

嵌入式相关知识点整理
因时间关系格式会比较乱,需要原Word文档的可通过下面链接进入百度网盘下载
链接:https://pan.baidu.com/s/1DIBgNlUkTGlMAonU7ITk1w
提取码:e5kv
嵌入式:
IEEE(美国电气和电子工程师协会):用于控制、监视或者辅助操作机器和设备的装置,是一种专用的计算机系统。
国内:以应用为中心,以计算机技术为基础,软硬件可裁剪,适应应用系统对功能、可靠性、成本、体积、功耗等严格要求的专用计算机系统。
从应用对象上加以定义:嵌入式系统是软件和硬件的综合体,还可以涵盖机械等附属装置。
C
一、关键字
1.变量的声明和定义有什么区别?
1)为变量分配地址和存储空间的称为定义,不分配地址的称为声明。
2)一个变量可以在多个地方声明,但是只在一个地方定义。
3) 加入extem修饰的是变量的声明,说明此变量将在文件以外或在文件后面部分定义。
*说明:很多时候一个变量,只是声明不分配内存空间,直到具体使用时才初始化,分配内存空间,如外部变量。
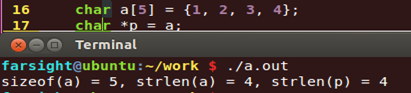
2. sizeof和strlen的区别
1)sizeof 是一个操作符(关键字),strlen是库函数。
2)sizeof 的参数可以是数据的类型,也可以是变量,而strlen 只能以结尾为 ‘/0’的字符串作参数。
3) 编译器在编译时就计算出了sizeof的结果。而strlen函数必须在运行时才能计算出来。
4)sizeof 计算的是数据类型占内存的大小,strlen 计算的是字符串实际的
度。
5)数组做 sizeof 的参数不退化,传递给 strlen就退化为指针了。
3. static关键字的作用以及C语言的关键字 static和C++的关键字static有什么区别?
1)作用:
1、修饰全局变量
改变变量的作用域,让它只能在本文件中使用。所以多个源文件可以定义同名的static全局变量,不会产生重定义错误。
2.、修饰局部变量
变量只初始化一次,生存期为整个源程序,程序结束,它的内存才释放。但是其作用域仍与自动变量相同,只能在定义该变量的函数内使用该变量。退出该函数后, 尽管该变量还继续存在,但不能使用它。
它放在.data 或者.bss段,默认初始化为0。初始化不为0放在.data段,没有初始化或初始化为0放在.bss段。程序一运行起来就给他分配内存,并进行初始化,也是唯一一次初始化。它的
修饰局部变量是改变它的生存期,变为和整个程序的生命周期一样。
3、修饰函数
和修饰全局变量一样,只在本文件中可见(即只能在本文件中被其他的函数调用)。
4、修饰类的成员变量
就变成静态成员变量,不属于对象,而属于类。不能在类的内部初始化,类中只能声明,定义需要在类外。类外定义时,不用加static关键字,只需要表明类的作用域。
5、修饰类的成员函数
变成静态成员函数,不属于对象,只属于类。形参不会生成 this 指针,仅能访问类的静态数据和静态成员函数。调用不依赖对象,所以不能作为虚函数。用类的作用域调用。
2)区别:
在C中 static 用来修饰局部静态变量、全局静态变量和函数。而C++中除了上述功能外,还用来定义类的成员变量和函数。即静态成员和静态成员函数。
注意:编程时 static 的记忆性,和全局性的特点可以让在不同时期调用的函数进行通信,传递信息,而C++的静态成员则可以在多个对象实例间进行通信,传递信息。
4. const 关键字的用途和作用
答:(1)可以定义 const 常量
(2)const 可以修饰函数的参数、返回值,甚至函数的定义体。被const 修饰的东西都受到强制保护,可以预防意外的变动,能提高程序的健壮性。
1)防止被修饰的成员的内容被改变。
2)修饰类的成员函数时,表示其为一个常函数,意味着成员函数将不能修改类成员变量的值。
3)在函数声明时修饰参数,表示在函数访问时参数(包括指针和实参)的值不会发生变化。
4)对于指针而言,可以指定指针本身为const,也可以指定指针所指的数据为const,const int *b = &a;或者int* const b = &a;修饰的都是后面的值,分别代表*b和b不能改变 。
5)const 可以替代c语言中的#define 宏定义,好处是在log中可以打印出BUFFER_SIZE 的值,而宏定义的则是不能。
#define BUFFER_SIZE 512
const int BUFFER_SIZE = 512;
*注意:const数据成员必须使用成员初始化列表进行初始化。
5. extern关键字的作用
extern 标识的变量或者函数声明其定义在别的文件中,提示编译器遇到此变量和函数时在其它模块中寻找其定义。(只声明不定义)
6. volatile 关键字的作用及使用场景
1)作用:
volatile修饰的变量在使用的时候不会直接在寄存器中取值,而是从内存中取值。
volatile的本意是“易变的” 因为访问寄存器要比访问内存单元快的多,所以编译器一般都会做减少存取内存的优化,但有可能会读脏数据。当要求使用volatile声明变量值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。精确地说就是,遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
2)使用场景:
a)中断服务程序中修改的供其它程序检测的变量需要加volatile【一个中断服务子程序中会访问到的非自动变量】
b)多任务环境下各任务间共享的标志应该加volatile【多线程应用中被几个任务共享的变量】
c)存储器映射的硬件寄存器通常也要加voliate,因为每次对它的读写都可能有不同意义。【并行设备的硬件寄存器】
1)一个参数既可以是const还可以是volatile吗?解释为什么。
2)一个指针可以是volatile吗?解释为什么。
3)下面的函数有什么错误:
int square(volatile int*ptr){
return*ptr**ptr;
}
下面是答案:
1)是的。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
2)是的。尽管这并不很常见。一个例子是当一个中服务子程序修该一个指向一个buffer的指针时。
3)这段代码有点变态。这段代码的目的是用来返指针*pr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr)
{ int
a,b; a =
*ptr; b =
*ptr; return
a * b; }
由于*ptr的值可能被意想不到地改变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下:
long square(volatile int *ptr)
{ int a;
a = *ptr;
return
a * a;
}
6. new 和 malloc 的区别?
1)大小:new分配内存按照数据类型进行分配,malloc分配内存按照指定的大小分配;
2)返回值:new返回的是指定对象的指针,而malloc返回的是void*,因此malloc的返回值一般都需要进行类型转换。
3)new不仅分配一段内存,而且会调用构造函数,malloc不会。
4)new分配的内存要用delete销毁,malloc要用free来销毁;delete销毁的时候会调用对象的析构函数,而free则不会。
5)重载:new是一个操作符可以重载,malloc是一个库函数,只能覆盖。
6)malloc分配的内存不够的时候,可以用realloc扩容。扩容的原理?new没用这样操作。
7)分配失败:new如果分配失败了会抛出bad_malloc的异常,而malloc失败了会返回NULL。
8) 申请数组时: new[]一次分配所有内存,多次调用构造函数,搭配使用delete[],delete[]多次调用析构函数,销毁数组中的每个对象。而malloc则只能sizeof(int) * n。
7. #define 与 typedef 的区别
1. 执行时间不同
关键字 typedef 在编译阶段有效,由于是在编译阶段,因此 typedef 有类型检查的功能。#define 则是宏定义,发生在预处理阶段,也就是编译之前,它只进行简单而机械的字符串替换,而不进行任何检查。
2、功能有差异
typedef 用来定义类型的别名,定义与平台无关的数据类型,与 struct 的结合使用等。#define 不只是可以为类型取别名,还可以定义常量、变量、编译开关等。
3、作用域不同
#define 没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用。而 typedef 有自己的作用域。
8. #define 和常量 const 的区别(const 相比于#define 的优点——const可以安全检查、调试)
1)类型和安全检查不同
宏定义是字符替换,没有数据类型的区别,同时这种替换没有类型安全检查,可能产生边际效应等错误;const常量是常量的声明,有类型区别,需要在编译阶段进行类型检查
2)编译器处理不同
宏定义是一个"编译时"概念,在预处理阶段展开,不能对宏定义进行调试,生命周期结束与编译时期;const常量是一个"运行时"概念,在程序运行使用,类似于一个只读行数据
3)存储方式不同
宏定义是直接替换,不会分配内存,存储与程序的代码段中;const常量需要进行内存分配,存储与程序的数据段中
4)定义域不同
5)定义后能否取消
宏定义可以通过#undef来使之前的宏定义失效;const常量定义后将在定义域内永久有效。
6)是否可以做函数参数
宏定义不能作为参数传递给函数;const常量可以在函数的参数列表中出现。
9. #define和inline的区别
1)define:定义预编译时处理的宏; 只进行简单的字符替换,无类型检测
inline: 内联函数对编译器提出建议,是否进行宏替换,编译器有权拒绝,既为提出申请,不一定会成功。
2)define:使用预编译器,没有堆栈,使用上比函数高效。但它只是预编译器上符号表的简单替换,不能进行参数有效性检测及使用C++类的成员访问控制。
inline:它消除了define的缺点,同时又很好地继承了它的优点。inline代码放入预编译器符号表中,高效;它是个真正的函数,调用时有严格的参数检测;它也可作为类的成员函数。
10. #ifndef #define #endif 的作用
防止头文件重复引用(主要是头文件中包含的全局变量的重复定义)
11.【sizeof】定义一个空的类型,里面没有任何成员变量和成员函数。对该类型求sizeof,得到的结果是多少?
答案是1。
为什么不是0?
空类型的实例中不包含任何信息,本来求sizeof应该是0,但是当我们声明该类型的实例的时候,它必须在内存中占有一定的空间,否则无法使用这些实例。至于占用多少内存,由编译器决定。Visual Studio中每个空类型的实例占用1字节的空间。
如果在该类型中添加一个构造函数和析构函数,再对该类型求sizeof,得到的结果又是多少?
应聘者:和前面一样,还是1.调用构造函数和析构函数只需要知道函数的地址即可,而这些函数的地址只与类型相关,而与类型的实例无关,编译器也不会因为这两个函数而在实例内添加任何额外的信息。
那如果把析构函数标记为虚函数呢?
应聘者:C++的编译器一旦发现一个类型中有虚拟函数,就会为该类型生成虚函数表,并在该类型的每一个实例中添加一个指向虚函数表的指针。
在32位的机器上,一个指针占4字节的空间,因此求sizeof得到4;如果是64位的机器,一个指针占8字节的空间,因此求sizeof则得到8
二、数组和字符串
1. 怎么将字符串赋值给字符数组
1)定义时直接用字符串赋值。 char a[10]="hello";但是不能先定义再赋值,即以下非法:char a[10]; a[10]="hello";
2)利用strcpy。 char a[10]; strcpy(a,"hello");
3)利用指针。 char *p; p="hello";这里字符串返回首字母地址赋值给指针p。另外以下非法:char a[10]; a="hello"; a已经指向在堆栈中分配的10个字符空间,不能再指向数据区中的"hello"常量。可以理解为a是一个地址常量,不可变,p是一个地址变量。
4)数组中的字符逐个赋值。
2. 以下四行代码的区别是什么?
指针,指针指向的是字符串常量,所以保存在常量区;
数组,自定义的,所以保存在栈区,加上const修饰,编译器做优化放到常量区
1)const char * arr = "123";
字符串123保存在常量区,const本来是修饰arr指向的值不能通过arr去修改,但是字符串“123”在常量区,本来就不能改变,所以加不加const效果都一样
2)char * brr = "123";
字符串123保存在常量区,这个arr指针指向的是同一个位置,同样不能通过brr去修改"123"的值
3)const char crr[] = "123";
这里123本来是在栈上的,但是const修饰,编译器可能会做某些优化,将其放到常量区
4)char drr[] = "123";
字符串123保存在栈区,可以通过drr去修改
三、函数
1. strcpy和strlen
1)strcpy是字符串拷贝函数,原型:char *strcpy(char* dest, const char *src);
2)从 src 逐字节拷贝到dest ,直到遇到'\0'结束,因为没有指定长度,可能会导致拷贝越界,造成缓冲区溢出漏洞,安全版本是 strncpy 函数。
3)strlen 函数是计算字符串长度的函数(求元素个数),返回从开始到'\0'之间的字符个数(不包括 ‘\0’)【没有遇到‘\0’会一直找下去,容易发生越界访问】。【区别sizeof(求字节数的大小)】
2. 回调和递归
回调:把函数当做参数传递到另一个函数内部去调用。
递归; 在函数的内部调用自身。
3. 函数传参原理
C语言中参数的传递方式一般存在两种方式:一种是通过栈的形式传递(压栈),另一种是通过寄存器的方式传递的。
四、指针
1. 什么是野指针,怎么避免?
1)定义:野指针就是指向一个已删除的对象、未申请就访问受限内存区域的指针。
2)(1)指针变量声明时没有被初始化。解决办法:指针声明时初始化,可以是具体的地址值,也可让它指向NULL。
(2)指针p被free或者delete之后,没有置为NULL。解决办法:指针指向的内存空间被释放后指针应该指向NULL。
(3)指针操作超越了变量的作用范围。解决办法:在变量的作用域结束前释放掉变量的地址空间并且让指针指向NULL。
2. 设置地址为0x67a9的整形变量的值为0xaa66
int *ptr;
ptr = (int *)0x67a9;
*ptr = 0xaa66;
3. 指针常量和常量指针的区别
指针常量是指定义了一个指针,这个指针的值只能在定义时初始化,其他地方不能改变。常量指针是指定义了一个指针,这个指针指向一个只读的对象,不能通过常量指针来改变这个对象的值。指针常量强调的是指针的不可改变性,而常量指针强调的是指针对其所指对象的不可改变性。
注意:无论是指针常量还是常量指针,其最大的用途就是作为函数的形式参数,保证实参在被调用函数中的不可改变特性。
五、结构体和共用体
1. 结构体和共用体的区别?
1)共用体的成员共用一块内存区,结构体的成员有个自独立的内存区。
2)结构体可以同时存储多种变量类型,而共同体同一个时间只能存储和使用多个变量类型的一种。
3)结构体总空间大小,等于各成员总长度,共用体空间等于最大成员占据的空间。
4)共用体不能赋初值而结构体可以。
六、操作系统和内存管理
1. 内存泄漏和溢出的区别以及分类
1)内存溢出(out of memory),是指程序在申请内存时,没有足够的内存空间供其使用。比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。(你要求分配的内存超出了系统能给你的,系统不能满足需求【分配的内存不足以放下数据项序列】 )
2)内存泄露 (memory leak),是指程序在申请内存后,无法释放已申请的内存空间。一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。(内存泄漏是指你向系统申请分配内存进行使用(new/malloc),可是使用完了以后却不归还(delete/free)【原因】,结果你申请到的那块内存你自己也不能再访问(也许你把它的地址给弄丢了),而系统也不能再次将它分配给需要的程序。)
*补充:
a)memory leak 会最终会导致out of memory!——内存不够用
b)上溢:栈满时再做进栈必定产生的空间溢出
下溢:栈空时再做退栈产生的空间溢出
3)以发生的方式来分类,内存泄漏可以分为4类:
a)常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
b)偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
c)一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
d)隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
4)内存泄漏的分类:
a)堆内存泄漏 (Heap leak)。对内存指的是程序运行中根据需要分配通过malloc,realloc new等从堆中分配的一块内存,再是完成后必须通过调用对应的 free或者delete 删掉。如果程序的设计的错误导致这部分内存没有被释放,那么此后这块内存将不会被使用,就会产生Heap Leak。
b)系统资源泄露(Resource Leak)。主要指程序使用系统分配的资源比如 Bitmap,handle ,SOCKET等没有使用相应的函数释放掉,导致系统资源的浪费,严重可导致系统效能降低,系统运行不稳定。
c)没有将基类的析构函数定义为虚函数。当基类指针指向子类对象时,如果基类的析构函数不是virtual,那么子类的析构函数将不会被调用,子类的资源没有正确是释放,因此造成内存泄露。
2. 如何判断内存泄漏?
内存泄漏通常是由于调用了malloc/new等内存申请的操作,但是缺少了对应的free/delete。为了判断内存是否泄露,
我们一方面可以使用linux环境下的内存泄漏检查工具Valgrind,mtrace检测
另一方面我们在写代码时可以添加内存申请和释放的统计功能,统计当前申请和释放的内存是否一致,以此来判断内存是否泄露。
3. 位段
1)定义:
在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为“位段”或称“位域”
2)方法:
“:”后面的数字用来限定成员变量占用的位数。
3)限制:
a)位域的宽度不能超过它所依附的数据类型的长度。通俗地讲,成员变量都是有类型的,这个类型限制了成员变量的最大长度,“:”后面的数字不能超过这个长度。
b)只有有限的几种数据类型可以用于位域。在 ANSI C 中,这几种数据类型是 int、signed int 和 unsigned int(int 默认就是 signed int)【整形家族】;到了 C99,_Bool 也被支持了。
4. 浮点数和复数在计算机中的存储形式
1)浮点数
无论是单精度还是双精度在存储中都分为三个部分:
符号部分(Sign) : 0代表正,1代表为负
指数部分(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
尾数部分(Mantissa):尾数部分
2)复数
分别存储实部和虚部
5. 什么是结构体对齐,字节对齐
1)原因:
a)平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
b)性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
2)规则
a)数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的对齐按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行。
b)结构(或联合)的整体对齐规则:在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
c)结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。
3)定义结构体对齐
可以通过预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是指定的“对齐系数”。
4、举例(https://www.jb51.net/article/120329.htm)
#pragma pack(2) //按2字节对齐
struct AA {
int a; //长度4 > 2 按2对齐;偏移量为0;存放位置区间[0,3]
char b; //长度1 < 2 按1对齐;偏移量为4;存放位置区间[4],占一个[5];
short c; //长度2 = 2 按2对齐;偏移量要提升到2的倍数6;存放位置区间[6,7]
char d; //长度1 < 2 按1对齐;偏移量为7;存放位置区间[8];共九个字节
};
#pragma pack() //恢复
6. malloc的原理,另外brk系统调用和mmap系统调用的作用分别是什么?
