(EK\)降低了一个\(O(V)\)左右的时间。而且它在二分图匹配问题中上界只有\(O(\sqrt V*E)\)。
\(CODE\)
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int INF=0x3f3f3f3f;
const int N=2020;
const int M=20020;
int head[M],to[M],val[M],nxt[M],cnt=1;
void add(int u,int v,int w)
{
cnt++;
nxt[cnt]=head[u];
val[cnt]=w;
to[cnt]=v;
head[u]=cnt;
}
int n,m,s,t;
int dis[N],cur[M];
inline bool bfs()
{
//memset(dis,0x3f,sizeof dis);
for(int i=1;i<=n;i++)
dis[i]=INF;
queue<int> q;
q.push(s);
dis[s]=0,cur[s]=head[s];
while(!q.empty())
{
int u=q.front();
q.pop();
for(int i=head[u];i;i=nxt[i])
{
int v=to[i];
if(val[i]>0&&dis[v]==INF)
{
q.push(v);
cur[v]=head[v];//当前弧优化
dis[v]=dis[u]+1;
if(v==t)return 1;
}
}
}
return 0;
}
inline int dfs(int u,int sum)
{
if(u==t)return sum;
int k,res=0;
for(int i=cur[u];i&∑i=nxt[i])
{
cur[u]=i;
int v=to[i];
if(val[i]>0&&dis[v]==dis[u]+1)//只遍历分层图
{
k=dfs(v,min(sum,val[i]));
if(k==0)dis[v]=INF;
val[i]-=k;
val[i^1]+=k;
res+=k;
sum-=k;
}
}
return res;
}
signed main()
{
scanf("%lld%lld%lld%lld",&n,&m,&s,&t);
for(int i=1;i<=m;i++)
{
int u,v,w;
scanf("%lld%lld%lld",&u,&v,&w);
add(u,v,w);
add(v,u,0);
}
int res=0;
while(bfs()){res+=dfs(s,INF);}
printf("%lld\n",res);
return 0;
}
