浅谈AC自动机
文章发布于摸鱼世界,转载请注明出处
前置芝士
\(Trie\)树必备,\(KMP\)最好会,不然我可能讲不清楚emm
前言
首先,让我放一下洋屁
\(Aho-Corasick_automaton\),该算法在1975年产生于贝尔实验室,是著名的多模匹配算法。
我曾经也以为这玩意是和AC有什么关系,现在发现并没有
通过上面的介绍,我们可以知道,这是一种多模匹配算法。大家都知道,\(KMP\)是针对单个模式串进行匹配,而\(AC\)自动机则是一种对于多个模式串的匹配算法。
正文
放在开头。
虽然\(AC\)自动机结合了\(Trie\)树以及\(KMP\)的思想,但其在本质上还是属于一种DFA(有限确定状态自动机),对于每个状态,新加入一个字符之后(通过转移函数)又会转移到一个新的状态。只是在这个转移函数的实现上,我们通过前面讲的两种算法进行了实现而已。(其实KMP也可以用DFA的思想来理解,但是对这个算法本身的理解可能就不会那么深)
注:DFA什么的我也没有深入了解,有兴趣的可以百度一下 ::aru😓:
来初步了解一下算法流程。
先把模式串插入\(Trie\)树(和基本插入操作一模一样!)
在\(Trie\)上通过一次类似\(bfs\)的操作(结合kmp),建立\(AC\)自动机
按照题目要求修改模板 ::aru👏:
很清楚(确实很清楚)的发现,难点就在建立AC自动机上(废话)
实际上,这就是在\(Trie\)上建立一个失配数组,也就是:如果在当前节点失配了,我们最优的选择是跳到哪一个点,就跳到哪一个点,而不是一味的返回根节点,完成大量重复的匹配操作。
还是用举例的方法吧..
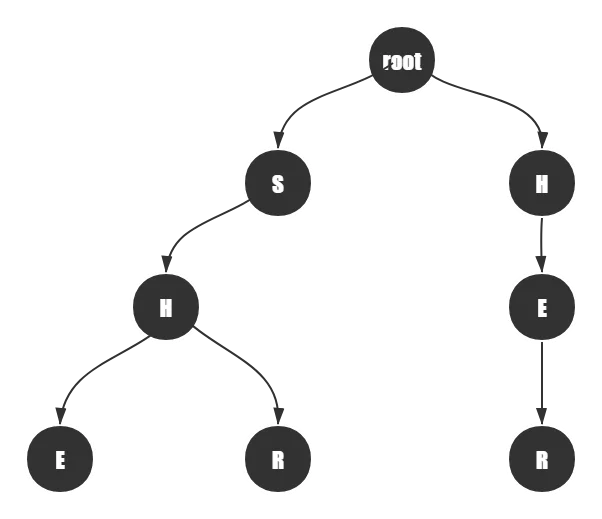
比如在这样一棵已经建立好的\(Trie\)树中,假设使用最暴力的做法,把一个文本串\(HES\)拿来匹配,会怎么做?