Malloc函数用于动态分配内存。为了减少内存碎片和系统调用的开销,malloc其采用内存池的方式,先申请大块内存作为堆区,然后将堆区分为多个内存块,以块作为内存管理的基本单位。当用户申请内存时,直接从堆区分配一块合适的空闲块。
Malloc采用隐式链表结构将堆区分成连续的、大小不一的块,包含已分配块和未分配块;同时malloc采用显示链表结构来管理所有的空闲块,即使用一个双向链表将空闲块连接起来,每一个空闲块记录了一个连续的、未分配的地址。
当进行内存分配时,Malloc会通过隐式链表遍历所有的空闲块,选择满足要求的块进行分配;当进行内存合并时,malloc采用边界标记法,根据每个块的前后块是否已经分配来决定是否进行块合并。
Malloc在申请内存时,一般会通过brk或者mmap系统调用进行申请。其中当申请内存小于128K时,会使用系统函数brk在堆区中分配;而当申请内存大于128K时,会使用系统函数mmap在映射区分配。
7. 什么时候会发生段错误
段错误通常发生在访问非法内存地址的时候,具体来说分为以下几种情况:
1)使用野指针
2)试图修改字符串常量的内容
8. C语言参数压栈顺序?
从右到左
9. C语言是怎么进行函数调用的?
每一个函数调用都会分配函数栈,在栈内进行函数执行过程。
调用前,先把返回地址压栈,然后把当前函数的esp(栈指针,用于指向栈的栈顶(下一个压入栈的活动记录的顶部);EBP为帧指针,指向当前活动记录的底部)指针压栈。
10. C++/C的内存分配
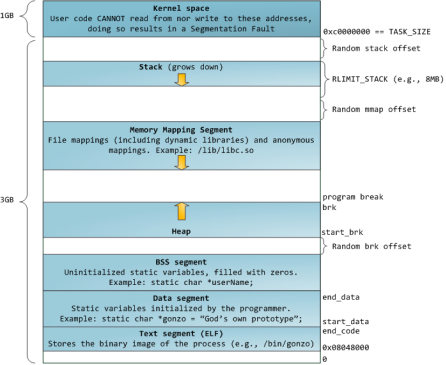
32bit CPU可寻址4G线性空间,每个进程都有各自独立的4G逻辑地址,其中0~3G是用户态空间,3~4G是内核空间,不同进程相同的逻辑地址会映射到不同的物理地址中。其逻辑地址其划分如下:
各个段说明如下:
3G用户空间和1G内核空间
1)静态区域:
a)text segment(代码段):包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机器代码。
b)data segment(数据段):存储程序中已初始化的全局变量和静态变量。
c)bss segment(bss段):存储未初始化的全局变量和静态变量(局部+全局),以及所有被初始化为0的全局变量和静态变量。对于未初始化的全局变量和静态变量,程序运行main之前时会统一清零。即未初始化的全局变量编译器会初始化为0
2)动态区域:
d)heap(堆区): 调用new/malloc函数时在堆区动态分配内存,同时需要调用delete/free来手动释放申请的内存。当进程未调用malloc时是没有堆段的,只有调用malloc时采用分配一个堆,并且在程序运行过程中可以动态增加堆大小(移动break指针),从低地址向高地址增长。分配小内存时使用该区域。 堆的起始地址由mm_struct 结构体中的start_brk标识,结束地址由brk标识。
e)memory mapping segment(映射区): 存储动态链接库以及调用mmap函数进行的文件映射
f)stack(栈区):使用栈空间存储函数的返回地址、参数、局部变量、返回值。从高地址向低地址增长。在创建进程时会有一个最大栈大小,Linux可以通过ulimit命令指定。
11. 请你说一说用户态和内核态区别
用户态和内核态是操作系统的两种运行级别,两者最大的区别就是特权级不同。
用户态拥有最低的特权级,内核态拥有较高的特权级。
运行在用户态的程序不能直接访问操作系统内核数据结构和程序。
内核态和用户态之间的转换方式主要包括:系统调用,异常和中断。
12. 请问什么是大端小端以及如何判断大端小端
大端是指低字节存储在高地址;小端存储是指低字节存储在低地址。我们可以根据联合体来判断该系统是大端还是小端,或者强制类型转换。因为联合体变量总是从低地址存储。

13. 你怎么理解操作系统里的内存碎片,有什么解决办法?
内存碎片通常分为内部碎片和外部碎片。
1. 内部碎片是由于采用固定大小的内存分区,当一个进程不能完全使用分给它的固定内存区域时就会产生内部碎片,通常内部碎片难以完全避免;(分配过大)
2. 外部碎片是由于某些未分配的连续内存区域太小,以至于不能满足任意进程的内存分配请求,从而不能被进程利用的内存区域。(分配过小)
现在普遍采取的内存分配方式是段页式内存分配。将内存分为不同的段,再将每一段分成固定大小的页。通过页表机制,使段内的页可以不必连续处于同一内存区域。
七、其它
1. include头文件的顺序以及双引号””和尖括号<>的区别
1)Include头文件的顺序:
对于include的头文件来说,如果在文件a.h中声明了一个在文件b.h中定义的变量,而不引用b.h。那么就要在a.c文件中引用b.h文件,并且要先引用b.h,后引用a.h,否则汇报变量类型未声明错误。
2)双引号和尖括号的区别:编译器预处理阶段查找头文件的路径不一样。
a)对于使用双引号包含的头文件,查找头文件路径的顺序为:
【编译器从当前工作路径开始搜索头文件】
当前头文件目录
编译器设置的头文件路径(编译器可使用-I显式指定搜索路径)
系统变量CPLUS_INCLUDE_PATH/C_INCLUDE_PATH指定的头文件路径
b)对于使用尖括号包含的头文件,查找头文件的路径顺序为:
【编译器从标准库路径开始搜索 头文件】
编译器设置的头文件路径(编译器可使用-I显式指定搜索路径)
系统变量CPLUS_INCLUDE_PATH/C_INCLUDE_PATH指定的头文件路径
2. 源码到可执行文件的过程
1)预编译(预处理 )【宏定义、文件包含、条件编译】(-E —— .i)
主要处理源代码文件中的以“#”开头的预编译指令。处理规则见下
1、删除所有的#define,展开所有的宏定义。
2、处理所有的条件预编译指令,如“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。
3、处理“#include”预编译指令,将文件内容替换到它的位置,这个过程是递归进行的,文件中包含其他文件。
4、删除所有的注释,“//”和“/**/”。
5、保留所有的#pragma 编译器指令,编译器需要用到他们,如:#pragma once 是为了防止有文件被重复引用。
6、添加行号和文件标识,便于编译时编译器产生调试用的行号信息,和编译时产生编译错误或警告是能够显示行号。
2)编译【生成汇编代码】(-S —— .s)
把预编译之后生成的xxx.i或xxx.ii文件,进行一系列词法分析、语法分析、语义分析及优化后,生成相应的汇编代码文件。
1、词法分析:利用类似于“有限状态机”的算法,将源代码程序输入到扫描机中,将其中的字符序列分割成一系列的记号。
2、语法分析:语法分析器对由扫描器产生的记号,进行语法分析,产生语法树。由语法分析器输出的语法树是一种以表达式为节点的树。
3、语义分析:语法分析器只是完成了对表达式语法层面的分析,语义分析器则对表达式是否有意义进行判断,其分析的语义是静态语义——在编译期能分期的语义,相对应的动态语义是在运行期才能确定的语义。
4、优化:源代码级别的一个优化过程。
5、目标代码生成:由代码生成器将中间代码转换成目标机器代码,生成一系列的代码序列——汇编语言表示。
6、目标代码优化:目标代码优化器对上述的目标机器代码进行优化:寻找合适的寻址方式、使用位移来替代乘法运算、删除多余的指令等。
3)汇编【生成机器代码】(-C —— .o)
将汇编代码转变成机器可以执行的指令(机器码文件)。 汇编器的汇编过程相对于编译器来说更简单,没有复杂的语法,也没有语义,更不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译过来,汇编过程有汇编器as完成。经汇编之后,产生目标文件(与可执行文件格式几乎一样)xxx.o(Windows下)、xxx.obj(Linux下)。
4)链接【生成可执行程序】(-O —— app)
将不同的源文件产生的目标文件进行链接,从而形成一个可以执行的程序。链接分为静态链接和动态链接:
1、静态链接:
函数和数据被编译进一个二进制文件。在使用静态库的情况下,在编译链接可执行文件时,链接器从库中复制这些函数和数据并把它们和应用程序的其它模块组合起来创建最终的可执行文件。
空间浪费:因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖,会出现同一个目标文件都在内存存在多个副本;
更新困难:每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。
运行速度快:但是静态链接的优点就是,在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
2、动态链接:
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
共享库:就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多分,副本,而是这多个程序在执行时共享同一份副本;
更新方便:更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。
性能损耗:因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失。
Linux基础
一、文件操作
1. 硬链接与符号链接的区别
硬链接:
利用Linux中为每个文件分配的物理编号—— inode号进行连接。因此不能跨越文件系统。
硬链接就是同一个文件使用了不同的别名, 与普通文件没什么不同,inode 都指向同一个文件在硬盘中的区块。使用ln(ln -L)创建。
软链接(符号链接):
利用文件路径名进行的连接【通常建立连接时采用绝对路径而不是相对路径,以增强可移植性】
保存了其代表的文件的绝对路径,是另外一种文件,在硬盘上有独立的区块,访问时替换自身路径。有自己独立的inode,但是其数据块内容比较特殊。(相当于 Windows 的快捷方式)。使用ln -s创建。
二、基础命令
1. linux用过的命令
● sudo su - 进入根目录
● cd pwd ls mkdir rmdir
● mv cp rm
● ps -al或者 top显示进程 kill 杀死进程
● chmod 修改权限 chown 修改文件拥有者 chgrp修改群组
● echo $PATH 打印路径
● cat 显示文件 head tail 分别显示头和尾页 tac 从尾到头显示
● nl 添加行号打印
● od 读取二进制文件
● touch :创建一个新的文件/修改文件时间
● du -ah 查看文件大小
● where 指令文件名搜寻
● gzip 压缩文件 以及解压缩
● tar 压缩文件
● vim 文档编辑器
/word 光标之下寻找word这个词
?word光标之上寻找这个词
● ll 命令 显示文件的详细信息
● > file.txt 这个>符号可以将跟在后面的文件清空
● psql dtasdb dtasuser 从后台进入DB (postgre SQL)
● 找到包含aaa的某一行 用grep |
● df 查看磁盘占用空间
数据结构
一、排序算法
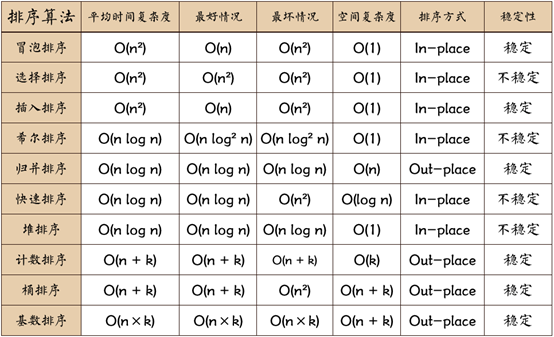
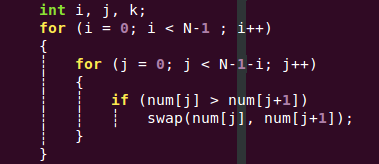
1、冒泡排序(Bubble Sort)【依次比较相邻元素的大小】
1)算法描述:
a)比较相邻的元素。如果第一个比第二个大,就交换它们两个;
b)对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
c)针对所有的元素重复以上的步骤,除了最后一个;
d)重复步骤1~3,直到排序完成。
2)代码实现:比较N-1趟,每趟比较N-1-i次
3)算法分析:
时间复杂度:最好O(n),最坏O(n^2),平均O(n^2);
空间复杂度:O(1)
稳定性: 稳定
2. 插入排序(Insertion Sort)【让已排好序的元素的下一个元素从后往前扫描,如果该元素大于新元素就往后移动一位,如果小于或者等于,就让新元素插入到这个位置】
1)算法描述:(插入N-1次),
a)从第一个元素开始,该元素可以认为已经被排序;
b)取出下一个元素,在已经排序的元素序列中从后向前扫描;
c)如果该元素(已排序)大于新元素,将该元素移到下一位置;
d)重复步骤b,直到找到已排序的元素小于或者等于新元素的位置;
e)将新元素插入到该位置后;
f)重复步骤b~e
2)代码实现:
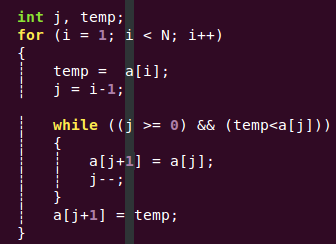

3)算法分析:
时间复杂度:最好O(n),最坏O(n^2),平均O(n^2);
空间复杂度:O(1)
稳定性: 稳定
3. 快速排序(Quick Sort)【挑出一个元素作为基准,把小于基准的放在基准前面,大于基准的放在基准后面,递归的排列两个子序列】(二分)
1)算法描述:
a)从数列中挑出一个元素,称为 “基准”(pivot);
b)重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
c)递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
2)代码实现:
https://blog.csdn.net/fhb1922702569/article/details/91868338
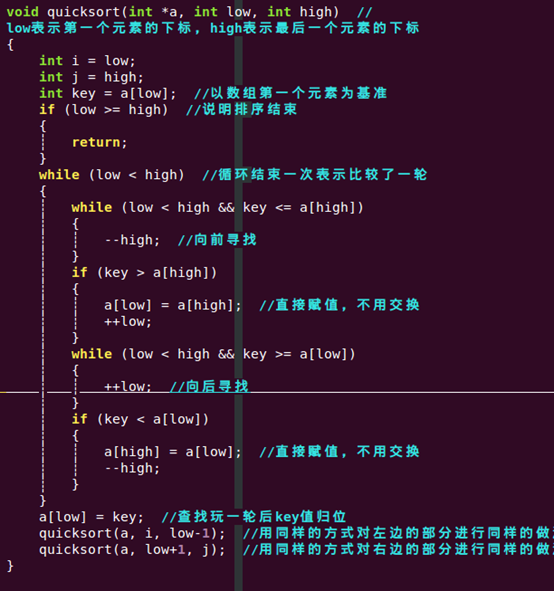
3)算法分析:
时间复杂度:最好O(nlogn),最坏O(n^2),平均O(nlogn);
空间复杂度:O(logn)
稳定性: 不稳定
4. 选择排序(Selection Sort)【依次找到最大或最小的元素】
1)算法描述:
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。(n-1趟)
2)代码实现:
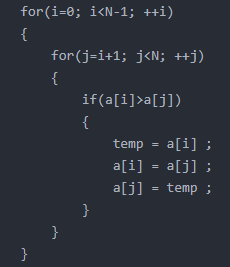
3)算法分析:
时间复杂度:最好O(n^2),最坏O(n^2),平均O(n^2);
空间复杂度:O(1)
稳定性: 不稳定
二、查找算法
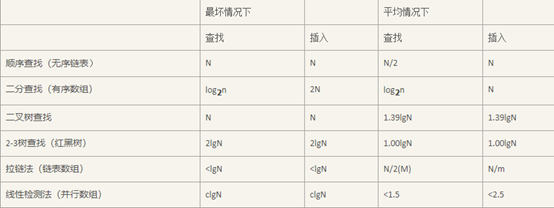

1. 顺序查找(线性查找)
1)说明:
适合于存储结构为顺序存储或链接存储的线性表。
2)算法描述:
顺序查找属于无序查找算法。从数据结构线形表的一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有找到关键字等于k的结点,表示查找失败。
3)代码实现:
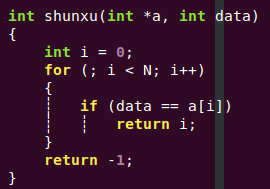
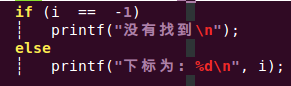
主函数接收返回值:
4)算法分析:
时间复杂度:O(n)
2. 二分查找(折半查找)
1)条件:
元素必须是有序的,如果是无序的则要先进行排序操作。
可以随机访问——顺序储存
2)算法描述:
二分查找属于有序查找算法。用定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
3)代码实现:

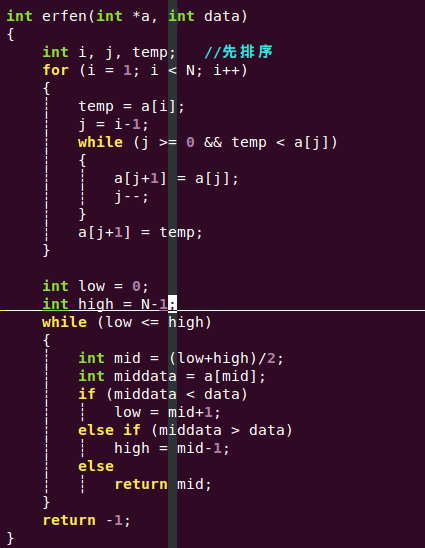
4)算法分析:
时间复杂度:O(log2n)
3. 插值查找(二分查找改进版)【O(log2(log2n))】
1)基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
复杂度分析:查找成功或者失败的时间复杂度均为O(log2(log2n))。
2)代码
int insertSearch(int *sortedSeq, int seqLength, int keyData) { int low = 0, mid, high = seqLength - 1; while (low <= high) { mid = low + (keyData - sortedSeq[low]) / (sortedSeq[high] - sortedSeq[low]); //mid = low + (key – a[low]) / (a[high] – a[low]) if (keyData < sortedSeq[mid]) { high = mid - 1;//是mid-1,因为mid已经比较过了 } else if (keyData > sortedSeq[mid]) { low = mid + 1; } else { return mid; } } return -1; }
