联合会员
周边
新闻
博问
闪存
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
默叶
博客园
首页
新随笔
联系
订阅
管理
随笔 - 13
文章 - 0
评论 - 0
阅读 -
13711
Python elasticsearch 报错及解决方法
1. ERROR: [1] bootstrap checks failed [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, # discovery.seed_providers, cluster.initial_master_nodes] must be configured
意思应该是:需要设置能够被选择为主节点的节点
在config/elasticsearch.yml中加入: cluster.initial_master_nodes: ["node-1"]
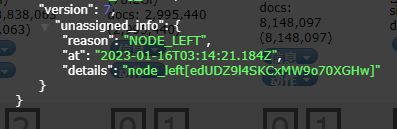
2. ES 分片失败:UNASSIGNED reason为node_left
背景: ES集群中一个节点突然因为运行内存占用大的程序而卡死,导致节点突然脱离集群,在elasticsearch-head中点击灰色分片显示node_lefe
原因: NODE_LEFT :由于承载该分片的节点离开集群导致未分配。
参考文章:
https://www.cnblogs.com/whl-jx911/p/14482749.html
解决办法:创建索引时设置副本数量至少为1,这样即使有一个节点断开,集群也能通过放在其他节点上的副本对分片进行恢复
3.document(s) failed to index... elasticsearch index missing
背景:使用elasticsearch的helpers.bulk方法对数据进行批量写入时,出现运行到bulk位置报:缺失对应的索引数据错误
原因:
bulk需要将格式为data = {"_index": "index_name", "_type": "type", "_source": dict}的字典放入一个数组里再批量写入
而个人在action数组拼接时错误将action.append(data)写成了action.append(line),也就是拼接错了字典,导致数据对不上
4.Document contains at least one immense term in field="" (whose UTF8 encoding is longer than the max length 32766)
翻译过来就是:有一个数据中的某个字段的值太长了,超过了规定的32766限制,field=""会显示是哪个字段的数据过长
解决:缩短某个字段的数据长度,或者干脆舍弃掉这部分数据,例如正常为几千的长度突然出现几十万的长度,很可能是乱码的数据
分类:
数据库 / Elasticsearch
好文要顶
关注我
收藏该文
微信分享
默叶
粉丝 -
1
关注 -
1
+加关注
0
0
升级成为会员
«
上一篇:
elasticsearch 内存分配设置
»
下一篇:
Python elasticsearch 使用心得
posted @
2023-02-28 17:57
默叶
阅读(
862
) 评论(
0
)
编辑
收藏
举报
刷新页面
返回顶部
登录后才能查看或发表评论,立即
登录
或者
逛逛
博客园首页
【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
相关博文:
·
Python elasticsearch_dsl 报错及解决方法
·
Python elasticsearch 使用心得
·
elasticsearch部署ELKat least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_mast
·
elasticsearch
·
elasticsearch 安装常见报错
阅读排行:
·
【自荐】一款简洁、开源的在线白板工具 Drawnix
·
没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
·
园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
·
无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
·
C#/.NET/.NET Core优秀项目和框架2025年2月简报
公告
昵称:
默叶
园龄:
3年11个月
粉丝:
1
关注:
1
+加关注
<
2025年3月
>
日
一
二
三
四
五
六
23
24
25
26
27
28
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
1
2
3
4
5
搜索
常用链接
我的随笔
我的评论
我的参与
最新评论
我的标签
我的标签
python
(1)
es
(1)
elasticsearch
(1)
随笔分类
Linux(2)
Python 高级(2)
Python 模块实现(1)
前端(0)
数据库(8)
随笔档案
2023年4月(1)
2023年3月(5)
2023年2月(5)
2023年1月(2)
阅读排行榜
1. Ubuntu打不开终端解决办法(6149)
2. elasticsearch 内存分配设置(2183)
3. elasticsearch 索引数据手动复制注意事项(1472)
4. Linux crontab定时任务设置方法(1102)
5. 使用elasticsearch-head修改一个索引的副本数(871)
点击右上角即可分享




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报