“我会暴力查询!”,直接从根节点出发,按照Trie树的顺序依次向下查询,经过\(H->E->不匹配R\)无法到达目标,返回根节点。
(这是最简单的情况,实际情况可能会失配多次,也就是会多次返回根节点)
而AC自动机中的\(KMP\)思想,就体现在对这一步的优化。它构造了一个“失配指针”,每次失配之后不再返回根节点,而是返回对应的失配指针指向的位置。
让我们来听一下dalao是怎么说的:沿着其父节点 的 失配指针,一直向上,直到找到拥有当前这个字母的子节点 的节点 的那个子节点
是不是超级复杂的
其实看起来很复杂,跟着一起画一画图就明白了。
首先,有个特殊的地方,根节点下面一层的结点要全部指向根节点,如图:
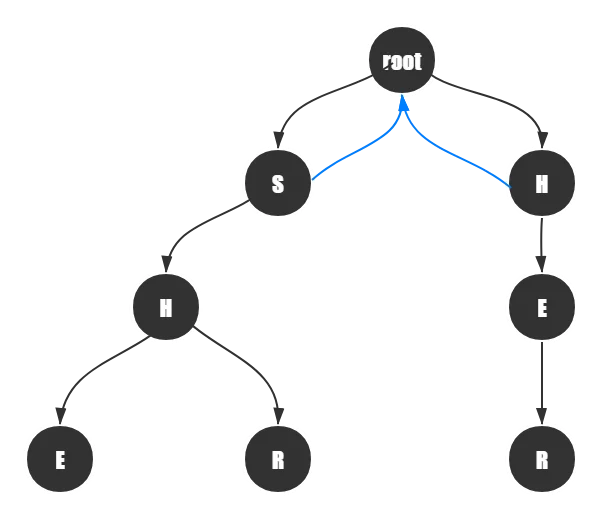
然后我们来看看对于第三层的\(H\)点应该如何指。
首先,沿着H的父节点的失配指针向上,到了根节点,发现根节点下有一个相同字母的结点,于是指向它:
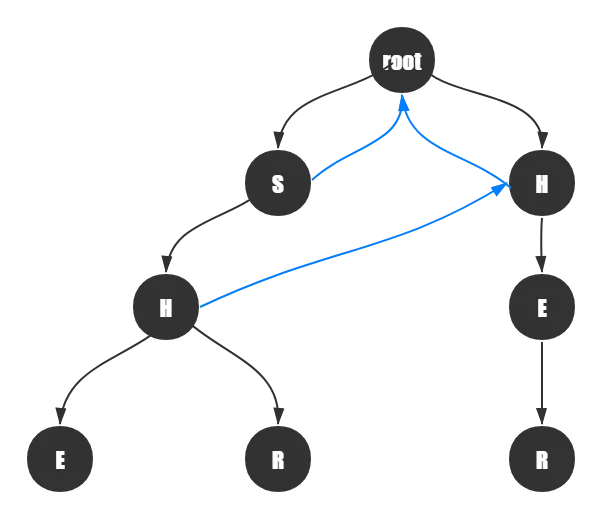
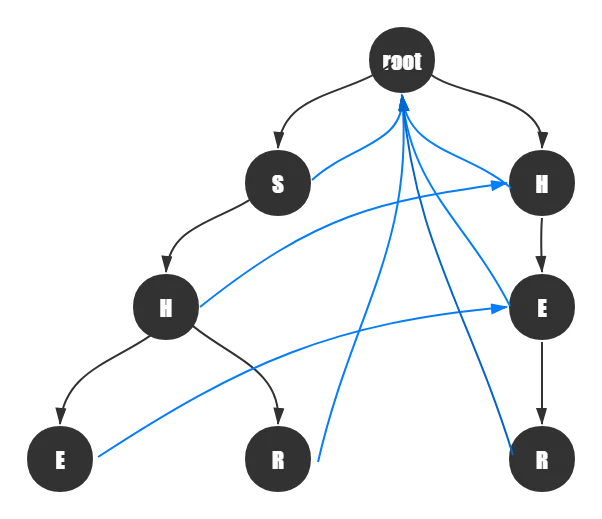
同理,其他结点也这样进行指向的操作。
全部完成之后的Trie树如下:
但在实现上肯定不能像上面描述的那样用while循环来找,我们应该怎么样做呢?
结合注释理解一下代码?