4. 哈希查找(哈希表法)
1)说明:哈希查找的主要过程是如何建立哈希表及如何解决元素位置占用的问题
a)哈希表(散列表):
根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
b)哈希函数(散列函数):
哈希函数的规则是:通过某种转换关系,使关键字适度的分散到指定大小的的顺序结构中,越分散,则以后查找的时间复杂度越小,空间复杂度越高。
c)两大特点:
"直接定址"和"解决冲突"。
d)解决冲突:https://www.cnblogs.com/zhangbing12304/p/7997980.html
1、链接法(拉链法):
将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于 1,但一般均取α≤1。
2、开放定址法:
当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。
注意:
①用开放定址法建立散列表时,建表前须将表中所有单元(更严格地说,是指单元中存储的关键字)置空。
②空单元的表示与具体的应用相关。
a) 线性探测法:
如果在计算出这个数据在哈希表中的位置,但是这个位置上有元素,则将这个位置++,将这个数据放入下一个位置,如果这个数据还有元素,就给这个位置继续++,直到找到一个位置,这个位置为0,表示这个位置可以存放数据。
b)线性补偿探测
c)随机探测
3、桶定址法。桶:一片足够大的存储空间。桶定址:为表中的每个地址关联一个桶。如果桶已经满了,可以使用开放定址法来处理。
2)算法描述:
a)用给定的哈希函数构造哈希表(先创建哈希表);
b)根据选择的冲突处理方法解决地址冲突;
c)在哈希表的基础上执行哈希查找(通过哈希函数定位要查找的元素)。
3)算法分析:
时间复杂度:O(1)
4)代码:
//散列表查找算法(Hash) #include <stdio.h> #include <stdlib.h> #define OK 1 #define ERROR 0 #define TRUE 1 #define FALSE 0 #define SUCCESS 1 #define UNSUCCESS 0 #define HASHSIZE 7 #define NULLKEY -32768 typedef int Status; typedef struct { int *elem; //基址 int count; //当前数据元素个数 }HashTable; int m=0; // 散列表表长 /*初始化*/ Status Init(HashTable *hashTable) { int i; m=HASHSIZE; hashTable->elem = (int *)malloc(m * sizeof(int)); //申请内存 hashTable->count=m; for (i=0;i<m;i++) { hashTable->elem[i]=NULLKEY; } return OK; } /*哈希函数(除留余数法)*/ int Hash(int data) { return data % m; } /*插入*/ void Insert(HashTable *hashTable,int data) { int hashAddress=Hash(data); //求哈希地址 //发生冲突 while(hashTable->elem[hashAddress]!=NULLKEY) { //利用开放定址的线性探测法解决冲突 hashAddress=(++hashAddress)%m; } //插入值 hashTable->elem[hashAddress]=data; } /*查找*/ int Search(HashTable *hashTable,int data) { int hashAddress=Hash(data); //求哈希地址 //发生冲突 while(hashTable->elem[hashAddress]!=data) { //利用开放定址的线性探测法解决冲突 hashAddress=(++hashAddress)%m; if (hashTable->elem[hashAddress]==NULLKEY||hashAddress==Hash(data)) return -1; } //查找成功 return hashAddress; } /*打印结果*/ void Display(HashTable *hashTable) { int i; printf("\n//==============================//\n"); for (i=0;i<hashTable->count;i++) { printf("%d ",hashTable->elem[i]); }
4. 二叉树查找
1)说明:
a)二叉树的概念:
1、若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2、若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3、任意节点的左、右子树也分别为二叉查找树。
b)二叉查找树性质:
对二叉查找树进行中序遍历,即可得到有序的数列。
2)算法描述:
a)先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,
b)然后在该行和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
3)算法分析:
平均时间复杂度:O(logn),最坏情况:O(n)
三、基本概念
1.公式
a)循环链表
队尾指针是rear,队头是front,其中QueueSize为循环队列的最大长度
1)队空条件:rear==front
2)队满条件:(rear+1) %QueueSIze==front
3)计算队列长度:(rear-front+QueueSize)%QueueSize
4)入队:(rear+1)%QueueSize
5)出队:(front+1)%QueueSize
b)顺序表
1)插入为n/2
2)删除为(n-1)/2
3)查找为(n+1)/2
2. 线性与非线性的区别和种类
1)线性结构(所谓线性关系:除第一个元素外,其他元素有且只有一个前驱;除最后一个元素外,其他元素有且只有一个后继!)
2)常用的线性结构:线性表、栈、队列、双队列、数组、串
3)常用的非线性结构:二维数组、多维数组、树(二叉树等)、图、广义表
3. 数据结构中的堆和栈的区别
在数据结构中,栈是一种线性表,而且是只可在表的一端进行插入和删除运算的线性表;
堆是一种树形结构,其满中树中任一非叶结点的关键字均不大于或不小于其左右子树的结点的关键字。
4. 什么是数据结构?
数据结构是计算机存储、组织数据的方式。对于特定的数据结构(比如数组),有些操作效率很高(读某个数组元素),有些操作的效率很低(删除某个数组元素)。程序员的目标是为当前的问题选择最优的数据结构。
5. 为什么我们需要数据结构?
数据是程序的核心要素,因此数据结构的价值不言而喻。无论你在写什么程序,你都需要与数据打交道,比如员工工资、股票价格、杂货清单或者电话本。在不同场景下,数据需要以特定的方式存储,我们有不同的数据结构可以满足我们的需求。
6. 前序和后序不能确定中序
7. 8种常用数据结构
https://www.cnblogs.com/williamjie/p/9558015.html
1)数组:
a)每一个数组元素的位置由数字编号,称为下标或者索引(index)。大多数编程语言的数组第一个元素的下标是0。
b)按维度分:一维数组和二维数组
c)基本操作:
Insert:在某个索引处插入元素
Get: 读取某个索引处的元素
Delete:删除某个索引处的元素
Size: 获取数组的长度
2)栈:
a)LIFO(后进先出)
b)基本操作:
Push: 在栈的最上方插入元素
Pop: 返回栈最上方的元素,并将其删除
Top: 返回栈最上方的元素,不删除
isEmpty:查询占是否为空
3)队列:
a)FIFO(先进先出)
b)基本操作:
Enqueue:在队列末尾插入元素
Dequeue:将队列第一个元素删除
isEmpty: 查询队列是否为空
Top: 返回队列的第一个元素
4)链表
a)定义:
链表是一系列节点组成的链,每一个节点保存了数据以及指向下一个节点的指针。链表头指针指向第一个节点,如果链表为空,则头指针为空或者为null。链表可以用来实现文件系统、哈希表和邻接表。
b)分类:单向链表,双向链表
c)基本操作:
InsertATEND: 在链尾插入元素
InsertATHead: 在链头插入元素
Delete: 删除链表指定的元素
DeleteATHead:删除链表第一个元素
Search: 在链表中查询指定的元素
isEmpty: 查询链表是否为空
5)图
a)定义:
由多个节点(vertex)构成,节点之间可以互相连接组成一个网络。(x, y)表示一条边(edge),它表示节点x与y相连。边可能会有权值(weight/cost)。
b)分类:有向图,无向图
c)表现形式:邻接矩阵,邻接表
d)遍历算法:广度优先搜索,深度优先搜索
6)树
a)定义:
树(Tree)是一个分层的数据结构,由节点和连接节点的边组成。树是一种特殊的图,它与图最大的区别是没有循环。树被广泛应用在人工智能和一些复杂算法中,用来提供高效的存储结构。
b)分类:N叉树,平衡树、二叉树、二叉查找树、平衡二叉树、红黑树、2-3树
7)前缀树
a)定义:
与树类似,用于处理字符串相关的问题时非常高效。它可以实现快速检索,常用于字典中的单词查询,搜索引擎的自动补全甚至IP路由。
8)哈希表
a)定义:
哈希(Hash)将某个对象变换为唯一标识符,该标识符通常用一个短的随机字母和数字组成的字符串来代表。
b)影响性能的指标:
哈希函数、哈希表大小、哈希冲突处理方式
8. 树、图、链表、队列
a)概念
度数:一个节点的子树的个数
树的度数:该树中节点的最大度数
树的高度/深度:树中节点层数的最大值
深林:n(n≥0)棵互不相交的树的集合称为森林。树去掉根节点就成为森林,森林加上一个新的根节点就成为树。
树的逻辑结构:树中任何节点都可以有零个或多个直接后继节点(子节点),但至多只有一个直接前趋节点(父节点),根节点没有前趋节点,叶子节点没有后继节点。
b)二叉树
1.、二叉树:二叉树(Binary Tree)是n(n≥0)个节点的有限集合,它或者是空集(n=0),或者是由一个根节点以及两棵互不相交的、分别称为左子树和右子树的二又树组成。二叉树与普通有序树不同,二又树严格区分左孩子和右孩子,即使只有一个子节点也要区分左右。
2、 满二叉树:深度为k(k≥1),有2^k-1个节点的二叉树。
3、完全二叉树:只有最下面两层有度数小于2的节点,且最下面一层的叶节点集中在最左边的若干位置上。
4、二叉树的遍历:
先序遍历
中序遍历
后序遍历
按编号顺序遍
访问当前出队节点,若左孩子存在则左孩子入队,若右孩子存在则右孩子入队,front向后移动。
5、完全二叉树总结点数为 N ,若 N 为奇数,则叶子结点数为( N+1 ) /2 ;若 N 为偶数,则叶子结点数为 N/2 。
6、平衡二叉树:每个结点的左子树和右子树的高度差至多等于1
7、空链域:n个结点的二叉链表共有2n个链域,除了根节点以外,其他每个节点都被一个链域所指向,因此用到的链域为n-1个,即空链域个数为:2n - ( n-1) = n+1个。
8、线索二叉树(引线二叉树) :“一个二叉树通过如下的方法“穿起来”—— 所有原本为空的右(孩子)指针改为指向该节点在中序序列中的后继,所有原本为空的左(孩子)指针改为指向该节点的中序序列的前驱。”
c)链表
1、循环链表:.对于(非循环的)链表而言,头结点可以不存在,但是存在头结点作用会更好,而对于循环链表,必须需要头结点,不然的话,循环链表最大的作用——循环。
d)广义表
1、长度为无穷大的广义表不能在计算机中实现,但是无限递归的广义表可以在计算机中实现。
e)总结
1、数组
优点:连续存储,遍历快且方便,长度固定,
缺点:移除和添加 需要迁移n个数据或者后移n个数据 。
2、链表
优点:离散存储,添加删除方便,
缺点:空间和时间消耗大,双向链表比单向的更灵活,但是空间耗费也更大
3、Hash表
优点:数据离散存储,利用hash算法决定存储位置
缺点:遍历麻烦。以java的HashMap为例
4、二叉树
优点:一般的查找遍历,有深度优先和广度优先,遍历分前序、中序、后序遍历,效率都差不多,但是如果数据经过排序,二叉树效率还是不错。
5、图
表示物件与物件之间的关系的数学对象,常用遍历方式深度优先遍历和广度优先遍历,这两种遍历方式对有向图和无向图均适用,遍历查找不及前面人一种数据结构。
e)经验
1、广度优先用队列,深度优先用栈。
2、顺序存储是指用物理上相邻的单元存储线性表的元素,简单的说就是可以用数组实现。访问节点只需要下标,所以是O(1), 增加和删除节点要整体移动目标元素后面的元素,最坏的情况是N次,所以是O(n)。
3、带尾指针的单向链表:插入可以,但是删除无法完成,因为p需要前移,但是单向链表无法得到前一个节点。
带尾指针的双向链表:插入和删除都很简单。
带尾指针的单向循环链表:插入很简单,删除则需要遍历整个链表,比较费时。
带头指针的双向循环链表:插入和删除都很简单。
重点在于避免遍历整个链表
四. 链表、队列、栈
1. 怎么判断链表中有环【快慢指针】
设置两个指针 p1,p2 。每次循环 p1 向前走一步, p2 向前走两步。直到 p2 碰到 NULL 指针或者两个指针相等结束循环。如果两个指针相等则说明存在环。
2. 求环长
按照上面两个指针不同步长步进的方法,第一次相遇时记录当前指针,步长为 1 的指针继续走,计数,直到再次来到记录的指针,经过的步数即为环长。
3. 找环入口
根据所得环长 Y ,设置指针指向头部,另一指针先向前走 Y 。若两指针当前指向的 node 相同,则为入口,否则各自向前走 1 再判断是否相等。
4. 链表和顺序表的优缺点
1)顺序表存储(典型的数组)
原理:顺序表存储是将数据元素放到一块连续的内存存储空间,相邻数据元素的存放地址也相邻(逻辑与物理统一)。
优点:(1)空间利用率高。(局部性原理,连续存放,命中率高)
(2)存取速度高效,通过下标来直接存储。
缺点:(1)插入和删除比较慢,比如:插入或者删除一个元素时,整个表需要遍历移动元素来重新排一次顺序。
(2)不可以增长长度,有空间限制,当需要存取的元素个数可能多于顺序表的元素个数时,会出现"溢出"问题.当元素个数远少于预先分配的空间时,空间浪费巨大。
时间性能 :查找 O(1) ,插入和删除O(n)。
2.链表存储
原理:链表存储是在程序运行过程中动态的分配空间,只要存储器还有空间,就不会发生存储溢出问题,相邻数据元素可随意存放,但所占存储空间分两部分,一部分存放结点值,另一部分存放表示结点关系间的指针。
优点:(1)存取某个元素速度慢。
(2)插入和删除速度快,保留原有的物理顺序,比如:插入或者删除一个元素时,只需要改变指针指向即可。
(3)没有空间限制,存储元素的个数无上限,基本只与内存空间大小有关.
缺点:(1)占用额外的空间以存储指针(浪费空间,不连续存放,malloc开辟,空间碎片多)
(2)查找速度慢,因为查找时,需要循环链表访问,需要从开始节点一个一个节点去查找元素访问。
时间性能 :查找 O(n) ,插入和删除O(1)。
3.使用情况:
*频繁的查找却很少的插入和删除操作可以用顺序表存储。堆排序,二分查找适宜用顺序表.
*如果频繁的插入和删除操作很少的查询就可以使用链表存储
*顺序表适宜于做查找这样的静态操作;链表适宜于做插入、删除这样的动态操作。
*若线性表长度变化不大,如果事先知道线性表的大致长度,比如一年12月,一周就是星期一至星期日共七天,且其主要操作是查找,则采用顺序表;若线性表长度变化较大或根本不知道多大时,且其主要操作是插入、删除,则采用链表,这样可以不需要考虑存储空间的大小问题。
5. 广义表
长度:最大括号中的逗号数加1。【最外层包含的元素个数(即去掉最外层括号后含有的元素个数)】;
深度:每个元素的括号匹配数加1的最大值【去掉几层括号可以得到最后一部分(能去掉括号数最多的一个是几层)】
例1:E((a,(a,b),((a,b),c)))的长度和深度分别为:1,4
例2:广义表(a,(a,b),d,e,((i,j),k))的长度是( ),深度是( )
其长度为5、深度为3、为什么呢?
长度的求法为最大括号中的逗号数加1,
即为:
a后面的逗号,
(a,b)后面的逗号,
d后面的逗号,
e后面的逗号,((i,j),k)前面的逗号,
总计有四个,那么广义表的长度是4+1=5;
深度的求法为上面每个元素的括号匹配数加1的最大值,
a为1+0=1;
(a,b)为1+1=2;
d,e类似;
((i,j),k)为2+1=3;
故深度为3。
原文:https://blog.csdn.net/w_k_l/article/details/78983957
6. 栈的应用:
1、符号匹配;
2、表达式求值;
3、实现函数调用
7. 静态链表
静态链表采用数组实现链表的存储,用空间换取时间,删除与插入需要改的是游标。
IO/进线程
一、基础知识
*1. 四种IO模型
a)阻塞IO:
最简单、最常用、效率最低
当你一开始建立一个套接字描述符的时候,系统内核将其设置为阻塞I0模式。
读操作中的:read、recv、recvfrom
写操作中的:write、send
其他操作:accept、connect
b)非阻塞IO:
可防止进程阻塞在I/O操作上,需要轮询
当我们将一个套接字设置为非阻塞模式,我们相当于告诉了系统内核:“当我请求/O操作不能够马上完成,你想让我的进程进行休眠等待的时候,不要这么做,请马上返回一个错误给我。”
当一个应用程序使用了非阻塞模式的套接字,它需要使用一个循环来不停地测试是否一个文件描述符有数据可读(称做polling)。
应用程序不停的polling内核来检查是否VO操作已经就绪。这将是一个极浪费CPU资源的操作。
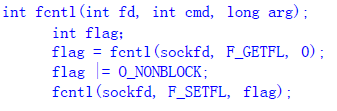
可以使用函数fcntl(),设置一个套接字的标志为0_NONBLOCK来实现非阻塞。
c)IO多路复用:
允许同时对多个I/O进行控制
思想:先构造一张有关描述符的表,然后调用一个函数。当这些文件描述符中的一个或多个已准备好进行I/0时函数才返回。函数返回时告诉进程那个描述符已就绪,可以进行I/0操作。
select()和poll()函数来实现

d)信号驱动IO:
一种异步通信模型
2. 阻塞,非阻塞,同步,异步
a)阻塞:调用者在事件没有发生的时候,一直在等待事件发生,不能去处理别的任务。
b)非阻塞:调用者在事件没有发生的时候,可以去处理别的任务,等事件发生后再回来处理。
c)同步:调用者必须自己去查看事件有没有发生。
d)异步:调用者不用自己去查看事件有没有发生,而是等待着注册在事件上的回调函数通知自己。
总结:阻塞和非阻塞看是否等待事件发生;同步和异步看有没有信号通知自己。
3. 服务器模型
1. 循环服务器:在同一个时刻只能响应一个客户端的请求
TCP服务器端运行后等待客户端的连接请求。
TCP服务器接受一个客户端的连接后开始处理,完成了客户的所有请求后断开连接。
TCP循环服务器一次只能处理一个客户端的请求。
只有在当前客户的所有请求都完成后,服务器才能处理下一个客户的连接/服务请求。
如果某个客户端一直占用服务器资源,那么其它的客户端都不能被处理。TCP服务器一般很少采用循环服务器模型。

2. 并发服务器:在同一个时刻可以响应多个客户端的请求
思想:服务器接受客户端的连接请求后创建子进程来为客户端服务

除非UDP服务器在处理某个客户端的请求时所用的时间比较长,人们实际上较少用UDP并发服务器模型。

二、进线程
*1.进程与线程的概念,其中有什么区别,他们各自又是怎么同步的?
1)基本概念:
a)一个程序的运行就是一个进程。进程是对运行时程序的封装,是系统进行资源调度和分配的的基本单位,实现了操作系统的并发;
b)线程是进程的子任务,是CPU调度和分派的基本单位,用于保证程序的实时性,实现进程内部的并发;线程是操作系统可识别的最小执行和调度单位。
2)区别:
a)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程依赖于进程而存在。
b)进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存。(同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。)
c)进程是资源分配的最小单位,线程是CPU调度的最小单位;
d)系统开销: 进程创建、销毁、切换的开销远大于线程开销
由于在创建或撤消进程时,系统都要为之分配或回收资源,如内存空间、I/O设备等。因此,操作系统所付出的开销将显著地大于在创建或撤消线程时的开销。类似地,在进行进程切换时,涉及到整个当前进程CPU环境的保存以及新被调度运行的进程的CPU环境的设置。而线程切换只须保存和设置少量寄存器的内容,并不涉及存储器管理方面的操作。可见,。
e)通信:线程通信比进程通信容易
由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。线程间可以直接读写进程数据段(如全局变量)来进行通信(需要进程同步和互斥手段的辅助,以保证数据的一致性)在有的系统中,线程的切换、同步和通信都无须操作系统内核的干预
f)进程编程调试简单可靠性高,但是创建销毁开销大;线程正相反,开销小,切换速度快,但是编程调试相对复杂。
7)进程间不会相互影响 ;但一个线程挂掉将导致整个进程挂掉
8)进程适应于多核、多机分布;线程适用于多核
3)线程间通信的方式:【临界区(全局变量)、互斥量、信号量、事件(信号)】
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
a)临界区
通过多线程的串行化来访问公共资源或一段代码(全局变量),速度快,适合控制数据访问;
b)锁机制:包括互斥锁(互斥量)、条件变量、读写锁
1、互斥锁(互斥量)【lock和unlock】
采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。可以和条件锁一起实现同步。当进入临界区时,需要获得互斥锁并且加锁;当离开临界区时,需要对互斥锁解锁,以唤醒其他等待该互斥锁的线程。
其主要的系统调用如下:
pthread_mutex_init:初始化互斥锁
pthread_mutex_destroy:销毁互斥锁
pthread_mutex_lock:以原子操作的方式给一个互斥锁加锁,如果目标互斥锁已经被上锁, pthread_mutex_lock调用将阻塞,直到该互斥锁的占有者将其解锁。
pthread_mutex_unlock:以一个原子操作的方式给一个互斥锁解锁。
2、读写锁
允许多个线程同时读共享数据,而对写操作是互斥的。
3、条件变量
可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。又称条件锁,用于在线程之间同步共享数据的值。条件变量提供一种线程间通信机制:当某个共享数据达到某个值时,唤醒等待这个共享数据的一个/多个线程。即,当某个共享变量等于某个值时,调用 signal/broadcast。此时操作共享变量时需要加锁。其主要的系统调用如下:
pthread_cond_init:初始化条件变量
pthread_cond_destroy:销毁条件变量
pthread_cond_signal:唤醒一个等待目标条件变量的线程。哪个线程被唤醒取决于调度策略和优先级。
pthread_cond_wait:等待目标条件变量。需要一个加锁的互斥锁确保操作的原子性。该函数中在进入wait状态前首先进行解锁,然后接收到信号后会再加锁,保证该线程对共享资源正确访问。
c)信号量机制(Semaphore):包括无名线程信号量和命名线程信号量【PV操作】
为控制具有有限数量的用户资源而设计的,它允许多个线程在同一时刻去访问同一个资源,但一般需要限制同一时刻访问此资源的最大线程数目。它只取自然数值,并且只支持两种操作:
P(SV)【消费】:如果信号量SV大于0,将它减一;如果SV值为0,则挂起该线程。
V(SV)【生产】:如果有其他进程因为等待SV而挂起,则唤醒,然后将SV+1;否则直接将SV+1。
其系统调用为:
sem_wait(sem_t *sem):以原子操作的方式将信号量减1,如果信号量值为0,则sem_wait将被阻塞,直到这个信号量具有非0值。(P)
sem_post(sem_t *sem):以原子操作将信号量值+1。当信号量大于0时,其他正在调用sem_wait等待信号量的线程将被唤醒。(V)
d)信号(事件)机制(Signal):类似进程间的信号处理。通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较。
4)进程间通信的方式:【管道、信号、共享内存、消息队列、信号灯、套接字】
a)管道
管道是基于文件描述符的通信方式。当一个管道建立时,它会创建两个文件描述符fd[0]和fd[1]。其中fd[0]固定用于读管道,而fd[1]固定用于写管道。构成了一个半双工的通道。
1、无名管道PIPE:
1)它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端
单工:只支持数据在一个方向上传输;只有一方能接受或发送信息,不能实现双向通信,举例:电视,广播。
半双工:允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信;在同一时间只可以有一方接受或发送信息,可以实现双向通信。举例:对讲机。
全双工:允许数据同时在两个方向上传输,因此,全双工通信是两个单工通信方式的结合,它要求发送设备和接收设备都有独立的接收和发送能力;在同一时间可以同时接受和发送信息,实现双向通信,举例:电话通信。
2)它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)
3)它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
2、命(有)名管道FIFO:
1)FIFO可以在无关的进程之间交换数据
2)FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
b)信号(Signal)
信号是在软件层次上对中断机制的一种模拟,是一种异步通信方式信号可以直接进行用户空间进程和内核进程之间的交互,内核进程也可以利用它来通知用户空间进程发生了哪些系统事件。
如果该进程当前并未处于执行态,则该信号就由内核保存起来,直到该进程恢复执行再传递给它;如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消时才被传递给进程
用户进程对信号的响应方式:
忽略信号:对信号不做任何处理,但是有两个信号不能忽略:即SIGKILL及SIGSTOP。
捕捉信号:定义信号处理函数,当信号发生时,执行相应的处理函数。
执行缺省操作:Linux对每种信号都规定了默认操作
信号的发送与捕捉
kill()kill函数同读者熟知的kill系统命令一样,可以发送信号给进程或进程组(实际上,kill系统命令只是kill函数的一个用户接口)。
kill -1命令查看系统支持的信号列表
raise()函数允许进程向自己发送信号
alarm()也称为闹钟函数,它可以在进程中设置一个定时器。当定时器指定的时间到时,内核就向进程发送SIGALARM信号。
pause()函数是用于将调用进程挂起直到收到信号为止。
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
1)Linux系统中共有64种信号。
SIGINT 2 Ctrl+C时操作系统给前台进程发送这个信号
SIGABRT 6 异常终止信号
SIGPOLL 8 指示一个异步I/O事件
SIGKILL 9 强行终止
SIGSEGV 11 无效存储访问时操作系统会发出这个信号
SIGPIPE 13 涉及管道和socket
SIGALRM 14 alarm
SIGCHILD 17 子进程终止
SIGUSR1 10 用户自定义
SIGUSR2 12 用户自定义
2)信号发送函数
kill(), sigqueue(),
raise(), alarm(), setitimer(), pause(),abort()
c)消息队列(Message Queue)【读写内容】
消息队列是IPC对象的一种
消息队列由消息队列ID来唯一标识
消息队列就是一个消息的列表。用户可以在消息队列中添加消息、读取消息等。
消息队列可以按照类型来发送/接收消息
是消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。具有写权限的进程可以按照一定的规则向消息队列中添加新信息;对消息队列有读权限的进程则可以从消息队列中读取信息。
特点:
1)消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级。
2)消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除。
3)消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
d)信号量(Semaphore)
信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
特点:
1)信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
2)信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作。
3)每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
4)支持信号量组。
e)共享内存(Shared Memory )
共享内存是一种最为高效的进程间通信方式,进程可以直接读写内存,而不需要任何数据的拷贝
为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间
进程就可以直接读写这一内存区而不需要进行数据的拷贝,从而大大提高的效率。由于多个进程共享一段内存,因此也需要依靠某种同步机制,如互斥锁和信号量等
共享内存是IPC的一种高效方式,速度很快。 shmget 创建共享内存 shmat 关联共享内存 shmdt 解除关联共享内存
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
特点:
1)共享内存是最快的一种IPC,因为进程是直接对内存进行存取
2)因为多个进程可以同时操作,所以需要进行同步
3)信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
共享内存的使用包括如下步骤:
创建/打开共享内存
映射共享内存,即把指定的共享内存映射到进程的地址空间用于访问
撤销共享内存映射
删除共享内存对象
f)套接字(Socket): 套接字也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同主机间的进程通信。
2. 如何采用单线程的方式处理高并发
在单线程模型中,可以采用I/O复用来提高单线程处理多个请求的能力,然后再采用事件驱动模型,基于异步回调来处理事件。
3. 多进程和多线程的区别使用场景
1)多进程优点:
1、每个进程互相独立,不影响主程序的稳定性,子进程崩溃没关系;
2、通过增加CPU,就可以容易扩充性能;
3、可以尽量减少线程加锁/解锁的影响,极大提高性能,就算是线程运行的模块算法效率低也没关系;
4、每个子进程都有2GB地址空间和相关资源,总体能够达到的性能上限非常大。
多进程缺点:
1、逻辑控制复杂,需要和主程序交互;
2、需要跨进程边界,如果有大数据量传送,就不太好,适合小数据量传送、密集运算 多进程调度开销比较大;
3、最好是多进程和多线程结合,即根据实际的需要,每个CPU开启一个子进程,这个子进程开启多线程可以为若干同类型的数据进行处理。当然你也可以利用多线程+多CPU+轮询方式来解决问题……
4、方法和手段是多样的,关键是自己看起来实现方便有能够满足要求,代价也合适。
2)多线程的优点:
1、无需跨进程边界;
2、程序逻辑和控制方式简单;
3、所有线程可以直接共享内存和变量等;
4、线程方式消耗的总资源比进程方式好。
多线程缺点:
1、每个线程与主程序共用地址空间,受限于2GB地址空间;
2、线程之间的同步和加锁控制比较麻烦;
3、一个线程的崩溃可能影响到整个程序的稳定性;
4、到达一定的线程数程度后,即使再增加CPU也无法提高性能,例如Windows Server 2003,大约是1500个左右的线程数就快到极限了(线程堆栈设定为1M),如果设定线程堆栈为2M,还达不到1500个线程总数;
5、线程能够提高的总性能有限,而且线程多了之后,线程本身的调度也是一个麻烦事儿,需要消耗较多的CPU。
3)多线程模型
主要优势为线程间切换代价较小,因此适用于I/O密集型的工作场景,因此I/O密集型的工作场景经常会由于I/O阻塞导致频繁的切换线程。同时,多线程模型也适用于单机多核分布式场景。
4)多进程模型
适用于CPU密集型。同时,多进程模型也适用于多机分布式场景中,易于多机扩展。
4. 死锁发生的条件以及如何解决死锁
1)定义:
死锁是指两个或两个以上进程在执行过程中,因争夺资源而造成相互等待的现象。
2)死锁产生的条件
a)互斥条件:进程对所分配到的资源不允许其他进程访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源。(一个资源每次只能被一个进程使用)
b)请求和保持条件:进程获得一定的资源后,又对其他资源发出请求,但是该资源可能被其他进程占有,此时请求阻塞,但该进程不会释放自己已经占有的资源。(一个进程因请求资源而阻塞时,对已获得的资源保持不放)
c)不可剥夺条件:进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用后自己释放
d)环路等待条件:进程发生死锁后,必然存在一个进程-资源之间的环形链。(若干进程之间形成一种头尾相接的循环等待资源关系)
3)解决死锁的方法即破坏上述四个条件之一,主要方法如下:
a)资源一次性分配,从而剥夺请求和保持条件
b)可剥夺资源:即当进程新的资源未得到满足时,释放已占有的资源,从而破坏不可剥夺的条件
c)资源有序分配法:系统给每类资源赋予一个序号,每个进程按编号递增的请求资源,释放则相反,从而破坏环路等待的条件。
5. 死循环+来连接时新建线程的方法效率有点低,怎么改进?
提前创建好一个线程池,用生产者消费者模型,创建一个任务队列,队列作为临界资源,有了新连接,就挂在到任务队列上,队列为空所有线程睡眠。
改进死循环:使用select epoll这样的技术
6. 怎么实现线程池
1)设置一个生产者消费者队列,作为临界资源
2)初始化n个线程,并让其运行起来,加锁去队列取任务运行
3)当任务队列为空的时候,所有线程阻塞
4)当生产者队列来了一个任务后,先对队列加锁,把任务挂在到队列上,然后使用条件变量去通知阻塞中的一个线程。
7. 5种IO模型
1)阻塞IO
调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停的去检查这个函数有没有返回,必须等这个函数返回才能进行下一步动作
2)非阻塞IO
非阻塞等待,每隔一段时间就去检测IO事件是否就绪。没有就绪就可以做其他事。
3)信号驱动IO
信号驱动IO:linux用套接口进行信号驱动IO,安装一个信号处理函数,进程继续运行并不阻塞,当IO时间就绪,进程收到SIGIO信号。然后处理IO事件。
4)IO复用/多路转接IO
linux用select/poll函数实现IO复用模型,这两个函数也会使进程阻塞,但是和阻塞IO所不同的是这两个函数可以同时阻塞多个IO操作。而且可以同时对多个读操作、写操作的IO函数进行检测。知道有数据可读或可写时,才真正调用IO操作函数
5)异步IO
linux中,可以调用aio_read函数告诉内核描述字缓冲区指针和缓冲区的大小、文件偏移及通知的方式,然后立即返回,当内核将数据拷贝到缓冲区后,再通知应用程序。
8. 进程的几种状态
1)正常进程
正常情况下,子进程是通过父进程创建的,子进程再创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程到底什么时候结束。 当一个进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
unix提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到:在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。 但是仍然为其保留一定的信息,直到父进程通过wait / waitpid来取时才释放。保存信息包括:
1、进程号the process ID
2、退出状态the termination status of the process
3、运行时间the amount of CPU time taken by the process等
2)孤儿进程
一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
3)僵尸进程
1、定义:
一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程。
僵尸进程是一个进程必然会经过的过程:这是每个子进程在结束时都要经过的阶段。
如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是“Z”。如果父进程能及时处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。
2、危害:
如果进程不调用wait / waitpid的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程。
3、处理:
1)外部消灭:(Kill)
通过kill发送SIGTERM或者SIGKILL信号消灭产生僵尸进程的进程,它产生的僵死进程就变成了孤儿进程,这些孤儿进程会被init进程接管,init进程会wait()这些孤儿进程,释放它们占用的系统进程表中的资源
2)内部解决:
1、子进程退出时向父进程发送SIGCHILD信号,父进程处理SIGCHILD信号。在信号处理函数中调用wait进行处理僵尸进程。
2、fork两次,原理是将子进程成为孤儿进程,从而其的父进程变为init进程,通过init进程可以处理僵尸进程。
9. Linux的4种锁机制:
1)互斥锁:mutex,用于保证在任何时刻,都只能有一个线程访问该对象。当获取锁操作失败时,线程会进入睡眠,等待锁释放时被唤醒
2)读写锁:rwlock,分为读锁和写锁。处于读操作时,可以允许多个线程同时获得读操作。但是同一时刻只能有一个线程可以获得写锁。其它获取写锁失败的线程都会进入睡眠状态,直到写锁释放时被唤醒。 注意:写锁会阻塞其它读写锁。当有一个线程获得写锁在写时,读锁也不能被其它线程获取;写者优先于读者(一旦有写者,则后续读者必须等待,唤醒时优先考虑写者)。适用于读取数据的频率远远大于写数据的频率的场合。
3)自旋锁:spinlock,在任何时刻同样只能有一个线程访问对象。但是当获取锁操作失败时,不会进入睡眠,而是会在原地自旋,直到锁被释放。这样节省了线程从睡眠状态到被唤醒期间的消耗,在加锁时间短暂的环境下会极大的提高效率。但如果加锁时间过长,则会非常浪费CPU资源。
4)RCU:即read-copy-update,在修改数据时,首先需要读取数据,然后生成一个副本,对副本进行修改。修改完成后,再将老数据update成新的数据。使用RCU时,读者几乎不需要同步开销,既不需要获得锁,也不使用原子指令,不会导致锁竞争,因此就不用考虑死锁问题了。而对于写者的同步开销较大,它需要复制被修改的数据,还必须使用锁机制同步并行其它写者的修改操作。在有大量读操作,少量写操作的情况下效率非常高。
10. 互斥锁(mutex)机制,以及互斥锁和读写锁的区别
1)互斥锁和读写锁的定义:
a)互斥锁:mutex,用于保证在任何时刻,都只能有一个线程访问该对象。当获取锁操作失败时,线程会进入睡眠,等待锁释放时被唤醒。
b)读写锁:rwlock,分为读锁和写锁。处于读操作时,可以允许多个线程同时获得读操作。但是同一时刻只能有一个线程可以获得写锁。其它获取写锁失败的线程都会进入睡眠状态,直到写锁释放时被唤醒。 注意:写锁会阻塞其它读写锁。当有一个线程获得写锁在写时,读锁也不能被其它线程获取;写者优先于读者(一旦有写者,则后续读者必须等待,唤醒时优先考虑写者)。适用于读取数据的频率远远大于写数据的频率的场合。
2)互斥锁和读写锁的区别:
a)读写锁区分读者和写者,而互斥锁不区分
b)互斥锁同一时间只允许一个线程访问该对象,无论读写;读写锁同一时间内只允许一个写者,但是允许多个读者同时读对象。
11. 单核机器上写多线程程序,是否需要考虑加锁,为什么?