//c数组为正常的Trie树
//nxt数组即为构造的失配指针
//利用bfs的拓展操作,把每个点的失配指针都求出来
void getnext()
{
queue<int> q;
for(int i=0;i<26;i++)
if(c[0][i])q.push(c[0][i]);
//首先把根节点下的所有点插入队列
while(!q.empty())
{
int u=q.front();
q.pop();
for(int i=0;i<26;i++)
if(c[u][i])
//如果有当前这个子节点,让它的失配指针指向:(前方高能)
//(((父节点)的失配指针指向结点)的子节点中与当前字母相同的结点)
//如果实在不能理解就画一下图,看一下是否能够这样做,为什么是对的
{
nxt[c[u][i]]=c[nxt[u]][i];
q.push(c[u][i]);
}
//否则就是失配了,指向失配指针
else c[u][i]=c[nxt[u]][i];
}
return;
}
画图很重要我太菜了
查询的话就非常简单了。。只需要对模式串挨着暴力查找,只是把失配后返回根节点的操作修改为返回到失配指针。刷这类的题主要需要思考的就是标记操作如何利用,利用好了就很棒
小小的拓展
做完了AC自动机的模板题,我发现那只是简单版,还有加强。。
简单说说这两段"进化"是怎么完成的。
首先是加强版->题目传送门
在加强版中,它不再问你有多少个串出现过,而是问你出现次数最多的串的次数以及原串。
虽然不优化算法都能过掉(好像是),但是既然是加强版,我们总要从其中学到一些东西。
用简单版的思想,我们每次需要跳nxt边,但是每次跳了nxt边之后的匹配不一定对答案产生了贡献。
比如这样一个图(只演示了一条路径作为参考)
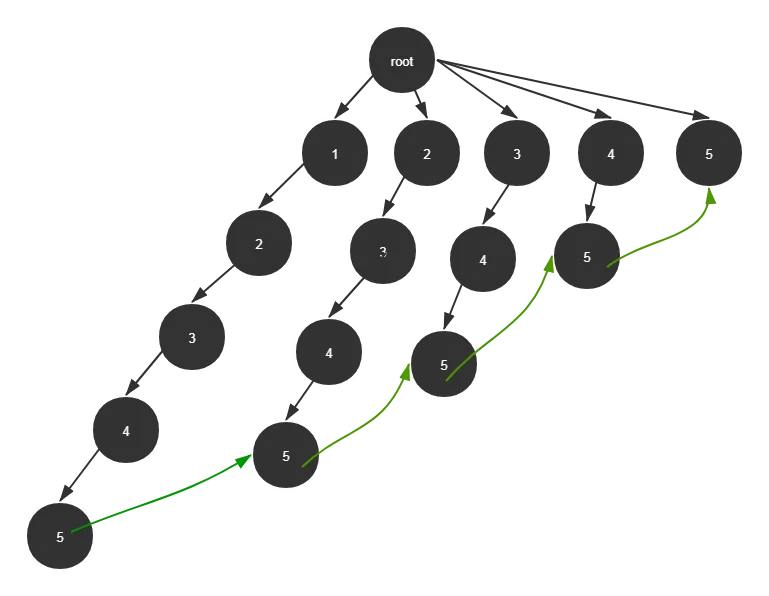
我们发现,绿色这一段中间经过的路程对答案是没有贡献的,因为最终还是会跳到最右侧去。所以我们可以像并查集的路径压缩一样,把这一段路径省去,节约\(O\)(玄学)的时间。
只需要在getnext中第一种情况里加上一句这样一句就可以了:
g[c[u][i]]=v[nxt[c[u][i]]]?nxt[c[u][i]]:g[nxt[c[u][i]]];
即对于c[u][i]这个点,我们检测它的失配指针是否对答案有贡献(v[nxt[c[u][i]]]),如果有,那答案就是原本的失配指针,否则就是gnxt[c[u][i]]。这样可以减少很多不必要的匹配。
最终统计答案的时候就不跳nxt边了,跳g边。(很显然)
小小的拓展2
是的没错,路的前方还是路
这次要求出每个模式串在文本串中出现的次数,并且模式串数量大大增多,达到了\(10^5\)。
我直接梅开二度
不知道大家是否还记得在\(KMP\)的学习中,我们将失配指针的方向倒置,成为了若干条由\(nxt[i]\)指向\(i\)的边,我们将其称作\(fail\)树。
回想在简单版的暴力中是如何实现查询的。每次暴力跳nxt边,直到当前点是某个点的末尾(被标记过),那么对应的计数加一。
记录下\(v[i]\)表示第\(i\)个模式串的结束位置。
假设母串为\(L\),当前匹配到了\(i\),并且当前结点编号为\(u\),我们就可以对这个\(u\)节点一路跳nxt指针,如果跳到了第\(i\)个模式串的末尾结点,那么对应的计数加一即可。把这个操作放到\(fail\)树中观察,就会发现只需要从根节点到\(u\)路径上的结点计数器全部加一,可以用到基本的树上差分来进行简化。
把树上差分的四个基本操作好好看看,就会发现只需要\(sum[]++\)就可以了。因为这一条路径上它们的LCA一定是根,根的计数不需要考虑,根也没有父节点了。。
所以具体实现起来就非常简单,只是在原串的基础上加了两个几行的代码而已。。
熬夜爆肝真的好累...