在单核机器上写多线程程序,仍然需要线程锁。
因为线程锁通常用来实现线程的同步和通信。在单核机器上的多线程程序,仍然存在线程同步的问题。因为在抢占式操作系统中,通常为每个线程分配一个时间片,当某个线程时间片耗尽时,操作系统会将其挂起,然后运行另一个线程。如果这两个线程共享某些数据,不使用线程锁的前提下,可能会导致共享数据修改引起冲突。
12. 并发(concurrency)和并行(parallelism)
1)并发(concurrency):指宏观上看起来两个程序在同时运行,比如说在单核cpu上的多任务。但是从微观上看两个程序的指令是交织着运行的,你的指令之间穿插着我的指令,我的指令之间穿插着你的,在单个周期内只运行了一个指令。这种并发并不能提高计算机的性能,只能提高效率。
2)并行(parallelism):指严格物理意义上的同时运行,比如多核cpu,两个程序分别运行在两个核上,两者之间互不影响,单个周期内每个程序都运行了自己的指令,也就是运行了两条指令。这样说来并行的确提高了计算机的效率。所以现在的cpu都是往多核方面发展。
13. fork和vfork的区别
1)fork( )的子进程拷贝父进程的数据段和代码段;vfork( )的子进程与父进程共享数据
2)fork( )的父子进程的执行次序不确定;vfork( )保证子进程先运行,在调用exec或exit之前与父进程数据是共享的,在它调用exec或exit之后父进程才可能被调度运行。
3)vfork( )保证子进程先运行,在它调用exec或exit之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
4)当需要改变共享数据段中变量的值,则拷贝父进程。
1、fork的基础知识:
创建一个和当前进程映像一样的进程可以通过fork( )系统调用:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
成功调用fork( )会创建一个新的进程,它几乎与调用fork( )的进程一模一样,这两个进程都会继续运行。在子进程中,成功的fork( )调用会返回0。在父进程中fork( )返回子进程的pid。如果出现错误,fork( )返回一个负值。
最常见的fork( )用法是创建一个新的进程,然后使用exec( )载入二进制映像,替换当前进程的映像。这种情况下,派生(fork)了新的进程,而这个子进程会执行一个新的二进制可执行文件的映像。这种“派生加执行”的方式是很常见的。
在早期的Unix系统中,创建进程比较原始。当调用fork时,内核会把所有的内部数据结构复制一份,复制进程的页表项,然后把父进程的地址空间中的内容逐页的复制到子进程的地址空间中。但从内核角度来说,逐页的复制方式是十分耗时的。现代的Unix系统采取了更多的优化,例如Linux,采用了写时复制的方法,而不是对父进程空间进程整体复制。
2、vfork的基础知识:
在实现写时复制之前,Unix的设计者们就一直很关注在fork后立刻执行exec所造成的地址空间的浪费。BSD的开发者们在3.0的BSD系统中引入了vfork( )系统调用。
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
除了子进程必须要立刻执行一次对exec的系统调用,或者调用_exit( )退出,对vfork( )的成功调用所产生的结果和fork( )是一样的。
vfork( )会挂起父进程直到子进程终止或者运行了一个新的可执行文件的映像。通过这样的方式,vfork( )避免了地址空间的按页复制。在这个过程中,父进程和子进程共享相同的地址空间和页表项。实际上vfork( )只完成了一件事:复制内部的内核数据结构。因此,子进程也就不能修改地址空间中的任何内存。
vfork( )是一个历史遗留产物,Linux本不应该实现它。需要注意的是,即使增加了写时复制,vfork( )也要比fork( )快,因为它没有进行页表项的复制。然而,写时复制的出现减少了对于替换fork( )争论。实际上,直到2.2.0内核,vfork( )只是一个封装过的fork( )。因为对vfork( )的需求要小于fork( ),所以vfork( )的这种实现方式是可行的。
3、写时复制
Linux采用了写时复制的方法,以减少fork时对父进程空间进程整体复制带来的开销。
写时复制是一种采取了惰性优化方法来避免复制时的系统开销。它的前提很简单:如果有多个进程要读取它们自己的那部门资源的副本,那么复制是不必要的。每个进程只要保存一个指向这个资源的指针就可以了。只要没有进程要去修改自己的“副本”,就存在着这样的幻觉:每个进程好像独占那个资源。从而就避免了复制带来的负担。如果一个进程要修改自己的那份资源“副本”,那么就会复制那份资源,并把复制的那份提供给进程。不过其中的复制对进程来说是透明的。这个进程就可以修改复制后的资源了,同时其他的进程仍然共享那份没有修改过的资源。所以这就是名称的由来:在写入时进行复制。
写时复制的主要好处在于:如果进程从来就不需要修改资源,则不需要进行复制。惰性算法的好处就在于它们尽量推迟代价高昂的操作,直到必要的时刻才会去执行。
在使用虚拟内存的情况下,写时复制(Copy-On-Write)是以页为基础进行的。所以,只要进程不修改它全部的地址空间,那么就不必复制整个地址空间。在fork( )调用结束后,父进程和子进程都相信它们有一个自己的地址空间,但实际上它们共享父进程的原始页,接下来这些页又可以被其他的父进程或子进程共享。
写时复制在内核中的实现非常简单。与内核页相关的数据结构可以被标记为只读和写时复制。如果有进程试图修改一个页,就会产生一个缺页中断。内核处理缺页中断的方式就是对该页进行一次透明复制。这时会清除页面的COW属性,表示着它不再被共享。
现代的计算机系统结构中都在内存管理单元(MMU)提供了硬件级别的写时复制支持,所以实现是很容易的。
在调用fork( )时,写时复制是有很大优势的。因为大量的fork之后都会跟着执行exec,那么复制整个父进程地址空间中的内容到子进程的地址空间完全是在浪费时间:如果子进程立刻执行一个新的二进制可执行文件的映像,它先前的地址空间就会被交换出去。写时复制可以对这种情况进行优化。
14. 有了进程,为什么还要有线程?
1)线程产生的原因:
进程可以使多个程序能并发执行,以提高资源的利用率和系统的吞吐量;但是其具有一些缺点:
a)进程在同一时间只能干一件事
b)进程在执行的过程中如果阻塞,整个进程就会挂起,即使进程中有些工作不依赖于等待的资源,仍然不会执行。
因此,操作系统引入了比进程粒度更小的线程,作为并发执行的基本单位,从而减少程序在并发执行时所付出的时空开销,提高并发性。
2)、线程的优势如下:
a)从资源上来讲,线程是一种非常"节俭"的多任务操作方式。在linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种"昂贵"的多任务工作方式。
b)从切换效率上来讲,运行于一个进程中的多个线程,它们之间使用相同的地址空间,而且线程间彼此切换所需时间也远远小于进程间切换所需要的时间。据统计,一个进程的开销大约是一个线程开销的30倍左右。(
c)从通信机制上来讲,线程间方便的通信机制。对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过进程间通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进城下的线程之间贡献数据空间,所以一个线程的数据可以直接为其他线程所用,这不仅快捷,而且方便。
3)、除了以上优点外,多线程程序作为一种多任务、并发的工作方式,还有如下优点
a)使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
b)改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序才会利于理解和修改。
15. 线程间机制(同步与互斥的区别)?
1)进程互斥指若干个进程要使用同一共享资源时,任何时刻最多允许一个进程去使用,其他要使用该资源的进程必须等待,直到占有资源的进程释放该资源。
2)进程同步指两个以上进程基于某个条件来协调它们的活动。一个进程的执行依赖于另一个协作进程的消息或信号,当一个进程没有得到来自于另一个进程的消息或信号时则需等待,直到消息或信号到达才被唤醒。
进程互斥关系是一种特殊的进程同步关系,即逐次使用互斥共享资源,也是对进程使用资源次序上的一种协调。
16. 怎样确定当前线程是繁忙还是阻塞?
使用ps命令查看
17. 请问就绪状态的进程在等待什么?
被调度使用cpu的运行权
18. 多线程的同步,锁的机制
同步的时候用一个互斥量,在访问共享资源前对互斥量进行加锁,在访问完成后释放互斥量上的锁。对互斥量进行加锁以后,任何其他试图再次对互斥量加锁的线程将会被阻塞直到当前线程释放该互斥锁。
如果释放互斥锁时有多个线程阻塞,所有在该互斥锁上的阻塞线程都会变成可运行状态,第一个变为运行状态的线程可以对互斥量加锁,其他线程将会看到互斥锁依然被锁住,只能回去再次等待它重新变为可用。在这种方式下,每次只有一个线程可以向前执行
18. 两个进程访问临界区资源,会不会出现都获得自旋锁的情况?
单核cpu,并且开了抢占可以造成这种情况。
19. windows消息机制
当用户有操作(鼠标,键盘等)时,系统会将这些事件转化为消息。每个打开的进程系统都为其维护了一个消息队列,系统会将这些消息放到进程的消息队列中,而应用程序会循环从消息队列中取出来消息,完成对应的操作。
20. 什么是进程,与程序有什么区别?
进程是一个程序的一次执行的过程。
区别:程序是静态的,它是一些保存在磁盘上的指令的有序集合,没有任何执行的概念。
进程是一个动态的概念,它是程序执行的过程,包括创建、调度和消亡。
21.守护进程
定义:一个在后台运行并且不受任何终端控制的进程
1)创建子进程,终止父进程【编程僵尸进程,脱离父进程】【fork()、exit(0)】
使得程序在shell终端里造成一个已经运行完毕的假象。之后所有的工作都在子进程中完成,而用户在shell终端里则可以执行其他的命令,从而使得程序以僵尸进程形式运行,在形式上做到了与控制终端的脱离。
2)在子进程中创建新会话【完全独立进程】【setsid()】
这个步骤是创建守护进程中最重要的一步,在这里使用的是系统函数 setsid。
setsid 函数用于创建一个新的会话,并担任该会话组的组长。调用setsid三个作用: a)让进程摆脱原会话的控制;
b)让进程摆脱原进程组的控制
c)让进程摆脱原控制终端的控制。
在调用fork函数时,子进程全盘拷贝父进程的会话期(session,是一个或多个进程组的集合)、进程组、控制终端等,虽然父进程退出了,但原先的会话期、进程组、控制终端等并没有改变,因此,那还不是真正意义上使两者独立开来。setsid函数能够使进程完全独立出来,从而脱离所有其他进程的控制。
3)改变工作目录(chdir /)
使用fork创建的子进程也继承了父进程的当前工作目录。由于在进程运行过程中,当前目录所在的文件系统不能卸载,因此,把当前工作目录换成其他的路径,如“/”或“/tmp”等。改变工作目录的常见函数是chdir。
4)重设文件创建掩码【umask(0)】
文件创建掩码是指屏蔽掉文件创建时的对应位。由于使用fork函数新建的子进程继承了父进程的文件创建掩码,这就给该子进程使用文件带来了诸多的麻烦。因此,把文件创建掩码设置为0,可以大大增强该守护进程的灵活性。设置文件创建掩码的函数是umask,通常的使用方法为umask(0)。
5)关闭文件描述符 【close()】
用fork新建的子进程会从父进程那里继承一些已经打开了的文件。这些被打开的文件可能永远不会被守护进程读或写,但它们一样消耗系统资源,可能导致所在的文件系统无法卸载。
22. select、pool、epool三则的区别
1、支持一个进程所能打开的最大连接数
|
select |
单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上FD_SETSIZE为32*64),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。 |
|
poll |
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 |
|
epoll |
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接 |
2、FD剧增后带来的IO效率问题
|
select |
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。 |
|
poll |
同上 |
|
epoll |
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。 |
3、 消息传递方式
|
select |
内核需要将消息传递到用户空间,都需要内核拷贝动作 |
|
poll |
同上 |
|
epoll |
epoll通过内核和用户空间共享一块内存来实现的。 |
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
23. exec函数族的作用
exec函数族提供了一种在进程中启动另一个程序执行的方法。它可以根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段。在执行完之后,原调用进程的内容除了进程号外,其他全部都被替换了。【当前进程映像替换成新的程序文件,而且该程序通常main函数开始执行】
可执行文件既可以是二进制文件,也可以是任何Linux下可执行的脚本文件。
用fork函数创建子进程后,子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程完全由新程序代换,而新程序则从其 main函数开始执行。因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用另一个新程序替换了当前进程的正文、数据、堆和栈段。有六种不同的exec函数可供使用,它们常常被统称为exec函数。这些exec函数都是UNIX进程控制原语。用fork可以创建新进程,用exec可以执行新的程序。exit函数和两个wait函数处理终止和等待终止。这些是我们需要的基本的进程控制原语。
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
其中只有execve是真正意义上的系统调用,其它都是在此基础上经过包装的库函数。“l”表示传递逐个列举,“v”表示将所有参数构造成指针数组传递。
网络编程
一、基础知识
1. 怎么唤醒被阻塞的socket线程?
给阻塞所缺的资源。
2. 简述DNS进行域名解析的过程
首先,客户端发出DNS 请求翻译IP地址或主机名。DNS服务器在收到客户机的请求后:
(1)检查DNS服务器的缓存,若查到请求的地址或名字,即向客户机发出应答信息;
(2)若没有查到,则在数据库中查找,若查到请求的地址或名字,即向客户机发出应答信息;
(3)若没有查到,则将请求发给根域DNS服务器,并依序从根域查找顶级域,由顶级查找二级域,二级域查找三级,直至找到要解析的地址或名字,即向客户机所在网络的DNS服务器发出应答信息,DNS 服务器收到应答后先在缓存中存储,然后,将解析结果发给客户机。
(4)若没有找到,则返回错误信息。
3. TCP和UDP的区别和各自适用的场景
1)TCP和UDP区别
a)连接
TCP是面向连接的传输层协议,即传输数据之前必须先建立好连接。
UDP无连接。
b)服务对象
TCP是点对点的两点间服务,即一条TCP连接只能有两个端点;
UDP支持一对一,一对多,多对一,多对多的交互通信。
c)可靠性
TCP是可靠交付:无差错,不丢失,不重复,按序到达。
UDP是尽最大努力交付,不保证可靠交付。
d)拥塞控制,流量控制
TCP有拥塞控制和流量控制保证数据传输的安全性。
UDP没有拥塞控制,网络拥塞不会影响源主机的发送效率。
e)报文长度
TCP是动态报文长度,即TCP报文长度是根据接收方的窗口大小和当前网络拥塞情况决定的。
UDP面向报文,不合并,不拆分,保留上面传下来报文的边界。
f)首部开销
TCP首部开销大,首部20个字节。
UDP首部开销小,8字节。(源端口,目的端口,数据长度,校验和)
2)TCP和UDP适用场景
TCP 是可靠的但传输速度慢,UDP 是不可靠的但传输速度快。因此在选用具体协议通信时,应该根据通信数据的要求而决定。
若通信数据完整性需让位与通信实时性,则应该选用TCP 协议(如文件传输、重要状态的更新等);反之,则使用 UDP 协议(如视频传输、实时通信等)。
4. socket编程中服务器端和客户端主要用到哪些函数
1)基于TCP的socket:
1、服务器:
创建套接字:socket()
绑定本机地址和端口:bind()
监听,设置允许的最大连接数,listen()
创建通信套接字:accept()
收发数据, send()和recv(),或者read()和write()
关闭套接字close()
2、客户端程序:
创建一个socket,用函数socket()
设置要连接的对方的IP地址和端口等属性
连接服务器,用函数connect()
收发数据,用函数send()和recv(),或read()和write()
关闭网络连接close()
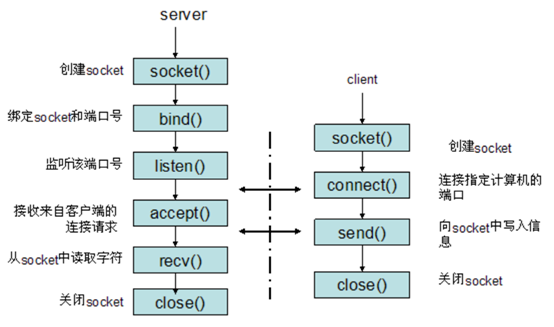
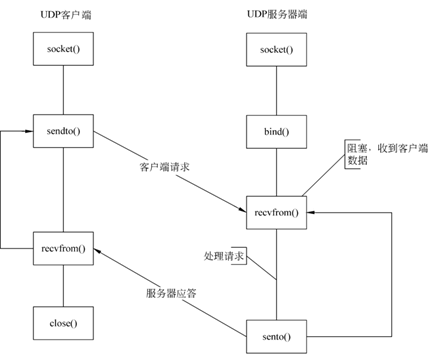
2)基于UDP的socket:
1、服务器
建立套接字文件描述符,使用函数socket(),生成套接字文件描述符。
设置服务器地址和侦听端口,初始化要绑定的网络地址结构。
绑定侦听端口,使用bind()函数,将套接字文件描述符和一个地址类型变量进行绑定。
接收客户端的数据,使用recvfrom()函数接收客户端的网络数据。
向客户端发送数据,使用sendto()函数向服务器主机发送数据。
关闭套接字,使用close()函数释放资源。
2、客户端流程
建立套接字文件描述符,socket()。
设置服务器地址和端口,struct sockaddr。
向服务器发送数据,sendto()。
接收服务器的数据,recvfrom()。
关闭套接字,close()。
5. 如何设计server,使得能够接收多个客户端的请求
多线程,线程池,IO复用。
6. TCP、UDP模型以及每层的协议?
1)网络体系结构即指网络的层次结构和每层所使用协议的集合。
2)OSI模型:
a)物理层:
通过媒介传输比特,确定机械及电气规范,传输单位为bit,主要包括的协议为:IEE802.3 CLOCK RJ45
b)数据链路层:
将比特组装成帧和点到点的传递,传输单位为帧,主要包括的协议为MAC VLAN PPP
c)网络层:
负责数据包从源到宿的传递和网际互连,传输单位为包,主要包括的协议为IP ARP ICMP
d)传输层:
提供端到端的可靠报文传递和错误恢复,传输单位为报文,主要包括的协议为TCP UDP
e)会话层:
建立、管理和终止会话,传输单位为SPDU,主要包括的协议为RPC NFS
f)表示层:
对数据进行翻译、加密和压缩,传输单位为PPDU,主要包括的协议为JPEG ASII
g)应用层:
允许访问OSI环境的手段,传输单位为APDU,主要包括的协议为FTP HTTP DNS
3)TCP/IP 模型:
a)网络接口层:MAC VLAN
b)网络层:IP ARP ICMP
c)传输层:TCP UDP
d)应用层:HTTP DNS SMTP
7. TCP与UDP的异同?
1)共同点:都是传输层协议
2)TCP:面向连接,用于数据的可靠传输【可靠性传输】(流式套接字);
UDP:无连接,数据传输不可靠【高效率传输】(数据报套接字)
8. 套接字类型
流式套接字(SOCK_STREAM)【TCP】
数据报套接字(SOCK_DARAM)【UDP】
原始套接字()SOCK_RAM
9. 什么是高可靠通信?
数据传输无错误、没有丢失、没有失序、数据无重复到达。
10. ARP与RARP的区别?
ARP是解决同一个局域网上的主机或路由器的IP地址和硬件地址的映射问题。【地址解析协议——根据IP地址获取物理地址】
RARP是解决同一个局域网上的主机或路由器的硬件地址和IP地址的映射问题。【反向地址转换协议】
11. TCP怎么保证可靠性,简述一下TCP建立连接和断开连接的过程以及time_wait状态
1)TCP保证可靠性:
a)序列号、确认应答、超时重传
数据到达接收方,接收方需要发出一个确认应答,表示已经收到该数据段,并且确认序号会说明了它下一次需要接收的数据序列号。如果发送发迟迟未收到确认应答,那么可能是发送的数据丢失,也可能是确认应答丢失,这时发送方在等待一定时间后会进行重传。这个时间一般是2*RTT(报文段往返时间)+一个偏差值。
b)窗口控制与高速重发控制/快速重传(重复确认应答)
TCP会利用窗口控制来提高传输速度,意思是在一个窗口大小内,不用一定要等到应答才能发送下一段数据,窗口大小就是无需等待确认而可以继续发送数据的最大值。如果不使用窗口控制,每一个没收到确认应答的数据都要重发。
使用窗口控制,如果数据段1001-2000丢失,后面数据每次传输,确认应答都会不停地发送序号为1001的应答,表示我要接收1001开始的数据,发送端如果收到3次相同应答,就会立刻进行重发;但还有种情况有可能是数据都收到了,但是有的应答丢失了,这种情况不会进行重发,因为发送端知道,如果是数据段丢失,接收端不会放过它的,会疯狂向它提醒......
c)拥塞控制
如果把窗口定的很大,发送端连续发送大量的数据,可能会造成网络的拥堵(大家都在用网,你在这狂发,吞吐量就那么大,当然会堵),甚至造成网络的瘫痪。所以TCP在为了防止这种情况而进行了拥塞控制。
慢启动:定义拥塞窗口,一开始将该窗口大小设为1,之后每次收到确认应答(经过一个rtt),将拥塞窗口大小*2。
拥塞避免:设置慢启动阈值,一般开始都设为65536。拥塞避免是指当拥塞窗口大小达到这个阈值,拥塞窗口的值不再指数上升,而是加法增加(每次确认应答/每个rtt,拥塞窗口大小+1),以此来避免拥塞。
将报文段的超时重传看做拥塞,则一旦发生超时重传,我们需要先将阈值设为当前窗口大小的一半,并且将窗口大小设为初值1,然后重新进入慢启动过程。
快速重传:在遇到3次重复确认应答(高速重发控制)时,代表收到了3个报文段,但是这之前的1个段丢失了,便对它进行立即重传。
然后,先将阈值设为当前窗口大小的一半,然后将拥塞窗口大小设为慢启动阈值+3的大小。
这样可以达到:在TCP通信时,网络吞吐量呈现逐渐的上升,并且随着拥堵来降低吞吐量,再进入慢慢上升的过程,网络不会轻易的发生瘫痪。
2)TCP建立连接和断开连接的过程:
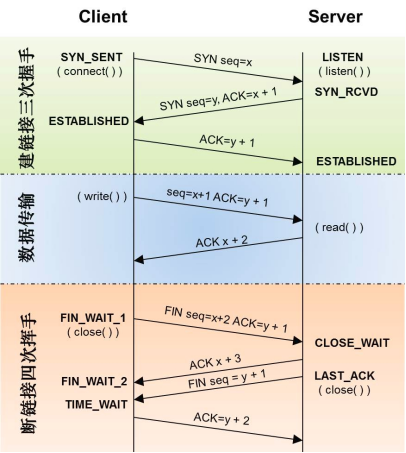
a)TCP连接(三次握手)过程:
第一次握手—— 客户端A:发送SYN连接报文,序列号为x,进入SYNC-SENT状态。
第二次握手—— 服务端B:发送SYN连接确认报文(SYN=1,ACK = 1),序列号为y(seq = y),确认报文x(ack = x + 1),进入SYNC-RCVD状态。
第三次握手—— 客户端A:发送ACK确认报文(ACK = 1),序列号为x+1(seq = x + 1),确认报文y+1(ack = y + 1),进入ESTABLISHED状态。
服务器B:收到后进入ESTABLISHED状态。
2)三次握手原因(为什么两次不可以,不用四次):
1、三次握手是为了防止,客户端的请求报文在网络滞留,客户端超时重传了请求报文,服务端建立连接,传输数据,释放连接之后,服务器又收到了客户端滞留的请求报文,建立连接一直等待客户端发送数据。
2、服务器对客户端的请求进行回应(第二次握手)后,就会理所当然的认为连接已建立,而如果客户端并没有收到服务器的回应呢?此时,客户端仍认为连接未建立,服务器会对已建立的连接保存必要的资源,如果大量的这种情况,服务器会崩溃。
3、两次不可以:
tcp是全双工通信,两次握手只能确定单向数据链路是可以通信的,并不能保证反向的通信正常
4、不用四次:
本来握手应该和挥手一样都是需要确认两个方向都能联通的,本来模型应该是:
1.客户端发送syn0给服务器
2.服务器收到syn0,回复ack(syn0+1)
3.服务器发送syn1
4.客户端收到syn1,回复ack(syn1+1)
因为tcp是全双工的,上边的四部确认了数据在两个方向上都是可以正确到达的,但是2,3步没有没有上下的联系,可以将其合并,加快握手效率,所有就变成了3步握手。
b) TCP释放(四次挥手)过程:
第一次挥手—— 服务端A:发送FIN报文(FIN = 1),序列号为u(seq = u),进入FIN-WAIT 1状态。
第二次挥手—— 客户端B:发送ACK确认报文(ACK = 1),序列号为v(seq = v),确认报文u(ack = u + 1),进入CLOSE-WAIT状态,继续传送数据。服务端A:收到上述报文进入FIN-WAIT2状态,继续接受B传输的数据。
第三次挥手—— 客户端B:数据传输完毕后,发送FIN报文(FIN = 1,ACK = 1),序列号为w(seq = w),确认报文u(ack = u + 1),进入LAST-ACK状态。
第四次挥手—— 服务端A:发送ACK确认报文(ACK = 1),序列号为u+1(seq = u + 1),确认报文w(ack = w + 1),进入TIME-WAIT状态,等待2MSL(最长报文段寿命),进入CLOSED状态。
客户端B:收到后上述报文后进入CLOSED状态。
3)四次挥手的原因?
1、当客户端确认发送完数据且知道服务器已经接收完了,想要关闭发送数据口(当然确认信号还是可以发),就会发FIN给服务器。
2、服务器收到客户端发送的FIN,表示收到了,就会发送ACK回复。
3、但这时候服务器可能还在发送数据,没有想要关闭数据口的意思,所以服务器的FIN与ACK不是同时发送的,而是等到服务器数据发送完了,才会发送FIN给客户端。
4、客户端收到服务器发来的FIN,知道服务器的数据也发送完了,回复ACK, 客户端等待2MSL以后,没有收到服务器传来的任何消息,知道服务器已经收到自己的ACK了,客户端就关闭链接,服务器也关闭链接了。
3)2MSL意义:
1、保证最后一次握手报文能到B,能进行超时重传。
2、2MSL后,这次连接的所有报文都会消失,不会影响下一次连接。
12. IP地址以及MAC地址作用
MAC地址是一个硬件地址,用来定义网络设备的位置,主要由数据链路层负责。
IP地址是IP协议提供的一种统一的地址格式,为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
13. 请问server端监听端口,但还没有客户端连接进来,此时进程处于什么状态?
这个需要看服务端的编程模型,如果如上一个问题的回答描述的这样,则处于阻塞状态,如果使用了epoll,select等这样的io复用情况下,处于运行状态。
二、网络协议
1. 常用的网络协议
1)TCP/IP协议
Internet最基本的协议、Internet国际互联网络的基础,由网络层的IP协议和传输层的TCP协议组成。
2)NETBEUI协议( NetBIOS用户扩展接口协议)
NETBEUI是为IBM开发的非路由协议,用于携带NETBIOS通信。NETBEUI缺乏路由和网络层寻址功能,既是其最大的优点,也是其最大的缺点。因为它不需要附加的网络地址和网络层头尾,所以很快并很有效且适用于只有单个网络或整个环境都桥接起来的小工作组环境。
因为不支持路由,所以NETBEUI永远不会成为企业网络的主要协议。NETBEUI帧中唯一的地址是数据链路层媒体访问控制(MAC)地址,该地址标识了网卡但没有标识网络。路由器靠网络地址将帧转发到最终目的地,而NETBEUI帧完全缺乏该信息。
网桥负责按照数据链路层地址在网络之间转发通信,但是有很多缺点。因为所有的广播通信都必须转发到每个网络中,所以网桥的扩展性不好。NETBEUI特别包括了广播通信的记数并依赖它解决命名冲突。一般而言,桥接NETBEUI网络很少超过100台主机。
3)IPX/SPX(分组交换/顺序交换)
与NetBEUI形成鲜明区别的是IPX/SPX比较庞大,在复杂环境下具有很强的适应性。这是因为IPX/SPX在设计一开始就考虑了网段的问题,因此它具有强大的路由功能,适合于大型网络使用。当用户端接入NetWare服务器时,IPX/SPX及其兼容协议是最好的选择。但在非Novell网络环境中,一般不使用IPX/SPX。
4)HTTP(超文本传输协议)
HTTP是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII码形式给出;而消息内容则具有一个类似MIME的格式。
1)HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,
是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议。
是一个基于TCP/IP通信协议来传递数据(HTML 文件,图片文件,查询结果等)。
是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
2)HTTP协议特点
1、简单快速:
客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:
HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3、无连接:
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4、无状态:
HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5、支持B/S及C/S模式。
6、默认端口80
7、基于TCP协议
3)HTTP过程概述:
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
4)HTTP 请求/响应的步骤如下:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.baidu.com。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
5)举例:
在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1、浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口80,和服务器建立TCP连接;
3、浏览器发出读取文件(URL中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP连接;
6、浏览器将该 html 文本并显示内容;
http1.1相比1.0有如下几点不同:
1.默认支持长连接;
2.带宽优化,并支持断点续传;
3.新增例如ETag,If-None-Match等更多的缓存控制策略;
4.Host头域;
5.新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除;
http2.0与1.1相比有如下几点不同:
1.多路复用,可以做到在一个连接并行的处理多个请求;
2.header压缩;
3.服务端推送;
4.解析格式不同。HTTP1.0和1.1的解析是基于文本,2.0的协议解析采用二进制格式,实现方便且健壮;
5)HTTPS(超文本传输安全协议):
HTTPS,是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。 它是一个URI scheme(抽象标识符体系),句法类同http:体系。用于安全的HTTP数据传输。
2. 请回答一下HTTP和HTTPS的区别,以及HTTPS有什么优缺点?
1)区别
a)HTTP协议是以明文的方式在网络中传输数据,而HTTPS协议传输的数据则是经过TLS加密后的,HTTPS具有更高的安全性
b)HTTPS在TCP三次握手阶段之后,还需要进行SSL 的handshake,协商加密使用的对称加密密钥
c)HTTPS协议需要服务端申请证书,浏览器端安装对应的根证书
d)HTTP协议端口是80,HTTPS协议端口是443
2)HTTPS优点:
a)HTTPS传输数据过程中使用密钥进行加密,所以安全性更高
b)HTTPS协议可以认证用户和服务器,确保数据发送到正确的用户和服务器
3)HTTPS缺点:
a)HTTPS握手阶段延时较高
由于在进行HTTP会话之前还需要进行SSL握手,因此HTTPS协议握手阶段延时增加
b)HTTPS部署成本高
一方面HTTPS协议需要使用证书来验证自身的安全性,所以需要购买CA证书;另一方面由于采用HTTPS协议需要进行加解密的计算,占用CPU资源较多,需要的服务器配置或数目高
3. 搜索baidu,会用到计算机网络中的什么层?每层是干什么的?
浏览器中输入URL
浏览器要将URL解析为IP地址,解析域名就要用到DNS协议,首先主机会查询DNS的缓存,如果没有就给本地DNS发送查询请求。DNS查询分为两种方式,一种是递归查询,一种是迭代查询。如果是迭代查询,本地的DNS服务器,向根域名服务器发送查询请求,根域名服务器告知该域名的一级域名服务器,然后本地服务器给该一级域名服务器发送查询请求,然后依次类推直到查询到该域名的IP地址。DNS服务器是基于UDP的,因此会用到UDP协议。
得到IP地址后,浏览器就要与服务器建立一个http连接。
因此要用到http协议,http协议报文格式上面已经提到。http生成一个get请求报文,将该报文传给TCP层处理,所以还会用到TCP协议。如果采用https还会使用https协议先对http数据进行加密。TCP层如果有需要先将HTTP数据包分片,分片依据路径MTU和MSS。TCP的数据包然后会发送给IP层,用到IP协议。IP层通过路由选路,一跳一跳发送到目的地址。当然在一个网段内的寻址是通过以太网协议实现(也可以是其他物理层协议,比如PPP,SLIP),以太网协议需要直到目的IP地址的物理地址,有需要ARP协议。
其中:
1、DNS协议,http协议,https协议属于应用层
应用层是体系结构中的最高层。应用层确定进程之间通信的性质以满足用户的需要。这里的进程就是指正在运行的程序。应用层不仅要提供应用进程所需要的信息交换和远地操作,而且还要作为互相作用的应用进程的用户代理,来完成一些为进行语义上有意义的信息交换所必须的功能。应用层直接为用户的应用进程提供服务。
2、TCP/UDP属于传输层
传输层的任务就是负责主机中两个进程之间的通信。因特网的传输层可使用两种不同协议:即面向连接的传输控制协议TCP,和无连接的用户数据报协议UDP。面向连接的服务能够提供可靠的交付,但无连接服务则不保证提供可靠的交付,它只是“尽最大努力交付”。这两种服务方式都很有用,备有其优缺点。在分组交换网内的各个交换结点机都没有传输层。
3、IP协议,ARP协议属于网络层
网络层负责为分组交换网上的不同主机提供通信。在发送数据时,网络层将运输层产生的报文段或用户数据报封装成分组或包进行传送。在TCP/IP体系中,分组也叫作IP数据报,或简称为数据报。网络层的另一个任务就是要选择合适的路由,使源主机运输层所传下来的分组能够交付到目的主机。
4、数据链路层
当发送数据时,数据链路层的任务是将在网络层交下来的IP数据报组装成帧,在两个相邻结点间的链路上传送以帧为单位的数据。每一帧包括数据和必要的控制信息(如同步信息、地址信息、差错控制、以及流量控制信息等)。控制信息使接收端能够知道—个帧从哪个比特开始和到哪个比特结束。控制信息还使接收端能够检测到所收到的帧中有无差错。
5、物理层
物理层的任务就是透明地传送比特流。在物理层上所传数据的单位是比特。传递信息所利用的一些物理媒体,如双绞线、同轴电缆、光缆等,并不在物理层之内而是在物理层的下面。因此也有人把物理媒体当做第0层。
C++
一、与C的区别
1. C++和C的区别
1)设计思想上:
C++是面向对象(以事务为中心。一切事物皆对象,通过面向对象的方式,将现实世界的事物抽象成对象)的语言。
C是面向过程(以过程为中心,把分析解决问题的步骤流程以函数的形式一步步设
计实现。
2)语法上:
C++具有封装、继承和多态三种特性;
C++相比C,增加多许多类型安全的功能,比如强制类型转换
C++支持范式编程,比如模板类、函数模板等;
2. 什么是面向对象?
面向对象可以理解成对待每一个问题,都是首先要确定这个问题由几个部分组成,而每一个部分其实就是一个对象。然后再分别设计这些对象,最后得到整个程序。传统的程序设计多是基于功能的思想来进行考虑和设计的,而面向对象的程序设计则是辈于对象的角度来考虑问题。这样做能够使得程序更加的简洁清晰。
说明:编程中接触最多的“面向对象编程技术”仅仅是面向对象技术中的一个组成部分。发挥面向对象技术的优势是一个综合的技术问题,不仅需要面向对象的分析,设计和编程技术,而且需要借助必要的建模和开发工具。
二、关键字
2. 说说你了解的类型转换
1)reinterpret_cast:可以用于任意类型的指针之间的转换,对转换的结果不做任何保证
2)dynamic_cast:这种其实也是不被推荐使用的,更多使用static_cast,dynamic本身只能用于存在虚函数的父子关系的强制类型转换,对于指针,转换失败则返回nullptr,对于引用,转换失败会抛出异常
3)const_cast:对于未定义const版本的成员函数,我们通常需要使用const_cast来去除const引用对象的const,完成函数调用。另外一种使用方式,结合static_cast,可以在非const版本的成员函数内添加const,调用完const版本的成员函数后,再使用const_cast去除const限定。
4)static_cast:完成基础数据类型;同一个继承体系中类型的转换;任意类型与空指针类型void* 之间的转换。
3. 、在C++ 程序中调用被 C 编译器编译后的函数,为什么要加 extern “C”?
答:C++语言支持函数重载,C 语言不支持函数重载。函数被C++编译后在库中的名字
与C 语言的不同。假设某个函数的原型为: void foo(int x, int y);
该函数被C 编译器编译后在库中的名字为_foo,而C++ 编译器则会产生像 _foo_int_int 之类的名字。
C++提供了C 连接交换指定符号extern“C”来解决名字匹配问题。
4. 如果同时定义了两个函数,一个带const,一个不带,会有问题吗?
不会,这相当于函数的重载。
5. const修饰成员函数的目的是什么?
表明函数调用不会对对象做出任何更改,事实上,如果确认不会对对象做更改,就应该为函数加上const限定,这样无论const对象还是普通对象都可以调用该函数。
6. C++中struct和class的异同
1)在C++中,可以用struct和class定义类,都可以继承。
2)区别:
a)structural的默认继承权限和默认访问权限是public,而class的默认继承权限和默认访问权限是private。
b)class还可以定义模板类形参。比如template <class T, int i>。
7. 引用和指针以及他们之间的区别?
1)定义:
a)引用:
引用的声明方法:类型标识符 &引用名=目标变量名;
引用引入了对象的一个同义词。定义引用的表示方法与定义指针相似,只是用&代替了*。
b)指针:
指针利用地址,它的值直接指向存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。因此,将地址形象化的称为“指针”。意思是通过它能找到以它为地址的内存单元。
2)区别:
1、指针有自己的一块空间,而引用只是一个别名;
2、使用sizeof看一个指针的大小是4字节(32bit),而引用则是被引用对象的大小;
3、指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象的引用;
4、作为参数传递时,指针需要被解引用才可以对对象进行操作,而直接对引用的修改都会改变引用所指向的对象;
5、可以有const指针,但是没有const引用;
6、指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能 被改变;
7、指针可以有多级指针(**p),而引用至于一级;
8、指针和引用使用++运算符的意义不一样;
9、如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露。
8. 常引用的作用
常引用的引入主要是为了避免使用变量的引用时,在不知情的情况下改变变量的值。常引用主要用于定义一个普通变量的只读属性的别名、作为函数的传入形参,避免实参在调用函数中被意外的改变。说明:很多情况下,需要用常引用做形参,被引用对象等效于常对象,不能在函数中改变实参的值,这样的好处是有较高的易读性和较小的出错率。
三、类和函数
1. C++如何处理返回值?
生成一个临时变量,把它的引用作为函数参数传入函数内。
2. 多态实现的原理(虚函数表具体是怎样实现运行时多态的)
子类若重写父类虚函数,虚函数表中,该函数的地址会被替换,对于存在虚函数的类的对象,在VS中,对象的对象模型的头部存放指向虚函数表的指针,通过该机制实现多态。虚函数是实现多态的基础。
编译器发现一个类中有虚函数,便会立即为此类生成虚函数表vtable。虚函数表的各表项为指向对应虚函数的指针。编译器还会在此类中隐含插入一个指针vptr(i对vc编译器来说,它插在类的第一个位置上)指向虚函数表。调用此类的构造函数时,在类的构造函数中,编译器会隐含执行vptr与vtable的关联代码,将yptr 指向对应的vtable,将类与此类的table联系了起来。另外在调用类的构造函数时,指向基础类的指针此时已经变成指向具体的类的this 指针,这样依靠此this 指针即可得到正确的vtable,。
如此才能真正与函数体进行连接,这就是动态联编,实现多态的基本原理。
3. 虚函数、纯虚函数、虚拟继承的关系和区别
1)虚函数:
C++的虚函数主要作用是”运行时多态”,父类中提供虚函数的实现,为子类提供默认的函数实现。
子类可以重写父类的虚函数实现子类的特殊化。
2)纯虚函数
在基类中不能对虚函数给出有意义的实现,而把它声明为纯虚函数,它的实现留给该基类的派生类去做。
3)普通函数:
普通函数是静态编译的,没有运行时多态,只会根据指针或引用的“字面值”类对象,调用自己的普通函数。
普通函数是父类为子类提供的“强制实现”。因此,在继承关系中,子类不应该重写父类的普通函数,因为函数的调用至于类对象的字面值有关。
4)虚函数和纯虚函数的区别
1. 虚函数和纯虚函数可以定义在同一个类(class)中,含有纯虚函数的类被称为抽象类(abstract class),而只含有虚函数的类(class)不能被称为抽象类(abstract class)。
2. 虚函数可以被直接使用,也可以被子类(sub class)重载以后以多态的形式调用,而纯虚函数必须在子类(sub class)中实现该函数才可以使用,因为纯虚函数在基类(base class)只有声明而没有定义。
3. 虚函数和纯虚函数都可以在子类(sub class)中被重载,以多态的形式被调用。
4. 虚函数和纯虚函数通常存在于抽象基类(abstract base class -ABC)之中,被继承的子类重载,目的是提供一个统一的接口。
5. 虚函数的定义形式:virtual {method body}
纯虚函数的定义形式:virtual { } = 0;
在虚函数和纯虚函数的定义中不能有static标识符,原因很简单,被static修饰的函数在编译时候要求前期bind,然而虚函数却是动态绑定(run-time bind),而且被两者修饰的函数生命周期(life recycle)也不一样。
6. 虚函数必须实现,如果不实现,编译器将报错,错误提示为:
error LNK****: unresolved external symbol "public: virtual void __thiscall
ClassName::virtualFunctionName(void)"
7. 对于虚函数来说,父类和子类都有各自的版本。由多态方式调用的时候动态绑定。
8. 实现了纯虚函数的子类,该纯虚函数在子类中就编程了虚函数,子类的子类即孙子类可以覆盖。该虚函数,由多态方式调用的时候动态绑定。
9. 虚函数是C++中用于实现多态(polymorphism)的机制。核心理念就是通过基类访问派生类定义的函数。
10. 多态性指相同对象收到不同消息或不同对象收到相同消息时产生不同的实现动作。C++支持两种多态性:编译时多态性,运行时多态性。
a.编译时多态性:通过重载函数实现
b 运行时多态性:通过虚函数实现。
11. 如果一个类中含有纯虚函数,那么任何试图对该类进行实例化的语句都将导致错误的产生,因为抽象基类(ABC)是不能被直接调用的。必须被子类继承重载以后,根据要求调用其子类的方法。
4. 析构函数的作用
1)析构函数与构造函数对应,当对象结束其生命周期,如对象所在的函数已调用完毕时,系统会自动执行析构函数。
2)析构函数名也应与类名相同,只是在函数名前面加一个位取反符~,例如~stud( ),以区别于构造函数。它没有任何参数,也没有返回值(包括void类型)。只能有一个析构函数,不能重载。
3)如果用户没有编写析构函数,编译系统会自动生成一个缺省的析构函数(即使自定义了析构函数,编译器也总是会为我们合成一个析构函数,并且如果自定义了析构函数,编译器在执行时会先调用自定义的析构函数再调用合成的析构函数),它也不进行任何操作。所以许多简单的类中没有用显式的析构函数。
4)如果一个类中有指针,且在使用的过程中动态的申请了内存,那么最好显示构造析构函数在销毁类之前,释放掉申请的内存空间,避免内存泄漏。
5)类析构顺序:1)派生类本身的析构函数;2)对象成员析构函数;3)基类析构函数。
4. 虚函数和多态
1)
a)概念:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果,这就是多态性。简单的说就是:用基类的引用指向子类的对象。
b)作用:
i)应用程序不必为每一个派生类编写功能调用,只需要对抽象基类进行处理即可。大大提高程序的可复用性。//继承
ii)派生类的功能可以被基类的方法或引用变量所调用,这叫向后兼容,可以提高可扩充性和可维护性。 //多态的真正作用
2)多态的实现主要分为静态多态和动态多态。
a)静态多态主要是重载,在编译的时候就已经确定;
b)动态多态是用虚函数机制实现的,在运行期间动态绑定。
举个例子:一个父类类型的指针指向一个子类对象时候,使用父类的指针去调用子类中重写了的父类中的虚函数的时候,会调用子类重写过后的函数,在父类中声明为加了virtual关键字的函数,在子类中重写时候不需要加virtual也是虚函数。
3)虚函数的实现:在有虚函数的类中,类的最开始部分是一个虚函数表的指针,这个指针指向一个虚函数表,表中放了虚函数的地址,实际的虚函数在代码段(.text)中。当子类继承了父类的时候也会继承其虚函数表,当子类重写父类中虚函数时候,会将其继承到的虚函数表中的地址替换为重新写的函数地址。使用了虚函数,会增加访问内存开销,降低效率。
5、静态函数和虚函数的区别
1)静态函数在编译的时候就已经确定运行时机,
虚函数在运行的时候动态绑定。
2)虚函数因为用了虚函数表(是个指针,32位机器占4个字节)机制,调用的时候会增加一次内存开销
6. 为什么析构函数必须是虚函数?为什么C++默认的析构函数不是虚函数?
1)将可能会被继承的父类的析构函数设置为虚函数,可以保证当我们new一个子类,然后使用基类指针指向该子类对象,释放基类指针时可以释放掉子类的空间,防止内存泄漏。
2)C++默认的析构函数不是虚函数是因为虚函数需要额外的虚函数表和虚表指针,占用额外的内存。而对于不会被继承的类来说,其析构函数如果是虚函数,就会浪费内存。因此C++默认的析构函数不是虚函数,而是只有当析构函数需要当作父类时,才设置为虚函数。
7. 重载、重写、隐藏、覆盖
1)重载:两个函数名相同,但是参数列表不同(个数,类型),返回值类型没有要求,在同一作用域中
2)重写:子类继承了父类,父类中的函数是虚函数,在子类中重新定义了这个虚函数(在子类中重新定义了父类中的虚函数),这种情况是重写( 派生类中存在重新定义的函数。其函数名,参数列表,返回值类型,所有都必须同基类中被重写的函数一致。只有函数体不同(花括号内),派生类调用时会调用派生类的重写函数,不会调用被重写函数。重写的基类中被重写的函数必须有virtual修饰)【子类和父类之间】
3)隐藏: 是指派生类的函数屏蔽了与其同名的基类函数,注意只要同名函数,不管参数列表是否相同,基类函数都会被隐藏。【基类和派生类之间】
*区别:
1)重写和重载的区别:
a)范围:被重写的函数和重写的函数在两个类中,而被重载的函数和重载的函数在一个类中。
b)参数:被重写的函数和重写的函数的参数列表一定相同,而被重载的函数和重载的函数参数列表一定不同。
c)是否virtual:重写的基类中被重写的函数必须要有virtual修饰(重写的定义),而重载函数和被重载的函数可以被virtual修饰,也可以没有。
2)隐藏和重写、重载的区别:
a)与重载的范围不同:隐藏和重写一样,在两个不同的类中。
b)参数不同:隐藏函数和被隐藏函数的参数列表可以相同也可以不同,但是函数名一定要相同。当参数不同时,无论基类中的参数是否被virtual修饰,基类的函数都是被隐藏的,而不是被重写。
8. 友元函数
1)定义:
友元函数是指某些虽然不是类成员却能够访问类的所有成员的函数。
2)性质:
a)一个友元函数可以同时定义为两个类的友元函数
b)友元函数既可以在类的内部,也可以在类的外部定义,必须在类内先声明。
c)在外部定义友元函数时,不必加关键字friend。
9. C++的空类有哪些成员函数
缺省构造函数
缺省析构函数
缺省拷贝构造函数
缺省赋值运算符
缺省取址运算符 const
*只有当实际使用这些函数的时候编译器才会去定义他们。
10. 谈谈你对拷贝构造函数和赋值运算符的理解
拷贝构造函数和赋值运算符有以下两个不同之处:
1) 拷贝构造函数生成新的类对象,而赋值运算符不能。
2) 由于拷贝构造函数是直接构造一个新的类的对象,所以在初始化这个对象之前不用检验源对象是否和新建对象相同。而赋值运算符则需要这个操作,另外赋值运算符中如果原来的对象中有内存分配的要先把内存释放掉。
*当有类中有指针类型的成员变量时,一定要重写拷贝构造函数和赋值运算符
11.构造函数能不能是虚函数
构造函数不能是虚函数。而且不能在构造函数中调用虚函数,因为那样实际执行的是父类的对应函数,因为自己还没有构造好。构函数可以是虚函激,而且,在一个复杂类结构中,这往往是必须的。析构函数也可以是纯虚函数,但纯虚析构函数必须有定义体,因为析构函数的调用是在子类中隐含的。
说明:虚函数的动态绑定特性是实现重载的关键技术,动态绑定根据实际的调用情况查询相应类的虚函数表,调用相应的虚函数。
四、指针
*1. 请你介绍一下C++中的智能指针
1)C++里面的四个智能指针:
auto_ptr, 【需要手动释放】(弃用)
shared_ptr, (常用——引用计数法)
weak_ptr,
unique_ptr
其中后三个是c++11支持,并且第一个已经被11弃用。
2)为什么要使用智能指针:
智能指针主要用于管理在堆上分配的内存。它将普通的指针封装为一个栈对象。当栈对象的生存周期结束后,会在析构函数中释放掉申请的内存,从而防止内存泄漏。
因为存在以下这种情况:申请的空间在函数结束时没有释放,造成内存泄漏。使用智能指针可以很大程度上的避免这个问题。因为智能指针就是一个类,当超出了类的作用域时,类会自动调用析构函数,析构函数会自动释放资源。
所以智能指针的作用原理:在函数结束时自动释放内存空间,不需要手动释放内存空间。
C++ 11中最常用的智能指针类型为shared_ptr,它采用引用计数的方法,记录当前内存资源被多少个智能指针引用。该引用计数的内存在堆上分配。当新增一个时引用计数加1,当过期时引用计数减一。只有引用计数为0时,智能指针才会自动释放引用的内存资源。对shared_ptr进行初始化时不能将一个普通指针直接赋值给智能指针,因为一个是指针,一个是类。可以通过make_shared函数或者通过构造函数传入普通指针。并可以通过get函数获得普通指针。
2. 智能指针有没有内存泄露的情况,怎么解决?
1)当两个对象相互使用一个shared_ptr成员变量指向对方,会造成循环引用,使引用计数失效,从而导致内存泄漏。
2)引入了weak_ptr弱指针,weak_ptr的构造函数不会修改引用计数的值,从而不会对对象的内存进行管理,其类似一个普通指针,但不指向引用计数的共享内存,但是其可以检测到所管理的对象是否已经被释放,从而避免非法访问。
五、内存管理
1. C++函数栈空间的最大值
默认是1M,但是可以调整。
ARM
1. 启动代码的作用
启动代码是用来初始化电路以及用来为高级语言写的软件作好运行前准备的一小段汇编语言,是任何处理器上电复位时的程序运行入口点。比如,刚上电的过程中,我们的 PC 机会对系统的一个运行频率进行锁定在一个固定的值,这个设计频率的过程就是在汇编源代码中进行的,也就是在启动代码中进行的。
2. 内核的七种工作模式
1、用户模式(user):正常程序执行模式;
2、系统模式(System):用于运行特权级操作系统任务;
3、特权模式(Supervisor):复位和软中断指令会进入该模式;
3、快速中断模式(FIQ):高优先级的中断产生会进入该种模式,用于高速通道传输;
4、外部中断模式(IRQ):低优先级中断产生会进入该模式,用于普通的中断处理;
5、数据访问中止模式(Abort):当存储异常时会进入该模式;
6、未定义指令中止模式(Undefined):执行未定义指令会进入该模式;
8、监控模式(Monitor):可以在安全模式和非安全模式之间切换;操作系统
3. Arm的基本数据类型:
字(Word):在ARM体系结构中,字的长度为32位。
半字(Half-Word):在ARM体系结构中,半字的长度为16位。
字节(Byte):在ARM体系结构中,字节的长度为8位。
双字节(DoubleWord):64位
4. ARM的存储格式
大端存储
小端存储
5. ARM的5级流水线
一、硬件机制
1. 请介绍一下操作系统中的中断
1)中断是指CPU对系统发生的某个事件做出的一种反应。CPU暂停正在执行的程序,保存现场后自动去执行相应的处理程序,处理完该事件后再返回中断处继续执行原来的程序。
2)分类:
一种是由CPU外部引起的,如I/O中断、时钟中断。
一种是来自CPU内部事件或程序执行中引起的中断。例如程序非法操作,地址越界、浮点溢出)。
一种是在程序中使用了系统调用引起的。
3)中断处理:
一般分为中断响应和中断处理两个步骤,中断响应由硬件实施,中断处理主要由软件实施。
三、其它
1. 操作系统为什么要分内核态和用户态
为了安全性。在cpu的一些指令中,有的指令如果用错,将会导致整个系统崩溃。分了内核态和用户态后,当用户需要操作这些指令时候,内核为其提供了API,可以通过系统调用陷入内核,让内核去执行这些操作。
2. GDB调试用过吗,什么是条件断点
1)GDB调试
GDB 是自由软件基金会(Free Software Foundation)的软件工具之一。它的作用是协助程序员找到代码中的错误。如果没有GDB的帮助,程序员要想跟踪代码的执行流程,唯一的办法就是添加大量的语句来产生特定的输出。但这一手段本身就可能会引入新的错误,从而也就无法对那些导致程序崩溃的错误代码进行分析。
GDB的出现减轻了开发人员的负担,他们可以在程序运行的时候单步跟踪自己的代码,或者通过断点暂时中止程序的执行。此外,他们还能够随时察看变量和内存的当前状态,并监视关键的数据结构是如何影响代码运行的。
2)条件断点
条件断点是当满足条件就中断程序运行,命令:break line-or-function if expr。
例如:(gdb)break 666 if testsize==100
3. 请你来说一说用户态到内核态的转化原理
1)用户态切换到内核态的3种方式
1、系统调用
这是用户进程主动要求切换到内核态的一种方式,用户进程通过系统调用申请操作系统提供的服务程序完成工作。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的ine 80h中断。
2、异常
当CPU在执行运行在用户态的程序时,发现了某些事件不可知的异常,这是会触发由当前运行进程切换到处理此。异常的内核相关程序中,也就到了内核态,比如缺页异常。
3、外围设备的中断
当外围设备完成用户请求的操作之后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条将要执行的指令,转而去执行中断信号的处理程序,如果先执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了有用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
2)切换操作
从出发方式看,可以在认为存在前述3种不同的类型,但是从最终实际完成由用户态到内核态的切换操作上来说,涉及的关键步骤是完全一样的,没有任何区别,都相当于执行了一个中断响应的过程,因为系统调用实际上最终是中断机制实现的,而异常和中断处理机制基本上是一样的,用户态切换到内核态的步骤主要包括:
1、从当前进程的描述符中提取其内核栈的ss0及esp0信息。
2、使用ss0和esp0指向的内核栈将当前进程的cs,eip,eflags,ss,esp信息保存起来,这个过程也完成了由用户栈找到内核栈的切换过程,同时保存了被暂停执行的程序的下一条指令。
3、将先前由中断向量检索得到的中断处理程序的cs,eip信息装入相应的寄存器,开始执行中断处理程序,这时就转到了内核态的程序执行了。
4. 请你说一说用户态和内核态区别
用户态和内核态是操作系统的两种运行级别,两者最大的区别就是特权级不同。用户态拥有最低的特权级,内核态拥有较高的特权级。运行在用户态的程序不能直接访问操作系统内核数据结构和程序。内核态和用户态之间的转换方式主要包括:系统调用,异常和中断。
5. 系统调用是什么,你用过哪些系统调用
1)概念:
在计算机中,系统调用(英语:system call),又称为系统呼叫,指运行在使用者空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供了用户程序与操作系统之间的接口(即系统调用是用户程序和内核交互的接口)。
操作系统中的状态分为管态(核心态)和目态(用户态)。大多数系统交互式操作需求在内核态执行。如设备IO操作或者进程间通信。特权指令:一类只能在核心态下运行而不能在用户态下运行的特殊指令。不同的操作系统特权指令会有所差异,但是一般来说主要是和硬件相关的一些指令。用户程序只在用户态下运行,有时需要访问系统核心功能,这时通过系统调用接口使用系统调用。
应用程序有时会需要一些危险的、权限很高的指令,如果把这些权限放心地交给用户程序是很危险的(比如一个进程可能修改另一个进程的内存区,导致其不能运行),但是又不能完全不给这些权限。于是有了系统调用,危险的指令被包装成系统调用,用户程序只能调用而无权自己运行那些危险的指令。另外,计算机硬件的资源是有限的,为了更好的管理这些资源,所有的资源都由操作系统控制,进程只能向操作系统请求这些资源。操作系统是这些资源的唯一入口,这个入口就是系统调用。
2)系统调用举例:
对文件进行写操作,程序向打开的文件写入字符串“hello world”,open和write都是系统调用。如下:
|
#include<stdio.h> #include<stdlib.h> #include<string.h> #include<errno.h> #include<unistd.h> #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> int main(int argc, char *argv[]) { if (argc<2) return 0; //用读写追加方式打开一个已经存在的文件 int fd = open(argv[1], O_RDWR | O_APPEND); if (fd == -1) { printf("error is %s\n", strerror(errno)); } else { //打印文件描述符号 printf("success fd = %d\n", fd); char buf[100]; memset(buf, 0, sizeof(buf)); strcpy(buf, "hello world\n"); write(fd, buf, strlen(buf)); close(fd); } return 0; } |
还有写数据write,创建进程fork,vfork等都是系统调用。
7.Makefile
8. gdb调试
9. Sqlite3数据库
工具
一、 GDB调试
1. 开始
首先对 .c 文件进行 -g 编译 ——gcc test.c -g -o test
然后开始调试 —— gdb test
2. 选项
查看文件:(gdb)1
设置断点:(gdb)b 6
查看断点情况:(gdb)info 6
运行代码:(gdb)r
查看变量值:(gdb)p n
单步运行:(gdb)n
(gdb)s
恢复程序运行:(gdb)c
帮助:(gdb)help [command]
二、Sqlite3数据库
基础概念:一个数据库文件(.db)有很多张数据表,表分为行(记录/元祖)和列(字段)
1、直接使用的命令
打开数据库:sqlite3 *.db(*.db是文件名)
显示所有命令:sqlite> .help
退出sqlite3:sqlite> .quit
显示当前文件打开的数据库文件:sqlite> .database
显示数据库中所有的表名:sqlite> .tables
c查看表的结构:sqlite> .schema <table_name>
创建新表:sqlite> creat table <table_name> (f1 type1, f2 type2…)
删除表:sqlite> drop table <table_name>
查询表中的所有记录:sqlite> select * from <table_name>
按指定条件查询表中记录:sqlite> select * from <table_name> where <expression>
向表中添加新纪录:sqlite> select * from <table_name> values (value1, value2, …)
按指定的条件删除表中的记录:sqlite> delete from <table_name> where <expression>
更新表中的记录:sqlite> updata <table_name> set <f1=value1>, <f2 = value2>, … where <expression>
在表中添加字段:sqlite> alter table <table> add column <field> <type> default …
sqlite>alter table <table> drop column <field>
在表中删除字段:1)sqlite> create table stu as select no, name, score from student
2) sqlite> drop table student
3) sqlite> alter table stu rname to student
2、编程接口
a)打开数据库:
int sqlite3_open(char *path, sqlite3 **db)
【path:数据库文件路径;
db:指向sqlite句柄的指针;
成功返回0,失败返回错误码(非零值)】
b)关闭数据库
int sqlite3_close(sqlite3 *db)
【成功返回0,失败返回错误码(非零值)】
c)错误信息返回
const char *sqlite3_errmsg(sqlite3 *db)
【返回错误信息】
d)

e)

f)

练习题
一、基本数据类型
1. 请写出 float x与“零值”比较的if 语句
【标准答案】 const float EPSINON = 0.00001;
if ((x >= - EPSINON) && (x <= EPSINON)
//if (x >= -0.00001 && x <= 0.00001)
不可将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”此类形式。
2. 请写出 char *p与“零值”比较的 if 语句
【标准答案】 if ( p == NULL)
if ( p != NULL)
3. 请简述以下两个for 循环的优缺点

二、内存管理
1. 下列程序有什么问题?




*三、算法
1. 实现字符串转换成整数(C库函数【atoi(*str)】)
int myAtoi(char *str) { int i, num = 0; for (i = 0; str[i] != '\0'; i++) if (str[i] >= '0' && str[i] <= '9') num = num * 10 + (str[i] - '0'); if (str[0] == '-') num = -num; return num; }
将一个字符串转换成一个整数,要求不能使用字符串转换整数的库函数。 数值为0或者字符串不是一个合法的数值则返回0
class Solution { public: int StrToInt(string str) { const int length = str.length(); int isNegtive = 1, overValue = 0; int digit = 0, value = 0; if (length == 0) return 0; else { int idx = 0; if (str[0] == '-') { isNegtive = -1; idx = 1; } else if (str[0] == '+') { idx = 1; } for (; idx<length; idx++) { digit = str[idx]-'0'; // overValue表示本轮循环是否会越界 overValue = isNegtive*value - INT_MAX/10 + (((isNegtive+1)/2 + digit > 8) ? 1:0); if (digit<0 || digit>9) return 0; else if (overValue > 0) return 0; value = value*10 + isNegtive*digit; } return value; } } };
2. 整数转换成字符串(非C库函数【itoa(num,*str,10)】)
#include <stdlib.h> int number = 123456; char string[25]; itoa(number, string,1 0);
*四、自定义函数
1. 、编写 strcpy 函数
(1)
char *strcpy(char *strDest, const char *strSrc); { assert((strDest!=NULL) && (strSrc !=NULL)); // 2分 char *address = strDest; // 2分 while( (*strDest++ = * strSrc++) != ‘\0’ ) // 2分 NULL ; return address ; // 2分 }
*assert:1、assert是个宏,函数原型定义在assert.h头文件中。
2、assert的作用是先计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。
3、频繁的调用会极大的影响程序的性能,增加额外的开销。在调试结束后,可以通过在包含#include <assert.h>的语句之前插入 #define NDEBUG 来禁用assert调用,
*abord:立即终止当前进程,产生异常程序终止
进程终止时不会销毁任何对象
(2)strcpy 能把strSrc 的内容复制到strDest,为什么还要char * 类型的返回值?
答:使函数能够支持链式表达式,增加了函数的“附加值”。同样功能的函数,如果能合理地提高的可用性,自然就更加理想。 // 2分
例如 int length = strlen( strcpy( strDest, “hello world”) );
2. 编写类 String 的构造函数、析构函数和赋值函数
已知类 String 的原型为:
class String
{
public:
String(const char *str = NULL); // 普通构造函数
String(const String &other); // 拷贝构造函数
~ String(void); // 析构函数
String & operate =(const String &other); // 赋值函数
private:
char *m_data; // 用于保存字符串
};
请编写 String 的上述4 个函数。
【标准答案】
// String 的析构函数
String::~String(void) // 3 分
{
delete [] m_data;
// 由于m_data 是内部数据类型,也可以写成 delete m_data;
}
// String 的普通构造函数
String::String(const char *str) // 6 分
{
if(str==NULL)
{
m_data = new char[1]; // 若能加 NULL 判断则更好
*m_data = ‘\0’;
}
else
{
int length = strlen(str);
m_data = new char[length+1]; // 若能加 NULL 判断则更好
strcpy(m_data, str);
}
}
// 拷贝构造函数
String::String(const String &other) // 3 分
{
int length = strlen(other.m_data);
m_data = new char[length+1]; // 若能加 NULL 判断则更好
strcpy(m_data, other.m_data);
}
// 赋值函数
String & String::operate =(const String &other) // 13 分
{
// (1) 检查自赋值 // 4 分
if(this == &other)
return *this;
// (2) 释放原有的内存资源 // 3 分
delete [] m_data;
// (3)分配新的内存资源,并复制内容 // 3 分
int length = strlen(other.m_data);
m_data = new char[length+1]; // 若能加 NULL判断则更好
// (4)返回本对象的引用 // 3 分
return *this;
}
*五、数据结构
*1. 单链表反转
class Solution { public: ListNode* ReverseList(ListNode* pHead) { if(pHead == NULL) return NULL; if(pHead -> next == NULL) return pHead; if(pHead -> next -> next == NULL) { pHead -> next -> next = pHead; pHead = pHead->next; pHead->next->next = NULL; return pHead; } ListNode *p,*q,*r; p=pHead; q=p->next; r=q->next; while(r->next!=NULL) { q->next=p; p=q; q=r; r=r->next; } q->next=p; r->next=q; pHead->next=NULL; pHead=r; return pHead; } };
2. 二叉树的第k个结点
给定一棵二叉搜索树,请找出其中的第k小的结点。例如, (5,3,7,2,6, 8)中,按结点数值大小顺序第三小结点的值为4。
class Solution { public: TreeNode* KthNode(TreeNode* pRoot, int k) { if(!pRoot) return nullptr; stack<TreeNode *> res; TreeNode* p =pRoot; while(!res.empty() || p ) { //res是空 and 遍历到空节点 while(p) { res.push(p); p = p->left; } TreeNode* node = res.top(); res.pop(); if((--k)==0) return node; p = node->right; } return nullptr; } };
5. 二叉搜索树的后序遍历
class Solution { public: bool VerifySquenceOfBST(vector<int> sequence) { if (sequence.size() < 1) return false; else if (sequence.size() < 3) return true; else { int idx = sequence.size() - 1; stack<int> bound_min, bound_max; stack<int> roots; roots.push(sequence[idx--]); bound_min.push(INT_MIN); bound_max.push(INT_MAX); for (; idx > -1; idx--) { if (sequence[idx] > sequence[idx+1]) { // 倒序遍历趋势为递增,说明是进入了某个右子树 if (sequence[idx] > bound_max.top()) // 当前元素超越了最大上限约束,这是不合法的 return false; else { // 合法,进入右子树,更新三个栈 bound_min.push(roots.top()); bound_max.push(bound_max.top()); roots.push(sequence[idx]); } } else { // 倒序遍历趋势为递减,说明是进入了某个左子树 if (sequence[idx] < bound_min.top()) { // 当前元素打破了最小下限约束,说明是右子树遍历完了,跳转到兄弟左子树 // 当前元素为兄弟左子树的根,之前右子树节点全部出栈 while (sequence[idx] < bound_min.top()) { bound_min.pop(); bound_max.pop(); roots.pop(); } } else {} // 没有突破下限,说明是右子树不存在,直接进入左子树,不做特殊处理 // 进入左子树,更新三个栈 bound_min.push(bound_min.top()); bound_max.push(roots.top()); roots.push(sequence[idx]); } } return true; } } };
8. 斐波那契数列
大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0)。n<=39
class Solution { public: int Fibonacci(int n) { if(n == 0) { return 0; } else if(n == 1) { return 1; } int sum = 0; int two = 0; int one = 1; for(int i=2;i<=n;i++) { sum = two + one; two = one; one = sum; } return sum; } };
六、嵌入式
1. 编码实现变量的某一位置0或者置1
a |= (0x1<<3);
a &= ~(0x1<<3);
